






准备
1.找到要爬取的网址链家https://bj.lianjia.com/zufang/dongcheng/
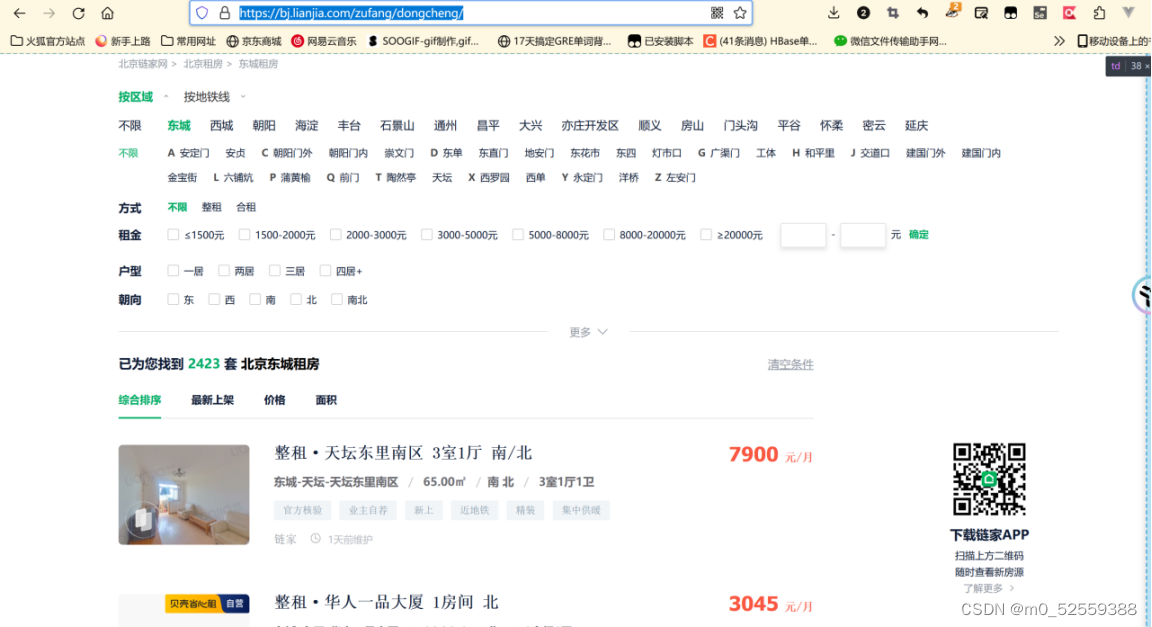 2.使用开发者工具检查寻找要爬取的信息
2.使用开发者工具检查寻找要爬取的信息

3.计划爬取步骤
(1)我们要获取房源的标题、位置、价格、朝向等信息,先为这些信息各建一个数组进行数据存储。
(2)编写获取标题、位置、价格、朝向等信息的方法,并封装成函数
(3)观察当页面跳到第2页第3页类似时网址变化
(4)编写爬取代码,并调用第2步的函数
进行实现
1.为要存储的信息编写数组
