






源博客地址:www.ozyblog.top
介绍
IK Analysis插件将Lucene IK分析器集成到elasticsearch中,支持自定义词典
es分词原生只能支持英文分词,IK支持中文分词
安装
先创建目录,ik是每个es都要创建:
root@ozy-linux:/home/ozy/Downloads# mkdir -p /usr/local/elasticsearch/es1/elasticsearch-7.4.2/plugins/ik
root@ozy-linux:/home/ozy/Downloads# mkdir -p /usr/local/elasticsearch/es2/elasticsearch-7.4.2/plugins/ik
root@ozy-linux:/home/ozy/Downloads# mkdir -p /usr/local/elasticsearch/es3/elasticsearch-7.4.2/plugins/ik然后解压:
unzip elasticsearch-analysis-ik-7.4.2.zip -d /usr/local/elasticsearch/es1/elasticsearch-7.4.2/plugins/ik/
unzip elasticsearch-analysis-ik-7.4.2.zip -d /usr/local/elasticsearch/es2/elasticsearch-7.4.2/plugins/ik/
unzip elasticsearch-analysis-ik-7.4.2.zip -d /usr/local/elasticsearch/es3/elasticsearch-7.4.2/plugins/ik/授权:
chown -Rf es:es /usr/local/elasticsearch/重启ES,测试
测试 创建索引库:
后记:这种curl容易语法出错,建议用后面的head插件,这种方法看看就好
curl -X PUT http://localhost:9200/ik -H 'Content-Type:application/json' -d'{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}'第一个参数是分片数,第二个参数是副本数
好像出错了,设置不起作用,还是用head插件吧:
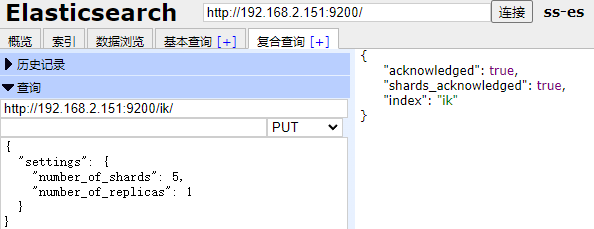
使用
设置mapping
Analyzer分词配置解释:
- ik_smart:粗粒度分词,比如中华人民共和国国歌,会拆分为中华人民共和国,国歌;
- ik_max_word:细粒度分词,比如中华人民共和国国歌,会拆分为中华人民共和国,中华人民, 中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌,会穷尽各种可能的组 合。
Text 数据类型被用来索引长文本,比如说电子邮件的主体部分或者一款产品的介绍。这些文本会被 分析,在建立索引前会将这些文本进行分词,转化为词的组合,建立索引。允许 ES来检索这些词语。 Text 数据类型不能用来排序和聚合。
Keyword 数据类型用来建立电子邮箱地址、姓名、邮政编码和标签等数据,不需要进行分词。可以 被用来检索过滤、排序和聚合。 keyword 类型字段只能用本身来进行检索。
当然还有其他类型,后面再说
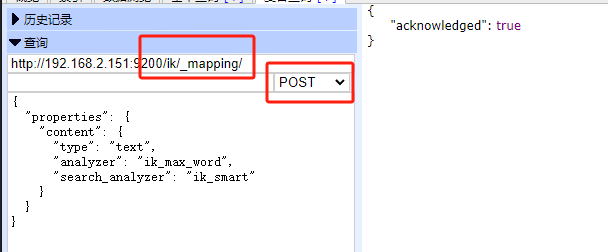
创建mapping:

使用head来请求
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
插入数据:
curl -XPOST http://localhost:9200/ik/_create/1 -H 'ContentType:application/json' -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}
'
curl -XPOST http://localhost:9200/ik/_create/2 -H 'ContentType:application/json' -d'
{"content":"公安部:各地校车将享最高路权"}
'
curl -XPOST http://localhost:9200/ik/_create/3 -H 'ContentType:application/json' -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
'
curl -XPOST http://localhost:9200/ik/_create/4 -H 'ContentType:application/json' -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
' 实测我的电脑还是不能用curl,老老实实用head吧:
查询:
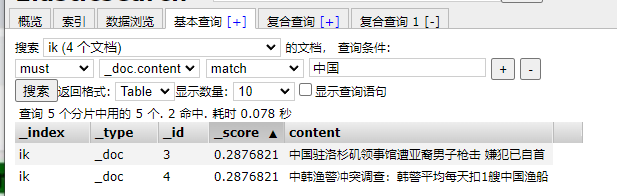
如果需要高亮显示匹配的内容:
{
"query": {
"match": {
"content": "中国"
}
},
"highlight": {
"pre_tags": [
"<font color=red>"
],
"post_tags": [
"</font>"
],
"fields": {
"content": {}
}
}
}实际业务肯定是从数据库中拿数据查询,所以linux需要安装mysql,下一篇安装mysql















 1184
1184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









