






前言:本文是河北工业大学(Hebut)计算机科学与技术专业编译原理的实验报告。公开实验报告是为了传承当时做实验前辈们的帮助,也是希望大家可以共同学习。慎抄,或者不建议抄袭!
实验三 语义分析程序设计与实现
一、实验目的
在实现词法、语法分析程序的基础上,编写相应的语义子程序,进行语义处理,加深对语法制导翻译原理的理解,进一步掌握将语法分析所识别的语法范畴变换为某种中间代码的语义分析方法,并完成相关语义分析器的代码开发。
二、基本实验内容及要求
对文法G2[<算术表达式>]中的产生式添加语义处理子程序,完成运算对象是简单变量和数值常数的四则运算的计值处理,将输入的四则运算转换为四元式形式的中间代码。
输入:包含测试用例(如由标识符、整型实型常数和+、−、、/、(、)构成的算术表达式)的源程序文件。
输出:将源程序转换为中间代码(四元式)形式表示,并将中间代码序列输出到文件中。若源程序中有错误,应指出错误信息。
要求:
1、结合实验一和实验二中的相关内容,完成语法制导翻译的程序设计。
2、对完成的编译系统进行全面测试,供测试的例子应包括符合语义规则的语句,以及分析程序能够判别的若干错例,并给出执行结果。例如,若输入文件中的内容为“123+ab6.78”,则输出四元式形式的中间代码为:
(*,ab,6.78,T1)
(+,123,T1,T2)
三、具体内容
(1)实验设计
对G2[E]文法建立翻译文法:
E → E ‘+’ T
{$$.PLACE = NewTemp();
GEN(+, $1.PLACE, $2.PLACE, $$.PLACE);}
| E ‘-’ T
{$$.PLACE = NewTemp();
GEN(-, $1.PLACE, $2.PLACE,$$.PLACE);}
| T
{$$.PLACE = $1.PLACE;}
T → T ‘’ F
{$$.PLACE = NewTemp();
GEN(, $1.PLACE, $2.PLACE, $$.PLACE);}
| T ‘/’ F
{$$.PLACE = NewTemp();
GEN(/, $1.PLACE, $2.PLACE, $$.PLACE);}
| F
{$$.PLACE = $1.PLACE;}
F → ‘(’ E ‘)’
{$$.PLACE = $2.PLACE;}
| i
{$$.PLACE = Entry($1);}
采用结构体,存储词法的类型和值,然后再语法中在结构体中加入状态号方便状态栈进行分析,在SLR(1)中一旦出现归约立马进入语义分析,执行语义子程序。
(2)程序代码
/*****************************************************************//**
* \file 语义分析程序.cpp
* \brief 编译原理实验三 语义分析程序设计与实现
*
* \author admin
* \date November 2022
*********************************************************************/
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<stack>
#include<iomanip>
#include<string>
#include <cstring>
#include"MyLex.h"
const int tempLength = 5;
struct TempWord
{
int num;
WORD word;
};
char* m;
TempWord tword;
WORD vol;
string Expr;
using namespace std;
string sGoto;
int step = 1;
stack<TempWord> status;/*状态栈*/
string word;
string value;
int NXQ = 0;/*四元式指针*/
int TempCnt = 1;/*临时变量计数器*/
string fPlace;
string tPlace;
string ePlace;
/*构造SLR(1)表,共有15个状态,需要构造ACTION表与GOTO表,然后用不同的函数处理*/
string Action[16][8] =
{
"s4","0","0","0","0","0","s5","0", //0
"0","0","s6","s7","0","0","0","acc", //1
"0","r3","r3","r3","s8","s9","0","r3", //2
"0","r6","r6","r6","r6","r6","0","r6", //3
"s4","0","0","0","0","0","s5","0", //4
"0","r8","r8","r8","r8","r8","0","r8", //5
"s4","0","0","0","0","0","s5","0", //6
"s4","0","0","0","0","0","s5","0", //7
"s4","0","0","0","0","0","s5","0", //8
"s4","0","0","0","0","0","s5","0", //9
"0","s15","s6","s7","0","0","0","0", //10
"0","r1","r1","r1","s8","s9","0","r1", //11
"0","r2","r2","r2","s8","s9","0","r2", //12
"0","r4","r4","r4","r4","r4","0","r4", //13
"0","r5","r5","r5","r5","r5","0","r5", //14
"0","r7","r7","r7","r7","r7","0","r7" //15
};
int Goto[16][3] =
{
1,2,3,
0,0,0,
0,0,0,
0,0,0,
10,2,3,
0,0,0,
0,11,3,
0,12,3,
0,0,13,
0,0,14,
0
};
char* NewTemp(void) /*产生一个临时变量*/
{
char* TempID = (char*)malloc(tempLength);
sprintf(TempID, "T%d", TempCnt++);
return TempID;
}
void reduction(int num)
{
switch (num)
{
case 1:// E→E+T
tPlace = status.top().word.token;
status.pop();
status.pop();
fPlace = status.top().word.token;
status.pop();
sGoto = "goto" + to_string(Goto[status.top().num][0]);
m = NewTemp();
