






简介:
Swin Transformer是一种专为计算机视觉任务设计的分层Transformer架构,其主要创新在于采用了滑动窗口机制和层级化结构。这种设计使得模型在处理图像时能够高效地提取多尺度特征,同时保持较低的计算复杂度。以下是Swin Transformer网络结构的详细介绍。
滑动窗口机制(Shifted Window):
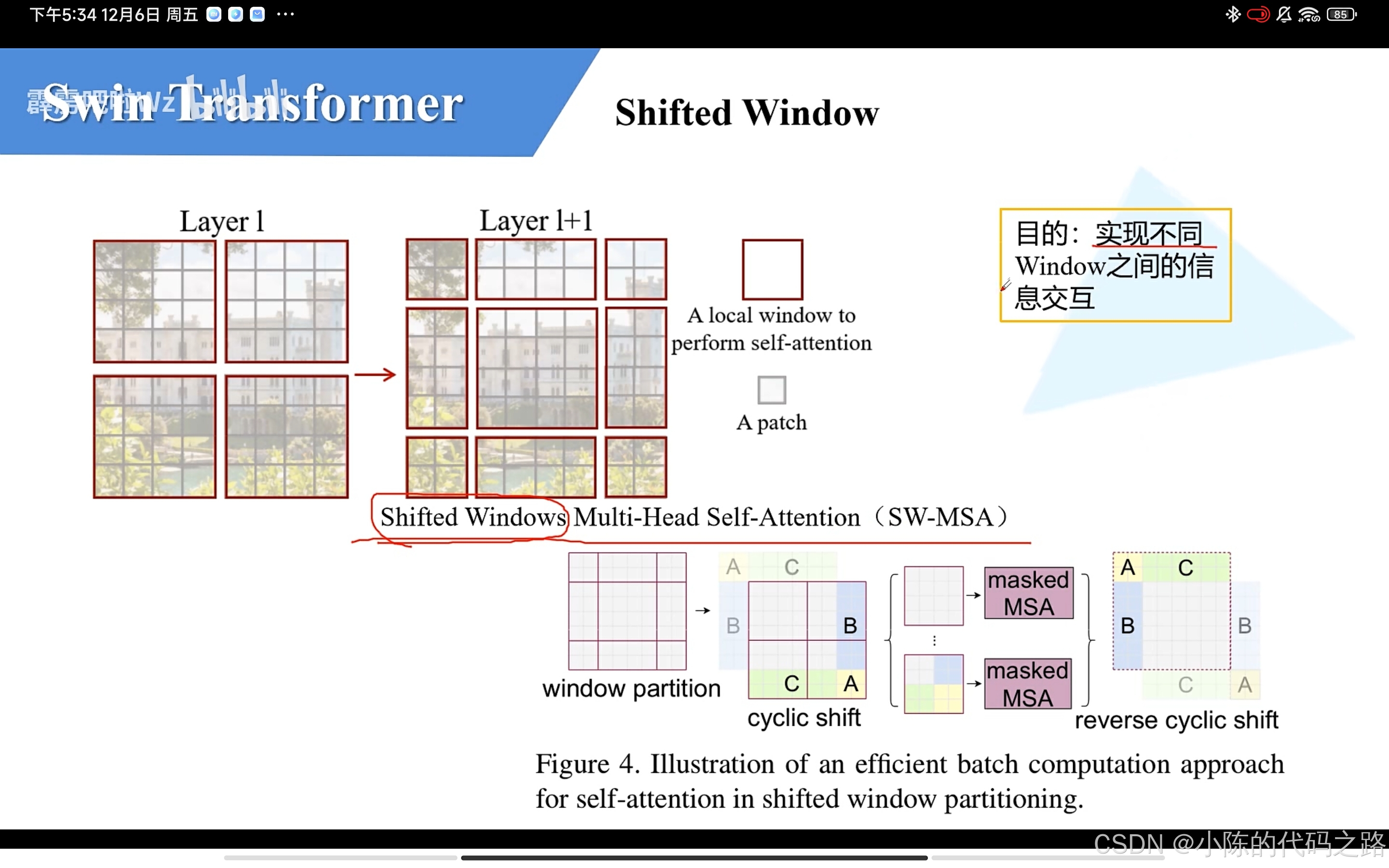
Swin Transformer的一个关键设计元素是其在连续的自注意力层之间移动窗口划分,Swin Transformer将自注意力计算分为多个局部窗口,这些窗口均匀地划分图像,且不会重叠。假设每个窗口包含M×M个图像块,对于一个大小为h×w的图像,全局自注意力模块和基于窗口的自注意力模块的计算复杂度分别为:

