







前言
论文 “PDGAN: A Novel Poisoning Defense Method in Federated Learning Using Generative Adversarial Network” 的阅读笔记,本博客总结了其最主要的内容。
阅读前提:对联邦学习(federated learning)和生成对抗网络(generative adversarial network)有一定的了解。
论文相关信息
- 标题
PDGAN: A Novel Poisoning Defense Method in Federated Learning Using Generative Adversarial Network - 出处和年份
| 出处 | 年份 |
|---|---|
| Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) | 2020 |
- 论文作者及其工作单位
| 作者 | 工作单位 |
|---|---|
| Zhao, Ying Chen, Junjun Zhang, Jiale Wu, Di Teng, Jian Yu, Shui |
关键词
Federated learning · Poisoning defense · Generative adversarial network
概述
一种针对于联邦学习中投毒攻击的防御方法
论文研究的问题及其意义
| 研究的问题 | 该研究的意义 |
|---|---|
| 在联邦学习中,攻击者可以使用投毒攻击让服务器的全局模型对某中类别的样本失效 | 可以发现哪些个服务端是攻击者,从而忽略它们上传的参数达到防御目的 |
现有方法及其优缺点
| 方法 | 优点 | 缺点 | 文献 |
|---|---|---|---|
| Secure multiparty computation and homomorphic additive cryptosystem | introduce huge computa- tion overhead to the participants and may bring a negative effect on model accu- racy | [10–12] | |
| Byzantine-tolerant machine learning methods | [13,14] | ||
| anomaly detection techniques | |||
| k-means and clustering: to check the participants’ updates across communication rounds and remove the outliers | [9,15,16] | ||
| cosine similarityand gradients norm detection | [17,18] |
上述各种方法在联邦学习框架下的效果都不好,因为各客户端的训练数据是非独立同分布的,这导致了各客户端上传的更新彼此之间是非常不同的。
论文的思路和方法及其优缺点
| 思路和方法 | 优点 | 缺点 |
|---|---|---|
| 由于不知道各客户端的数据,所以在服务器设置一个GAN来产生一个测试数据集,利用各客户端本地模型在此数据集上的打分来判断哪个客户端是攻击者。预先设定一个阈值,打分低于这个阈值的客户端被视为攻击者,在以后的训练当中忽视它上传的更新。 |
- PDGAN 的框架
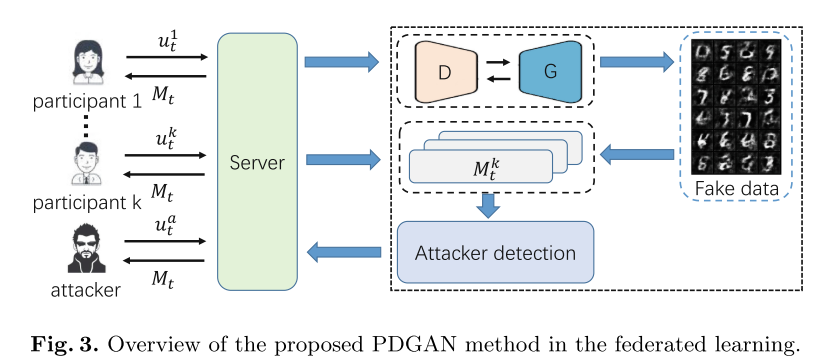
(1) G : G: G:产生fake data

(2) D : D: D: 服务器的全局模型作为discriminator,对 G G G产生的fake data进行判别

论文使用的数据集和实验工具
| 数据集 | 实验工具 | 源码 |
|---|---|---|
| MNIST,Fashion-MNIST | 语言框架:PyTorch, 硬软件设备:Intel Xeon W-2133 3.6 GHz CPU, Nvidia Quadro P5000 GPU with 16G RAM and RHEL7.5 OS |
论文的实验方法
- 设立了两种情形:
(1) 1 attacker, 9 benign pariticipants, totally10 participants
(2) 3 attackers, 9 benign pariticipents, totally 10 participants - 训练数据随机分配给10个participants
- 攻击任务
(1) 对于 M N I S T MNIST MNIST数据集:使全局模型对标签1判定为标签7
(2) 对于 F a s h i o n − M N I S T Fashion-MNIST Fashion−MNIST数据集:使全局模型对标签T-shirt判定为标签Pullover - 模型的评价标准
(1) poisoning accuracy: 将投毒样本分类为攻击者设定的类别的成功率
(2) overall accuracy: 对所有样本正确分类的成功率
有个问题,攻击者要让服务器将1判别为7,正确分类是说服务器仍将1分类为1,还说将1分类为7也是“正确判别”? - 数据重构
(1) M N I S T : MNIST: MNIST: 经过大概400轮的迭代,可以产生较为清晰的fake data,可以用来对每个客户端进行评测从而确定哪一个是投毒攻击者。
服务器端的auxiliary data包括标签为0和4的数据,用于喂入discriminator。

