







摘要
文档级关系抽取任务旨在从一个多句子的文档中抽取出实体对的关系。最近的研究通常采用基于序列或图形的模型来表示文档,以预测所有实体对的关系。然而,我们发现这样一个模型并不健壮而且表现出奇怪的行为:当一整篇测试文档作为输入到模型中,它可以预测正确,但当删除非证据语句时,它会出错。因此,我们提出一个句子重要性评估和句子聚焦损失框架用于DocRE——我们设计了一个句子重要性得分和句子聚焦损失来鼓励模型去关注证据句子。在两个主要的数据集上实验结果展现了我们的SIEF框架不仅提升了整体性能,而且使文档及关系抽取模型更加健壮。更重要的是,SIEF是一个通用框架,当和其他基本模型结合后表现出有效性。
贡献
提出的SIEF是一个通用框架,可以与各种base-model结合并且是有效的,进一步增加了模型的可解释性。
方法
整体框架图: 
句子重要性评估
我们估计每个句子对于特定实体对的重要性。得分较低的判决将被视为非证据,原则上可以在不改变DocRE预测的情况下删除。我们提出了一个基于DocRE预测的句子重要性得分,该预测包含或不包含所讨论的句子。我们的观察是,关系提取任务通常对证据来说是单调的,即(非严格)更多的关系将被预测为更多的句子。如果我们删除一个句子,并且预测的关系概率降低,那么这个句子很可能就是证据。如果预测的概率没有改变,那么这个句子很可能是没有证据的。此外,当句子被删除时,预测概率有时会增加,在这种情况下,DocRE模型是不可靠的,因为这违反了单调性。 公式如下:
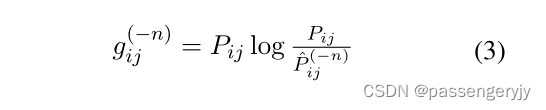
作者通过计算两个概率——分别为基于原始文档的分类概率Pij和删除掉第n个句子后的文档输入所得到分类概率,再通过计算KL散度其中一项得到第n句的重要性得分gij,作者最后引入一个超参数阈值β来评估该句话是evidence sentence or not。
句子聚焦损失
在这一块,作者通过引入sentence focusing loss来鼓励模型在输入文档为完整文档和去掉证据句的文档两种情况下所得到的预测结果保持一致。句子聚焦损失公式如下:

这个并不是最终公式,作者对此稍作改变,,选择一次删除一个non-evi sentence,具体原因和最终公式详见原文。
实验结果
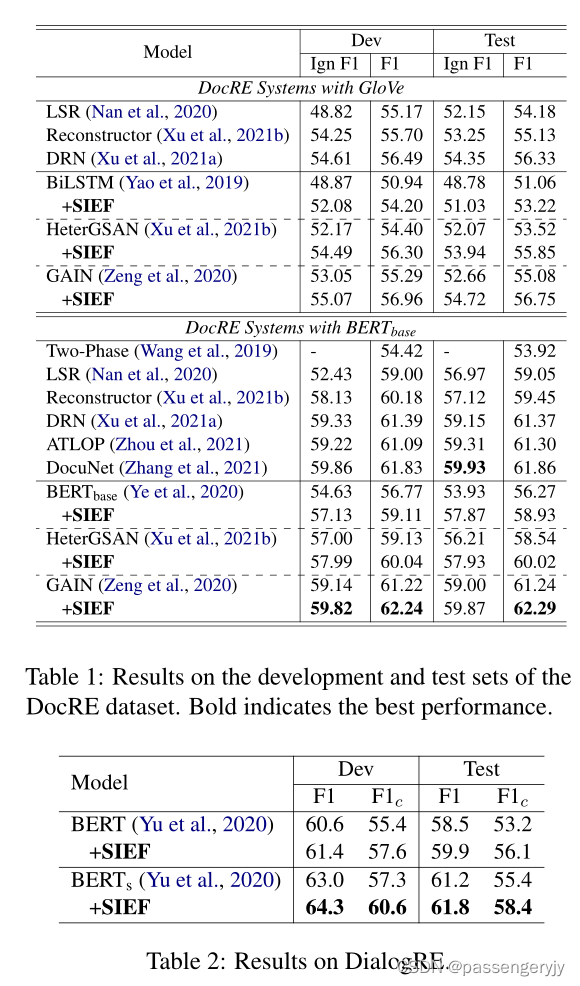
由于作者所提出的框架为一个通用框架,可以应用到诸多base模型上,本文作者选择BiLSTM,Bert-base,HeterGSAN,GAIN作为基础模型,数据集采用通用数据集DocRED,以及对话数据集DialogRE。其中对于数据集DocRED作者用Two Phase,LSR,Reconstructor,DRN,ATLOP,DocuNet来做比较。作者分别利用Glove和Bert-base做嵌入,并都进行了对比且取得了由于比较模型的效果。
结论
作者在本文中提出了一种新的句子信息评估和聚焦(SIEF)方法,用于文档关系抽取(DocRE)。设计了一个句子重要性得分和一个句子聚焦损失,以鼓励模型关注证据句子。提出的SIEF是一个通用框架,可以与各种基本DocRE模型相结合。实验结果表明,SIEF在不同领域都能持续地提高基础模型的性能,并提高了DocRE模型的鲁棒性。















 1328
1328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