 2.编写获取标题函数
2.编写获取标题函数
通过检查,可知标题所在类为content__list–item–aside,获取内容后,使用.get将title获取,具体函数如下
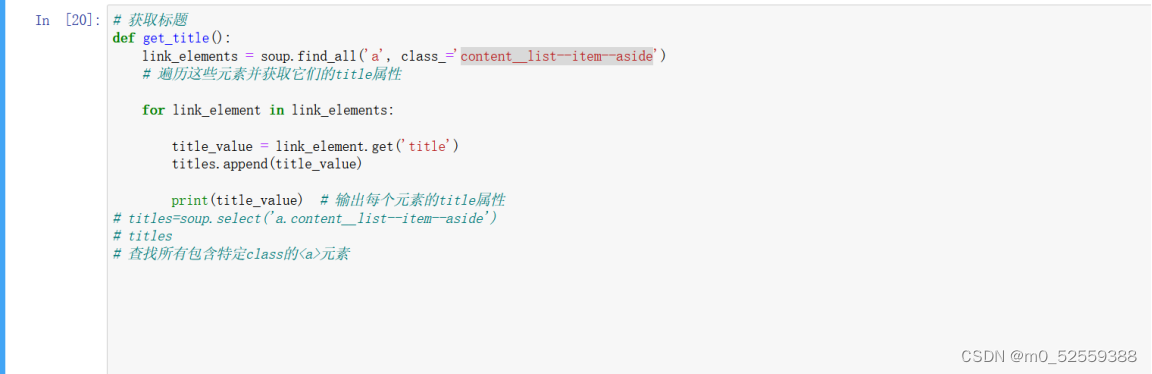 3.获取信息函数
3.获取信息函数
获取信息有包括地址、朝向等信息,所以除了使用类获取文本后,再指定元素用正则表达式将内容抽取出来,并放入列表中,具体代码如下所示

4.获取价格信息
使用类名获取到价格信息,但由于价格信息是分别包含在和中。类似下面这样子。
“<span class=“content__list–item-price”>5300 元/月”
