







摘要:
基于分布式多方数据的机器学习(ML)在许多领域都是必需的。现有的方法,如联邦学习,收集由中央聚合器上的一组设备计算的输出,并运行迭代算法来训练全局共享模型。不幸的是,这种方法容易受到各种攻击,包括模型中毒,这在sybil的存在下会变得更糟。(存在恶意节点)
( "Sybil" 是一个网络安全术语,指的是恶意控制者使用多个虚假身份或节点来攻击系统或网络的行为。这种攻击手法通常通过创建大量虚假身份来破坏系统的正常运行或影响决策。这些虚假身份通常被用来欺骗系统,以获取对系统的控制权或操纵系统的行为,这种攻击方式得名于古典小说《Sybil》中的主角,她有多重人格。在网络安全领域,Sybil 攻击通常被用于描述网络中的恶意节点行为。)
在本文中,我们首先评估了联邦学习对基于sybil的中毒攻击的脆弱性。然后我们描述了FoolsGold,这是一种针对该问题的新颖防御方法,它基于分布式学习过程中客户端更新的多样性来识别中毒sybil。与以前的工作不同,我们的系统不限制预期的攻击者数量,不需要学习过程之外的辅助信息,并且对客户端及其数据做出更少的假设。
在我们的评估中,我们表明FoolsGold超越了现有最先进的方法来对抗基于符号的标签翻转和后门中毒攻击的能力。
我们的结果适用于不同的客户数据分布、不同的中毒目标和不同的攻击策略。
1.Intriduction
为了从用户生成的数据中训练多方机器学习(ML)模型,用户必须提供和共享他们的训练数据,这可能是昂贵的或侵犯隐私的。联邦学习[26],[27]是解决这两个问题的最新解决方案:当跨移动设备进行训练时,数据保存在客户端设备上,只有模型参数被传输到中央聚合器。这允许客户端在本地独立地计算他们的模型更新,同时保持基本的隐私水平。
然而,联邦学习引入了一个有风险的设计权衡:以前只充当被动数据提供者的客户端现在可以观察中间模型状态,并作为分散训练过程的一部分提供任意更新。这就为恶意的客户端创造了一个几乎不受限制地操纵培训过程的机会。特别是,伪装成诚实客户端的攻击者可以发送错误的更新,恶意地影响训练模型的属性,这一过程被称为模型中毒。
中毒攻击已经在集中式环境中得到了很好的探索,其中两个常见的例子是标签翻转攻击[9],[23]和后门攻击[4],[14],[20]。在两种攻击类型中,中毒数据所占比例越大,攻击效果越高。联邦学习环境中,每个客户端都在本地维护数据,攻击者自然可以通过使用sybils来提高攻击效率[17]。
A federated learning poisoning experiment.
基于图1中的设置,我们通过三个实验说明了联邦学习对sybil-base的中毒的脆弱性,并在表1中显示了结果。首先,我们重新创建了原联邦学习论文[26]中的基线评估,并跨非IID数据源训练了一个MNIST[24]数字分类器(图1(a)和表1中的基线列)。我们在十个诚实客户之间训练一个softmax分类器,每个客户持有原始十位MNIST数据集的单个数字分区。每个模型训练3000个同步迭代,在每个迭代中,每个客户使用50个随机抽取的训练示例执行本地SGD更新。
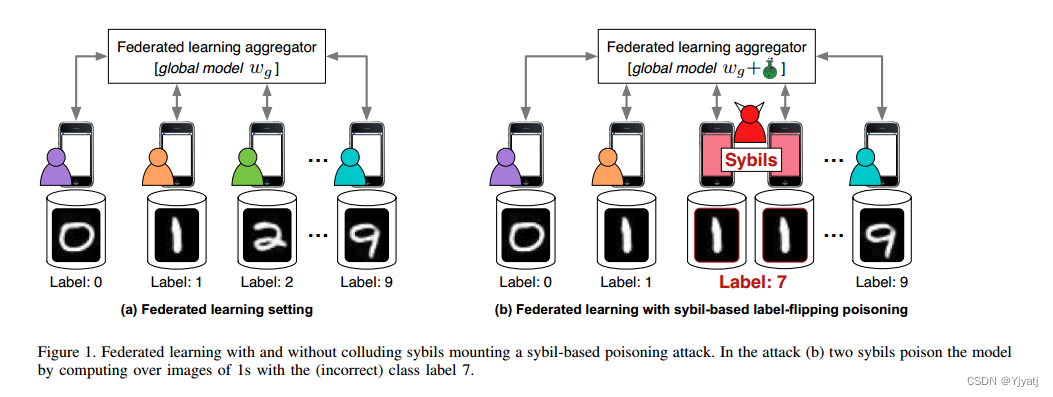
接着,我们利用标签翻转1-7毒化攻击[7]重新运行基线评估:系统中的每个恶意客户都有一个毒化数据集,其中的1被标记为7(图1(b))。成功的攻击会生成一个模型,无法正确分类1,并错误地预测它们为7。我们定义攻击成功率为测试集中最终模型将1预测为7的比例。我们进行了两个实验,在其中1或2个恶意Sybil客户攻击了共享模型(表1中的攻击1和攻击2)。
在表1中展示了基线(无攻击)的准确性和攻击成功率,以及在mnist数据集的联邦学习上下文中具有1和2个sybills的攻击。

表1显示,只有2个sybils时,在最终的共享模型中,96.2%的1被预测为s。由于一个诚实客户端持有数字1的数据,而两个恶意sybils节点持有有毒的1-7数据,因此恶意sybils节点对共享模型的影响是诚实客户端的两倍。
这种攻击说明了联邦学习的一个问题:所有客户端对系统都有相同的影响。因此,无论在联邦学习系统中有多少诚实的客户端,只要有足够的sybils,攻击者就可以利用Sybil节点来破坏系统的模型。
在集中式环境下,已知的针对毒化攻击的防御手段,如鲁棒损失[21]和异常检测[35],都假设对客户端进行控制或明确观察训练数据。然而,这些假设并不适用于联邦学习,因为服务器只能观察作为迭代机器学习算法一部分发送的模型参数。因此,这些防御手段无法应用于联邦学习。
对于适用于联邦学习的毒化防御方法,需要对预期Sybil节点数量进行明确限制[10],[36]。据我们所知,我们是首个在没有明确攻击者数量参数的情况下缓解基于Sybil节点的毒化攻击的研究。
由于联邦学习服务器无法查看客户端的训练数据,并且没有验证数据集,因此服务器无法轻松验证哪些客户端参数更新是真实的。此外,这些更新是随机随机过程的产物,会表现出高方差。我们提出了FoolsGold:一种新的联邦学习Sybil攻击防御方法,该方法根据贡献相似性调整客户端的学习速率。本研究的见解在于,当一组Sybil节点操纵共享模型时,在整 个训练过程的期望中,它们将朝着特定的恶意目标做出更新,其行为比预期更为相似。
FoolsGold能够防御联邦学习中任意数量Sybil节点的攻击,而对原始联邦学习流程的改变最小。此外,FoolsGold不假定特定数量的攻击者。我们在4个不同数据集(MNIST[24]、VGGFace2[13]、KDDCup99[16]、Amazon Reviews[16])和3种模型类型(1层Softmax、Squeezenet、VGGNet)上对FoolsGold进行了评估,发现我们的方法能够在各种条件下缓解标签翻转和后门攻击,包括不同的客户端数据分布、不同的毒化目标和各种Sybil攻击策略。
总的来说,我们做出了以下贡献:
a.我们考虑了对联邦学习架构的sybil攻击,并表明ML中针对恶意对手的现有防御(Multi-Krum[10]和RONI[6](见附录B))是不够的。
b.我们为联邦学习设置设计、实现和评估了一种针对基于sybill的中毒攻击的新型防御,该设置使用基于客户端间贡献相似性的每个客户端的自适应学习率。
c.在这种情况下,我们讨论了攻击者可以执行的最佳和智能攻击,同时提出了进一步缓解的可能方向。
2.Background
机器学习(ML):许多机器学习问题可以表示为在一个大的欧几里得空间中损失函数的最小化。对于预测离散二进制输出的ML二进制分类任务;预测误差越大,损失越大。给定一组训练数据和提出的模型,ML算法针对给定的训练集进行训练或找到一组最优参数。