可以看出,全局自注意力模块的计算复杂度是与图像块数目hw的平方成正比的,对于大规模的图像,其计算量较大,不太实用。而基于窗口的自注意力模块的计算复杂度是线性的,当窗口大小M固定时,它的计算量是可扩展的,因此更适用于大规模的图像。
基于窗口的自注意力模块虽然复杂度小,但是它忽视了窗口间的连接关系,这限制了其建模能力。这个时候滑动窗口机制应运而生:
在相邻的两个Transformer 模块第一个窗口会用规则的方法划分并合并块,第二个就不那么规则了,这种不那么规则的划分方法就是滑动窗口机制(两个模块加起来才是完整的滑动窗口模块)。
困难点:
开始窗口固定大小,计算量小,滑动之后计算量大,所以要采取措施减少计算量。
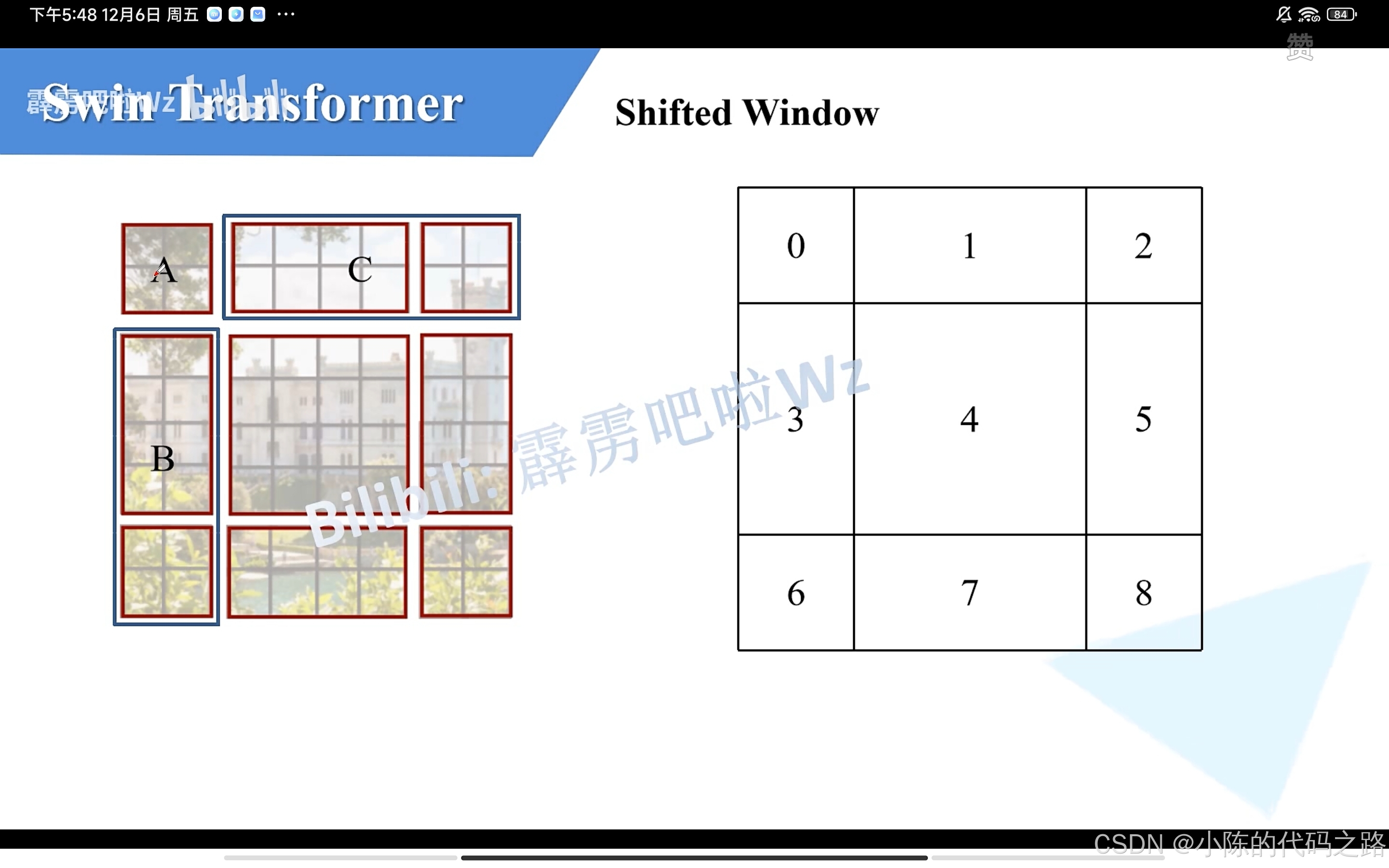
1.首先将滑动窗口分成ABC三部分。
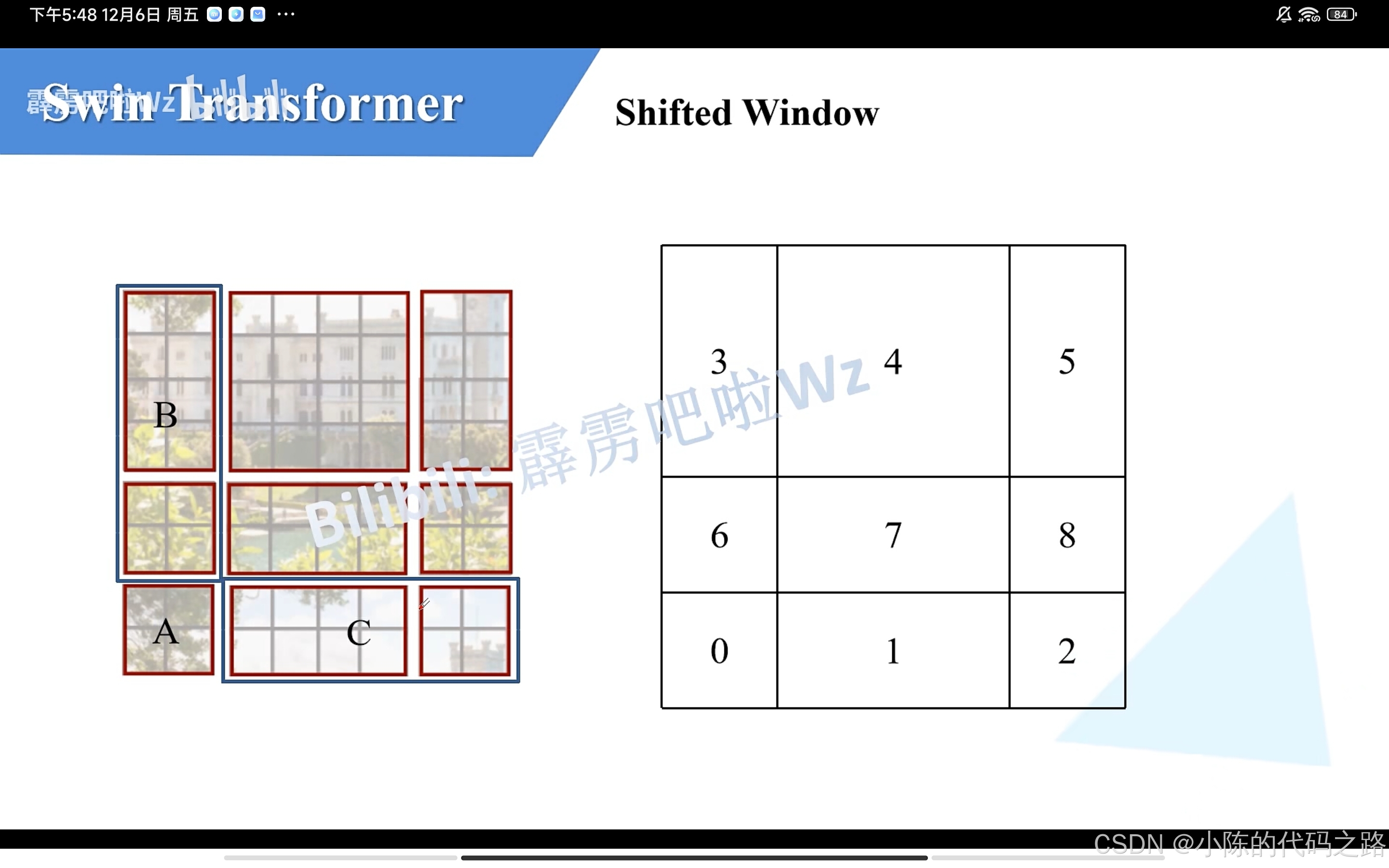