Expr = "产生四元式( + ," + tPlace + ", " + fPlace + ", " + m + ")";
ePlace = m;
tword = { Goto[status.top().num][0] ,{"E",ePlace} };
status.push(tword);
break;
case 2:// E→E-T
tPlace = status.top().word.token;
status.pop();
status.pop();
fPlace = status.top().word.token;
status.pop();
sGoto = "goto" + to_string(Goto[status.top().num][0]);
m = NewTemp();
Expr = "产生四元式( - ," + ePlace + ", " + tPlace + ", " + m + ")";
ePlace = m;
tword = { Goto[status.top().num][0] ,{"E",ePlace} };
status.push(tword);
break;
case 3:// E→T
ePlace = status.top().word.token;
status.pop();
sGoto = "goto" + to_string(Goto[status.top().num][0]);
tword = { Goto[status.top().num][0] ,{"E",ePlace} };
status.push(tword);
Expr = "E.PLACE = " + ePlace;
break;
case 4:// T→T*F
tPlace = status.top().word.token;
status.pop();
status.pop();
fPlace = status.top().word.token;
status.pop();
sGoto = "goto" + to_string(Goto[status.top().num][1]);
m = NewTemp();
Expr = "产生四元式( * ," + tPlace + ", " + fPlace + ", " + m + ")";
tPlace = m;
tword = { Goto[status.top().num][1] ,{"T",tPlace} };
status.push(tword);
break;
case 5:// T→T/F
tPlace = status.top().word.token;
status.pop();
status.pop();
fPlace = status.top().word.token;
status.pop();
sGoto = "goto" + to_string(Goto[status.top().num][1]);
m = NewTemp();
Expr = "产生四元式( / ," + tPlace + "," + fPlace + "," + m + ")";
tPlace = m;
tword = { Goto[status.top().num][1] ,{"T",tPlace} };
status.push(tword);
break;
case 6:// T→F
tPlace = status.top().word.token;
status.pop();
sGoto = "goto" + to_string(Goto[status.top().num][1]);
tword = { Goto[status.top().num][1] ,{"T",fPlace} };
status.push(tword);
Expr = "T.PLACE = " + tPlace;
break;
case 7:// F→(E)
status.pop();
fPlace = status.top().word.token;
status.pop(); status.pop();
sGoto = "goto" + to_string(Goto[status.top().num][2]);
tword = { Goto[status.top().num][2] ,{"F",fPlace} };
status.push(tword);
Expr = "F.PLACE = " + fPlace;
break;
case 8:// F→i
fPlace = status.top().word.token;
status.pop();
sGoto = "goto" + to_string(Goto[status.top().num][2]);
tword = { Goto[status.top().num][2] ,{"F",fPlace} };
status.push(tword);
Expr = "F.PLACE = " + fPlace;
break;
default:
break;
}
}
string outStack()
{
string s = "";
string c;
TempWord val;
stack <TempWord> temp;
while (!status.empty())
{
val = status.top();
temp.push(val);
c = to_string(val.num) + " ";
s += c;
status.pop();
}
//复原
while (!temp.empty())
{
val = temp.top();
temp.pop();
status.push(val);
}
return s;
}
int getChar(string word)
{
if (word == "LP")return 0;
if (word == "RP")return 1;
if (word == "PL")return 2;
if (word == "MI")return 3;
if (word == "MU")return 4;
if (word == "DI")return 5;
if (word == "ID" || word == "INT" || word == "REAL")return 6;
if (word == "#")return 7;
}
void out()
{
cout << std::left << setw(8) << step << std::right << setw(30) << outStack();
cout << std::left << setw(12) << word << setw(10) << value << setw(10)<<sGoto;
step++; sGoto = "";
if (value[0] != 'r')
{
cout << endl;
}
}
void scanner(FILE* fp)
{