随机梯度下降法(SGD): ML中的一种方法是使用随机梯度下降(SGD)[12],这是一种迭代算法,它选择一批训练样例,使用它们计算当前模型参数的梯度,并在损失函数最小的方向上采取梯度步骤。然后,该算法更新模型参数并执行另一次迭代。SGD是一种通用的学习算法,可用于训练多种模型,包括深度学习模型[12]。本文采用SGD算法作为优化算法。
在SGD中,模型参数w在每次t时迭代更新如下:
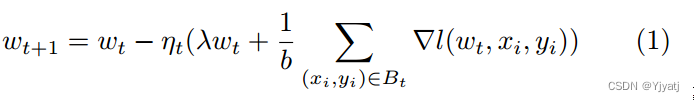
ηt 表示local learning rate 本地学习率
λ 是防止过拟合的正则化参数
Bt 表示大小为b的训练数据示例(xi; yi)的梯度批数batch
derta l 表示损失函数的梯度
Batch size 是SGD与其对应的梯度下降(GD)的区别所在。在GD中,使用整个数据集来计算梯度方向,而在SGD中,每次迭代使用一个子集。这个子集可以按预先确定的顺序选择或随机抽样,但SGD的总体效果是,随着时间的推移,看到的梯度方向会发生变化(并且随着批处理具有更高的方差,尺寸b减小)。在实践中,SGD比GD更受欢迎,有几个原因:对于大型数据集,SGD的成本更低,理论上可以扩展到无限大的数据集。
典型的启发式方法包括在固定次数的迭代中运行SGD,或者在梯度的大小低于阈值时停止。当这种情况发生时,模型训练完成,参数wt作为最优模型w *返回。
联邦学习[26]federate learning :在FoolsGold中,我们假设一个标准的联邦学习上下文,其中数据分布在多个数据所有者之间,不能共享。分布式学习过程在一组客户端的同步更新轮次中执行,其中k个客户端更新的加权平均值,基于n个总示例中的比例训练集大小nk,自动应用于模型。
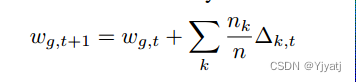
即使训练数据的分布不是独立同分布(non-IID),联邦学习仍然可以达到收敛。 例如,联邦学习可以训练MNIST[24]数字识别分类器,其中每个客户端只持有1个数字类(0-9)的数据,如图1(a)所示。
联邦学习有两种形式:FEDSGD,其中每个客户机将每个SGD更新发送到服务器; FEDAVG,其中客户机在将更新发送到服务器之前本地批处理SGD的多个迭代,这样通信效率更高。我们证明了FoolsGold可以成功地应用于这两种算法。
联邦学习还支持跨一组具有高度私有数据的客户端进行模型训练。例如,差分私有[18]和安全聚合[11]已经发布,但是在多方环境中使用联邦学习仍然会带来新的隐私和安全漏洞[4],[22],[32]。在本文中,我们设计了FoolsGold来解决基于sybil的中毒攻击。
针对机器学习的定向投毒攻击 Targeted poisoning Attacks on ML:在定向投毒攻击中[7],[28],攻击者精心创建中毒的训练样例,并将其插入到被攻击模型的训练数据集中。这样做是为了增加/减少训练模型预测目标样本作为目标类的概率[23](见图1(b))。例如,这种攻击可以避免异常检测或逃避电子邮件垃圾邮件过滤[30]。
在FoolsGold中,我们考虑两种类型的目标攻击。在标签翻转攻击中[9],在保持数据特征不变的情况下,将一类诚实训练样例的标签翻转到另一类。在后门攻击[4],[20]中,原始训练数据的单个特征或小区域被秘密模式增强并重新标记。模式充当目标类的触发器,攻击者可以利用目标类。一般来说,中毒攻击不能显著改变其他职业的预测结果,这一点很重要。否则,攻击会被共享模型的用户检测到。
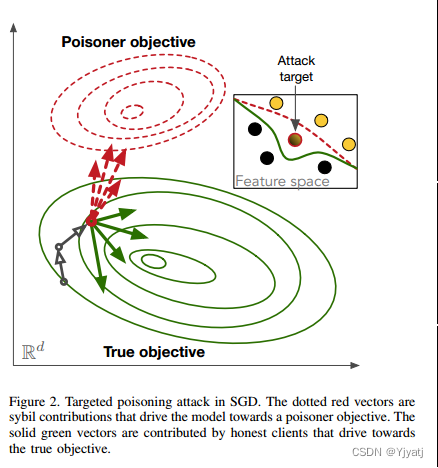
在联邦学习中,聚合器看不到任何训练数据,因此我们从模型更新的角度来看待中毒攻击:更新的子集在任何给定迭代中发送到模型的数据都是有毒的[10]。这在功能上与集中中毒攻击相同,在这种攻击中,总训练数据的一个子集被中毒。图2演示了联邦学习上下文中的目标中毒攻击。
Sybil attacks 允许客户端加入和离开的系统容易受到sybil攻击[17],在这种攻击中,攻击者通过使用多个串通的别名加入系统来获得影响力。在FoolsGold中,我们假设对手利用sybils对联邦学习进行更强大的中毒攻击。
3.Assumptions and threat model(假设与威胁模型)
设置的假设 Setting assumptions
我们只研究联邦学习,因此假设数据在客户端之间是分布式和隐藏的。攻击者只能通过联邦学习API访问和影响ML训练状态,无法观察到其他诚实客户端的训练数据。
这意味着,通过观察模型状态的总变化,攻击者可以观察到所有客户端的总平均梯度,但他们无法查看任何单个诚实客户端的梯度。
在算法的服务器端,我们假设聚合器没有受到损害,也没有恶意。
同样,我们假设有一定数量的诚实客户端参与系统,这些客户端拥有与攻击者中毒目标相反的训练数据。更准确地说,我们的解决方案要求模型定义的每个类都在至少一个诚实客户端的数据中表示。
没有这些诚实的客户端,就不可能有基于贡献的防御,因为模型一开始就无法了解这些类的任何信息。
用于联邦学习的安全聚合通过混淆单个客户端更新提供了更好的隐私[11]。我们假设这些类型的混淆
没有使用安全聚合方法,中央服务器能够观察每次迭代中任何个体客户端的模型更新。
毒化攻击Poisoning attacks
在我们的设定中,针对全局训练模型的有针对性毒化攻击是由攻击者执行的。攻击者有一个明确的毒化目标:增加一个类别被错误分类为另一个不正确的类别的概率,同时不影响其他任何类别的输出概率。为了最大限度减少毒化攻击被发现的可能性,攻击的辅助类别的预测结果应该最小程度地改变。
我们假设毒化攻击采用标签翻转策略[9]或后门策略[4],[20]。标签翻转策略是指将诚实训练样本的标签翻转到目标类别,而后门策略则是指未使用的特征被增加了秘密模式并被利用。
由于攻击者可能进行的SGD更新的范围是无限的,另一种可能的攻击方式是通过缩放恶意更新来压制诚实客户端。然而,现有的基于幅度的检测方法 [10] 可以防止这些攻击,因此我们不考虑这些攻击。
Sybil节点通过提供更新来对联邦学习执行毒化攻击,将共享模型引导到一个共同的毒化目标,如图2所示。
我们不限制Sybil节点如何选择这些毒化更新:它们可以来自毒化的数据[7],也可以通过其他方法计算。
攻击者的能力Attacker capability
在拥有许多诚实客户端的部署中,要使毒化攻击成功,攻击者必须对其目标类别施加的影响力超过该类别的总诚实影响力。这已经成为训练数据中代表不足的类别的问题,但在联邦学习中,每个客户端获得了聚合梯度的均等份额,攻击者可以通过生成额外的Sybil节点来攻击任何具有足够影响力的类别。
如果系统中存在第三方账户验证流程,我们假设攻击者有方法绕过它,可以通过创建恶意账户或者妥协诚实客户/账户来绕过。
