







Citation:: [1]
B. Su, H. Zhang, and Z. Zhou, “HSIC-based Moving Weight Averaging for Few-Shot Open-Set Object Detection,” in Proceedings of the 31st ACM International Conference on Multimedia, Ottawa ON Canada: ACM, Oct. 2023, pp. 5358–5369. doi: 10.1145/3581783.3611850.
Abstract
We study the problem of few-shot open-set object detection (FOOD), whose goal is to quickly adapt a model to a small set of labeled samples and reject unknown class samples. Recent works usually use the weight sparsification for unknown rejection, but due to the lack of tailored considerations for data-scarce scenarios, the performance is not satisfactory. In this work, we solve the challenging few-shot open-set object detection problems from three aspects. First, different from previous pseudo-unknown sample mining methods, we employ the evidential uncertainty estimated by the Dirichlet distribution of probability to mine the pseudounknown samples from the foreground and background proposal space. Second, based on the statistical analysis between the number of pseudo-unknown samples and the Intersection over Union (IoU), we propose an IoU-aware unknown objective, which sharps the unknown decision boundary by considering the localization quality. Third, to suppress the over-fitting problem and improve the model’s generalization ability for unknown rejection, we propose the HSICbased (Hilbert-Schmidt Independence Criterion) moving weight averaging to update the weights of classification and regression heads, which considers the degree of independence between the current weights and previous weights stored in the long-term memory banks. We compare our method with several state-of-the-art methods and observe that our method improves the mean recall of unknown classes by 12.87% across all shots in the VOC-COCO dataset settings. Our code is available at http s:/github.com/binyisu/food.
我们研究的是少数几个镜头的开放集对象检测(FOOD)问题,其目标是使模型快速适应一小部分标记样本,并剔除未知类样本。近期的研究通常使用权重稀疏化来进行未知剔除,但由于缺乏对数据稀缺场景的针对性考虑,其性能并不令人满意。在这项工作中,我们从三个方面解决了具有挑战性的少镜头开集物体检测问题。首先,与以往的伪未知样本挖掘方法不同,我们采用了由 Dirichlet 概率分布估计出的证据不确定性,从前景和背景提议空间中挖掘伪未知样本。其次,基于伪未知样本数量与联合交集(IoU)之间的统计分析,我们提出了一种 IoU 感知未知目标,通过考虑定位质量来锐化未知决策边界。第三,为了抑制过拟合问题并提高模型对未知剔除的泛化能力,我们提出了基于 HSIC(希尔伯特-施密特独立准则)的移动权重平均法来更新分类和回归头的权重,该方法考虑了当前权重与存储在长期记忆库中的先前权重之间的独立程度。我们将我们的方法与我们将我们的方法与几种最先进的方法进行了比较,发现我们的方法在 VOC-COCO 数据集设置的所有镜头中将未知类的平均召回率提高了 12.87%。我们的代码见 http s:/github.com/binyisu/food。
