






 本文探讨了大模型部署中使用FP16半精度来减少内存占用,通过LMDeploy进行量化技术,以提升推理速度。特别关注了decoder-only架构的特性,以及如何在存储和推理阶段分别处理量化问题。同时,介绍了如何进行实际的安装、部署和量化实践。
本文探讨了大模型部署中使用FP16半精度来减少内存占用,通过LMDeploy进行量化技术,以提升推理速度。特别关注了decoder-only架构的特性,以及如何在存储和推理阶段分别处理量化问题。同时,介绍了如何进行实际的安装、部署和量化实践。
大模型部署背景

参数用FP16半精度也就是2字节,7B的模型就大约占14G

2.LMDeploy简介

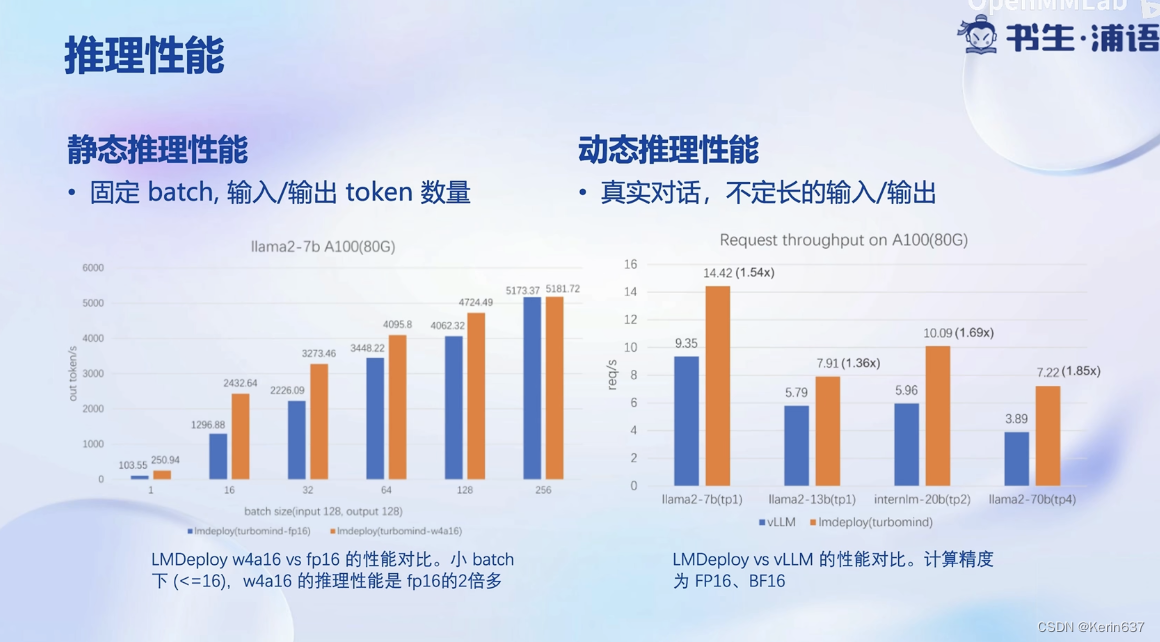
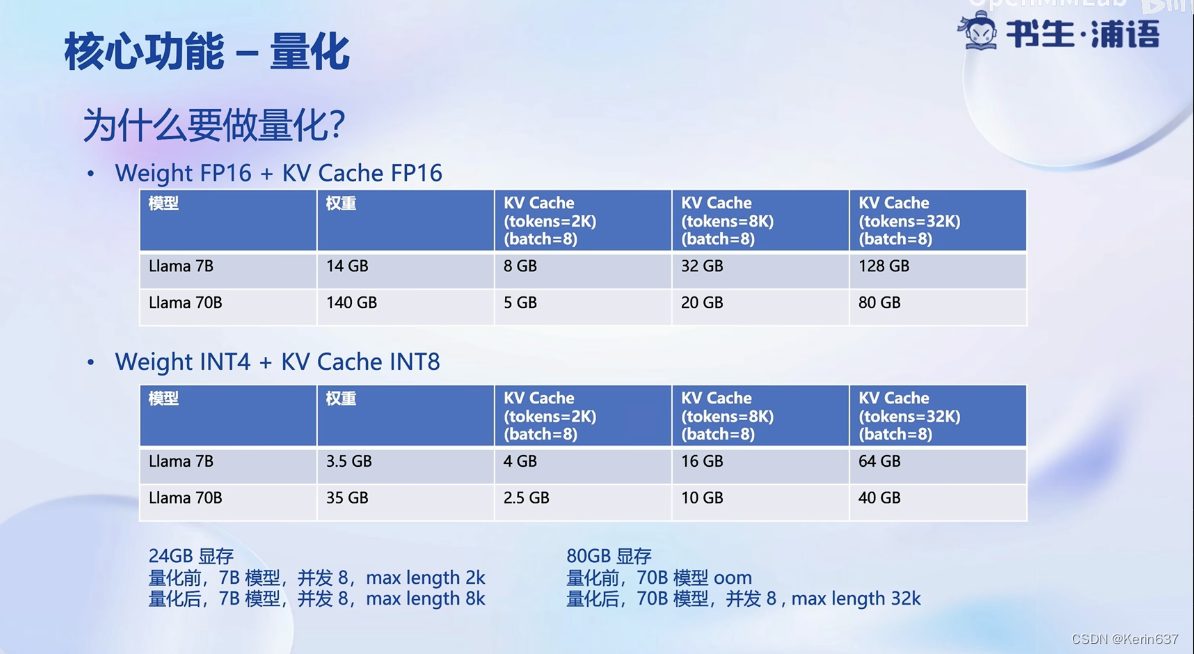
量化降低显存需求量,提高推理速度

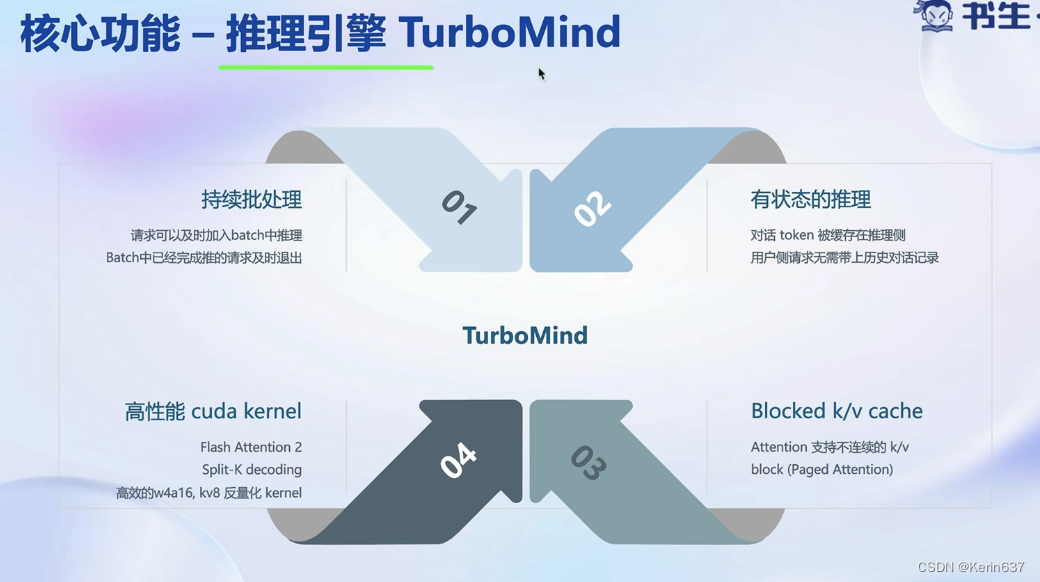
大语言模型推理是典型的访问密集型,因为是decoder only的架构,需要token by token的生成,因此需要频繁读取之前生成过的token。
这个量化只是在存储时做的, 在推理时还要反量化回FP16.
