






摘要:
关系抽取(RelationExtraction,RE)已经从句子级发展到文档级,需要聚集文档信息并使用实体和提及进行推理。现有研究将具有相似表示的实体节点和提及节点放在文档级图中,其复杂的边会产生冗余信息。此外,现有的研究只关注实体级推理路径,没有考虑跨句实体间的全局交互作用。为此,提出了一种基于GRAPH信息聚合和跨句推理网络(GRACR)的文档级RE模型。通过构造简化的文档级图对文档中所有提及和句子的语义信息进行建模,并通过设计实体级图对长距离跨句实体对之间的关系进行挖掘。实验结果表明,GRACR在两个公共文档级RE数据集上取得了良好的性能。该方法在提取跨句实体对的潜在关系时特别有效。代码可在GitHub - UESTC-LHF/GRACR上获得。
Introduction:
Relation extraction (RE) is to identify the semantic relation between a pair of named entities in text. 关系抽取( RE )是识别文本中一对命名实体之间的语义关系。
Document-level RE requires the model to extract relations from the document and faces some intractable challenges:
- a document contains multiple sentences, thus relation extraction task needs to deal with more rich and complex semantic information.文档中包含多个句子,关系抽取任务需要处理更加丰富和复杂的语义信息。
- subject and object entities in the same triple may appear in different sentences, and some entities have aliase, which are often named entity mentions. Hence, the information utilized by document-level RE may not come from a single sentence. 同一个三元组中的主语和宾语实体可能出现在不同的句子中,并且有些实体存在别名,这些别名往往是命名实体指称。因此,文档级RE所利用的信息可能不是来自单个句子。
- there may be interactions among different triples. Extracting the relation between two entities from different triples requires reasoning with contextual features.不同三元组之间可能存在交互作用。从不同的三元组中抽取两个实体之间的关系需要结合上下文特征进行推理。
In this paper, we propose GRACR, a graph information aggregation and logical crosssentence reasoning network, to better cope with document-level RE. GRACR applies a document-level graph and attention mechanism to model the semantic information of all mentions and sentences in a document. It also constructs an entity-level graph to utilize the interaction among different entities to reason the relations. Finally, it uses an attention mechanism to fuse document embedding, aggregation, and inference information to help identify relations. Experimental results show that our model achieves excellent performance on DocRED and CDR.
本文提出了GRACR,一种图信息聚合和逻辑跨句推理网络,以更好地应对文档级RE。GRACR应用文档级图和注意力机制对文档中所有提及和句子的语义信息进行建模。它还构建了一个实体级图来利用不同实体之间的交互来推理关系。最后,它使用注意力机制融合文档嵌入、聚合和推理信息来帮助识别关系。实验结果表明,我们的模型在DocRED和CDR上取得了优异的性能。
First, how to integrate rich semantic information of a document to obtain entity representations?
1、We construct a document-level graph to integrate complex semantic information,我们构建了一个文档级图来整合复杂的语义信息。which is a heterogeneous graph containing mention nodes and sentence nodes.这是一个包含提及节点和句子节点的异构图。 but not entity nodes, which avoids introducing redundant information caused by repeated node representations.
2、Representations of mention nodes and sentence nodes are computed by the pretrained language model BERT。提及节点和句子节点的表示由预训练语言模型BERT计算。The built document-level graph is input into the R-GCNs, a relational graph neural network, to make nodes contain the information of their neighbor nodes.将构建的文档级图输入到关系图神经网络R - GCNs中,使节点包含其邻居节点的信息。
3、representations of entities are obtained by performing logsumexp pooling operation on representations of mention nodes. In previous methods, representations of entity nodes are obtained from representations of mention nodes.实体的表示通过对提及节点的表示执行logumexp池化操作获得。在以往的方法中,实体节点的表示是由提及节点的表示得到的。
4、Hence putting them in the same graph will introduce redundant information and reduce discriminability. Unlike previous document-level graph construction, our document-level graph contains only sentence nodes and mention nodes to avoid redundant information caused by repeated node representations.因此将它们放在同一个图中会引入冗余信息,降低判别性。与以往的文档级图构建不同,我们的文档级图只包含句子节点和提及节点,以避免重复节点表示造成的冗余信息。
how to use connections between entities for reasoning?