所以需要再提取,并将其合成字符串写入数组中,具体代码如下
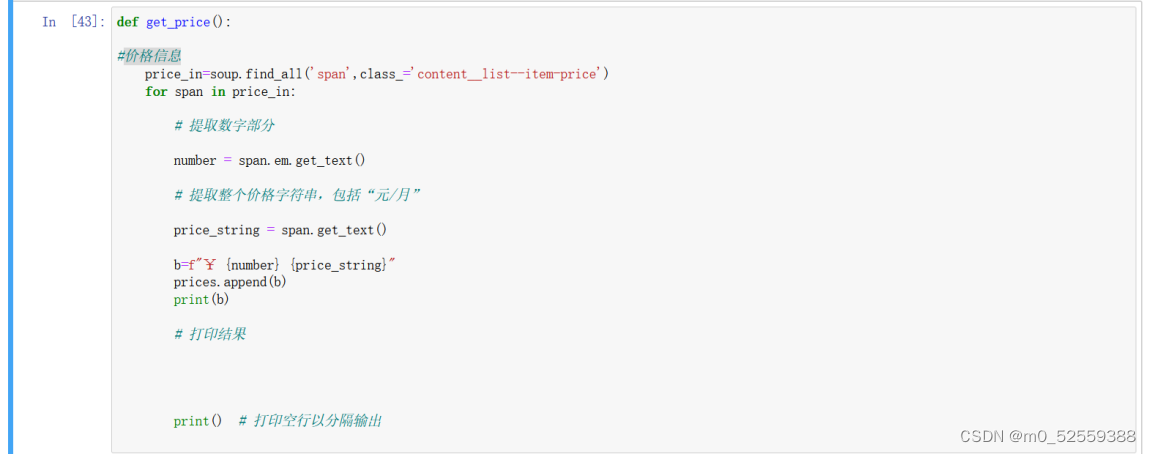
5.接着打开网页,观察页数变化时网址变化
这是第2页时的网址
 可知想遍历1-7页,网址可写为
可知想遍历1-7页,网址可写为
https://bj.lianjia.com/zufang/dongcheng/pg{page}/#contentList
6.编写爬取代码,这里我使用的是 BeautifulSoup,并调用上面封装的函数,具体代码如下