Sybil节点观察全局模型状态,并在任何迭代中向聚合器发送任意梯度贡献。Sybil节点可以通过相互之间共享状态,以及以智能、协调的方式发送更新来进行勾结。受多组非勾结敌对者控制的Sybil节点可能会同时执行毒化攻击。
4. SGD Challenges and defenses
在传统的联邦学习设置中,联邦学习服务只能访问本地SGD计算的输出。从聚合器的角度来看,从SGD迭代流中检测符号是困难的。如果使用GD而不是SGD作为优化算法,那么检测就会变得更容易:在这种设置中,更新是数据的确定性函数,重复更新很容易检测到。SGD的挑战有三个方面:
挑战1 每个客户端都包含一个局部的、不可见的数据分区,这些数据分区独立地可能无法满足全局学习目标。当从客户端接收梯度时,聚合器很难判断梯度是否指向恶意目标。我们假设我们设计的系统FoolsGold没有验证数据集。
挑战2 由于每次迭代只使用原始数据集的一小部分,因此随机目标随着每次迭代而变化。聚合器不能假设指向零星方向的更新是恶意的。同样,聚合器不能假设相似的更新来自相似的底层数据集。
挑战3 随着更新的批处理大小b的减小,客户机贡献的更新方差增加。在任何给定的迭代中,采样数据集的较小部分会导致梯度值的较大方差,从而产生上述零星行为。由于攻击者可以向模型发送任意更新,因此我们不能相信它们会符合指定的批处理大小配置。
上述挑战使得现有的中毒防御无法抵御针对联邦学习的基于sybil的攻击,特别是在non-iid设置中。
Multi-Krum[10]是专门设计用于对抗联邦学习中的攻击者的。在Multi-Krum中,将对全局模型的前f个贡献 即离平均客户贡献最远的f个贡献从聚合梯度中移除。Multi-Krum使用欧几里得距离来确定哪些梯度贡献被删除,需要对预期对手的数量进行参数化,并且理论上只能承受客户端池中多达33%对手的基于sybilb的中毒攻击。
我们假设攻击者可以生成大量的密码,使得关于诚实客户端比例的假设变得不现实。此外,Multi-Krum过程中的平均值可能受到符号贡献的任意影响。我们在6.2节中比较了 FoolsGold against Multi-Krum。
5. FoolsGold design
我们的解决方案适用于仅能访问客户端随机梯度下降(SGD)计算结果的联邦学习环境。我们设计了一种学习方法,它不对系统中诚实客户的比例做假设。我们的学习方法仅使用学习过程本身的状态来调整客户端的学习率。
我们的关键观点是,通过梯度更新的多样性可以将诚实客户端与伪装者区分开来。在联邦学习中,由于每个客户端的训练数据都有一个独特的分布,并且不是共享的,而sybils有着共同的目标,所以它们将提供比诚实的客户端更相似的更新。联邦学习的这个特性在图6中展示,第6.3节对此进行了探讨。
<说人话就是说,诚实客户端提供的梯度更新是多样化的,而恶意客户端提供的更新是相似的。>
(假设?是指上文提到的关键观点)
FoolsGold使用这个假设来调整每次迭代中每个客户端的学习率。我们的方法旨在保持提供独特梯度更新的客户端的学习率,同时降低重复提供相似的梯度更新的客户端的学习率。
考虑到这一点,FoolsGold有五个设计目标:
目标1 当系统不受攻击时,FoolsGold应该保持联邦学习的性能。
目标2 FoolsGold应该减少那些指向相似方向的客户端对模型的贡献。
目标3 FoolsGold在遭受不断增加的伪装者参与的毒化攻击时应具备鲁棒性。
目标4 FoolsGold应该区分由于SGD的变化而被误认为恶意的诚实更新和指向共同恶意目标的伪装者更新。
目标5 FoolsGold不应该依赖于关于客户端的外部假设,也不应该要求对攻击者的数量进行参数化。

现在我们解释一下FoolsGold方法(算法1)。在联邦学习协议中,梯度更新是在同步更新轮次中收集和聚合的。FoolsGold根据以下两个因素对每个客户端的学习率 αi 进行调整:(1)在任何给定迭代中指示性特征之间的更新相似性;(2)来自过去迭代的历史信息。
请注意,我们使用α表示FoolsGold指定的学习率,η表示传统的局部学习率。它们是相互独立的。
余弦相似度。Cosine similarity 我们使用余弦相似度来度量更新之间的角距离。这比欧几里得距离更可取,因为攻击者可以操纵梯度的大小来实现不相似性,但是不能操纵梯度的方向,因为这样会降低攻击的有效性。诚实更新的大小也受到客户端超参数的影响,例如本地学习率,这些参数我们无法控制。
特征的重要性。Feature importance 从潜在中毒攻击的角度来看,模型中有三种类型的特征:(1)与模型的正确性相关但为了成功攻击必须进行修改的特征;(2)与模型的正确性相关但与攻击无关的特征;(3)与攻击和模型正确性都无关的特征。
与其他分散的中毒防御类似[36],我们只在模型中的指示性特征(类型1和类型2)中寻找相似性。这可以防止攻击者在执行攻击时操纵不相关的功能,这将在6.4节中进行评估。
通过测量全局模型输出层中模型参数的大小,找到指示性特征。由于在执行SGD时训练数据特征和梯度更新是归一化的,因此输出层参数的大小直接映射到其对预测概率的影响[37]。这些特征可以根据它们对模型的影响进行过滤(硬)或重新加权(软),并在所有类之间进行规范化,以避免一个类对另一个类产生偏倚。
对于深度神经网络,我们不考虑模型非输出层中的值的大小,它们不直接映射到输出概率,并且更难以推理。最近关于深度神经网络特征影响的研究[1],[15]可能会更好地捕捉深度学习中基于sybil的中毒攻击的意图,我们将此分析作为未来的工作。
Updates history. FoolsGold维护来自每个客户端的更新历史。它通过将来自单个客户机的每次迭代的更新聚合到单个聚合的客户机梯度(第3行)来实现这一点。为了更好地估计客户端所做的总体贡献的相似性,FoolsGold计算成对的聚合的历史更新之间的相似性,而不仅仅是当前迭代的更新。
图3显示,即使对于具有共同目标的两个sybil,由于挑战2中提到的问题,在给定迭代中的更新也可能而出现分歧。但是,两个sybils 聚合的历史更新之间的余弦相似度很高,满足了目标2。
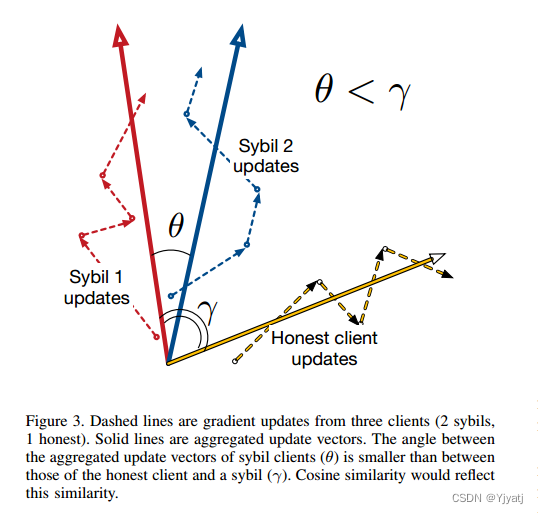
我们解释指示性特征上的余弦相似度,值在-1和1之间,代表了两个sybils客户端之间会话的强烈程度。我们将vi定义为客户机i的最大两两相似性,确保只要存在一个这样的交互,我们就可以降低贡献的价值,即使存在越来越多sybils节点也依然能保持鲁棒性,如目标3所规定的那样。
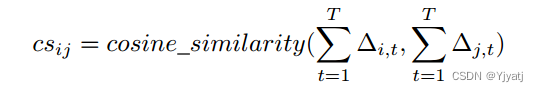
Pardoning.由于我们对诚实的客户和sybils之间的余弦相似度没有足够的保证,因此在此方案下,诚实的客户可能会被错误地惩罚。
