







前言
本项目缘起于在Buff上一直看到有特殊磨损枪皮,但没能找到合适的入手可能,遂考虑自己定制一把生日磨损,本文主要是关于磨损的一些相关了解。
时间:2024年6月1日
2024年6月3日补充:找到了一个好用的工具网站,基本上可以满足目前需求,以后看有没有优化的可能,本项目暂时挂起。(他的排序似乎不是单纯的排列组合,在数学上有什么优化的空间吗?)
https://andersonproescholdbell.github.io/floatsV1/index.html
通过油猴脚本在Buff网站可以提取库存磨损,也可以提取Steam市场的磨损
关于网页上元素提取可以参看
https://cloud.tencent.com/developer/article/1863796
另外通过获取磨损过程中繁琐而耗时的体验想到,如果想要将磨损公式应用在加密中,通过分发十个密钥是否能够得到一个高强度的密码?
前期准备
手套和刀不适用于炼金,纪念品和收藏品最上级不能炼金(每位炼金术师都曾跌倒在晶红石英上)
按照消费—工业—军规—受限—保密—隐秘顺序依次往上,十把同类型(暗金/非暗金)下级合成对应上级(产出概率有左右派之分,本文主要是合成炉所以不太相关)
作为第一次炼金尝试的是小炉子,从梦魇武器箱的军规级(Mil-spec)
