






基础知识
1.导入外部模块/库 import
2.类中成员变量的权限修饰符
__name__ 系统定义的
_name 受保护的,仅类的实例和子类的实例可访问
__name 私有的
3. Pycharm的快捷按键
1. Shift+F10执行该.py文件或是以该文件替换你的代码。
2. 双击Shift以全局搜索,可以搜索 类,文件,工具窗口,动作(actions)以及设置。
3. Ctrl+F8在光标所在行添加一个断点。
4. #注释 Ctrl+/ “”” “””多行注释。
5.当前文件查找 Ctrl+F 全局查找Ctrl+Shift+F 替换Ctrl+R 全局替换Ctrl+Shift+R
6.关于库的安装
pip install -i +
https://pypi.tuna.tsinghua.edu.cn/simple #清华镜像网站
http://mirrors.aliyun.com/pypi/simple/ #阿里云
http://pypi.douban.com/simple/ #豆瓣
https://pypi.mirrors.ustc.edu.cn/simple/ #中国科技大学
http://pypi.hustunique.com/ #华中理工大学
http://pypi.sdutlinux.org/ #山东理工大学
4.关于 PEP 8
(1)命名规范
PEP8 中对Python的良好的编程习惯做了示范,举个例子:

上图中下划线画出来的是“推荐的”写法,圈出来的是以大写区分的驼峰式写法,PEP 8不推荐 函数名、局部变量名使用大写字母。
具体如下:
库名、函数名、局部变量名:
全小写,以下划线分开:line_str
全局变量:
全大写,以下划线分开:NAME_LIST
类名:
以大写字母区分的驼峰式命名:NameDict
(2)代码书写
1.函数定义应空出两个空白行


2.文件末尾不能有(无用的)空白行

3.换行书写不必加反斜杠(backslash)

内部库函数
1. eval() 将str类转换为其内容对应的类
2.<classname>() 将任意类型的数据转换为该类型
数据类型
【在讨论这个问题之前,有一天必须阐明,那就是python同C++一样,里面的一切概念的基础都是“类”,也就是说单纯的数据“类型”是不存在的,str, list, dict都指的是对应的类。】
按照变量的类型是否为原子类型,可分为:
标量类型:其本身是一个整体,没有可分开访问的内部结构,不可再分的数据类型
bool
int
float
complex(复数)
None
非标量类型:结构化的类型,具有可供分开访问的内部结构
list
tuple
str
dict
range
set
按照变量类型是否可变,分为:
可变数据类型:该类型的对象可以修改,不可哈希(unhashable)
list
dict
set
不可变数据类型:该类型的对象不可修改,可哈希(hashable)
str
tuple
int, float, complex, None, bool
正则表达式(Regular Expression)---相关库:re
正则表达式的构成
一个完整的正则表达式由一下部分组成:
检索条件 + 检索次数 + 检索模式
1.检索条件
正则表达式的核心部分,用户在此指定内核将以何种方式去检索(匹配)某字符串。
2.检索次数
检索条件一般是单字符检索,要想完全处理字符串不可能写多次单字符的条件,有以下几种次数的字符表达:
* # 匹配任意次(0到多次)
+ # 匹配1到多次
? # 0次或者1次
{m} # 准确匹配m位
{m,} # 至少m位
{m,n} # 匹配 [m,n]闭区间所表示的次数
-》写几个简单的示例,
匹配字符串中含有指定字符的部分 [abc]*
只取字符串开头的有效字 \w
取字符串结尾的字符 .$
匹配指定字符以外的任何字符 [^abc]
3.检索模式
Python正则表达式默认的检索模式是贪婪模式,即意为在多数的检索次数下,尽可能地多地去检索指定字符串;
---》如何转变检索模式到“尽可能少地去检索”呢?
在检索次数的后面紧跟着写一个’?’即可。
正则表达式的书写规则(PEP 8规范):
在正式的开发工作当中,SDK或IDE的警报不太可能会影响程序的运行,但在初学阶段,经常阅读警告并尝试去解决,将自己与先进开发者去对齐,我认为是大有裨益的。
以下图为例:

以正则表达式的书写为例,在PEP 8 的命名规范当中,不推荐使用直接反斜杠直接转义的写法,诸如’\d’’\w’此类,因为Python中’\’有实际含义,所以在正则表达式中用”\\”来表示一个反斜杠;或是直接只用r字符串。
另外,如果想要在正则表达式中表示一个普通的反斜杠符号,则需要四个反斜杠,即”\\\\”。
解决方案如下:

不过实际测试下来,是否遵守这个命名规范并不会影响正则表达式的执行,要么是解释器做了优化,要么就是开发工具做了优化,这个就无所谓了。
几个重要函数:搜索(search)、匹配(match)、替换(sub)、查找(findall)
参数flags为正则表达式的模式设定位,以下是可选的标志:

【以下函数参考了菜鸟教程中的详解,感谢】
函数1:search()

功能:扫描整个字符串然后返回第一个成功的匹配
返回值:类Match[bytes]的对象 或 空

-------》下面是一些简单的示例:
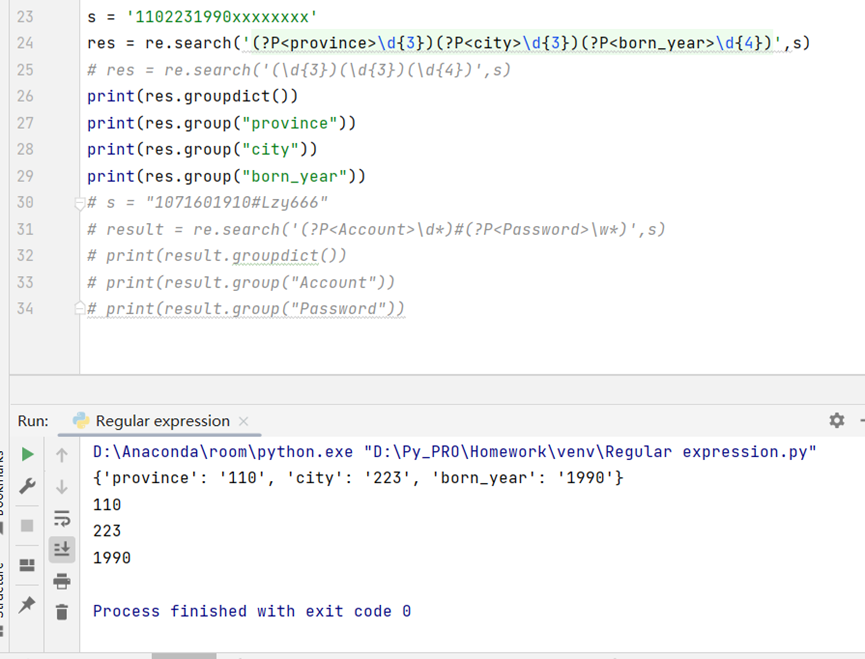
实例:提取给定字符串中的指定字段(仅第一次)

实例:从给定字符串当中以一定的规则实现有效信息的提取并为每一个子串起名,可以放入字典中

函数2.findall()

功能:搜索整个字符串并返回所有匹配的结果
返回值:类list的对象(列表)

实例:检索一个字符串中所有的数字

函数3.match()

功能:从字符串的开头开始匹配,若不满足正则表达式,则立即返回None
返回值:类Match[bytes]的对象 或 空
问题:Match()与search()有什么区别???
函数match()从给定字符串的起始位置(字符)匹配,一旦不满足指定的正则表达式,立即返回None;
而函数search(),扫描给定字符串的全部内容,并返回第一次的检索结果。
实例:匹配字段

matchObj1处理流程是从str1字符串开头匹配一个字符’a’,并无视字母的大小写(re.I)。
matchObj2处理流程是从str2字符串开头匹配尽可能多的任意个字符,直到字符‘v’。

此处与上个实验大同小异,
对比两个mathcObj1的实验结果,说明match的匹配规则是从头开始匹配,不满足规则立即返回None。
另外,需要指出的是这里的matchObj2的处理启用的是怠惰模式,即按照正则表达式的规则,尽可能少地去匹配字符。
函数4.sub()

功能:按照pattern与flags指定的规则对string进行替换,将匹配内容替换为repl
返回值:类bytes的对象



实例:从杂乱字符串中提取有效信息

Matplotlib绘图
常规颜色设置参考图:

渐变颜色条:
(更多详见https://matplotlib.org/2.0.2/examples/color/colormaps_reference.html)


















 1656
1656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