2.将AC部分移到最下方
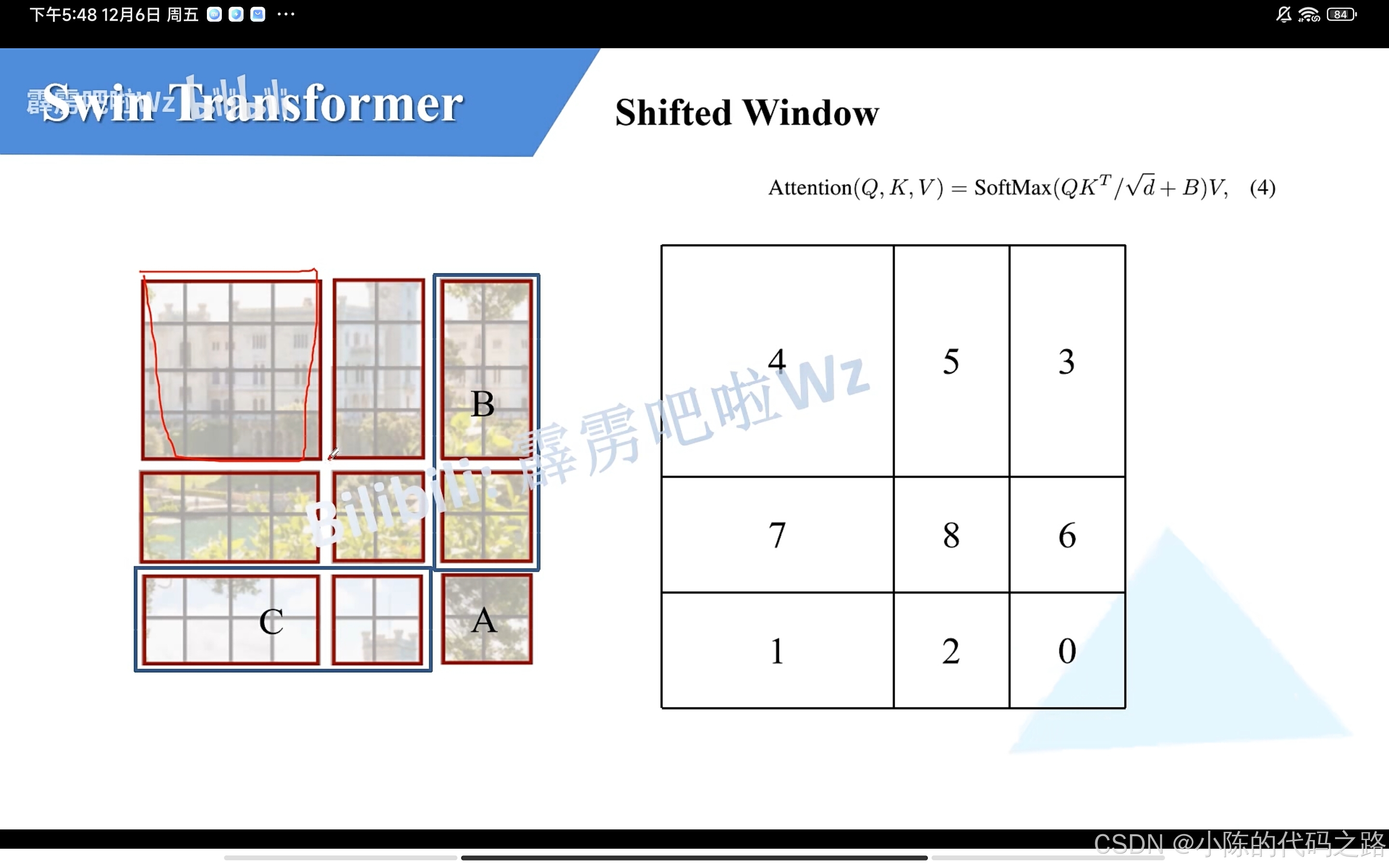
3.将BA部分移到最右方。这样就大致形成了四个4x4的窗口。但是形成的4x4窗口内部还是两部分组成,经过下方操作解决。
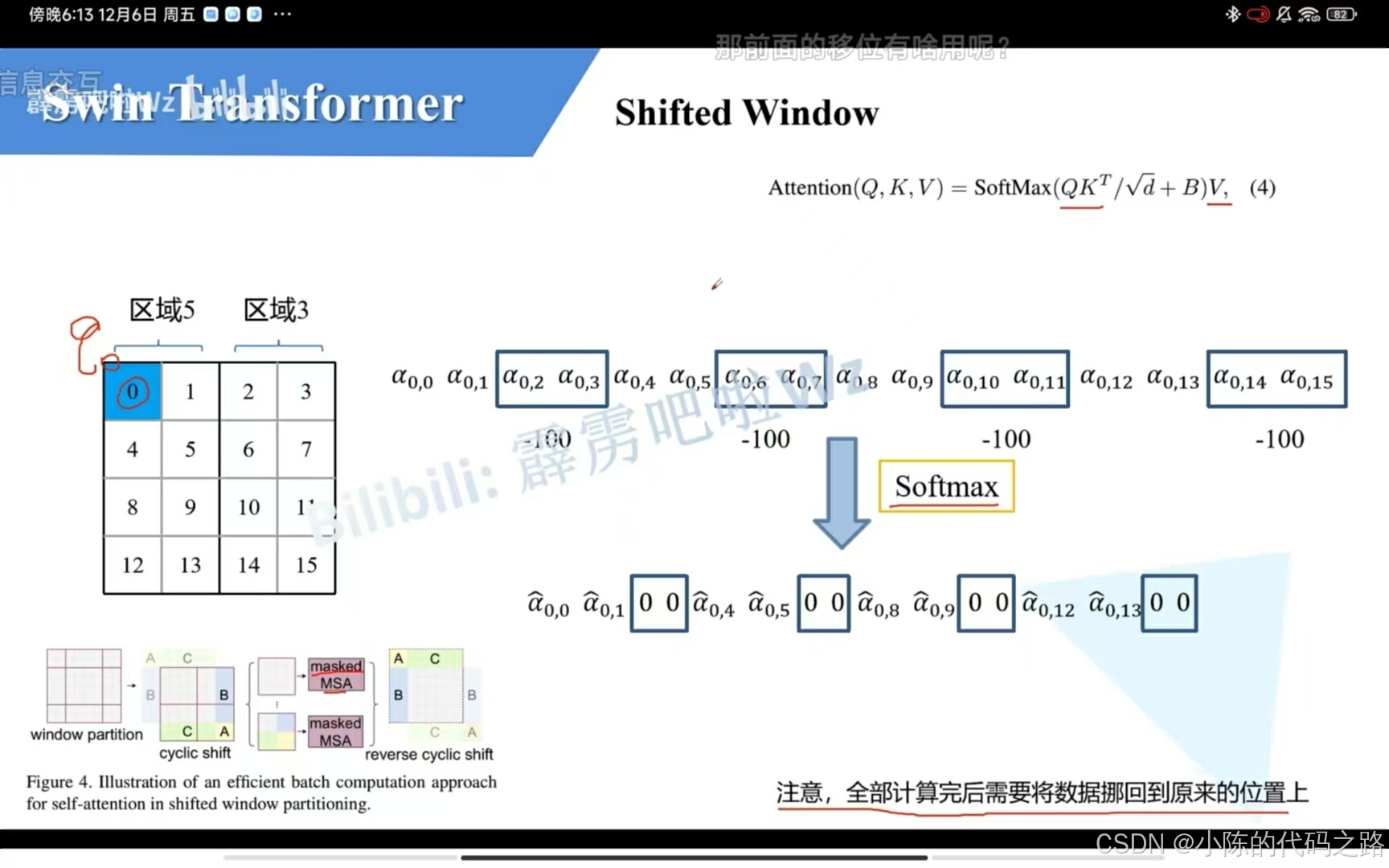
具体来说,Swin Transformer首先将输入图像划分为多个不重叠的窗口,并在这些窗口内独立计算W-MSA(Window-Multi Head Attention)。然而,由于这些窗口之间缺乏信息交流,Swin Transformer引入了SW-MSA(Shifted Window-Multi Head Attention),通过将窗口位置进行移位来实现跨窗口的信息交互。在SW-MSA中,masked MSA的使用确保了在移位后的窗口中,只有相应位置的元素能够参与注意力计算,而不相关的位置则被屏蔽。