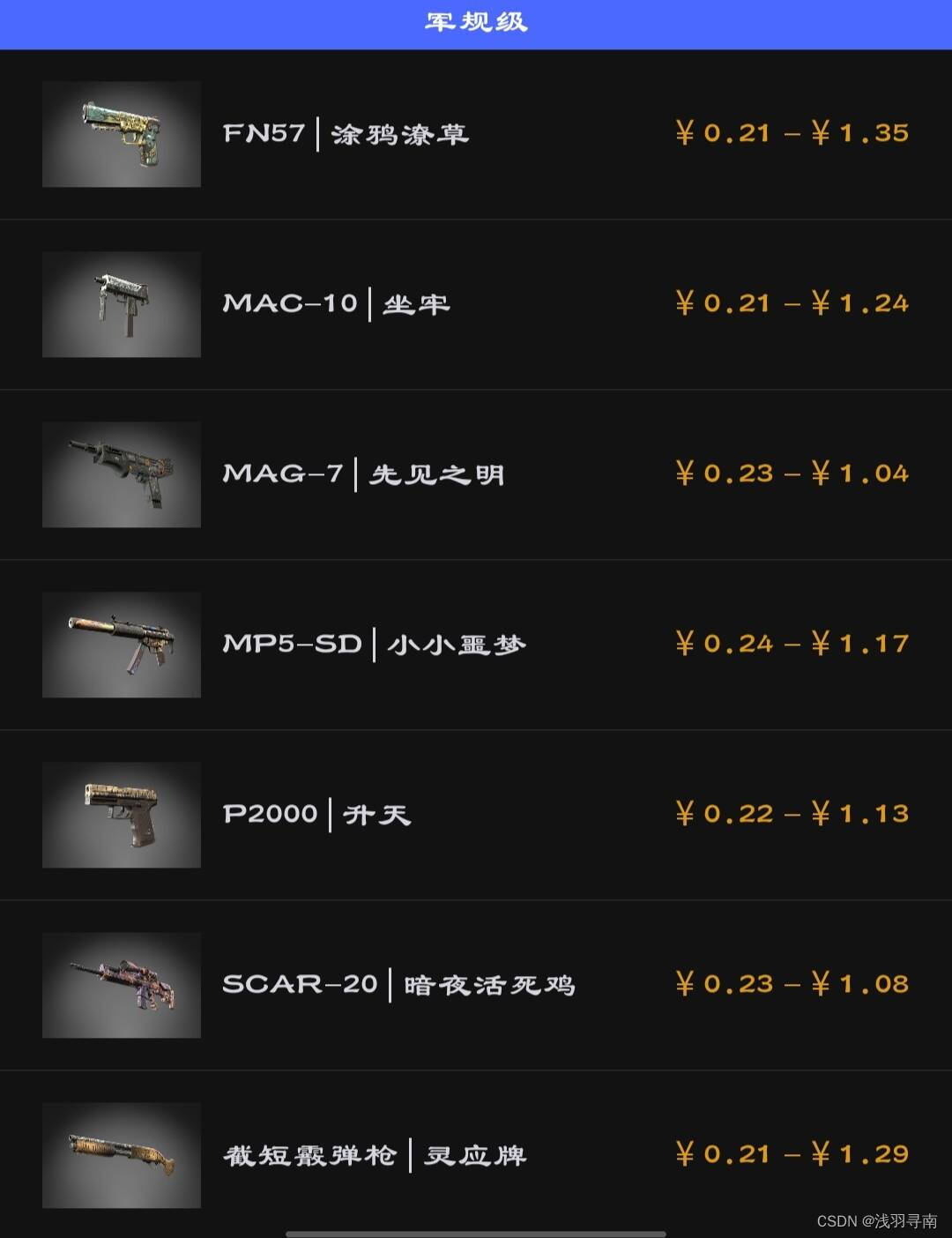
合成到受限级(Restricted)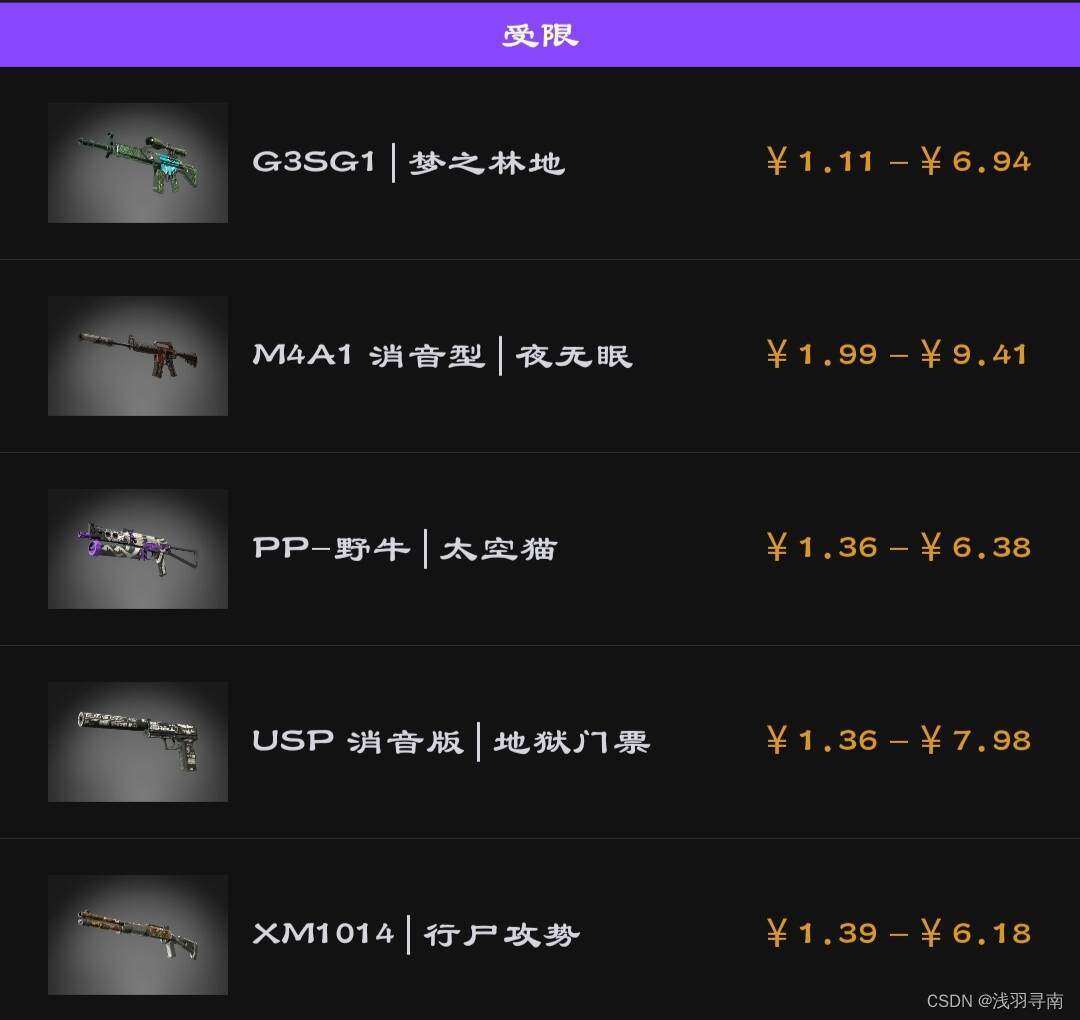
作为便宜量大好用还是主战武器皮肤,产出夜无眠和太空猫都是期望的理想结果,地狱门票作为手枪局常用,行尸攻势是类似猫猫狗狗的胡里花哨的皮肤,只要不是连狙都挺好
磨损计算规则
磨损程度分五种:
崭新(0-0.07)
略磨(0.07-0.15)
久经(0.15-0.38)
破损(0.38-0.44)
战痕(0.44-1)
假定预期输出磨损为Y,十把原材料的平均磨损为X(X即十把武器磨损之和/10)
Y=X×(目标产物磨损区间)+目标产物最小磨损
磨损区间来源参考
https://wiki.cs.money/zh/weapons/m4a1-s/night-terror
可知
夜无眠 0-0.7
太空猫 0-0.67
地狱门票 0-0.76
行尸攻势 0-0.5
梦之林地 0-1
本次目标产物定为 夜无眠(FieldTested)(0.18931226) 进行尝试
因而所需平均磨损X可由
X×(0.7-0)+0=0.18931226(+0.00000000x )
所得X范围为[0.2704460858, 0.2704460998]
理论上只要能够保证十把原材料的平均磨损落在这个区间中即可,开始收货!