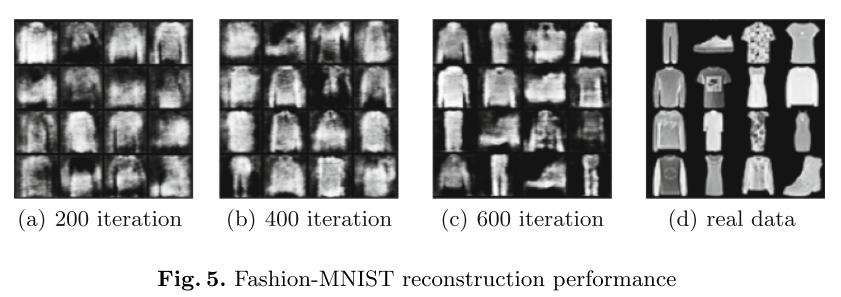
(2)
F
a
s
h
i
o
n
−
M
N
I
S
T
:
Fashion-MNIST:
Fashion−MNIST: 经过大概600轮的迭代,可以产生较为清晰的fake data,可以用来对每个客户端进行评测从而确定哪一个是投毒攻击者。
服务器端的auxiliary data包括标签为dress、coat和sandal的数据,用于喂入discriminator。
- 服务器端开始检测攻击者的时机
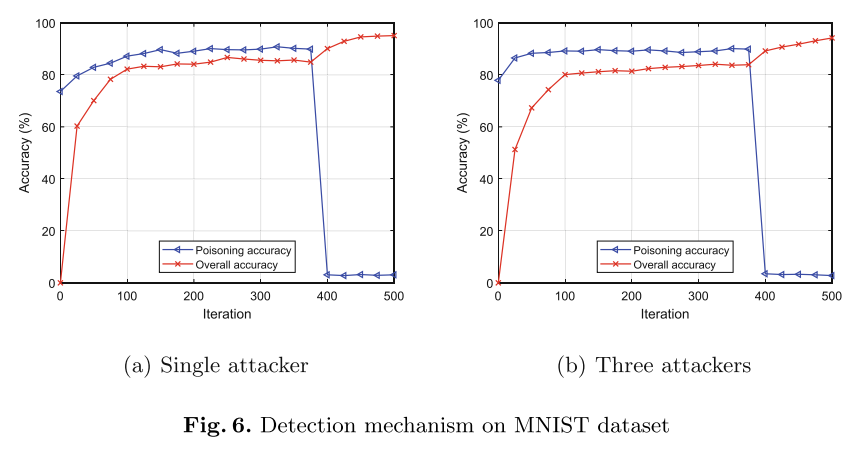
(1) M N I S T MNIST MNIST数据集:实验设置服务器经过400的迭代后,将generator产生的fake data用于检测投毒攻击者
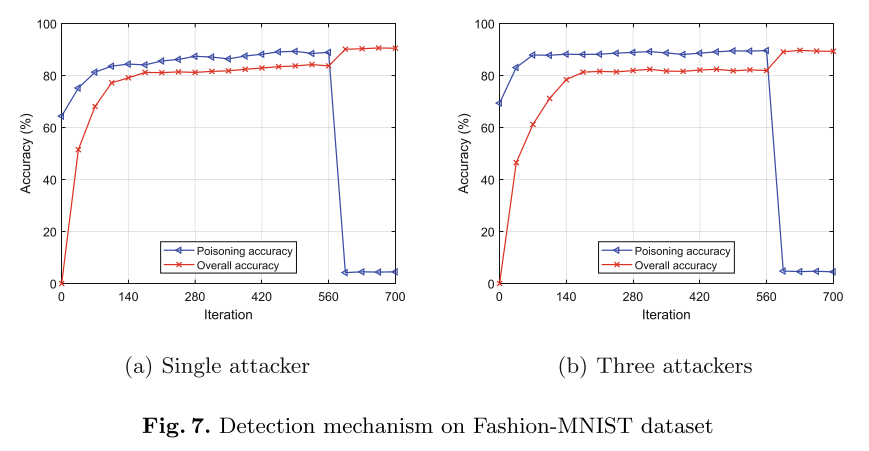
(2) F a s h i o n − M N I S T Fashion-MNIST Fashion−MNIST数据集:实验设置服务器经过600的迭代后,将generator产生的fake data用于检测投毒攻击者
实验结果
- 对于 M N I S T MNIST MNIST数据集,400轮迭代后,服务器端开始使用generator产生的fake data来检测攻击者,可以看到攻击者的攻击效果迅速降低(poisoning accurac迅速降低到3.1%)。对于 F a s h i o n − M N I S T Fashion-MNIST Fashion−MNIST数据集,则是从600迭代后开始检测攻击者。
- 3个attacker的攻击效果更好(posioning accuracy上升得更快)。
















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











