






残差连接(residual connection):为了在反向传播过程中不造成梯度消失。所以使神经网络在输出时增加一项x,则该层网络对x求偏导的时候,就会有一个常数项。
ROI(region of interest):指从图像中选择的感兴趣区域。
自注意子层(' Self '):建立起模态内的联系。
双向交叉注意子层(‘Cross’):用于交换信息和对齐两种模态间的实体,以建立跨模态的联系。
主要贡献
1、构建了一个大型Transformer模型。
2、使用五个不同的代表性任务预训练模型。
3、赋予模型跨模态预训练的能力。
模型框架
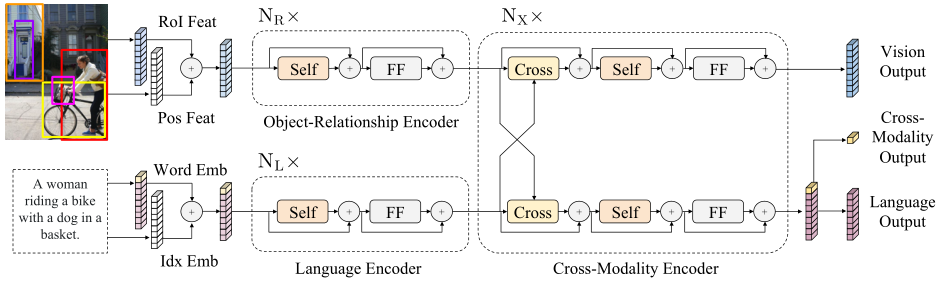
LXMERT框架主要由三个Transformer编码器组成:对象关系编码器(object relationship encoder),语言编码器(language encoder)和交叉模态编码器(cross-modality encoder)。整体框架的输入为一个图像句子对,输出为同规格的图像句子对,以及一个跨模态输出。
单模态编码器(object relationship和language )
编码器的每层包含一个自注意(' Self ')子层和一个前馈(' FF ')子层,而前馈子层又由两个全连接层组成,每个子层后又加了残差连接和层归一化(由“+”表示),输入为图像或语言的特征序列,其中,语言特征序列hi表示为:

将单词wi及其在句子中的位置i一同嵌入向量特征中。
图像特征序列vj表示为:
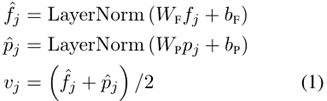
将Faster R-CNN提取的区域特征fj以及特征框的位置特征pj通过全连接层后共同组成图像特征。
交叉模态编码器(cross-modality)
编码器的每个跨模态层由一个双向交叉注意(‘Cross’)子层、两个自注意子层和两个前馈子层组成。其中‘Cross’层包含两个单向交叉注意子层:从语言到图像(L->R)、从图像到语言(R->L)。对于编码器第k层,‘Cross’层输出为:
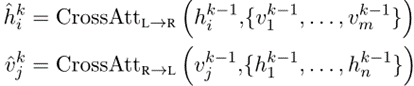
其再经过' Self '层输出:
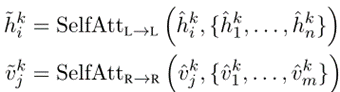
最后,经过前馈子层(' FF ')产生第k层输出![]() 和
和![]() 。
。
预训练策略
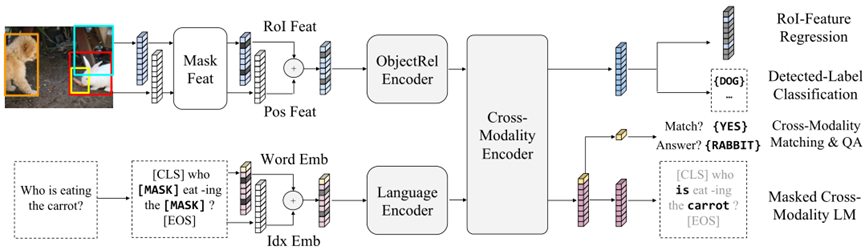
包含五个训练任务:
(1)掩码跨模态语言建模(Masked Cross-Modality LM )。每个单词以0.15的概率被随机遮掩,并让模型来预测这些遮掩单词。与BERT不同,LXMERT不仅可以通过剩余单词来预测掩码词,还可以跨模态,用图像特征来预测。这更有助于建立从图像模态到语言模态的连接。
(2)通过RoI特征回归进行掩码对象预测(RoI-Feature Regression)。以0.15的概率随机屏蔽对象,并让模型预测这些被屏蔽对象的特性。具体是使用L2损失来预测被屏蔽对象的RoI特征fj,此任务不需要语言特征,可以使模型建立图像模态内的联系。
(3)通过检测标签分类进行掩码对象预测(Detected-Label Classification)。为了学习带有交叉熵损失的被屏蔽对象的标签,其结合了视觉信息和语义信息进行联合预测。本文未采用预训练图像本身的注释,而是采用Faster R-CNN检测到的标签。
(4)跨模态匹配(Cross-Modality Matching )。每个句子有0.5的概率被一个不匹配的句子替换。然后,训练分类器来判断图像和句子是否匹配。目的是检测模型将语言信息与视觉信息的对齐效果。
(5)图像问题回答(QA)。当图像和问题匹配时,要求模型去预测这些与图像相关的问题的答案。
本文采用的这种多模态预训练策略不仅可以使模型从相同模态的可见区域中推断出被掩码的特征,甚至可以从不同模态的对齐组件中推断出掩码特征。这利于建立模态内关系和跨模态关系。
实验结果
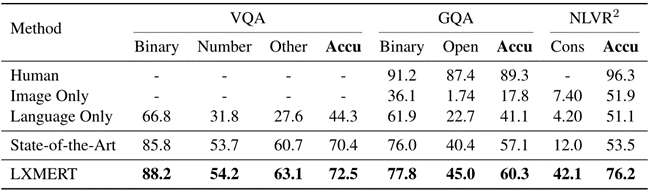
本文使用三个数据集来评估LXMERT框架:VQA v2.0,GQA 和NLVR。同时又比较了最先进的方法(SotA)、人类表现、仅图像、仅语言的结果。
NLVR:康奈尔自然语言视觉推理,是一种语言基本数据集。包含92244对自然语言语句的基础上合成图像。每个数据都有两个自然图像img0, img1和一个语言语句s。任务是确定句子是否是真实的或虚假的图像。数据是通过众包收集的,并且需要关注对象集、数量、比较和空间关系的推理。















 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