新增部分:
但在查阅资料时参考视频 BV1Eo4y197pU下
@札称榙 的回复
“其实并不是十把磨损完全按照公式来计算的,git上的大佬那个公式用了V社的浮点运算机制,才能算出来准确的生成物磨损,你如果单纯只是用10把材料去简单进行“十进制的数学加和”,结果是会有偏差的。另外V社的这个浮点运算机制的原因,生成物的磨损也不是连续的,比如这级的磨损是0.1234567,你是没有办法合成出0.1234568的,只有IEEE754运算里有的数才能被生成,这也就是为什么普通数学加减计算的磨损会有偏差。”
和 @沐言sama 的回复
“相对的,暴力枚举肯定比精进浮点数筛选高啊,这肯定不是暴力枚举,肯定是优化过的分层。算法正常的话不存在进位出错的。顺序我指的是市场购买顺序按计算出来给出的数据顺序购买,进位出错只能是自己磨损顺序放错了导致7位以后浮点计算中进位出现了问题。”
放置顺序和具体7位以上的位数舍去,仍需考虑
【待更新】
这是一个计算浮点数的网站,似乎可以规避以上问题:
https://andersonproescholdbell.github.io/floatsV1/index.html
自适应寻找可能解
汰换模拟采用网站(貌似和Buff使用的都是右派概率生成)
https://csfloat.com/trade-up
考虑目前网站只能被动提供10件物品磨损去“验证”产出结果磨损,以及第三方网站可以通过steam提供的api(Inventory URL)读取磨损值,交给程序完成寻找解在成本控制上是可行的
于是设想设计一个封装好的程序,目标功能如下:
- 通过提供的接口爬取已有库存的磨损值,也许可以拉成excel供后续使用
- 通过https://wiki.cs.money/zh/weapons/获取目标磨损区间(最大最小磨损)
- 通过目标公式在库存的数据中寻找可能的解并标记
- 额外功能,在给定数据库中尝试找到尽可能多的不重复组解
- 额外功能,在无解情况下,Buff上底价或者低溢价爬目标磨损的原材料下单
程序实现
可能需要JavaScript, 预期是主要依托Python完成。
FloatMarket能爬,我们能不能爬?