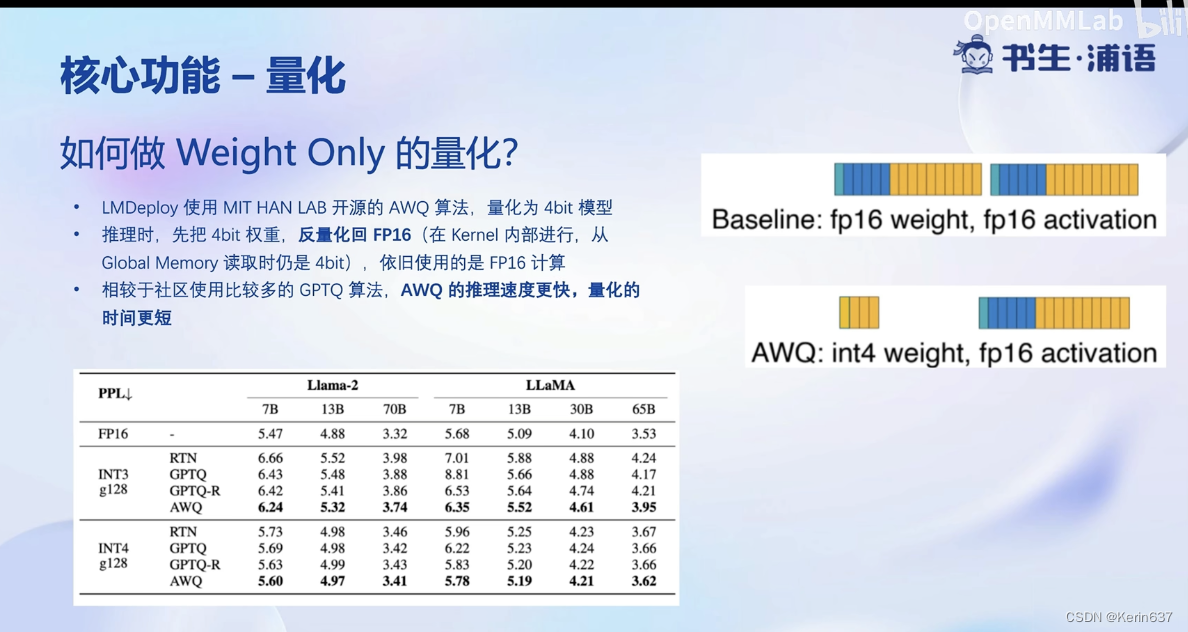
w4a16意思是参数4bit量化,激活时是16bit
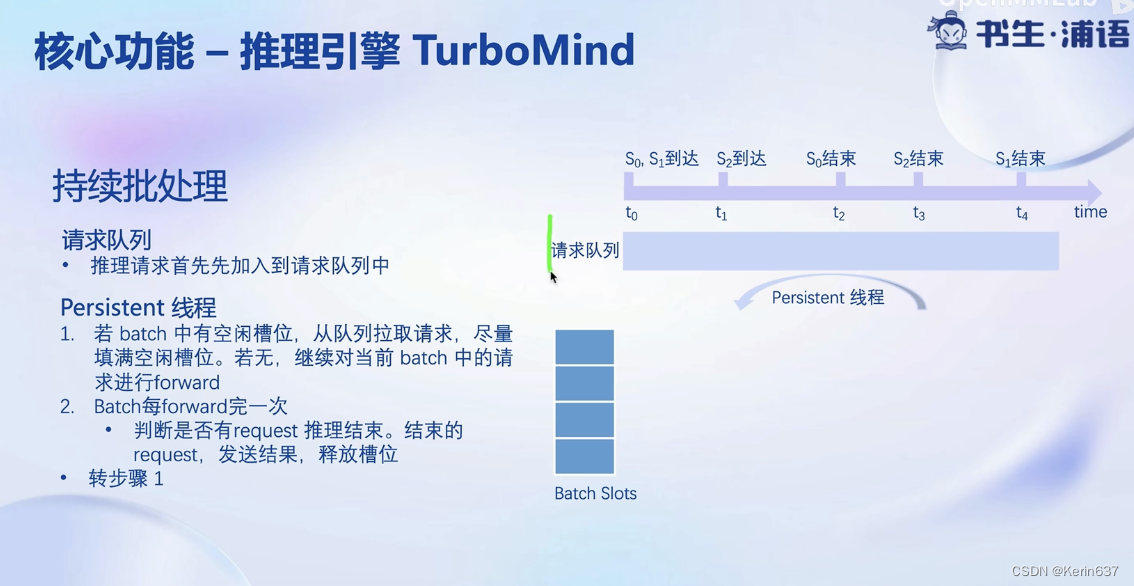
不用等一个batch的请求全部执行完才退出。