我们引入了一种赦免机制,通过计算vi和vj的比率对余弦相似度重新加权(第13行)来避免惩罚这些诚实的客户端,从而满足目标4。然后新的客户端学习率αi,通过在0-1域中逆最大相似分数来确定。因为我们假设系统中至少有一个客户端是诚实的,所以我们重新调整向量,使学习率的最大自适应为1(第18行)。这确保了至少有一个客户端将有一个未修改的更新,并鼓励系统满足目标1:一个只包含诚实节点的系统将不会惩罚他们的贡献。
(这一块儿我的理解是:余弦相似度是-1到1的,对于取负值的余弦相似度我们取逆,这样可以使得所有的分数都处于0-1之间。)
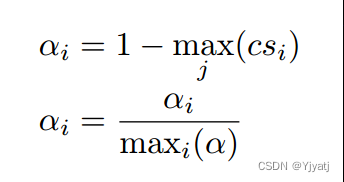
logit. 然而,即使是非常相似的更新,余弦相似度也可能小于1。攻击者可以通过增加sybil的数量来利用这一点,以保持其影响力。因此,我们希望鼓励在该函数的两个尾部附近的值有更高的散度(差异),并避免对相似度值低但非零的诚实客户端进行惩罚。因此,对于这些属性,我们使用以0.5为中心的logit函数(反sigmoid函数)(第19行)。<该函数的使用有助于在两端的情况下鼓励更高的差异,并避免对低但非零相似度值的诚实客户端进行惩罚。>我们还公开了一个置信度参数κ,用于缩放logit函数,并在9中表明,κ可以设置为客户端之间数据分布的函数,以保证收敛。
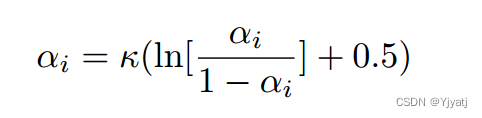
当使用logit函数的结果时,任何超过0-1范围的值都将被裁剪并舍入到其各自的边界值。最后,通过应用最终的重新缩放学习率来计算整体梯度更新:
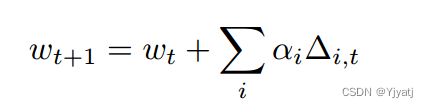
请注意,此设计不需要对预期的sybils数量或其属性进行参数化(目标5),它独立于底层模型,也独立于SGD细节,例如本地客户机的学习率或批大小。
Augmenting FoolsGold with other methods(用其他方法增强FoolsGold)。简单地根据客户端的总梯度相似度修改客户端的学习率并不能处理所有的中毒攻击。显然,来自单一对手的攻击不会表现出这种相似性。当与现有的检测有限数量攻击者的中毒攻击的解决方案增强时,最好使用FoolsGold。在第7节中,我们用Multi-Krum来评价FoolsGold。
Convergence properties(收敛性质)。FoolsGold类似于重要性抽样[29]和自适应学习率方法[42],这两种方法都已应用于SGD算法,并具有收敛性保证。我们在第9章分析了FoolsGold的收敛性保证。我们的实验结果进一步支持了FoolsGold在多种条件下的收敛性。
foolsGold security guarantees(安全保证)。我们声称,我们的设计通过限制对手通过伪装获得的影响力,减轻了他们实施目标中毒攻击的能力。
我们还声称FoolsGold满足特定的设计目标:它在保留诚实节点的更新的同时,对伪装节点的贡献进行了惩罚。在下一节中,我们通过对 FoolsGold 的原型进行实证验证,以跨多个不同维度验证我们的主张。
6. Evaluation
我们通过600行Python代码实现了一个联邦学习原型来评估FoolsGold。原型包括150行FoolsGold代码,实现了算法1。我们使用scikit-learn[34]来计算向量的余弦相似度。对于下面的每个实验,我们将原始训练数据划分为相交的非iid训练集,在每个数据集上本地计算SGD更新,并使用所描述的FoolsGold方法聚合更新以训练全局共享分类器。
我们在四个著名的分类数据集上评估我们的原型:MNIST [24],一个数字分类问题;VGGFace2 [13],一个人脸识别问题;KDDCup [16],包含分类的网络入侵模式;以及 Amazon [16],包含产品评论文本的语料库。表 2 描述了每个数据集。每个数据集都因其特定性而被选中。
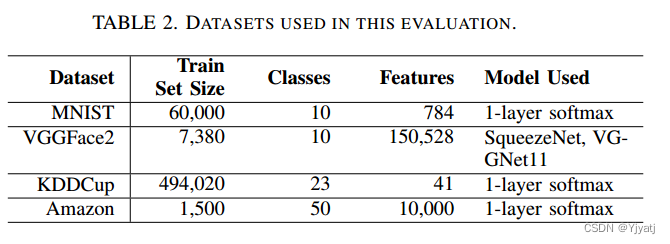
MNIST 被选作评估的基线数据集,因为它在原始联邦学习评估 [26] 中被广泛使用。VGGFace2 数据集被选为一个更复杂的学习任务,需要深度神经网络来解决。为了在评估中简化对毒化攻击的处理,我们限制了这个数据集的范围,仅选取了前 10 个最常见的类别。
KDDCup 数据集特征数量较少,存在巨大的类别不平衡现象:一些类别只有 5 个样本,而另一些类别则有超过 280,000 个样本。最后,Amazon 数据集具有少量示例,并包含文本数据:每个评论被转换为其独热编码(One-Hot Encoding),产生了一个大小为 10,000 的大特征向量。
在本节的所有实验中,执行的是针对性的毒化攻击,试图在联邦学习原型训练过程中鼓励一个源标签被分类为目标标签。在数据划分时,每个类别总是由一个客户端完整地表示,这与联邦学习的基线一致。在所有实验中,系统中的诚实客户端数量因数据集而异:对于 MNIST 和 VGGFace2 为 10,对于 KDDCup 为 23,对于 Amazon 为 50。我们在第 6.3 节中考虑更多独立同分布设置。
对于 MNIST、KDDCup 和 Amazon,我们训练了一个单层全连接的 Softmax 进行分类。每种情况下训练模型的大小是类别数和特征数的乘积。对于 VGGFace2,我们使用了 torchvision 包 [25] 中在 Imagenet 上预训练的两种流行架构:SqueezeNet1.1,一个设计用于边缘设备的较小模型,参数量为 727,000;以及 VGGNet11,一个参数量为 1.28 亿的较大模型。当使用 FoolsGold 比较客户端相似度时,我们仅使用最终输出层梯度中的特征(在 VGGNet 中是全连接层,在 SqueezeNet 中是 10 个 1x1 卷积核)。
在 MNIST 中,数据已划分为 60,000 个训练示例和 10,000 个测试示例[24]。对于 VGGFace2、KDDCup 和 Amazon,我们随机将总数据的 30% 划分为测试数据。测试数据用于评估我们算法的性能两个指标:攻击率,即被攻击目标(标签翻转攻击的源标签或后门攻击的嵌入图像)被错误地分类为目标标签的比例;准确率,即测试集中被正确分类的示例的比例。
MNIST 和 KDDCup 数据集的迭代次数为 3,000 次,批处理大小为 50,除非另有说明。对于 Amazon,由于特征数量较高,每个类别的样本数量较少,我们进行了 100 次迭代,批处理大小为 10。对于 VGGFace2,我们进行了 500 次迭代,使用批处理大小为 8 的 SGD,动量为 0.9,权重衰减为 0.0001,学习率为 0.001。这些值是在训练集上使用交叉验证得出的。在训练期间,图像被调整为 256x256,随机裁剪和翻转至 224x224。在测试期间,图像被调整为 256x256,并裁剪为 224x224 的中心。
