







Wide&Deep模型是由单层的 Wide部分和多层的 Deep部分组成的混合模型。 其中,Wide部分的主要作⽤是让模型具有较强的“记忆能⼒”;Deep部分的主要作⽤是让模型具有“泛化能⼒”,正是这样的结构特点,使模型兼具了逻辑回归和深度神经⽹络的 优点——能够快速处理并记忆⼤量历史⾏为特征,并且具有强⼤的表 达能⼒。
关于“记忆能力”
“记忆能⼒”可以被理解为模型直接学习并利⽤历史数据中物品或 者特征的“共现频率”的能⼒。⼀般来说,协同过滤、逻辑回归等简单 模型有较强的“记忆能⼒”。由于这类模型的结构简单,原始数据往往可以直接影响推荐结果,产⽣类似于“如果点击过A,就推荐B”这类规 则式的推荐,这就相当于模型直接记住了历史数据的分布特点,并利 ⽤这些记忆进⾏推荐。
关于“泛化能力”
“泛化能⼒”可以被理解为模型传递特征的相关性,以及发掘稀疏甚⾄从未出现过的稀有特征与最终标签相关性的能⼒。
深度神经⽹络通过特征的多次⾃动组合, 可以深度发掘数据中潜在的模式,即使是⾮常稀疏的特征向量输⼊, 也能得到较稳定平滑的推荐概率,这就是简单模型所缺乏的“泛化能 ⼒”。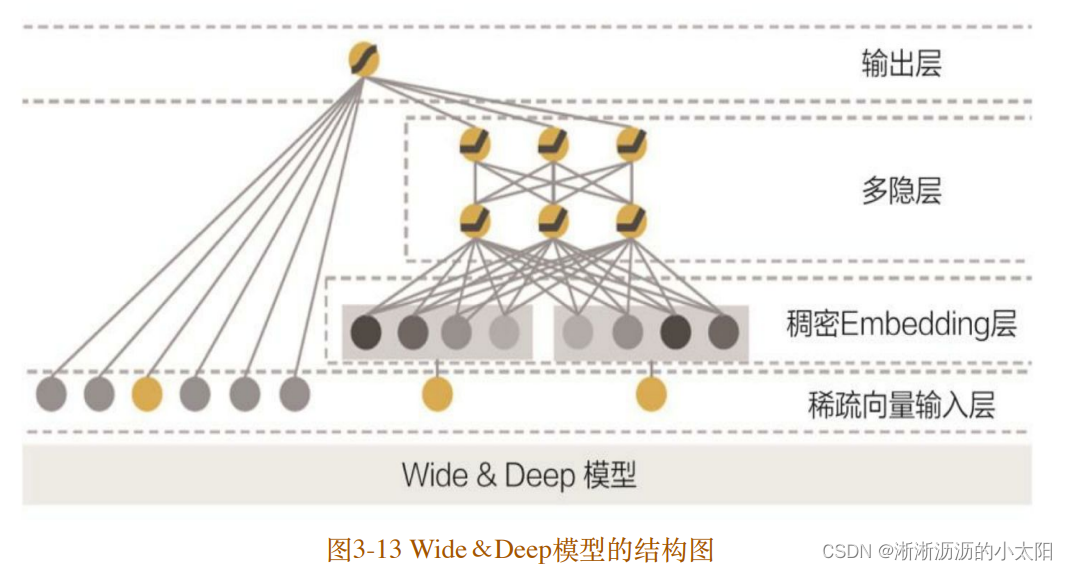
Wide&Deep模型把单输⼊层的Wide部分与由Embedding层和多隐 层组成的Deep部分连接起来,⼀起输⼊最终的输出层。单层的Wide部 分善于处理⼤量稀疏的 id类特征;Deep部分利⽤神经⽹络表达能⼒强 的特点,进⾏深层的特征交叉,挖掘藏在特征背后的数据模式。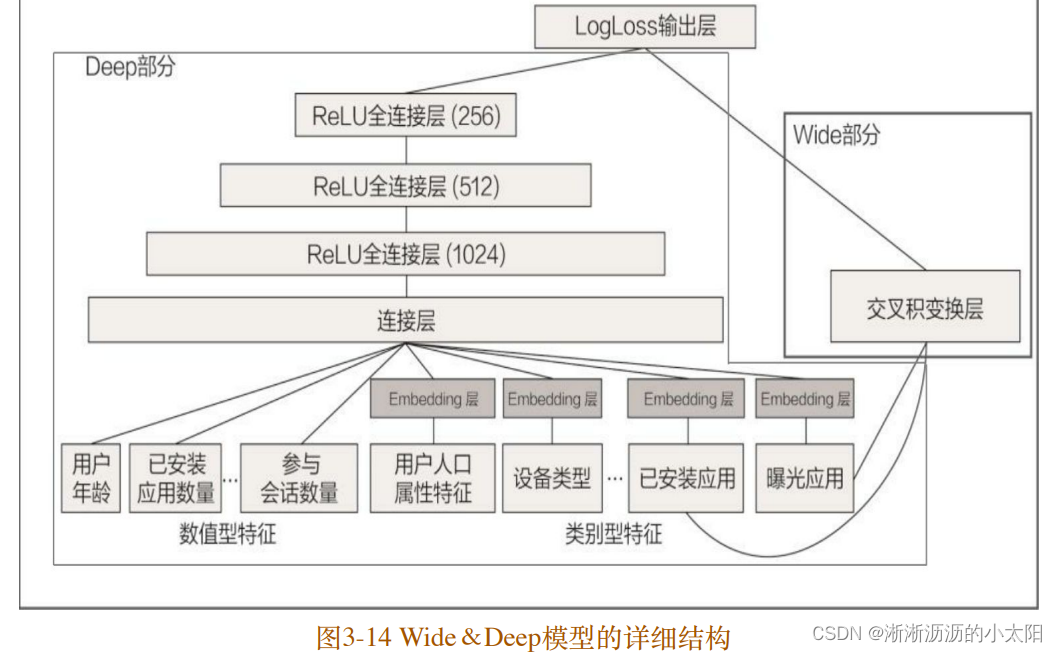
Deep 部分的输⼊是全量的特征向量,包括⽤户年龄(Age)、已 安装应⽤数量(#App Installs)、设备类型(Device Class)、已安装 应⽤(User Installed App)、曝光应⽤(Impression App)等特征。已 安装应⽤、曝光应⽤等类别型特征,需要经过Embedding层输⼊连接层 (Concatenated Embedding),拼接成1200维的Embedding向量,再依 次经过3层ReLU全连接层,最终输⼊LogLoss输出层。
Wide 部分的输⼊仅仅是已安装应⽤和曝光应⽤两类特征,其中已 安装应⽤代表⽤户的历史⾏为,⽽曝光应⽤代表当前的待推荐应⽤。 选择这两类特征的原因是充分发挥Wide部分“记忆能⼒”强的优势。
Wide 部分组合“已安装应⽤”和“曝光应⽤”两个特征的函数被称为 交叉积变换(Cross Product Transformation)函数,其形式化定义如下式所⽰。

wide部分和deep部分使用logistics loss连接在一起,通过bp联合训练,而不是单独训练然后做ensemble。loss直接把wide部分的loss和deep部分的loss相加

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