int num;
vol = myLex(fp);
word = vol.value;
while (value != "acc")
{
value = Action[status.top().num][getChar(word)];
out();
if (value.substr(0, 1) == "r")
{
num = stoi(value.substr(1));
reduction(num);
cout << std::left<<setw(10)<<Expr << endl;
}
else if (value.substr(0, 1) == "s")
{
num = stoi(value.substr(1));
tword = { num,vol };
status.push(tword);
vol = myLex(fp);
word = vol.value;
}
else if (value == "0")
{
cout << "语法错误:error: in (" << lines << ")lines " << word << " 处出现错误!" << endl;
exit(0);
}
}
cout << "RIGHT" << endl;
}
int main()
{
char fileName[20];/*待查询的文件名*/
cout << "请输入要进行词法分析的文件名:";
cin >> fileName;
FILE* fpInput = fopen(fileName, "r");
TempWord start = { 0,{"#",""} };
status.push(start);
cout << std::left << setw(8) << "步骤数" << setw(30) << "状态栈" << setw(12) << "待分析符号" << setw(10) << "当前操作" << endl;
scanner(fpInput);
fclose(fpInput);
}
/*****************************************************************//*
* \file 源.cpp
* \brief 编译原理实验一 词法分析程序设计与实现
*
* \author admin
* \date October 2022
*********************************************************************/
#define _CRT_SECURE_NO_WARNINGS
#include<fstream>
#include<string>
#include"number.h"
using namespace std;
const int MAX_KEYWORD_NUMBER = 40; /*关键字的数量*/
const char* KEY_WORD_END = "Waiting for extending"; /*关键字结束标记*/
const char* KEY_WORD_START = "Waiting for identifying"; /*关键字结束标记*/
const char* Keyword[MAX_KEYWORD_NUMBER] = { KEY_WORD_START,"if","else","for","do","begin","end",KEY_WORD_END };/*关键词数组*/
const char* Value[MAX_KEYWORD_NUMBER] = { KEY_WORD_START,"IF","ELSE","FOR","DO","BEGIN","END","ID","INT","REAL","LT","LE","EQ","NE","GT","GE","IS","PL","MI","MU","DI","AND","OR","NOT","OCT","HEX","CHAR","STR","LP","RP","#",KEY_WORD_END };/*助记符数组*/
char TOKEN[30];/*存放单词词文*/
int lines = 1;/*记录当前运行到的行数*/
struct WORD
{
string value;
string token;
};
/**
* \brief 显示错误信息
* \param s 错误信息
*/
void report_error(string s)
{
cout << "词法错误:error: in (" << lines << ")lines, " << s << endl;
}
/**
* \brief 以token查询关键字表
* \param token 待查字符串
* \return 如果为关键字,返回所处位置,没有找到返回0
*/
int lookUp(char* token)
{
int i = 1;
while (strcmp(Keyword[i], KEY_WORD_END) != 0)
{
if (strcmp(token, Keyword[i]) == 0)return i;
i++;
}
return 0;
}
/**
* \brief 输出二元式
* \param a 单词的value值
* \param token 有值单词的值
*/
WORD out(int a, const char* token)
{
WORD word = { Value[a],token };
return word;
}
/**
* \brief 扫描文件字符并拼接token进行查询
* \param fp 文件指针
*/
WORD scanner_example(FILE* fp)
{
char ch; int i, c;
while ((ch = fgetc(fp)) != EOF)
{
if (ch == ' ' || ch == '\t')//不识别空格和tab
{
ch = fgetc(fp);
fseek(fp, -1, SEEK_CUR);
}
else if (ch == '\n')//不识别换行
{
lines++;
}
else if (isalpha(ch)) /*it must be a identifer!*/
{
TOKEN[0] = ch; ch = fgetc(fp); i = 1;
while (isalnum(ch))
{
TOKEN[i] = ch; i++;
ch = fgetc(fp);
}
TOKEN[i] = '\0';
if (ch != EOF)
{
fseek(fp, -1, SEEK_CUR); /* retract*/
}
c = lookUp(TOKEN);
if (c == 0) return out(7, TOKEN);
else if (c == 6)return out(6, " ");
else return out(c, " ");
}
else if (isdigit(ch) || ch == '.')