在非攻击场景下,我们使每个实验运行至收敛。在所有攻击场景下,我们发现所选择的迭代次数足够高,以至于攻击的性能随着每次迭代变化很小,表明攻击结果是一致的。对于每个实验,FoolsGold 参数设置为置信参数 κ = 1,并且不使用历史梯度或重要特征过滤(我们分别在第 6.5 节和第6.4节中独立评估这些设计元素)。每个报告的数据点是5次实验的平均值。
6.1. Canonical attack scenarios(经典攻击场景)
我们在三个数据集上的评估使用了5种攻击场景(我们在本次评估中称为经典攻击场景)(见表3)。攻击A -1是一种传统的中毒攻击:单个客户端携带中毒数据加入联邦学习系统。攻击 A-5 是同样的攻击,但由5个 Sybil 客户端加入系统进行。每个客户机通过SGD发送其数据子集的更新,这意味着它们的更新并不相同。攻击A-2x5评估了FoolsGold一次挫败多种攻击的能力:两组客户端服务器同时攻击系统,为了攻击评估目的,我们假设这些攻击中的类不重叠。
(我们不会在2-3攻击的同时执行1-2攻击,因为评估1-2攻击会受到2-3攻击的影响。)
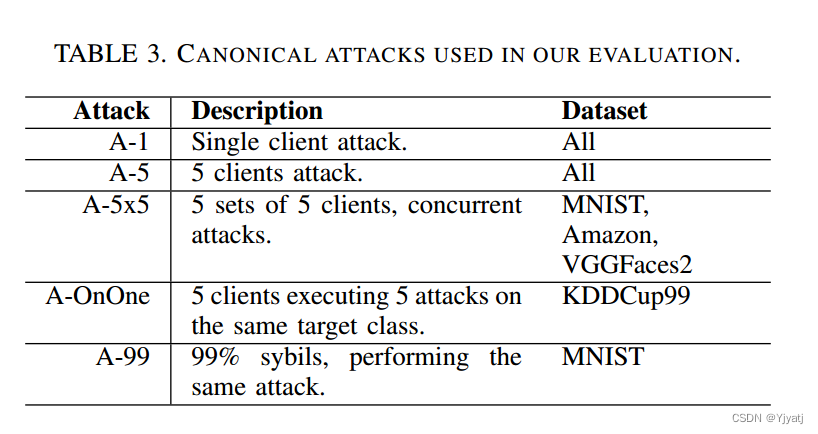
由于KDDCup99是一个具有严重类别不平衡的独特数据集,因此我们选择在该数据集上执行与A-OnOne攻击不同的攻击。在KDDCup99中,提供了来自各种网络流量模式的数据。类别“Normal”标识没有任何网络攻击的模式,它在整个数据集中占据了相当大的比例(约占数据的20%)。因此,当攻击KDDCup99时,我们假设攻击者错误地标记了恶意攻击模式,这些模式比例很小(约占数据的2%),并将恶意类别毒害为“Normal”类别。
A- AllOnOne是一种针对KDDCup的独特攻击,其中5种不同的恶意模式都被标记为“Normal”,并且每次攻击同时进行。
最后,我们使用A-99来说明FoolsGold对大规模攻击场景的鲁棒性。在这种攻击中,攻击者生成990个sybil来压制一个由10个诚实客户端组成的网络,并且所有这些sybil都试图对MNIST进行单一的1-7攻击。
由于我们在整个工作中使用这些经典攻击,因此我们首先在启用了FoolsGold的情况下评估在各自数据集上的每种攻击(表3中)效果。图4绘制了表3中每种攻击的攻击率和测试准确率。
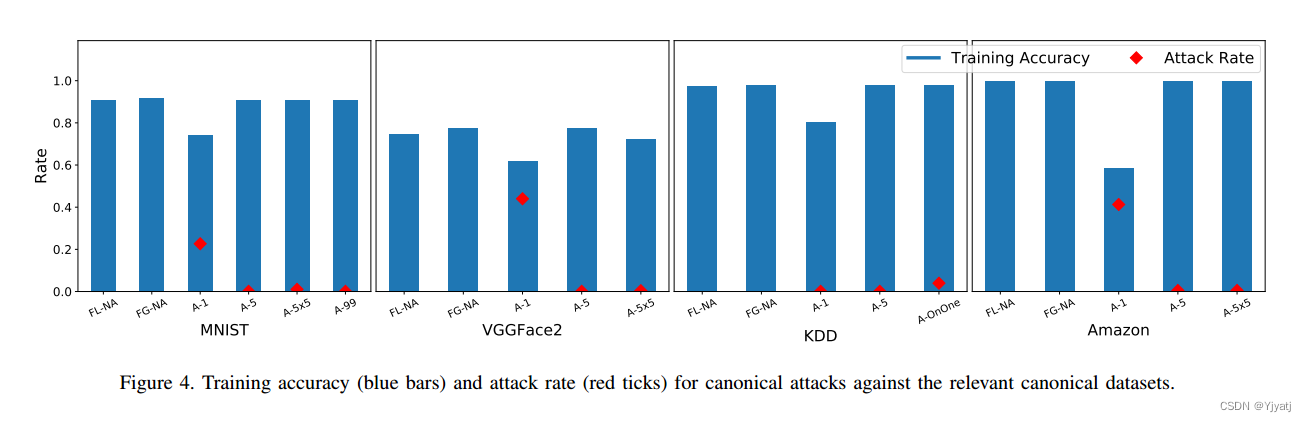
该图还显示了未受攻击的系统的结果:原始联邦学习算法(FL-NA)和使用FoolsGold算法(FG-NA)的系统。
从图4可以看出,对于大多数攻击,包括A-OnOne攻击和A-99攻击,FoolsGold在保持高训练精度的同时有效地阻止了攻击。当FoolsGold面对更大的sybil组时,它有更多的信息来更可靠地检测sybil之间的相似性。在只有一个恶意客户端攻击系统的A-1攻击中,FoolsGold表现最差。原因很简单:没有多重串通的sybil。对于FoolsGold聚合器来说,恶意客户和诚实客户是无法区分的。
另一个有趣的点是假阳性的普遍存在。在A-1 KDDCup中,我们的系统错误地惩罚了与攻击者勾结的诚实客户端,在应用防御时降低了诚实客户端的预测率。我们观察到低训练错误率的两个主要原因是高攻击率(假阴性)或高目标类错误率(假阳性)。我们还将在第6.3节讨论数据相似度的误报。
6.2. Comparison to prior work(与先前工作的比较)
我们将 FoolsGold 与Multi-Krume 聚合 [10] 进行比较,Multi-Krume 聚合是在分布式 SGD 中防御拜占庭客户端的已知最先进技术(见第2节)。
与 Multi-Krum 的比较。在这个实验中,我们将 FoolsGold 与 Multi-Krum 和未经修改的联邦学习基线进行比较,并在改变 Sybil 数量时观察其表现。
我们按照原始论文 [10] 中指定的方式实现了 Multi-Krum:在每次迭代中,计算每个更新与最近的 n-f-2 个邻居的欧几里得距离总和。删除距离最远的 f 个更新,然后计算剩余更新的平均值。Multi-Krum 依赖于 f 参数:系统容忍的最大拜占庭客户端数量。为了在此设置中防御 Sybil 攻击,我们将 f 设置为执行毒化攻击的 Sybil 数量。尽管这对 Multi-Krum 是最理想的情况,但我们注意到,在防御 Sybil 攻击时,先验知识的 f 是一个不切实际的假设。
在运行 Multi-Krum 时,我们发现其在非 IID 设置下的表现特别差。当诚实客户端的更新方差很高,并且 Sybil 的更新方差较低时,Multi-Krum 会将诚实客户端从系统中移除。这使得 Multi-Krum 不适合用于防御联邦学习中的 Sybil,而联邦学习旨在用于非 IID 设置 [26]。
图5显示了三种方法针对不断增加的毒害者数量的性能:对未经修改的非 IID 联邦学习系统进行了1-7攻击(基线),采用 Multi-Krum 聚合的联邦学习系统和我们提出的解决方案。我们展示了 FoolsGold 对 FEDSGD 和 FEDAVG [26] 的有效性,其中客户端在与聚合器共享更新之前执行多个本地迭代。(1-7攻击是指把源标签为1的数据的目标标签改为7)

我们看到,一旦一个类别的投毒者的比例(Number of Poisoners)增加到超过持有该类别的诚实客户端的相应数量(图中是1),对于navie averaging (基线),攻击率就会显著增加。
除了超出预期的sybils的参数化数量之外,攻击者还可以在任何给定的迭代中影响平均客户端贡献,并且Multi-Krum将无法区分诚实的客户端和sybils。
Multi-Krum最多可以处理33%的sybil[10],但超过这个阈值就失效了。相比之下,随着sybil比例的增加,FoolsGold会进一步惩罚攻击者,在这种情况下,即使有9个攻击者,FoolsGold也会保持稳健。
与图4中的结果一致,当只有一个投毒者时,图5中的FoolsGold表现最差。我们还在附录B中表明,FoolsGold在防御后门攻击方面同样优于Multi-Krum[20]。
也就是说,FoolsGold在攻击者多的情况下更有利
6.3. Varying client data distributions(不同的客户端数据分布)
(证明了它在IID和non-IID两种数据中的表现都很好,而上面提到multi-krum在non-IID数据下表现非常差)
FoolsGold所依赖的假设是,客户之间的训练数据有足够的差异。然而,一个现实的场景可能涉及到每个客户端都有重叠数据的设置,比如同一个人的图像。
