







目录
1️⃣ Swin-transformer介绍
Vision transformer将transformer应用到视觉领域,然而它存在一些问题:
- 需要对特征图中的所有patch计算自注意力,即全局自注意力,导致计算开销大
- 采用全局自注意力,每个patch都和其他patch进行交互,导致局部信息提取效率低
Swin-transformer是为了克服上述缺点而提出的,发表在2021年 ICCV上,其主要创新点就是引入窗口偏移(Shifted Window)机制,主要包括两块:
- Windows Multi-head Self-Attention(W-MSA)
- Shifted Windows Multi-Head Self-Attention(SW-MSA)
2️⃣ 原理介绍
下面这张图介绍了Swin Transformer的整体流程,看起来很复杂,现在我按照顺序逐一进行分析。
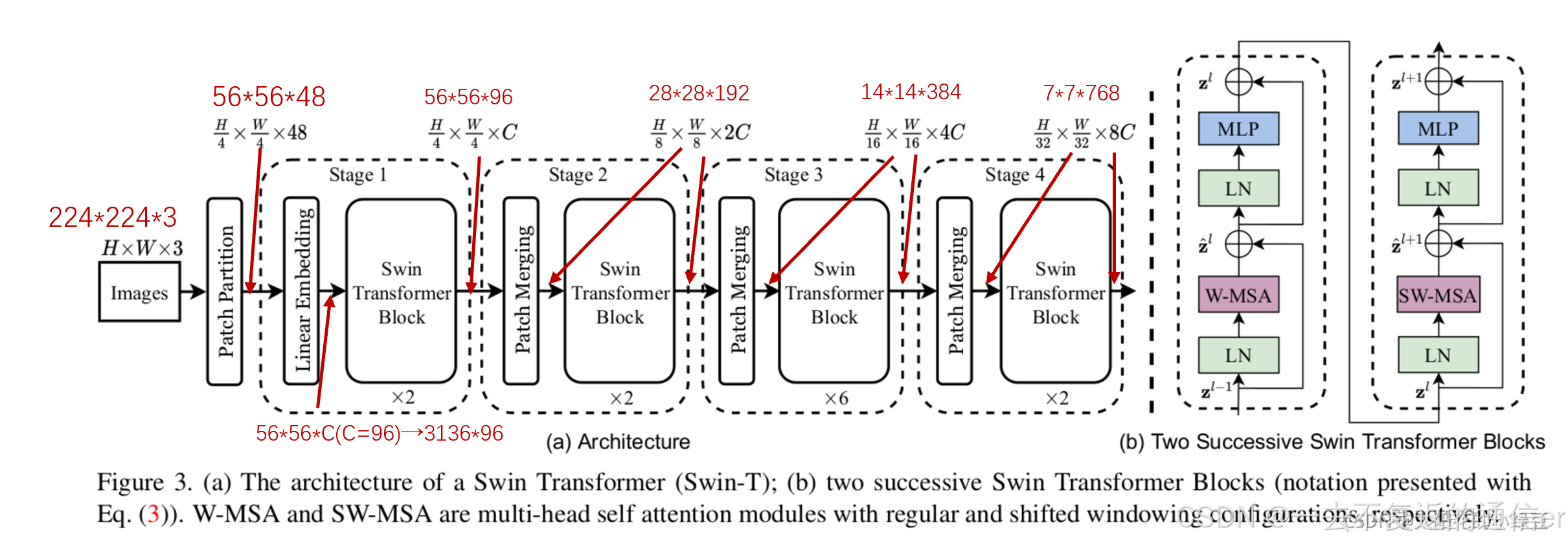
2.1 Patch Partition和Linear Embedding
假设有一张输入图片为224×224×3。经过Patch Partition变成56×56×48。关于Patch操作,看Patch Partition,一看就懂,包会的。
然后经过Linear Embedding,变成56×56×C,对于Swin-T结构,论文中的C设置的是96。56×56×96,表示56×56个patch,每个patch维度是96。transformer输入格式通常是序列长度×每个单词的Embedding维度,因此56×56会被拉直。因此变成3136×96,表示patch个数×patch维度,可以发现3136太大了,会导致耗费太多计算资源。因此作者提出W-MSA。关于为什么W-MSA会节省计算资源,看我下面的分析:
实际上,图中的Patch Partition和Linear Embedding类似于ViT里的Patch Projection,在代码里就是用一次卷积操作完成的。
具体的维度是什么,看一下代码
2.2 Swin Transformer Block
介绍例子之前,先声明两点:
- Swin Transformer Block有两种block形式,一个是W-MSA,另一个是SW-MSA。注意这两个结构是成对使用的,先使用W-MSA再使用SW-MSA。因此Swin Transformer Block都是偶数。
- Swin Transformer Block两种block形式都不会改变特征的维度,这是内部结构决定的
好了,我们来看下面这个例子:左图是对整个特征图进行MSA,每个patch都要和整个特征图中的其他patch进行交互,计算量大。
因此右图提出W-MSA,W-MSA将特征图划分为多个大小为 M × M M×M M×M的小窗口(windows),每个小窗口里有 M 2 M^2 M2个patch,并在每个窗口内独立地进行MSA。(一个大小为 H × W H×W H×W的特征图,下面这个小例子中窗口大小是 M = 2 M=2 M=2,因此特征图被划分成 H 2 × W 2 \frac{H}{2}×\frac{W}{2} 2H×2W个小窗口),计算量将显著减少,那会减少多少呢?