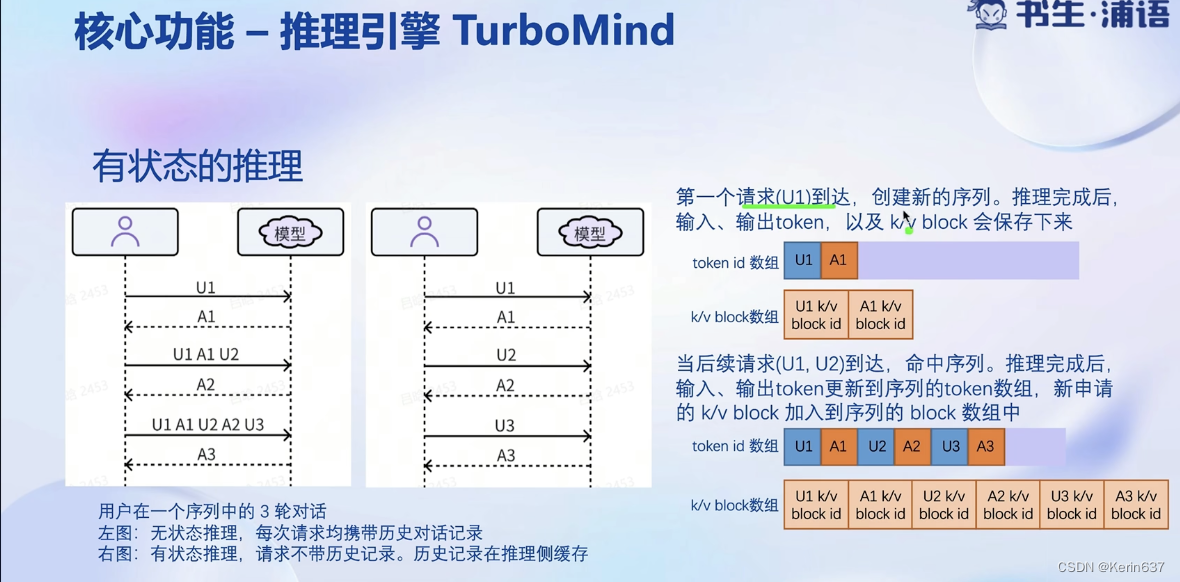
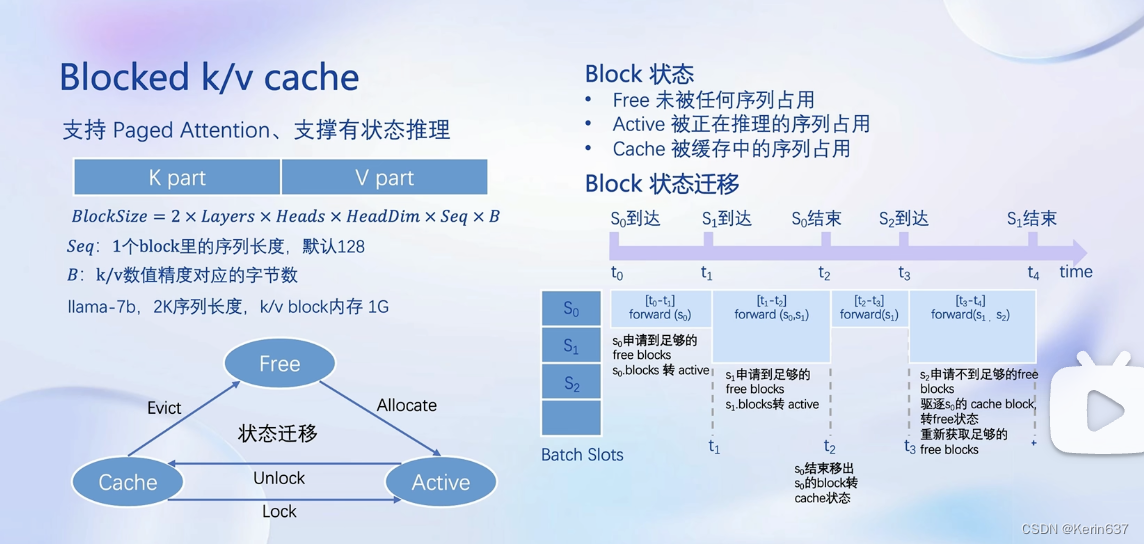
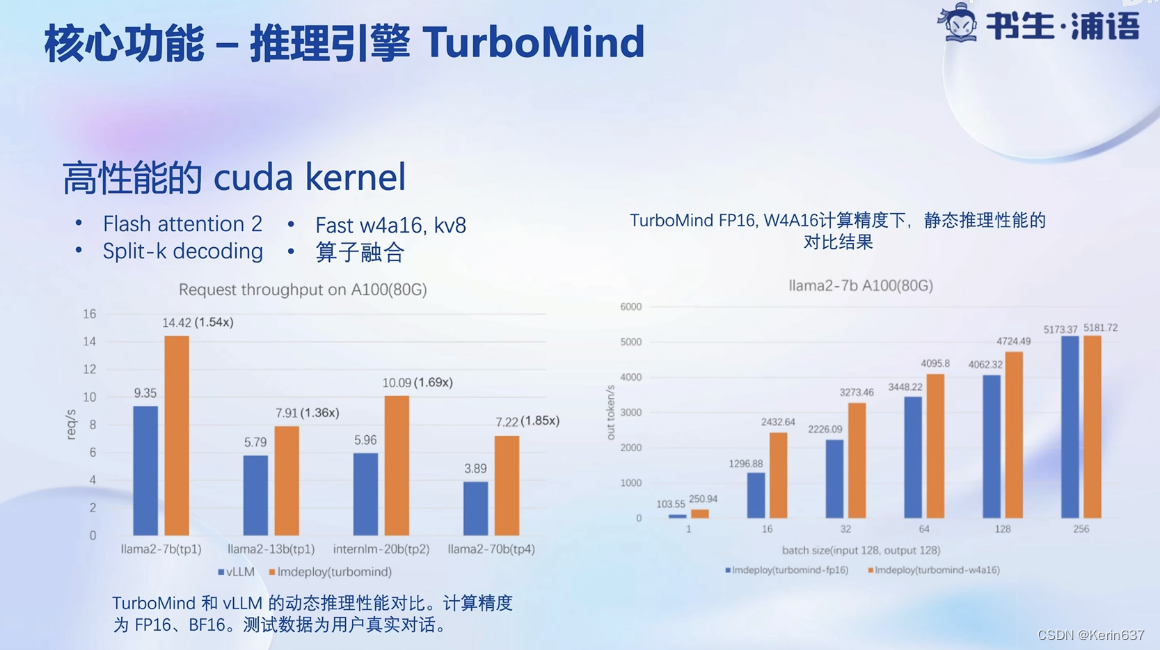