 7.编写将数组内容写入csv文件代码,考虑到有些数据可能为空,所以做了如果数据为空,则传控制操作
7.编写将数组内容写入csv文件代码,考虑到有些数据可能为空,所以做了如果数据为空,则传控制操作
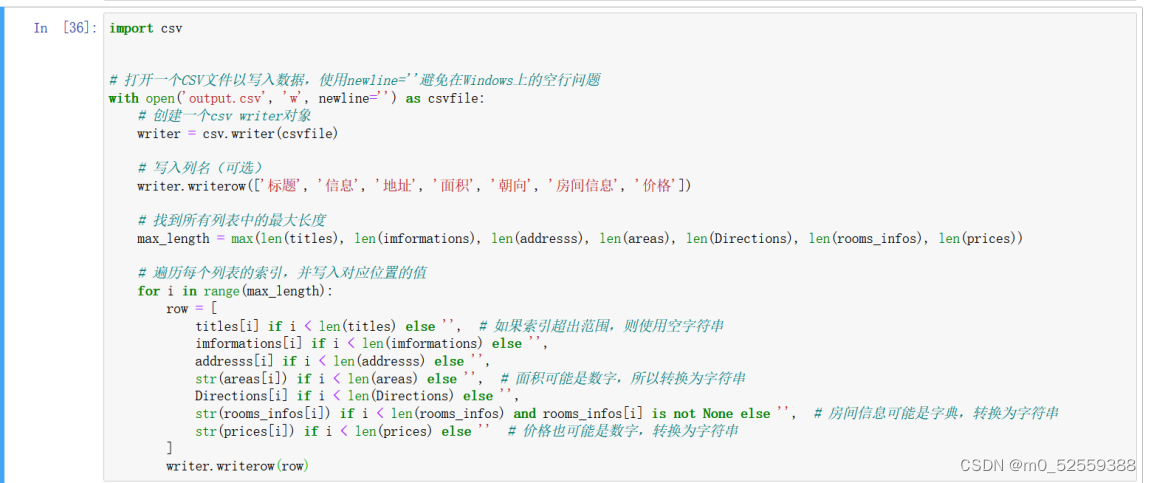
实现效果
1.获取信息数据
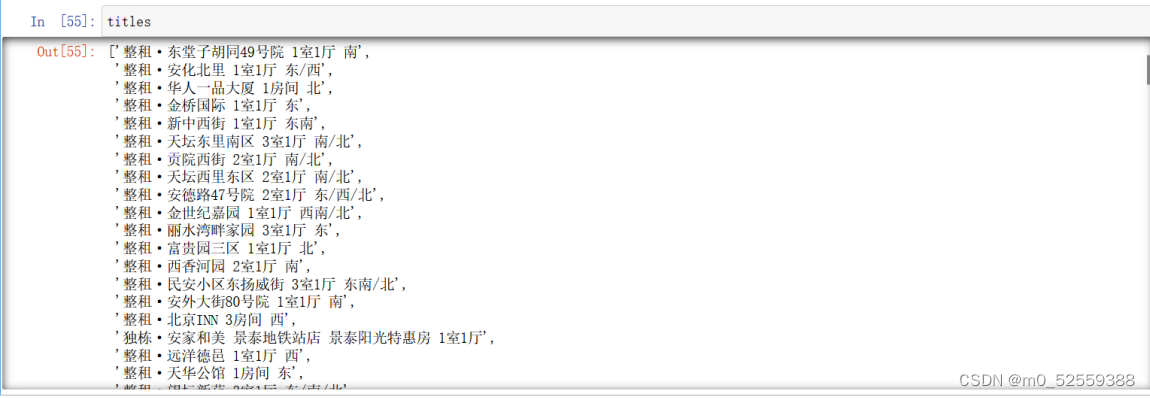
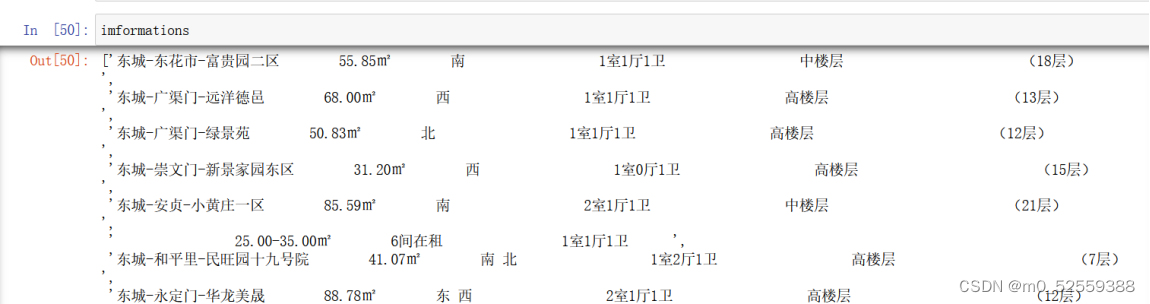 2.获取标题数据
2.获取标题数据
3.获取地址数据
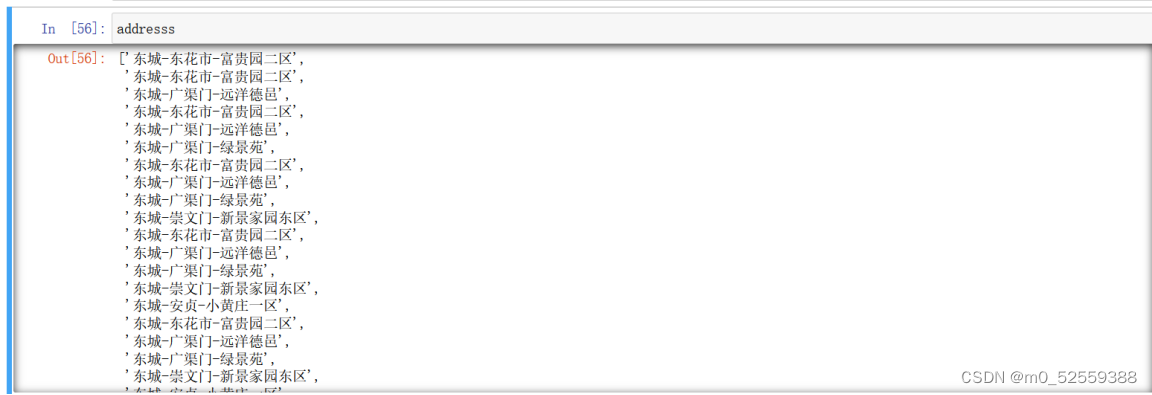 4.获取面积数据