层级化结构:
指的是将输入图像通过多个阶段(Stage)逐步处理,每个阶段负责提取不同层次的特征。这种设计使得模型能够有效地捕捉从细粒度到粗粒度的视觉信息,并适应不同尺度的任务需求。下文详解。
网络整体框架:
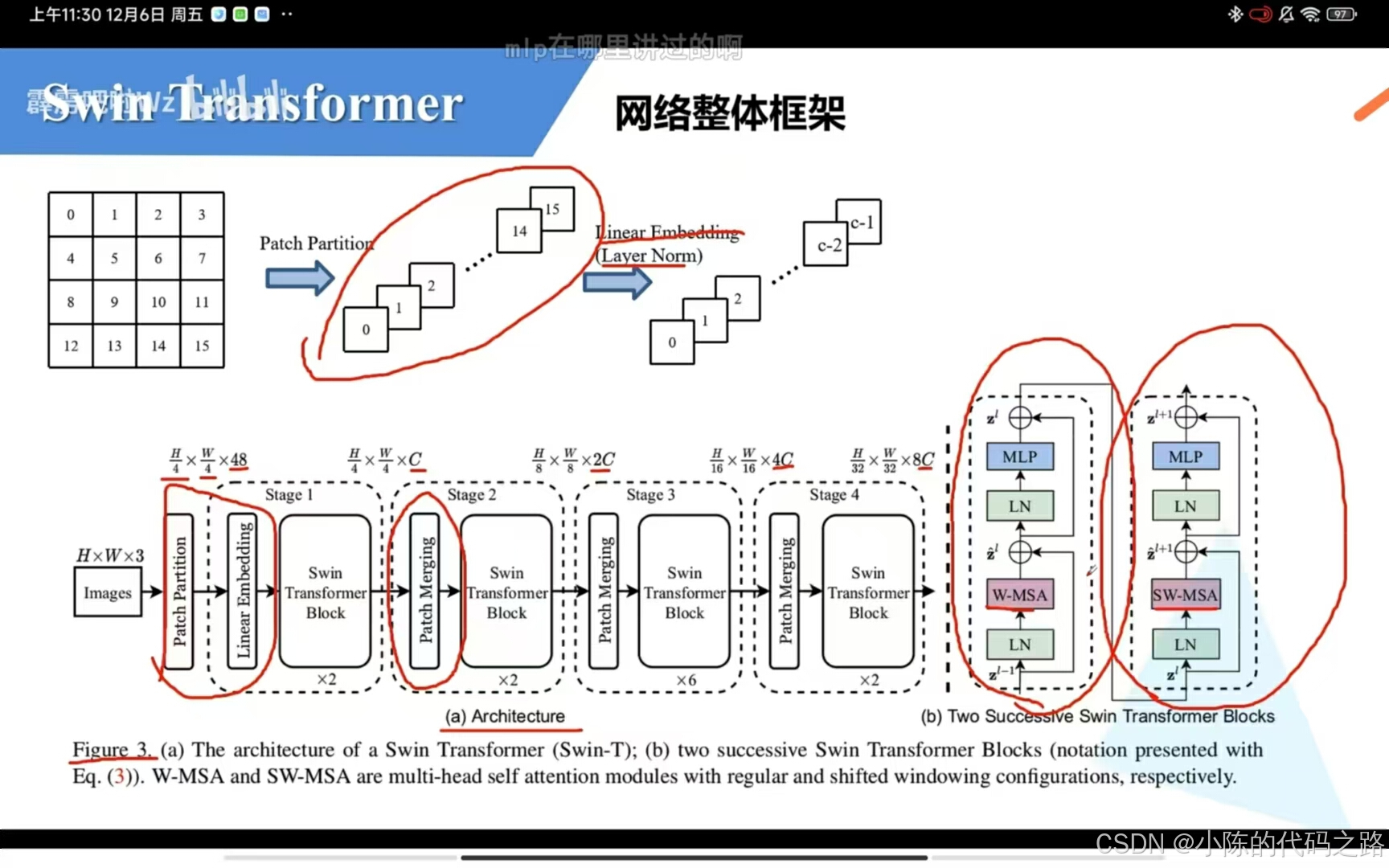
架构方面:
Swin Transformer通常由四个主要的Stage组成,每个Stage包括多个重复的Swin Transformer Block。每个Stage的功能如下:
Stage 1:输入图像经过Patch Partition和Linear Embedding处理,将图像划分为小块并映射到高维空间。
Patch Partition:
是将输入图像分割成固定大小的小块,通常每个小块的尺寸为4×4像素,所以通道数也增加了四倍。