为了在不同数据分布假设下测试FoolsGold,我们使用10个诚实客户端对MNIST和VGGFace2进行A-5 0-1攻击(使用5个sybils),同时改变sybils和诚实客户端中共享数据的比例。
我们在一个网格(xsybil,xhonest ∈ {0,0.25,0.5,0.75,1})上改变了sybils和诚实客户端的分布 ,其中x为不相交数据与共享数据的比值。具体来说,0%的比例指的是非iid设置,其中每个客户端的数据集由一个类组成,100%是指从所有类中统一采样每个客户端的数据集的设置。比例x是指客户端持有所有类的x%统一数据和特定类的(1−x)%不一致数据的设置。为了创建一个具有x%共享数据的sybil客户端,我们首先使用类别0创建一个具有x%共享数据和(1 - x)%不共享数据的诚实客户端,然后将所有0标签翻转为1以执行有针对性的攻击。
(这里的网格?应该是说一种实验设置,这个网格由{0,0.25,0.5,0.75,1}这些值组成,通过不同的参数值的变化来观察其对结果的影响)
在这里,x 表示不同的数据集成分之间的比例,指的是非共享数据和共享数据的比例。具体来说,比例为 0% 表示非独立同分布(IID)的设置,即每个客户端的数据集只包含一个类别,而比例为 100% 表示每个客户端的数据集都是从所有类别中均匀抽样得到的设置。
当比例为 x 时,表示每个客户端持有 x% 来自所有类别的均匀数据,剩余 (1 - x)% 的数据来自某一个特定类别的独立数据。为了创建一个具有 x% 共享数据的 Sybil 客户端,首先创建一个包含 x% 共享数据和 (1 - x)% 独立数据的诚实客户端,其中 x% 的共享数据使用类别 0,然后将所有标签为 0 的数据标签改为 1,以执行有针对性的攻击。
为了理解FoolsGold是如何处理这些情况的,我们在图6中可视化了VGGFaces2 A -5实验的所有客户机的梯度历史。每一行显示最后一个分类层中客户机的历史梯度,其中最上面的10行对应诚实客户机,最下面的5行对应sybils。图6的左侧显示了非iid设置(xsybil;由于每个诚实客户端都有对应于唯一类的数据,因此它们的梯度非常不相似,并且由于sybils对于0-1攻击具有相同的中毒数据集,因此它们的梯度非常相似。因此,FoolsGold可以很容易地检测到sybils梯度。
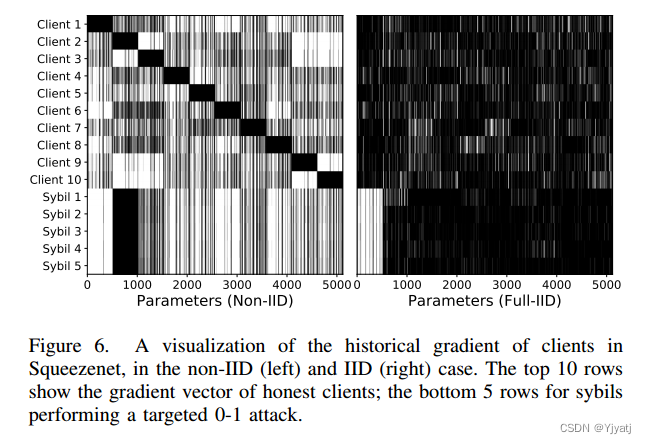
图6的右侧显示了IID设置中的历史梯度(xsybil;xhonest = 1)。即使诚实的客户端都持有统一的训练数据样本,SGD的随机性也会引入诚实客户端之间的方差,并且由于他们的有毒数据,sybil梯度仍然是唯一不同的,如图6的左下角所示。想要执行有针对性的中毒攻击的黑客会产生基本相似的梯度更新,使FoolsGold能够成功。
在附录A中,我们通过客户端间更新相似度的边界正式定义了FoolsGold的收敛性。
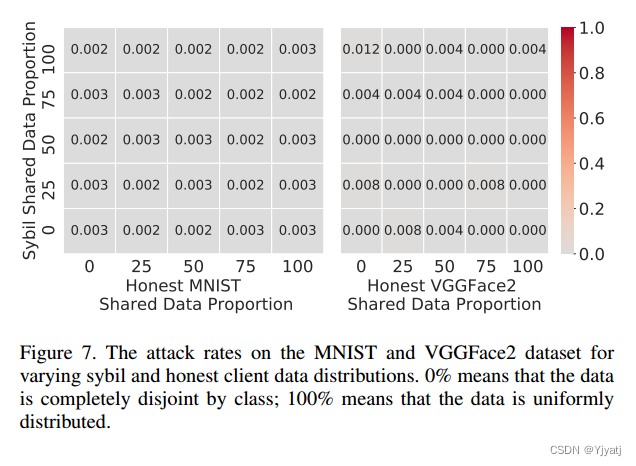
FoolsGold在所有组合中都能有效防御中毒攻击:在使用SqueezeNet和VGGNet的情况下,MNIST和VGGFace2数据集的最大攻击率都小于1%。我们在图7中显示了这些结果。正如本节中的结果所示,恶意参与者无法通过操纵其恶意数据分布来破坏FoolsGold。相反,它们必须直接操作它们的梯度输出,这是我们接下来要探讨的。
6.4. What if the attacker knows FoolsGold? 如果攻击者了解FoolsGold呢?
如果攻击者了解FoolsGold算法,他们可能会尝试以某种方式发送更新,以鼓励更多的不相似性。这是一种主动的权衡:随着攻击者的更新变得不那么相似(检测机会降低),它们对毒化目标的集中度也降低(攻击效用降低)。
我们考虑并评估了攻击者可能试图破坏FoolsGold的四种方式:(1)混合恶意和正确的数据,(2)更改sybil的训练批次大小,(3)用噪声扰动贡献的更新,以及(4)不经常和自适应地发送毒化的更新。由于空间限制,(1)和(2)的结果列在附录B中。
Adding intelligent noise to updates.添加智能噪声到更新。一组智能的Sybil可能会发送一对经过精心扰动的噪声,设计得能够相互抵消,总和为零。例如,如果攻击者产生一个随机的噪声向量 ζ,两个恶意更新 a1 和 a2 可以作为 v1 和 v2 提交,使得:v1 = a1 + ζ,和 v2 = a2 - ζ。
由于噪声向量 ζ 与毒化目标无关,其包含将增加恶意更新的不相似性,并降低 FoolsGold 检测它们的效果。同时要注意的是,这两个更新的总和仍然是相同的:v1 + v2 = a1 + a2。这个策略也可以通过采用正交的噪声向量及其否定来扩展到超过 2 个 Sybil:对于这些向量的任何子集,余弦相似度为 0 或 -1,而总和仍然为 0。(噪声向量既与毒化目标无关又能降低检测的效果)
正如在第 5 节中解释的那样,如果 ζ 只应用于类型(3)的特征:那些对于模型或攻击不重要的特征,这种攻击最为有效。这会增加 Sybil 的不相似性,并且不会对攻击造成不利影响。
此攻击受到模型中指示性特征的过滤的缓解。我们不再查看模型中所有特征之间的余弦相似度,而是基于特征重要性的加权余弦相似度。
为了评估这种机制对于毒化攻击的重要性,我们在 MNIST 上执行上述的智能噪声攻击,其中每个示例包含一些不相关的特征(大的黑色区域):一对 Sybil 发送具有智能噪声 ζ 的 v1 和 v2。然后,我们将被定义为指示性的模型参数的比例从 0.001(在 MNIST 上的 8 个特征)变化到 1(所有特征)。
(这里应该是在说,指示性特征在数据中所占的比例越多攻击表现越好,反之越弱。然而它想要抵御foolsgold的检测智能噪声要加在无关的特征上才可以。所以说明攻击者的这种方法行不通。)
图8显示了不同比例的指示性特征的攻击率和训练精度。我们首先观察到,当使用所有指示性特征时(最右边),投毒攻击是成功的。
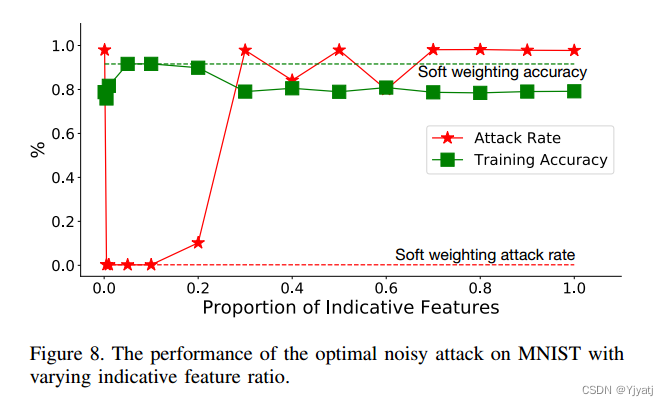
当指示性特征的比例降到0.1(10%)以下时,智能噪声引起的不相似性从余弦相似度中去除,中毒向量主导相似度,导致智能噪声策略失败,攻击率接近0。我们还观察到,如果指示性特征的比例过低(0.01),训练精度也会受到影响。当考虑到如此少的特征时,诚实的客户端似乎也会相似,导致误报。
我们还评估了软特征加权机制,该机制基于模型参数本身按比例对每个贡献进行加权。同样的智能MNIST投毒攻击,软加权方法的结果也如图8所示。在攻击率和训练精度方面,软过滤机制的性能与最优硬过滤机制相当。
