







这篇文章提出的模型在视觉问答(VQA,GQA)上得到了最好的结果,甚至今年后续以此为基础或对照的的文章都没有超越这个结果。论文中很多地方提到这一方法是用到了BERT模型的方法(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding)
参考博客:博客
整个模型,作者意图是将其称为预训练,输出的视觉,语言和跨模态结果用于下游视觉模型中。
直接上图,

从图中可以看到,模型整体流程并不难懂,首先是得到视觉和文本的嵌入,然后先进行单模态的自注意编码(这里似乎没有加入跨模态的门机制进行自注意,虽然最近的注意力模型主要是连接方式不一样,但是为什么这篇文章的结果就能达到目前最好的效果,值得深入考虑,回头再说)。再进行跨模态的注意,并且这些编码模块会进行多次注意(其中Nr,NL,Nx分别是5,9,5)。最终得到的是处理后的视觉,语言和跨模态输出。
和大多数模型不同,LXMERT在使用了来自BERT的掩码方法得到特征嵌入,并且最后多出了一个跨模态输出.下面将重点介绍这几点,
一,语言任务:蒙版跨模态LM
语言任务设置和BERT几乎相同,单词以0.15的概率随机遮掩。不同的是LXMERT模型中遮掩的词除了可以从非掩蔽词语表示以外还可以从视觉模态去预测,从而解决歧义问题。所以称为Masked Cross-Modality LM。
二,视觉任务:蒙盖对象预测
同样以0.15的概率屏蔽对象的特性,同样,屏蔽对象的特性也是跨模态的。所以总体来说,视觉和语言都是通过遮掩的方式实现了跨模态的预测编码。
三,模型(编码器)
单模态编码:视觉和语言两个模态的自注意和一个前馈子层,不同的是视觉编码器循环迭代连接五次,而语言编码器循环迭代连接九次
多模态编码:
{hki}表示第i个单词在第k层语言特征,{vKj}表示第j个单词在第k层的视觉特征

为了进一步建立内部联系,自我主义子层被应用到交叉注意层,公式如下:

这种方式,同样令人想到DFAF那篇文章,如图1所示,和单模态一样,每个子层后面接了一个残差连接和层归一化。
输出:其中跨模态的输出是和BERT一样,在每个句子之前加上一个特殊标记。在语言特征的句子中,特殊标记相应的特征向量作为跨模态输出

四,训练数据
汇总了MSCOCO和视觉基因组,VQA2.0,GQA和VG-QA,提供了一个大的对其视觉和语言数据集。在18万张不同的图像上有9.18万幅图像和句子对。在符号方面,训练前的数据包含约1亿单词和650万图像对象。
评估框架的数据集是VQA 2.0,GQA和NLVR2
实验
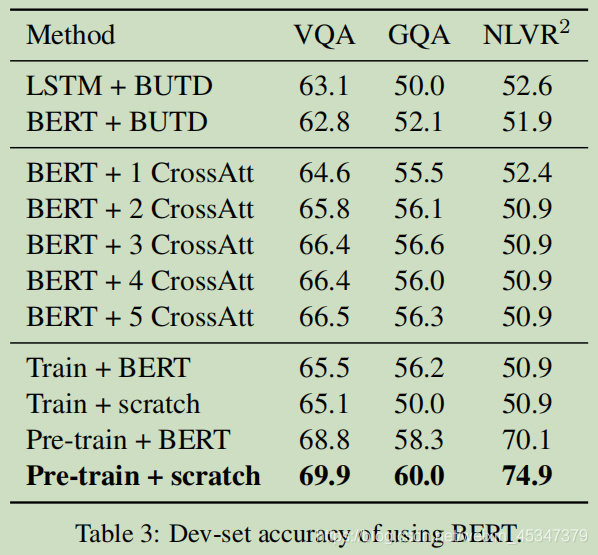
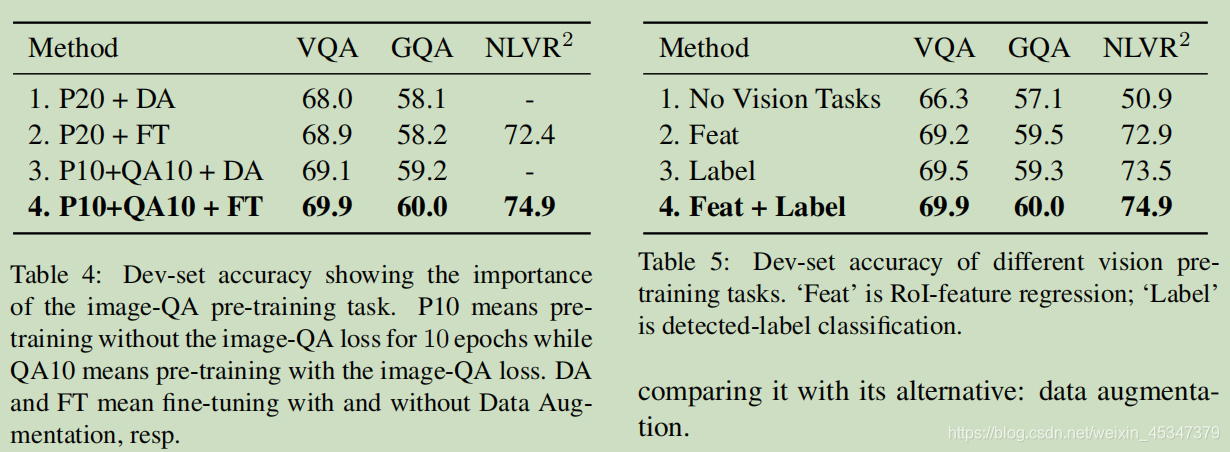
结果



















 1159
1159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