这一过程类似于Vision Transformer(ViT)中的Patch Embedding,但Swin Transformer选择了更小的patch尺寸,从而能够提取更细粒度的特征。
Linear Embedding:
是一个线性变换层,旨在将每个patch的特征向量从原始维度映射到一个预设的维度C。这个维度通常是根据模型的大小和复杂性来选择的,以便于后续的自注意力计算。
Stage 2-4:每个后续Stage首先通过Patch Merging层进行下采样,减少特征图的尺寸,同时增加通道数。这一过程允许模型在更深层次上整合信息,从而提高特征表示能力。
Patch Merging:

Patch Merging模块是
首先将每2x2的patch形成一个新的patch,从而实现特征图的降采样。这一过程不仅减少了特征图的空间分辨率,还调整了通道数,以便于后续的处理。
然后通过将多个相邻的小图像块(patches)合并为一个更大的图像块,来有效地捕捉更丰富的上下文信息。这种合并不仅增加了感受野,还能够提取多尺度特征。
最后合并后的patch再经过卷积层进行特征提取,最终形成新的特征表示。
swin tramsformer block:
一般是偶数个,因为通常由一个W-MSA窗口自注意力模块加一个SW-MSA滑动窗口自注意力模块
相对位置偏置(Relative Position Bias)
用于增强模型对输入元素之间相对位置关系的理解。相对位置偏置通过引入可学习的参数矩阵,调整不同位置之间的相对关系,从而在计算注意力时提供更准确的位置信息。
相对位置偏置的作用
- 改善自注意力机制:
在计算自注意力时,Swin Transformer不仅考虑查询(Q)和键(K)之间的点积,还加入了一个相对位置偏置项。这一偏置项是根据元素之间的相对位置计算得出的,使得模型能够更好地捕捉到不同输入元素间的关系。