实践复盘
在240603晚上的后续实际操作中收集了94个各类型原材料,通过网站
https://andersonproescholdbell.github.io/floatsV1/index.html
搭配出了六套夜无眠,余料拉了两套太空猫一套连喷。在独立分布前提期望下大概能出两炉目标产物就好了。第一炉是太空猫炸了连狙,但是目标磨损是0.237137049,实际产出是0.237137035;还有两次尝试机会,和B站的@CandyPizzaLB大佬交流后大约是和放置顺序有关(IEEE754的作用机制),后续继续了解学习;
在汰换过程中发现,实际饰品的按名称后同类排列顺序大抵是从高磨损到低磨损 但也存在个别例外,对后续定位也是有益的经验。
这一炉算是余料的余料配的,最后14个搭配出1001种期望产出1588818281888的太空猫(实际只能展示十位磨损),可惜。
2024年6月4日14:49:47
和Simon交流后更新:关于0.237137035和0.237137049

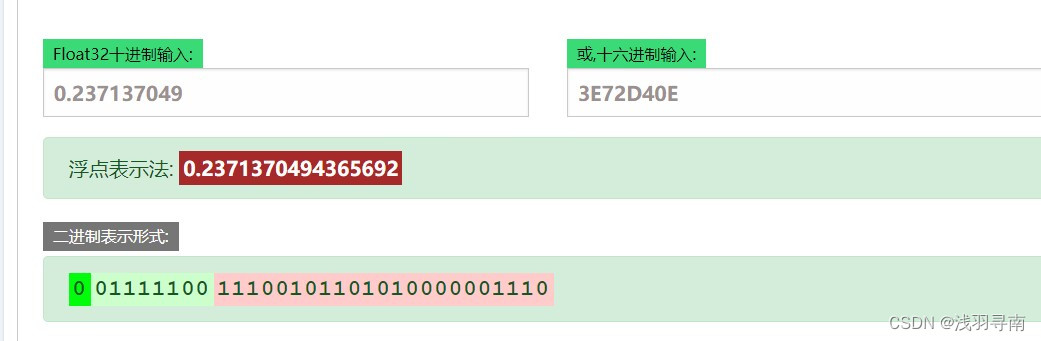
可以观察到是在32位数的最低位精度产生的误差,这也表明了七位小数之后,想要更准确的磨损前提是要查证IEEE754中是否存在对应的浮点数(如果目标数要用更高精度的format表示,则炼金不可用)。二进制表示形式来源于:
https://tooltt.com/floatconverter/
此中关注到计算结果偏差并非原材料磨损带来的,而是计算过程中顺序带来的,目前理解上近似于如下规则:
5+5+4 和 5+4+5
在每一步计算后都进行四舍五入,会得到两个不同结果。
傻瓜式卡高位磨损使用教程:
- 首先根据预期产物磨损和原材料的上下限套公式得到一个大致原材料平均数的解,后续获取也就收集这个磨损附近的原材料,根据经验最好是选取一些方差较大的极端数据可以提高碰的成功率?(只是经验没有经过严格验算);
- 库存材料就用buff查磨损,市场材料就用Steam Market Tool拉到一面一百个查磨损(理论上在三十个到五十个材料中就应该能有一个预计产出解,根据排列组合方式至少有一百万亿组合,足够碰出一个需要的八位数字)(这里考虑到与添加顺序是相关的采用排列数而非组合数);
- 将提取出的磨损值批量以英文逗号分隔的形式复制粘贴导入到上述floatsV1的网站里(他那里提到commas,但实际上导入的一长串数据前后不需要逗号,以及无视4 digits的那个提示),根据目标产物磨损上下限,目标磨损,小数位数进行遴选。我自己个人习惯是要勾选更低位数
- 得到预期结果,网站会给定一串特定的Combo,回到游戏中进行汰换,由于我第一炉没有严格按照顺序导致最终结果的八九位开始与预期不符,根据@CandyPizzaLB的说法,如图中这串combo,比如说0.2508060就应该是第一个放进炉子中的,0.286320就是第二个放进炉子中的,以此类推。
- 由于本身多个可能产出的问题,尤其是多个上级产物的上下限之间并不一致的情况,需要重复以上炼金步骤,得到预期磨损的预期产物。

根据步骤四反馈得到的问题,如果预期磨损是六位七位小数(尤其是生日中月份日期是一位的),冗余要比八位小数高很多,成功率也应该高很多。
以下是一个自己尝试写的小代码,专门处理最后余料的余料。当数据规模大起来以后,内存会炸,初步考虑是
combinations = list(itertools.combinations(data, num))
的原因:
import itertools
def calculate_average(data):
return sum(data) / len(data)
def find_combinations(data, num, coefficients):
combinations = list(itertools.combinations(data, num))
results = []
for combination in combinations:
average = calculate_average(combination)
for coefficient in coefficients:
result = average * coefficient
results.append(result)
return results
if __name__ == "__main__":
data = [0.21055656671524048,0.23193314671516418,0.23738840222358704,0.2531515955924988,0.23174238204956055,0.2151155173778534,0.23283444344997406,0.2509741485118866,0.2398422658443451,0.25069206953048706,0.25004056096076965,0.2464776337146759,0.24224704504013062,0.2114250212907791]
selected_data = 10
coefficients = [0.5, 0.67, 0.7, 0.76]
possible_results = find_combinations(data, selected_data, coefficients)
for i, result in enumerate(possible_results):
print(f"Combination {i + 1}: {result}")
with open("results.txt", "w") as file:
for i, result in enumerate(possible_results):
file.write(f"Combination {i + 1}: {result}\n")


















 5745
5745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