{
if (ch == '0')
{
ch = fgetc(fp);
if (ch >= '0' && ch < '8')
{
TOKEN[0] = '0'; i = 1;
while (isdigit(ch))
{
TOKEN[i] = ch; i++;
ch = fgetc(fp);
}
TOKEN[i] = '\0';
return out(24, TOKEN);
}
else if (ch == 'x')
{
TOKEN[0] = '0'; TOKEN[1] = 'x';
ch = fgetc(fp); i = 2;
while (ch >= '.' && ch <= '9' || ch >= 'a' && ch <= 'f' || ch >= 'A' && ch <= 'F')
{
TOKEN[i] = ch; i++;
ch = fgetc(fp);
}
TOKEN[i] = '\0';
return out(25, TOKEN);
}
else if (ch != '.' && !isdigit(ch))
{
return out(8, "0\0");
}
else
{
fseek(fp, -1, SEEK_CUR); /* retract*/
}
}
else if (isdigit(ch) || ch == '.')
{
int flag = getFCON(fp, TOKEN, ch);
if (!flag)report_error("数值错误!");
return out(flag, TOKEN);
}
}
else
{
switch (ch)
{
case ':':ch = fgetc(fp);
if (ch == '=')out(16, " ");
break;
case '<': ch = fgetc(fp);
if (ch == '=')out(11, " ");
else if (ch == '>') out(13, " ");
else
{
fseek(fp, -1, SEEK_CUR);
out(10, " ");
}
break;
case '=': out(12, " "); break;
case '>': ch = fgetc(fp);
if (ch == '=')out(15, " ");
else
{
fseek(fp, -1, SEEK_CUR);
out(14, " ");
}
break;
case'+':return out(17, " "); break;
case'-':return out(18, " "); break;
case'*':return out(19, " "); break;
case'/':
//不识别注释
ch = fgetc(fp);
if (ch == '/')//单行注释
{
while (ch != '\n')ch = fgetc(fp);
lines++;
ch = fgetc(fp);
fseek(fp, -1, SEEK_CUR);
}
else if (ch == '*')//多行注释
{
while (true)
{
ch = fgetc(fp);
if (ch == '\n')
{
lines++; ch = fgetc(fp);
}
if (ch == '*')
{
ch = fgetc(fp);
if (ch == '/')
{
ch = fgetc(fp);
if (ch == '\n')
{
lines++; ch = fgetc(fp);
}
break;
}
else fseek(fp, -1, SEEK_CUR);
}
}
}
else
{
fseek(fp, -1, SEEK_CUR);
return out(20, " ");
}
break;