4.获取面积数据
 5.获取朝向数据
5.获取朝向数据
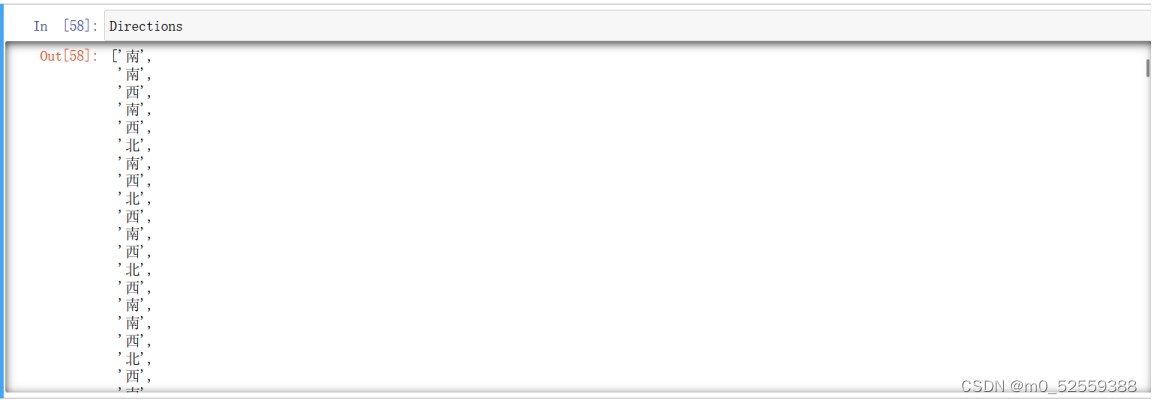 6.获取房间信息数据
6.获取房间信息数据

7.获取价格数据
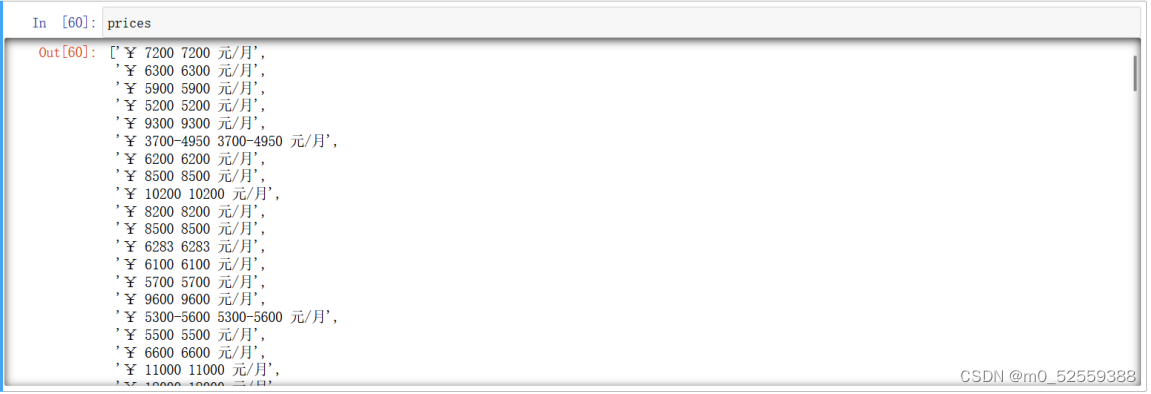 8.写入csv文件
8.写入csv文件
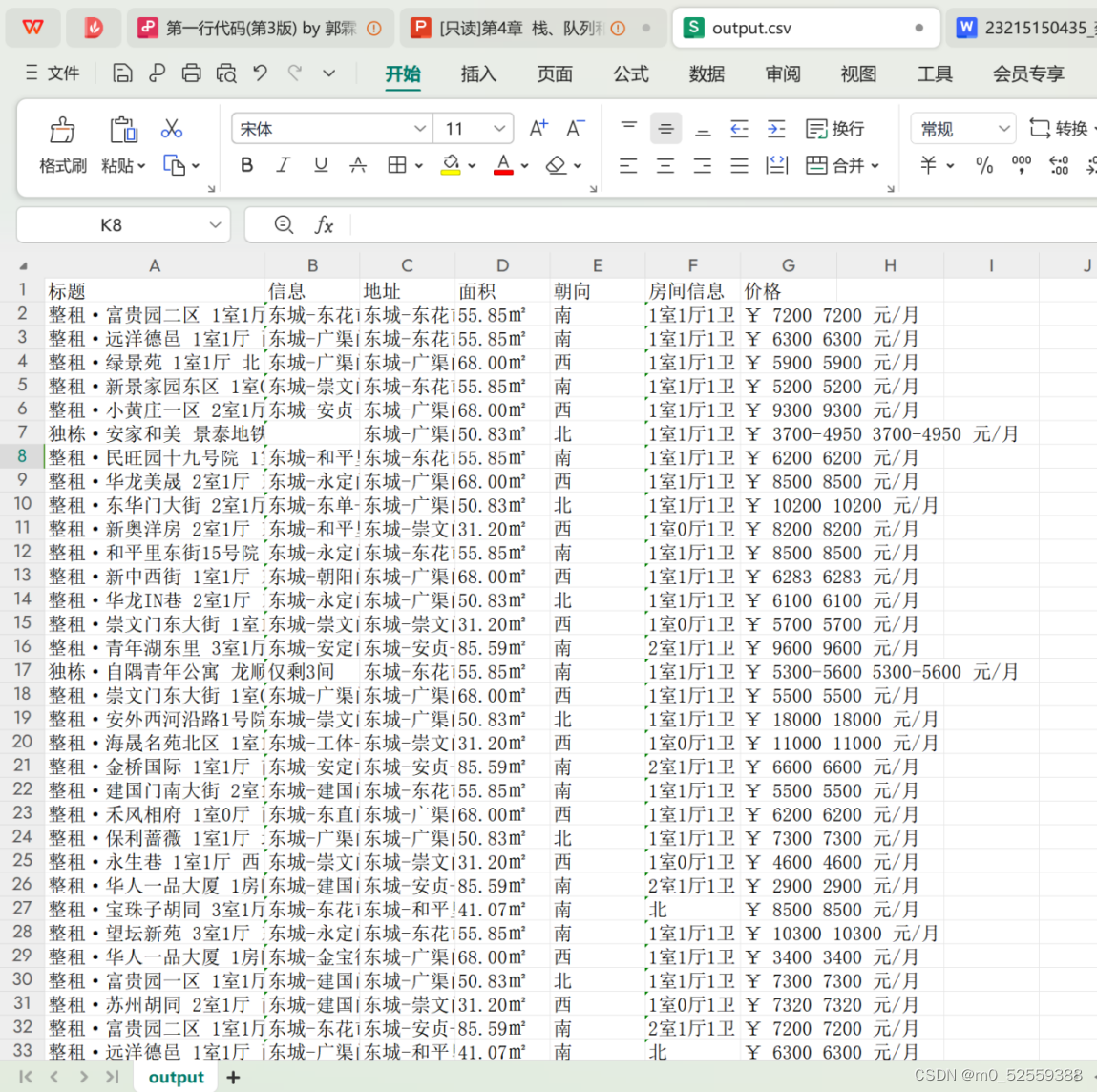
















 5467
5467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











