







定义
回归分析是指一种预测性的建模技术,主要是研究自变量和因变量的关系。通常使用线/曲线来拟合数据点,然后研究如何使曲线到数据点的距离差异最小。
举个例子,我们可以提供了每天的抖音榜单中的商品销量数据,用来预测未来一周时间的预测销量。此时每天的抖音榜单中的商品销量数据就是自变量,而未来一周时间的预测销量就是因变量。
模型步骤
采用上述文字所述的机器学习建模三个步骤
- step1:模型假设,选择模型框架(线性模型,非线性模型)
- step2:模型评估,如何判断众多模型的好坏(损失函数)
- step3:模型优化,如何筛选最优的模型(梯度下降)
我们以线性模型来说明上述步骤。
Step 1:模型假设 - 线性模型
一元线性模型(单个特征)
当仅有一个特征为 x ,一元线性模型就可以假设为 y = b + w * x 。b和w可以取任意实数。
多元线性模型(多个特征)
当输入特征不止一个时,假设有
x
0
x_0
x0,
x
1
x_1
x1,
x
2
x_2
x2,
x
3
x_3
x3四个变量。那么多元线性模型就可以假设为 y = b +
∑
w
i
x
i
\sum_{}w_ix_i
∑wixi
Step 2:模型假设 - 损失函数
假设
x
1
x_1
x1为自变量,
y
1
y_1
y1为因变量。f为所找线性模型的函数。
为了判断模型的好坏,我们可以用模型预测的
y
1
∗
y_1^*
y1∗和真实值
y
1
y_1
y1的差作为损失函数,损失函数所得值越小,模型就越好。
假设我们有10个变量,采取一元线性模型,那么上面损失函数即为:
L
(
w
,
b
)
=
∑
n
=
1
10
(
y
n
∗
−
(
b
+
w
∗
x
n
)
)
2
L(w,b)=\sum_{n=1}^{10}{(y_n^*-(b+w*x_n))^2}
L(w,b)=∑n=110(yn∗−(b+w∗xn))2
Step 3:最佳模型 - 梯度下降
已知损失函数
L
(
w
,
b
)
=
∑
n
=
1
10
(
y
n
∗
−
(
b
+
w
∗
x
n
)
)
2
L(w,b)=\sum_{n=1}^{10}{(y_n^*-(b+w*x_n))^2}
L(w,b)=∑n=110(yn∗−(b+w∗xn))2,我们需要找到一个w和b使得L的值最小。
我们需要引入一个概念
学习率:移动的步长
1.先随机选取两个初始值
w
0
w_0
w0,
b
0
b_0
b0
2.分别计算当w=
w
0
w_0
w0,b=
b
0
b_0
b0时对w和b的偏微分。
∂
L
∂
w
∣
w
=
w
0
,
b
=
b
0
,
∂
L
∂
b
∣
w
=
w
0
,
b
=
b
0
\frac{\partial L}{\partial w}|_{w=w_0,b=b_0},\frac{\partial L}{\partial b}|_{w=w_0,b=b_0}
∂w∂L∣w=w0,b=b0,∂b∂L∣w=w0,b=b0
3.将w0减去w的偏微分和学习率的积得到下一个w1,将b0减去w的偏微分和学习率的积得到下一个b1。
w
1
←
w
0
−
L
R
∗
∂
L
∂
w
∣
w
=
w
0
,
b
=
b
0
w_1 \leftarrow w_0 - LR * \frac{\partial L}{\partial w}|_{w=w_0,b=b_0}
w1←w0−LR∗∂w∂L∣w=w0,b=b0
b
1
←
b
0
−
L
R
∗
∂
L
∂
b
∣
w
=
w
0
,
b
=
b
0
b_1 \leftarrow b_0 - LR*\frac{\partial L}{\partial b}|_{w=w_0,b=b_0}
b1←b0−LR∗∂b∂L∣w=w0,b=b0
LR是学习率
然后重复上述操作,直到两个偏微分都等于0。此时就找到损失函数的一个最低点。
一元一次线性模型最终的结果是一条直线,在解决问题时,各种点的分布往往是一条复杂的曲线。这时候我们就需要使用更复杂的复习,用1元2次或者1元3次等等来更好的去拟合。
过拟合问题
当我们使用更复杂的模型去拟合曲线时,有时会发现一个很奇怪的现象。该模型在训练集的误差非常小,但是在测试集的表现却很差,这是因为模型在训练集上产生过拟合的问题,也就是拟合过度。
加入正则化
当我们想要获得更优秀的模型时,往往需要加入更多的特征,但是权重w可能会使得某些特征权值过高,导致出现过拟合现象,所以我们加入正则化。

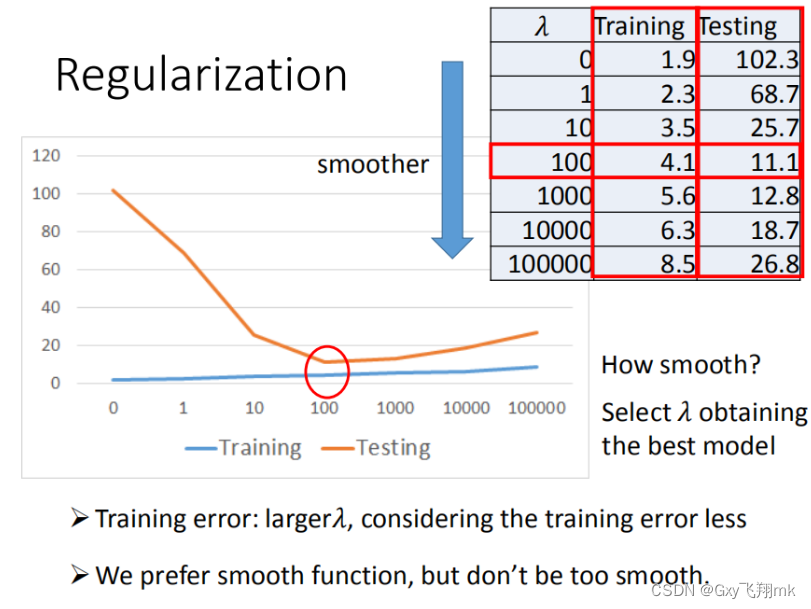
- w 越小,表示 function 较平滑的,function输出值与输入值相差不大
- 在很多应用场景中,并不是 w 越小模型越平滑越好,但是经验值告诉我们 w 越小大部分情况下都是好的。
- b 的值接近于0,对曲线平滑是没有影响
















 2184
2184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