case'&':ch = fgetc(fp);
if (ch == '&')out(21, " ");
else report_error("逻辑运算出错!"); break;
case'|':ch = fgetc(fp);
if (ch == '|')out(22, " ");
else report_error("逻辑运算出错!"); break;
case'!':out(23, " "); break;
case'(':return out(28, " "); break;
case')':return out(29, " "); break;
case '\'':
{
ch = fgetc(fp);
TOKEN[0] = ch;
if ((ch = fgetc(fp) != '\''))
{
report_error("字符常量出错!");
}
else
{
TOKEN[1] = '\0';
}
out(26, TOKEN);
break;
}
case '\"':
{
ch = fgetc(fp); i = 0;
while (ch != '\"')
{
TOKEN[i] = ch; i++;
ch = fgetc(fp);
}
TOKEN[i] = '\0';
out(27, TOKEN);
break;
}
default: report_error("运算符号出错!"); break;
}
}
}
if (ch == EOF)
{
return out(30, " ");
}
}
WORD myLex(FILE* fp)
{
return scanner_example(fp);
}
#include<iostream>
#include<math.h>
#include<string>
using namespace std;
#define ClassNo 100 //Suppose the class of number is 100
#define EndState -1
#define ErrorState -2
enum
{
DIGIT = 1, POINT, OTHER, POWER, PLUS, MINUS
};
int w, n, p, e, d;
int Class;
int ICON;
long double FCON;
static int CurrentState;
int GetChar(void);
int EXCUTE(int, int);
int GetChar(char c)
{
if (isdigit(c))
{
d = c - '0';
return DIGIT;
}
if (c == '.')return POINT;
if (c == 'E' || c == 'e')return POWER;
if (c == '+')return PLUS;
if (c == '-')return MINUS;
return OTHER;
}
int EXCUTE(int state, int symbol)
{
switch (state)
{
case 0:
switch (symbol)
{
case DIGIT:
n = 0; p = 0; e = 1; w = d; CurrentState = 1; Class = ClassNo; break;
case POINT:
n = 0; p = 0; e = 1; w = 0; CurrentState = 3; Class = ClassNo; break;
default:
CurrentState = EndState;
}
break;
case 1:
switch (symbol)
{
case DIGIT:
w = w * 10 + d; break; //CurrentState = 1