Summary
存在问题
- 缺乏对于数据稀缺情况的针对性考虑
- 针对在真实世界场景中的不平衡数据集上进行模型训练的挑战
- 小样本训练在真实世界应用/未知类缺乏泛化能力、在已知类容易过拟合
- 没有用来训练的真实未知数据
提出的方法
- 使用由Dirichlet概率分布预测的[[Evidential uncertainty 证据不确定性]]来挖掘[[Pseudo-unknown sample 伪未知样本]]
- 提出IoU感知未知目标(IoU-aware unknown objective),从而锐化了未知决策边界unknown decision boundary
- 为了降低过拟合以及提高模型对于未知拒绝的泛化能力,引入HSIC滑动权重平均(Hilbert-Schmidt Independence Criterion)
具体实现
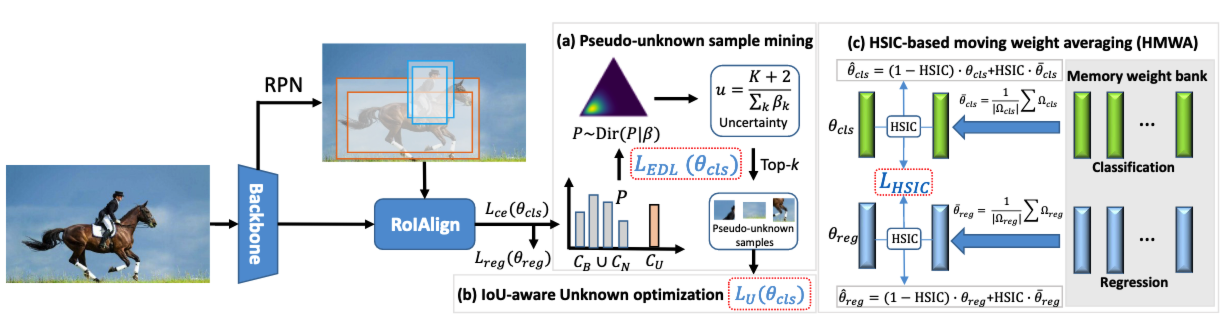
前提 preliminary
- object detection dataset D = { ( x , y ) , x ∈ X , y ∈ Y } D=\{(x,y),x\in \mathbf{X}, y\in \mathbf{Y}\} D={(x,y),x∈X,y∈Y},
- x x x denotes an input image
- y = { ( c i , b i ^ ) } i = 1 I y=\{(c_i,\widehat{b_i})\}^I_{i=1} y={(ci,bi )}i=1I represents the class c c c and box annotation b b b
- D D D contains training set D t r D_{tr} Dtr and testing set D t e D_{te} Dte
- D t r D_{tr} Dtr contains K K K known classes C K = C B ∪ C N = { 1 , ⋯ , K = B + N } C_K=C_B \cup C_N=\{1,\cdots, K=B+N\} CK=CB∪CN={
1,⋯,K=B+N}
- C B = { 1 , c d o t s , B } C_B=\{1,cdots,B\} CB={ 1,cdots,B} represents B B B base known classes
- C N = { B + 1 , ⋯ , K } C_N=\{B+1,\cdots,K\} CN={ B+1,⋯,K} represents N N N novel known classes, each with M M M-shot support examples.
- D t e D_{te} Dte contains C K = C B ∪ C N C_K=C_B \cup C_N CK=CB∪CN known classes and C U C_U CU unknown classes. ( C K ∩ C U = ∅ C_K \cap C_U=\varnothing CK∩CU=∅)
- merge countless unknown categories into one class C U = { K + 1 } C_U=\{K+1\} CU={ K+1}
- K + 2 K+2 K+2 classes in total: K K K known classes (base & novel), 1 1 1 unknown, 1 1 1 background
基线设置 baseline setup
- backbone: [[renFasterRCNNRealTime2016|Faster R-CNN]] (RPN, R-CNN)
- loss: L = L E D L + L U + L H S I C L=L_{EDL}+L_U+L_{HSIC} L=LEDL+LU+LHSIC
伪未知样本挖掘 pseudo-unknown sample mining
- employs the [[Evidential uncertainty 证据不确定性]] estimated by [[Dirichlet Distribution 狄利雷克分布]] of probability to mine pseudo-unknown samples from proposal space: u ( b i ) = K + 2 Δ ( b i ) = K + 2 ∑ k = 1 K + 2 β k ( b i ) u(b_i)=\frac{K+2}{\Delta (b_i)}=\frac{K+2}{\sum^{K+2}_{k=1}\beta_k (b_i)} u(bi)=Δ(bi)K+2=∑k=1K+2βk(bi)K+2
- here, β k \beta_k βk is the class-wise strength, and it is linked to the learned evidence e k e_k ek by the equality β k = e k + 1 \beta_k=e_k+1 βk=ek+1
- the learned evidence is
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