1、we exploit connections between entities and propose an entity-level graph for reasoning.我们利用实体之间的连接,提出了一个实体级的图来进行推理。
2、The entity-level graph is built by the positional connections between sentences and entities to make full use of cross-sentence information. It connects long-distance crosssentence entity pairs.实体级图是通过句子和实体之间的位置关系构建的,以充分利用跨句子信息。它连接远距离的跨句实体对。
3、Through the learning of GNN, each entity node can aggregate the information of its most relevant entity nodes, which is beneficial to discover potential relations of long-distance cross-sentence entity pairs.通过GNN的学习,每个实体节点可以聚合其最相关实体节点的信息,有利于发现长距离跨句实体对的潜在关系。An attention mechanism is applied to fuse document embedding, aggregation, and inference information to extract relations of entity pairs.

Methodology:
GRACR mainly consists of 4 modules: encoding module, document-level graph aggregation module, entity-level graph reasoning module, and classification module.GRACR主要包括4个模块:编码模块、文档级图聚合模块、实体级图推理模块和分类模块。
1、in encoding module, we use a pre-trained language model such as BERT to encode the document. 在编码模块中,我们使用BERT等预训练语言模型对文档进行编码。

We use the representations of mention nodes after graph convolution to compute the preliminary representation of entity node ei by logsumexp pooling as epre i , which incorporates the semantic information of ei throughout the whole document.
2、in document-level graph aggregation module, we construct a heterogeneous graph containing mention nodes and sentence nodes to integrate rich semantic information of a document.在文档级图聚合模块中,我们构建了一个包含提及节点和句子节点的异构图来整合文档的丰富语义信息
To integrate rich semantic information of a document to obtain entity representations, we construct a document-level graph (Dlg) based on H.为了整合文档丰富的语义信息以获得实体表示,我们基于H构建了文档级图( Dlg )。
Dlg has two different kinds of nodes:
- Sentence nodes:which represent sentences in D. The representation of a sentence node si is obtained by averaging the representations of contained words.
- Mention nodes:which represent mentions in D. The representation of a mention node mi is achieved by averaging the representations of words that make up the mention.
three types of edges in Dlg:
- Mention-mention edge:To exploit the co-occurrence dependence between mention pairs, we create a mention-mention edge. Mention nodes of two different entities are connected by mention-mention edges if their mentions co-occur in the same sentence.
- Mention-sentence edge:Mention-sentence edge is created to better capture the context information of mention. Mention node and sentence node are connected by mention-sentence edges if the mention appears in the sentence.
- Sentence-sentence edge:All sentence nodes are connected by sentence-sentence edges to eliminate the effect of sentences sequence in the document and facilitate intersentence interactions.
Then, we use an L-layer stacked R-GCNs to learn the document-level graph. R-GCNs can better model heterogeneous graph that has various types of edges than GCN.
3、in entity-level graph reasoning module, we also propose a graph for reasoning to discover potential relations of long-distance and cross-sentence entity pairs.在实体级图推理模块中,我们还提出了一个用于推理的图,以发现远距离和跨句子实体对的潜在关系。
Elg contains only one kind of node: Entity node
There are two kinds of edges in Elg:
- Intra-sentence edge:Two different entities are connected by an intra-sentence edge if their mentions co-occur in the same sentence.
- Logical reasoning edge:If the mention of entity ek has co-occurrence dependencies with mentions of other two entities in different sentences, we suppose that ek can be used as a bridge between entities.
Similar to Dlg, we apply an L-layer stacked R-GCNs to convolute the entity-level graph to get the reasoned representation of entity.
In order to better integrate the information of entities, we employ the attention mechanism to fuse the aggregated information, the reasoned information, and the initial information of entity to form the final representation of entity.
4、in classification module, we merge the context information of relation representations obtained by self-attention to make final relation prediction.在分类模块中,我们将自注意力得到的关系表示的上下文信息进行融合,进行最终的关系预测。
- concatenate entity final representations and relative distance representations to represent one entity pair.
- concatenate the representations to form the target relation representation.
- employ self-attention to capture context relation representations, which can help us exploit the topic information of the document.
- use a feed-forward neural network (FFNN) on the target relation representation or and the context relation representation for prediction.
- transform the multi-classification problem into multiple binary classification problems, since an entity pair may have different relations.