case POINT:
CurrentState = 2; break;
case POWER:
CurrentState = 4; break;
default:
ICON = w;
CurrentState = EndState;
}
break;
case 2:
switch (symbol)
{
case DIGIT:
n++; w = w * 10 + d; break;
case POWER:
CurrentState = 4; break;
default:
FCON = w * pow(10, e * p - n);
CurrentState = EndState;
}
break;
case 3:
switch (symbol)
{
case DIGIT:
n++; w = w * 10 + d; CurrentState = 2; break;
default:
CurrentState = ErrorState;
}
break;
case 4:
switch (symbol)
{
case DIGIT:
p = p * 10 + d; CurrentState = 6; break;
case MINUS:
e = -1; CurrentState = 5; break;
case PLUS:
CurrentState = 5; break;
default:
CurrentState = ErrorState;
}
break;
case 5:
switch (symbol)
{
case DIGIT:
p = p * 10 + d; CurrentState = 6; break;
default:
CurrentState = ErrorState;
}
break;
case 6:
switch (symbol)
{
case DIGIT:
p = p * 10 + d; break;
default:
FCON = w * pow(10, e * p - n);
CurrentState = EndState;
}
break;
}
return CurrentState;
}
int getFCON(FILE* fp, char* token, char& ch)
{
char temp[30];
int i = 0, j = 0, flag = 8;
CurrentState = 0;
while (CurrentState != EndState)
{
token[i] = ch; i++;
if (ch == 'e' || ch == 'E' || ch == '.')flag = 9;
EXCUTE(CurrentState, GetChar(ch));
if (CurrentState == ErrorState)
{
return 0;
}
if (CurrentState != EndState)
{
ch = fgetc(fp);
}
}
if (ch != EOF)
{
fseek(fp, -1, SEEK_CUR);
}
if (flag == 9)sprintf(temp, "%g", FCON);
else sprintf(temp, "%d", ICON);
strcpy(token, temp);
return flag;
}
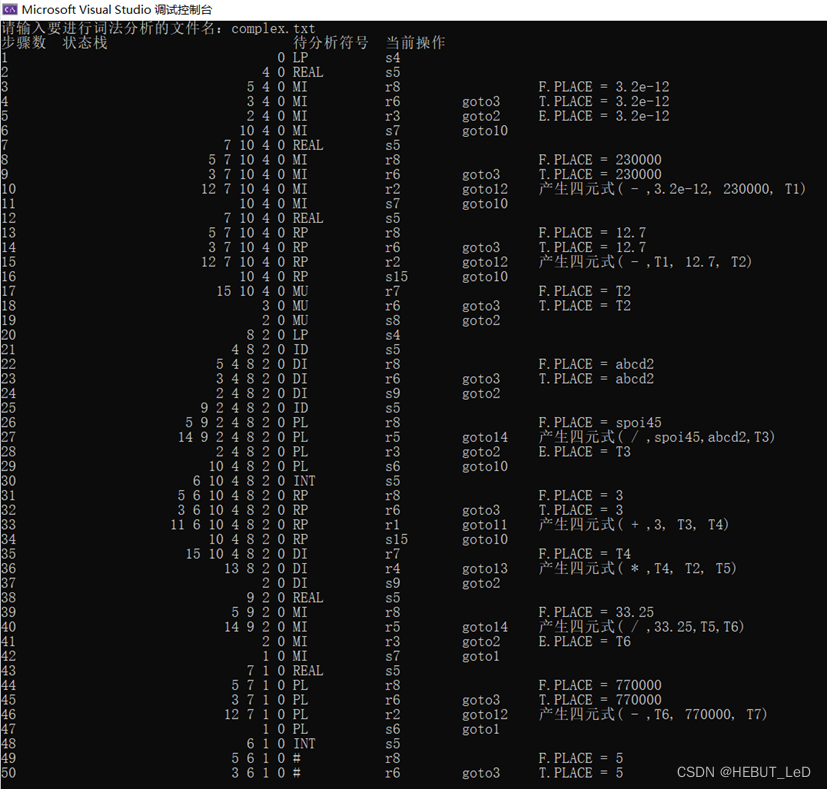
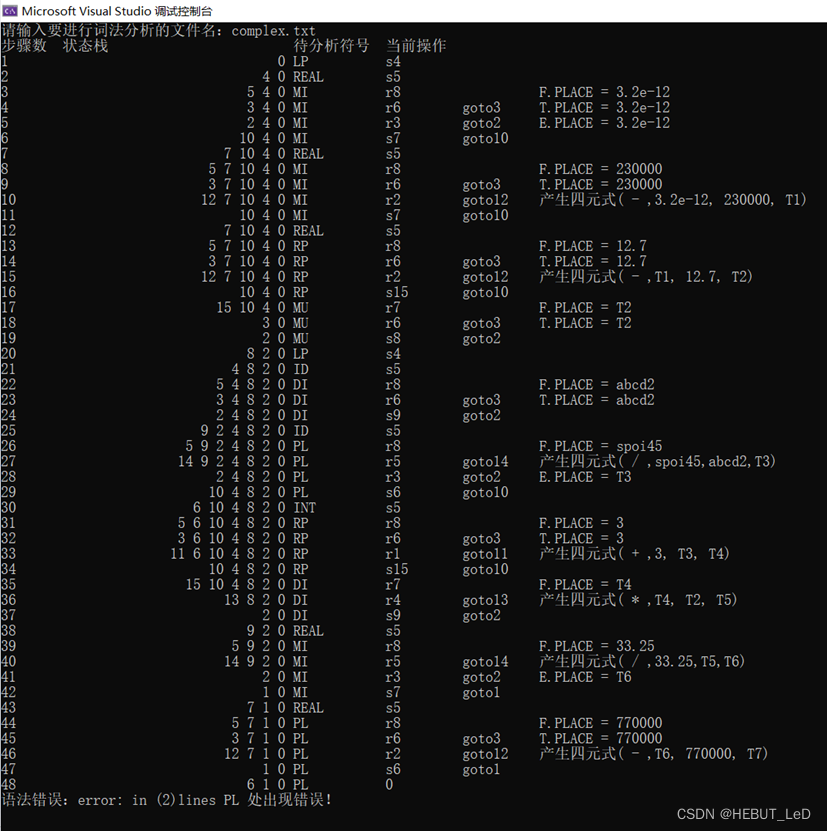
(3)实验结果分析
正确示例:

错误示例:














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