例如,在处理图像时,相对位置偏置能够帮助模型理解某个像素与其邻近像素之间的空间关系,从而更有效地提取特征。 - 减少参数量:
相对位置偏置通过引入一个较小的可学习参数矩阵来表示不同位置之间的关系,这样可以显著减少需要学习的位置编码参数数量。这种方法不仅提高了计算效率,还保持了模型在不同任务上的灵活性。 - 提升性能:
实验表明,使用相对位置偏置的Swin Transformer在多个视觉任务上表现优于使用绝对位置编码或没有位置编码的模型。例如,在ImageNet和COCO等数据集上,相对位置偏置显著提高了分类和检测精度
实现方式
在Swin Transformer中,相对位置偏置通常在自注意力计算公式中被引入。具体来说,当计算注意力分数时,除了常规的Q*K操作外,还会加上一个反映相对位置关系的偏置项。这一偏置项的维度与窗口大小相关,例如,对于一个 7×77×7 的窗口,其相对位置偏置矩阵的维度为 49×4949×49
模型详细配置参数:
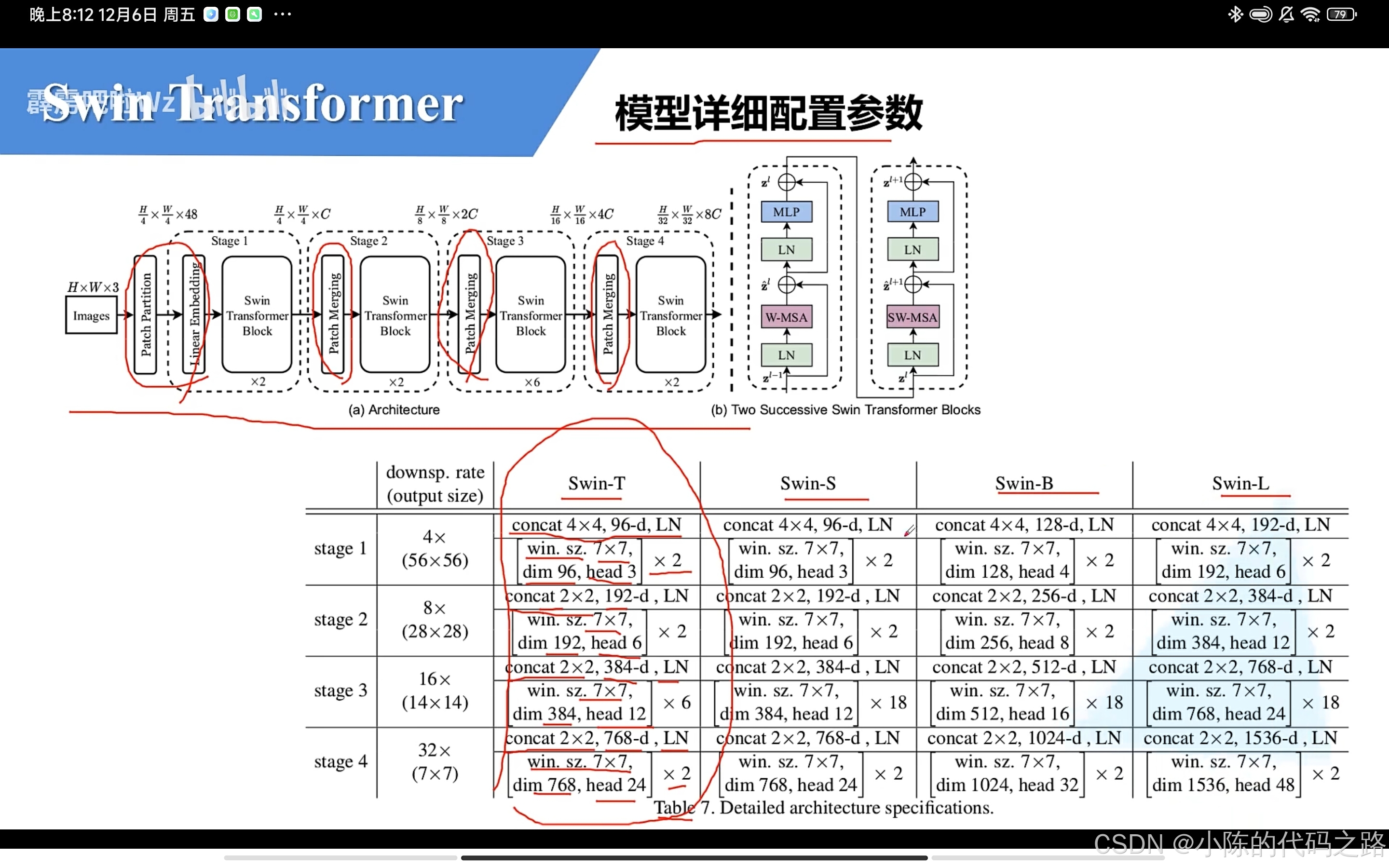
Swin-T:t是最小的意思,s是small较小的模型,b是base,l是large大的模型
然后在swin-T中,
首先经过Patch Partition和Linear Embedding处理
concat4x4:将高和宽下采样四倍
96-d:通道数变为96
然后经过LN:linear normal线性层
再堆叠两个MSA:win.sz7x7:指的是窗口的大小7x7
dim96:指的是输出通道是96
head3:指的是多头自注意力采用的3头
后面的步骤同理。

















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