Adaptive updates method.自适应更新方法。我们设计了另一种针对FoolsGold的最佳攻击?,即操纵其内存组件。如果攻击者知道FoolsGold在更新历史上使用了余弦相似度,并且能够在本地计算sybil之间的两两余弦相似度,他们可以记录这些信息,并决定只有当它们的相似性足够低时才发送有毒更新(算法2)。该算法使用参数M,表示sybils间余弦相似度阈值。

当M较低时,用户不太可能被FoolsGold发现,因为他们发送更新的频率较低; 但是,这也将降低每个sybil对全局模型的影响。
攻击者可能会为成功的攻击生成大量的脚本,但考虑到攻击者不确定需要多大的影响力来压制诚实的客户端,这就成为了实现最佳攻击的一个困难权衡。
为了证明这一点,上面的智能噪声攻击是由2个sybills在MNIST上执行的,FoolsGold使用余弦相似度中的特征软加权(MNIST对智能噪声攻击的最佳防御)。图9显示了M与匹配每个诚实的对立客户的影响所需的最终期望比例之间的关系。
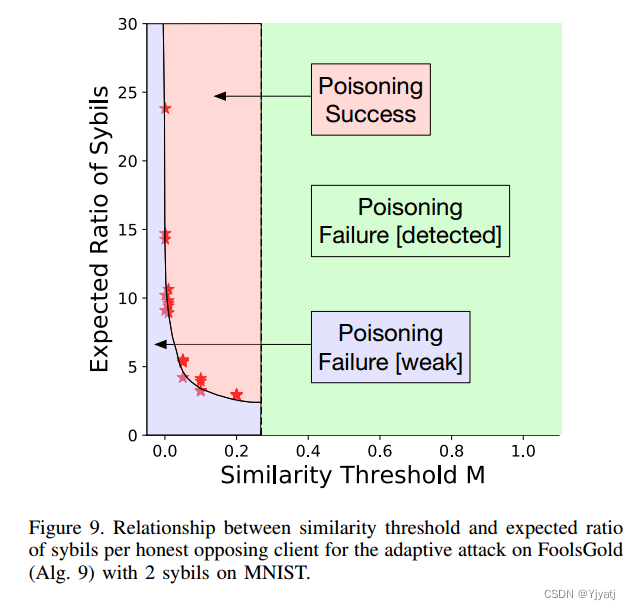
例如,如果我们观察到 sybil 仅在 25% 的时间内发送毒化梯度,则它们需要 4 个 sybil。给定预先指定的相似度阈值 M,所显示的数值是预期需要的 sybil 数量,以进行最佳攻击。该攻击是最佳的,因为使用更少的 sybil 无法提供足够的影响力毒化模型,而使用更多的 sybil 则效率低下。
如图 9 所示,由三个阴影区域表示:在右侧的绿色区域(M > 0.27)中,阈值太高,任何毒化攻击都会被检测和清除。在左下方的蓝色区域中,攻击未被检测,但 sybil 数量不足以击败诚实的对手客户。最后,在左上方的红色区域中,攻击成功,可能使用了比所需更多的 sybil。
只要有足够多的sybil和适当低的阈值,攻击者就可以破坏我们目前对观察到的数据集的防御。找到合适的阈值是具有挑战性的,因为它取决于许多其他因素:系统中诚实客户的数量、FoolsGold考虑的指示性特征的比例以及数据的分布。
此外,与联邦学习的基线中毒攻击相比,这种攻击需要更高比例的sybils。例如,当M设置为0.01时,攻击者将需要每个对立客户端至少10个sybils来毒害模型,而在联邦学习中,他们只需要超过对立客户端的数量。
在不知道诚实客户端数量及其真实训练数据的情况下,攻击者不知道成功毒害模型所需的sybill的确切数量。
6.5. Effects of design elements( 设计元素的作用)
第5节中描述的三个主要设计元素((history, pardoning and logit)中的每一个都解决了特定的挑战。在接下来的实验中,我们禁用了三个组件中的一个,并记录了得到的模型的训练误差、攻击率和目标类误差。
History 前一节中的两种subversion策略增加了每次迭代中更新的变化。
由sybil发送的更新中增加的方差导致每次迭代中的余弦相似度是客户端sybil可能性的不准确近似值。我们的设计使用历史来解决这个问题,我们通过比较有历史和没有历史的愚金的性能来评估它,使用a -5 MNIST攻击,80%的有毒数据和1的批处理大小(两个因素之前显示有很高的方差)。
Pardoning 我们声称诚实的客户端更新可能类似于sybils的更新,特别是当诚实的客户端拥有目标类的数据时。为了评估赦免系统的必要性和有效性,我们比较了愚金在KDDCup上与A-AllOnOne攻击在赦免和不赦免情况下的表现。
Logit 使用logit函数的一个重要动机是,攻击者可以任意增加sybils的数量,以减轻其更新的任何非零权重。我们评估了FoolsGold在A-99 MNIST攻击中使用和不使用logit函数的性能。
图10显示了六种不同评估的总体训练错误、sybil攻击率和目标类错误。

A-AllOnOne KDDCup攻击的攻击率为5组攻击的平均攻击率。
总的来说,结果与我们的说法一致。比较有和没有历史记录的A-5 MNIST案例,我们发现历史记录成功地减轻了在没有历史记录的系统中可能会通过的攻击。比较a - allonone KDDCup攻击的结果,我们发现,在没有宽恕的情况下,训练错误和目标类错误都增加了,而两种情况下的攻击率都可以忽略不计,这表明目标类的误报率很高。最后,比较a -99 MNIST攻击的结果,没有logit功能,对手能够通过用sybils压倒愚金来发动成功的攻击,这表明logit功能是防止这种攻击所必需的。
6.6. FoolsGold performance overhead (性能开销)
我们评估了使用FoolsGold增强联邦学习系统所带来的运行时开销。我们通过在商用CPU上训练MNIST分类器和在Titan V CPU上训练VGGFace2深度学习模型,在10 - 50个客户端上运行有FoolsGold和没有FoolsGold的系统。
图11显示了FoolsGold为基于CPU和GPU的工作负载增加的相对减速。在CPU上,FoolsGold算法性能开销最大的部分是计算两两余弦相似度。我们的Python原型没有经过优化,有一些已知的优化可以提高计算角距离的速度[2]。
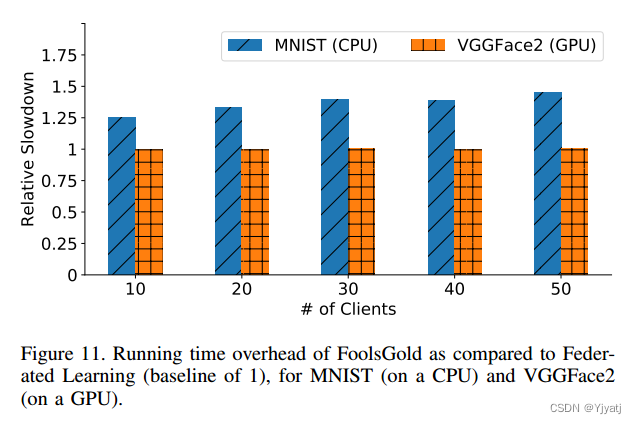
当在GPU上训练深度学习模型时,训练成本足够高,以至于FoolsGold的相对减速可以忽略不计。我们对执行FoolsGold算法所需的总时间进行了微基准测试,发现即使有50个客户机,它所花费的时间也不到1.5秒。
7. Limitations
Combating a single client adversary.对付一个中毒客户端。
FoolsGold被设计用来对抗基于sybil的攻击,我们在图5中的结果表明,FoolsGold不能成功地减轻由单个中毒客户端发起的攻击。
然而,我们注意到,Multi-Krum可以检测并删除单个恶意行为者[10]。虽然Multi-Krum并不是为非iid设置而设计的,而且在非iid设置中表现不佳,但我们进行了一个实验,在实验中,我们用一个适当参数化的Multi-Krum解决方案增强了FoolsGold,其中f = 1。
我们考虑一个理想的strawman attack(稻草人攻击?),其中单个对抗性客户端在每次迭代中将向量发送到中毒目标。这种攻击不需要密码,因此可以绕过FoolsGold。图12显示了在面对并发的A-5攻击和理想的稻草人攻击时,FoolsGold、Multi-Krum和两个系统的训练准确率和攻击率。
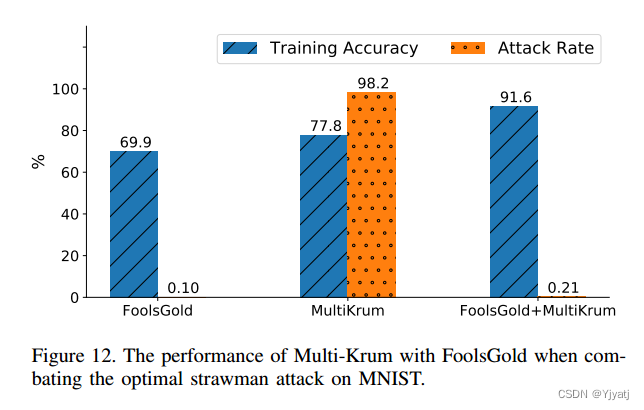
当 Multi-Krum 参数设置为 f = 1 并且 FoolsGold 也同时启用时,这两种方法并不会相互干扰。Multi-Krum 方法可以有效地防止所谓的“稻草人攻击”,即一种特定的攻击方式。同时,FoolsGold 方法可以防止另一种名为“sybil 攻击”的攻击。然而,独立地运行这两种方法时,它们各自都无法同时有效地防御这两种攻击。可能会出现其中一种方法无法检测到针对它自身的攻击,或者另一种方法允许攻击者通过“sybil”攻击方式来使系统陷入困境。