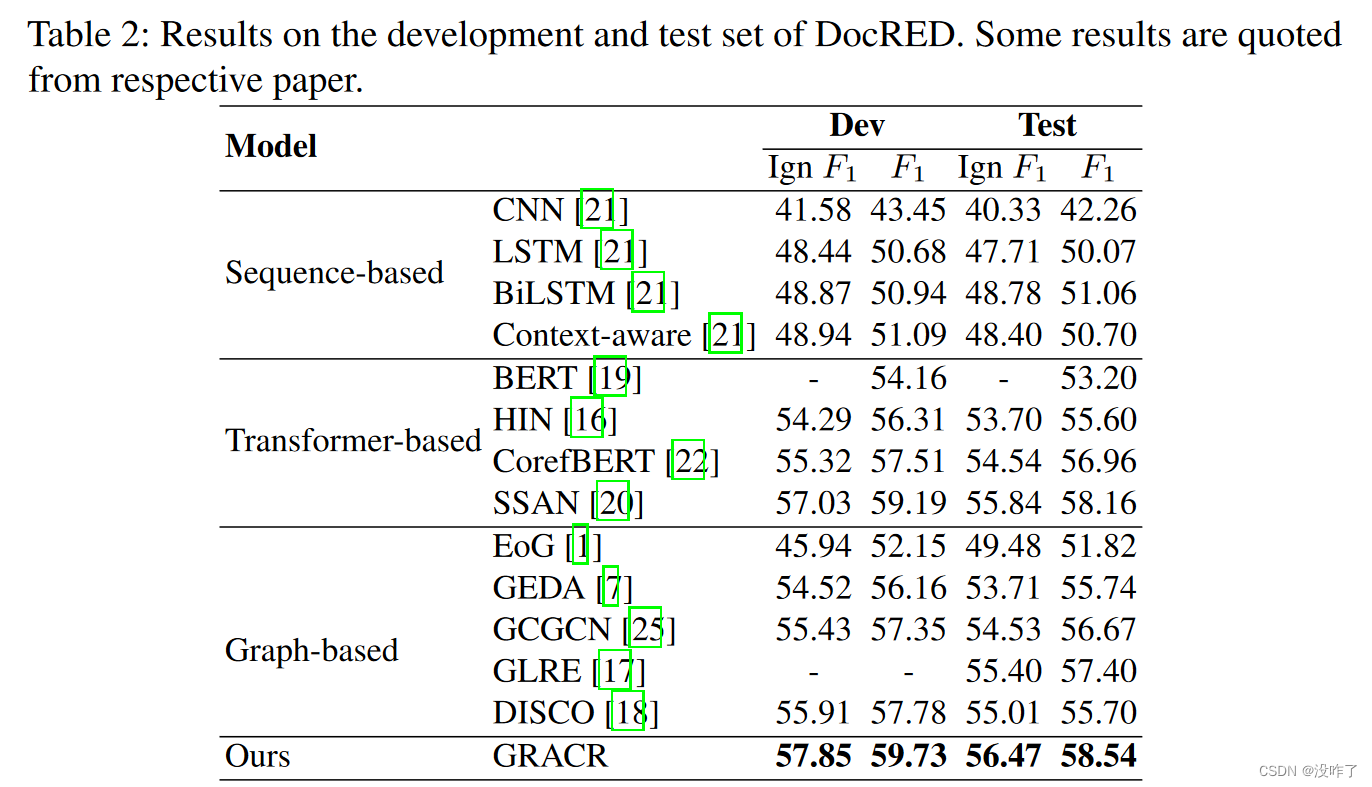
Experiments and Results:
1、Dataset:DocRED and CDR dataset. CDR contains 1,500 PubMed abstracts about chemical and disease with 3,116 relational facts.
2、Experiment Settings and Evaluation Metrics:To implement our model, we choose uncased BERT-base as the encoder on DocRED and set the embedding dimension to 768. For CDR dataset, we pick up BioBERT-Base v1.1, which re-trained the BERT-base-cased model on biomedical corpora. All hyper-parameters are tuned based on the development set. Other parameters in the network are all obtained by random orthogonal initialization and updated during training.
3、Ablation Study
4、Intra- and Inter-sentence Relation Extraction














 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