MSA和W-MSA的计算量公式为,具体推导过程见:Swin-Transformer网络结构详解
Ω ( M S A ) = 4 h w C 2 + 2 ( h w ) 2 C Ω ( W − M S A ) = 4 h w C 2 + 2 M 2 h w C \begin{aligned}&\Omega(\mathrm{MSA})=4\mathrm{hwC}^2+2(\mathrm{hw})^2\mathrm{C}\\&\Omega(\mathrm{W}-\mathrm{MSA})=4\mathrm{hwC}^2+2\mathrm{M}^2\mathrm{hwC}\end{aligned} Ω(MSA)=4hwC2+2(hw)2CΩ(W−MSA)=4hwC2+2M2hwC
其中h代表特征图高度,w代表特征图宽度,C代表特征图深度,M代表每个窗口(Windows)的大小。
假设特征图的h、w都为112,M=7, C=128, 采用W-MSA模块相比MSA模块能够节省约40124743680 FLOPs:
2 ( h w ) 2 C − 2 M 2 h w C = 2 × 11 2 4 × 128 − 2 × 7 2 × 11 2 2 × 128 = 40124743680 2(\mathrm{hw})^2\mathrm{C}-2\mathrm{M}^2\mathrm{hw}\mathrm{C}=2\times112^4\times128-2\times7^2\times112^2\times128=40124743680 2(hw)2C−2M2hwC=2×1124×128−2×72×1122×128=40124743680
然而W-MSA也存在一些问题,W-MSA只会在每个窗口内进行自注意力计算,窗口之间无法进行信息传递,为了解决该问题,作者提出了SW-MSA模块,即对窗口进行偏移,如下图所示:

左侧使用的是刚刚讲的W-MSA(假设是第L层),那么根据之前介绍的W-MSA和SW-MSA是成对使用的,那么第L+1层使用的就是SW-MSA(右侧图)。可以发现,右图窗口相较于左图窗口发生了偏移,具体怎么偏移的呢?
即窗口从左上角分别向右侧和下方各偏移了 ⌊ M 2 ⌋ ⌊ \frac{M}{2} ⌋ ⌊2M⌋个像素, M M M是窗口大小,在论文中是4,因此偏移2个patch。
换一个更加直观的图进行理解:

可以发现通过将窗口进行偏移后,由原来的4个窗口变成9个窗口了。对于右图中中间4×4的窗口,它能使左图中4个窗口的信息联系起来,这样就解决了窗口之间无法进行信息传递的问题。
聪明的你可能发现了,原来是4个窗口,现在变成了9个窗口,而且窗口大小还不一样,此时没法组成一个batch进行处理了,有一个方法就是对小的窗口进行padding,把它们都变成大小为4×4的窗口,然后进行9次W-MSA,这不是给自己找事呢吗,确实是这样滴,因此作者为了解决这个事,又提出了Efficient batch computation for shifted configuration
论文中的操作如下图所示,有点看不懂,因此借鉴博客Swin-Transformer网络结构详解的描述:

下图左侧是刚刚通过偏移窗口后得到的新窗口,右侧是为了方便大家理解,对每个窗口加上了一个标识。然后0对应的窗口标记为区域A,3和6对应的窗口标记为区域B,1和2对应的窗口标记为区域C

然后先将区域A和C移到最下方:

接着,再将区域A和B移至最右侧:

移动完后,4是一个单独的窗口。但其他的还都是分散的,因此将5和3合并成一个窗口;7和1合并成一个窗口;8、6、2和0合并成一个窗口,神奇的发现,又和原来一样是4个4x4的窗口了。
但是有个问题,把不同的区域合并在一起后再进行MSA,信息不就乱了吗?
确实是这样,因此,采用masked MSA,通过设置掩码来隔绝不同区域的信息。
下面举个例子,例如左图所示,区域5和区域3组成了4×4窗口,里面共有16个patch,现在把窗口拉直(第一行从左到右,第二行从左到右以此类推),则变成了右图所示的样子,蓝色代表区域5的patch,绿色代表区域3的patch

有了输入X,我们就可以计算Q,K,V了,注意嗷,Q,K,V的大小是一样的。一定也是16行,按照和X同样的排列,两个区域5,两个区域3,以此类推。但是有多少列取决于网络设计,如下图所示:

有了Q,K,V,现在我们计算 Q K T QK^T QKT,如下图所示:

Q K T QK^T QKT的大小是16×16,其中蓝色部分表示 区域5的patch和区域5的patch相乘;绿色表示 区域3的patch和区域3的patch相乘;白色部分表示交叉相乘。因为我们隔绝不同区域的信息,因此白色部分都不考虑,所以想办法把它们都刨去。因此设计的掩码格式如下图所示,蓝色和绿色部分的掩码都是0,白色部分都是-100(没写出来,太乱了)。

然后让 Q K T QK^T QKT除以 d k \sqrt{d_k} dk得到 Q K T / d k QK^T/\sqrt{d_k} QKT/dk,再与掩码相加,注意是相加,transformer里是相乘。最后经过Softmax后,白色部分的值基本就趋近0了。这样就实现了隔绝不同区域的信息。
区域分布不同,掩码的格式也不同,论文的作者做了可视化,我举得这个例子就是下图中window1的情况:

再回头看一下Shift window后的图片:

我们通过上述不同的Mask MSA,对4个4
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7257
7257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