FoolsGold是专门为处理来自一组sybils的中毒攻击而设计的:我们认为目前的技术状态更适合于减轻来自单个参与者的攻击。
Improving FoolsGold against informed attacks. 改进FoolsGold对抗知情攻击。
在图9中,我们观察到FoolsGold可以被一个知情的对手用许多sybil破坏。
我们认为非决定论non-determinism(不知道他说的这个是啥?) 可能会进一步帮助改进FoolsGold。例如,通过在history机制中使用梯度的加权随机子集,或者通过测量客户贡献的随机子集之间的相似性。有了更多的随机性,知情的对手就更难以利用对FoolsGold设计的了解来获得优势。
另一个解决方案是使用更好的相似性度量。这包括先前工作的策略,如结合基于图的相似性[41],使用来自客户数据集的辅助信息[39],或强制设置最小相似性分数以拒绝异常贡献。这些解决方案虽然更了解情况,但也需要对攻击的性质有更多的假设。
8. Related work
我们回顾了联邦学习中防止中毒的最新技术Multi-Krum[10]。在这里,我们回顾安全ML, sybils和中毒更广泛的文献。
安全机器学习:在联邦学习中减少sybil的另一种方法是使整个系统更加安全。例如可信执行环境(如SGX)是另一种解决方案[33]。然而,我们注意到,基于sybil的中毒可以在数据输入级别执行,而这是不受SGX保护的。即使在运行可信代码的安全区域中,也可以通过恶意数据执行中毒攻击。FoolsGold可以添加到基于SGX的系统中,以防止sybil攻击。
其他解决方案利用数据来源来防止中毒攻击[5],方法是对可能是恶意的模型进行分割、识别和删除训练数据。该解决方案需要对如何收集训练数据和在联邦学习中进行额外的假设,其中许多客户端从各种来源提供数据,这种假设是不现实的。
sybils防御。减轻sybils的一种方法是使用工作量证明[3],其中客户端必须解决计算成本高的问题(易于检查)才能为系统做出贡献。最近的替代方案已经探索了权益证明的使用[19],它根据客户在系统中的权益价值来衡量客户。
(工作量证明(Proof of Work,PoW)是一种计算密集型的机制,通常用于加密货币网络中,比如比特币。这个机制要求计算机完成一定量的复杂计算,以证明其完成了一项“工作”,并且验证者能够在较短的时间内验证这一工作的合法性。在加密货币中,这种工作通常是在区块链上添加新区块时所完成的计算。这个过程需要大量的计算能力和时间,因此能够有效限制某个节点或者用户对网络的控制权。
权益证明(Proof of Stake,PoS)是一种区块链共识机制,用于验证和确认交易以及创建新的区块。与权益证明相关的概念是区块链中的共识算法,它与“工作量证明”(Proof of Work,PoW)不同,后者是比特币等一些区块链网络使用的共识机制。
在权益证明中,区块链的验证者(也称为“矿工”)被选中创建新的区块的几率是基于其拥有的加密货币数量。换句话说,持有更多加密货币的人更有可能被选中验证新的交易并获得相应的奖励。
权益证明机制旨在减少能源消耗和计算资源的浪费,与工作量证明相比,它不需要进行大量的计算来解决复杂的数学问题。这种机制被一些区块链项目采用,因为它被认为在环保和效率方面具有优势。然而,权益证明也有一些争议和挑战,例如富者愈富等一些可能导致的问题。)
一些方法使用辅助信息主动检测和删除sybills,例如底层社交网络[38],或者检测和拒绝恶意行为[39],[40]。许多sybil检测策略将客户端之间的交互映射到加权图中,并使用来自社交网络的sybil防御[41]作为减少。然而,联邦学习限制了向中央服务公开的信息量,而这些防御可能依赖于危及隐私的信息。相比之下,FoolsGold在学习过程之外不使用任何辅助信息。
其他ML中毒防御。另一种中毒防御涉及袋装分类器[8],以减轻系统中异常值的影响。这些防御措施在集中数据集的场景中是有效的,但在禁止访问数据的联邦学习设置中应用起来很复杂。该算法还承担了训练过程中梯度计算的控制。
"装袋分类器"(Bagging Classifier)是一种集成学习方法,其核心思想是通过构建多个独立的分类器并结合它们的预测结果来改善整体的分类性能。它的工作方式是通过对原始数据进行随机有放回抽样(bootstrap sampling),生成多个不同的训练集,然后在每个训练集上训练一个基本分类器。最终的预测结果是通过对这些分类器的预测进行平均或投票来得出。
常见的装袋分类器算法包括随机森林(Random Forest),它是一种基于决策树的装袋方法。通过建立多个决策树,并根据这些树的预测结果来做出最终的预测,随机森林可以有效地处理数据中的噪声和异常值,从而提高整体分类性能。
AUROR[36]是为多方ML设置设计的防御。它将指示性特征定义为最重要的模型特征,并收集对这些特征的修改分布并将其提供给聚类算法。超过阈值距离的小集群的贡献将被删除。这种聚类假设该特性的大部分更新都来自所有指示性特性的诚实客户端。与AUROR不同的是,FoolsGold假定存在sybil,并使用梯度相似性来检测异常客户端。
9. Conclusion
日益增长的隐私和可扩展性挑战驱动着ML的去中心化的发展。为了解决这些挑战,联邦学习(Federated Learning)成为了一种被应用于生产环境的最先进的技术提议 [27]。
然而,这种去中心化为恶意客户参与培训打开了大门。为了达到中毒的目的,我们考虑了sybil中毒攻击的问题。我们证明了现有的对此类攻击的防御是无效的,并提出了FoolsGold,一种利用客户端贡献相似性的防御。
我们的研究结果表明,FoolsGold能够缓解各种攻击类型,即使在Sybil(虚假身份)压倒性地混入诚实用户的情况下也很有效。我们还考虑了高级攻击类型,其中Sybil混合了恶意数据和诚实数据,给他们的更新添加了智能噪音,并自适应地限制其恶意更新的速率以避免被检测。在所有场景下,我们的防御能够胜过以往的工作。FoolsGold对联邦学习算法的改动很少,依赖于诸如余弦相似性等标准技术,并且不需要关于预期Sybil数量的先验知识。我们希望我们的工作能够激发对与基础学习过程共同设计的防御措施进行进一步研究。
附录:
附录A:Convergence analysis(收敛性分析)
附录B:Additional Evaluations(附加评估)

















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









