







OpenDILab新开设了混合动作空间专栏,将从离散动作空间和连续动作空间入手,为大家介绍混合动作空间的起源和发展,并解读一系列学术界相关paper。
本文作为混合动作空间系列专题文章的第一篇,主要是介绍混合动作空间的类型以及经典环境,公式不多,可以放心食用~
近年来,强化学习的混合动作空间(Hybrid Action Space) 逐渐成为热门话题。动作空间是强化学习问题里的一个重要设定。我们训练一个人工智能体,都离不开动作空间。
动作空间的重要性有以下两点,设计良好的动作空间,对于强化学习算法的训练非常重要:
1.处理不同的动作空间类型,需要采取不同的优化算法;
2.动作空间的复杂性也影响着RL算法的性能表现。
一个典型的强化学习环境通常是离散(Discrete) 或连续 (Continuous) 动作空间。有很多朋友对强化学习环境很感兴趣,想要深究钻研。
在此推荐下我们的强化学习平台DI-engine,平台介绍了目前强化学习领域各种经典的离散/连续/混合动作环境,也总结了各种RL算法所适用的动作空间类型。
✨DI-engine项目repo地址:![]() https://github.com/opendilab/DI-engine
https://github.com/opendilab/DI-engine

离散动作空间指动作的可取值是有限个离散的数值,比如
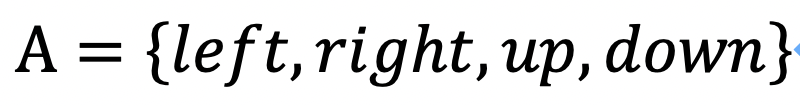
。
常见的解决离散动作空间的RL经典算法有 DQN(Human-level control through deep reinforcement learning)、A2C(Asynchronous Methods for Deep Reinforcement Learning) 等。
✨DQN介绍:![]() https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf
https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf
✨A2C介绍:![]() https://arxiv.org/pdf/1602.01783.pdf
https://arxiv.org/pdf/1602.01783.pdf
例如,Atari是最经典最常用的离散动作空间强化学习环境,常作为离散动作空间强化学习算法的基准测试环境。
✨Atari详细指南:![]() https://di-engine-docs.readthedocs.io/zh_CN/latest/env_tutorial/atari_zh.html
https://di-engine-docs.readthedocs.io/zh_CN/latest/env_tutorial/atari_zh.html

Atari强化学习环境

连续动作空间指动作的可取值是无限个连续的数值,比如
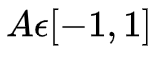
。常见的解决连续动作空间的RL经典算法有 DDPG、ACER。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1516
1516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