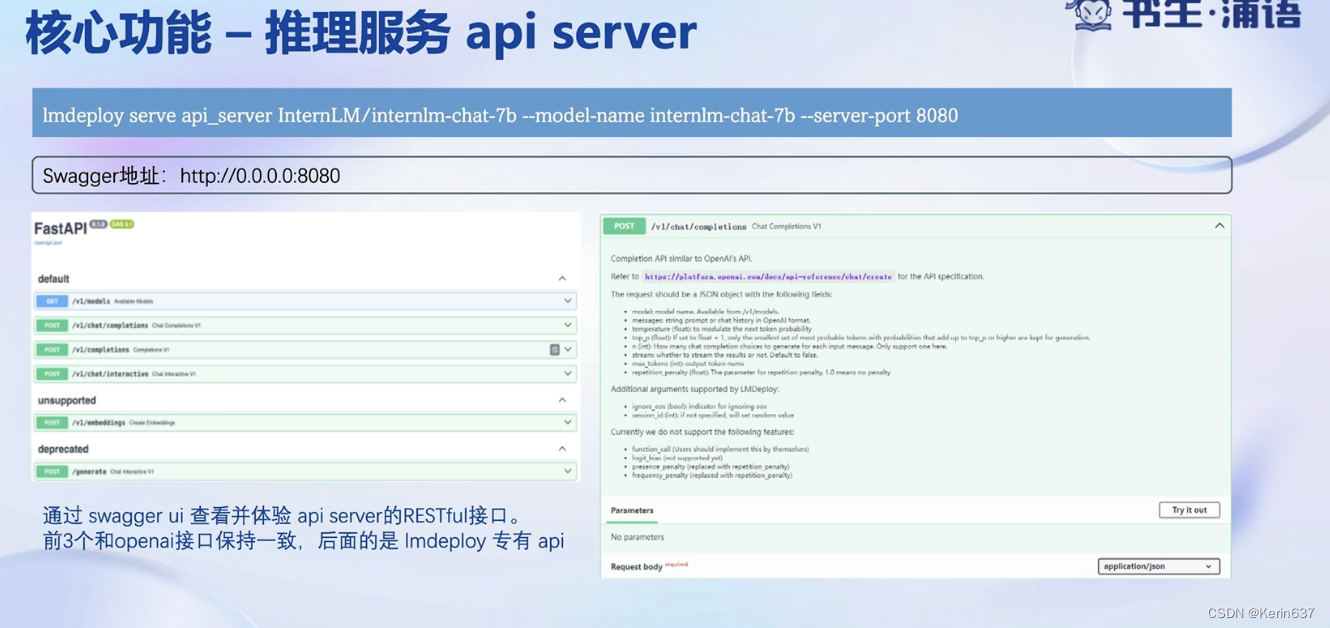
3.动手实践-安装、部署、量化

















 2494
2494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









