







本人在学习 Java 的 IO流 时,发现之前对字符编码、Java 中 char 类型的理解完全是错误的,所以开始大量查找资料,破站、知乎、CSDN 都翻了很多。码了好几天时间,由于内容太多,本文是讲的是字符编码,关于 Java 中 char 类型的讲解在另一篇博文:
【字符编码】Java的char类型与Unicode、UTF-16的联系
https://blog.csdn.net/m0_55908255/article/details/147430863?spm=1011.2415.3001.5331看完本文的字符编码,就可以去看上面这篇。希望这两篇博文对各位有帮助
学习视频:
你懂乱码吗?锟斤拷烫烫烫(详解ASCII、Unicode、UTF-32、UTF-8编码)_哔哩哔哩_bilibili
非常详细的字符编码讲解,ASCII、GB2312、GBK、Unicode、UTF-8等知识点都有_哔哩哔哩_bilibili
其他笔记:
https://zhuanlan.zhihu.com/p/363036851
目录
7.3.3 Windows下为什么会有 UTF-8 和 UTF-8 BOM ?
1.前言
相信大家都遇到过打开一个文本文件然后出现乱码的情况,经典的 "锟斤拷" 乱码(bushi),如下:
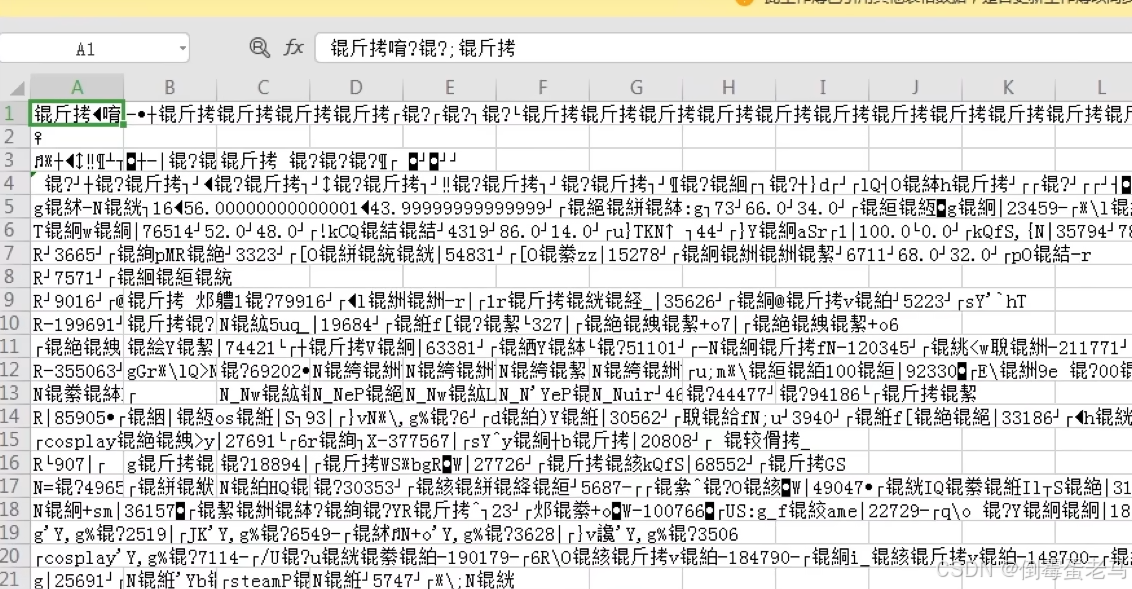
没在深夜见过"锟斤拷"的人,不足以语人生...
好了回归正题,乱码到底是怎么来的呢?知名乱码 "锟斤拷" 又为何如此常见?不着急,要理解乱码,首先需要知道计算是如何存储为文字的:
学过计算机的都知道,计算机只能存储 0、1 这两个二进制数,无论是文本文件里的数字、字母、汉字、标点符号、控制字符、emoji😈👴等都需要用某种方式转换成二进制数字进行存储,需要的时候再读出来
🆗,解释到这里,下面先为大家解释一下后面要用到的名词,然后再开始本文的重点内容
1.1 位(Bit)
计算机存储的最小单位,仅存 0 或 1
1.2 字节(Byte)
字节是计算存储容量的一种计量单位。我们知道计算机只能识别 0、1 组成的二进制数据。一个 0 或 1 就是 1 位(bit),而 8 bit = 1Byte = 1字节。计算机一般以 8 bit = 1Byte = 1字节 为基本单位进行数据的读写
1.3 字符(Character)
字符和字节不太一样,任何一个文字或符号都是一个字符。但一个字符在文本文件中所占的字节不定,而是由采用的编码规范决定一个字符存储到文本文件中时占多少字节
因此不同的编码规范会导致同一个字符在文本文件中所占的字节不同。例如:
'马' 是一个常用的汉字字符,如果采用 GBK 编码规范,'马' 存储到文本文件时会占用 2 个字节 ;如果采用 UTF-8 编码规范,'马' 存储到文本文件时会占用 3 个字节
验证
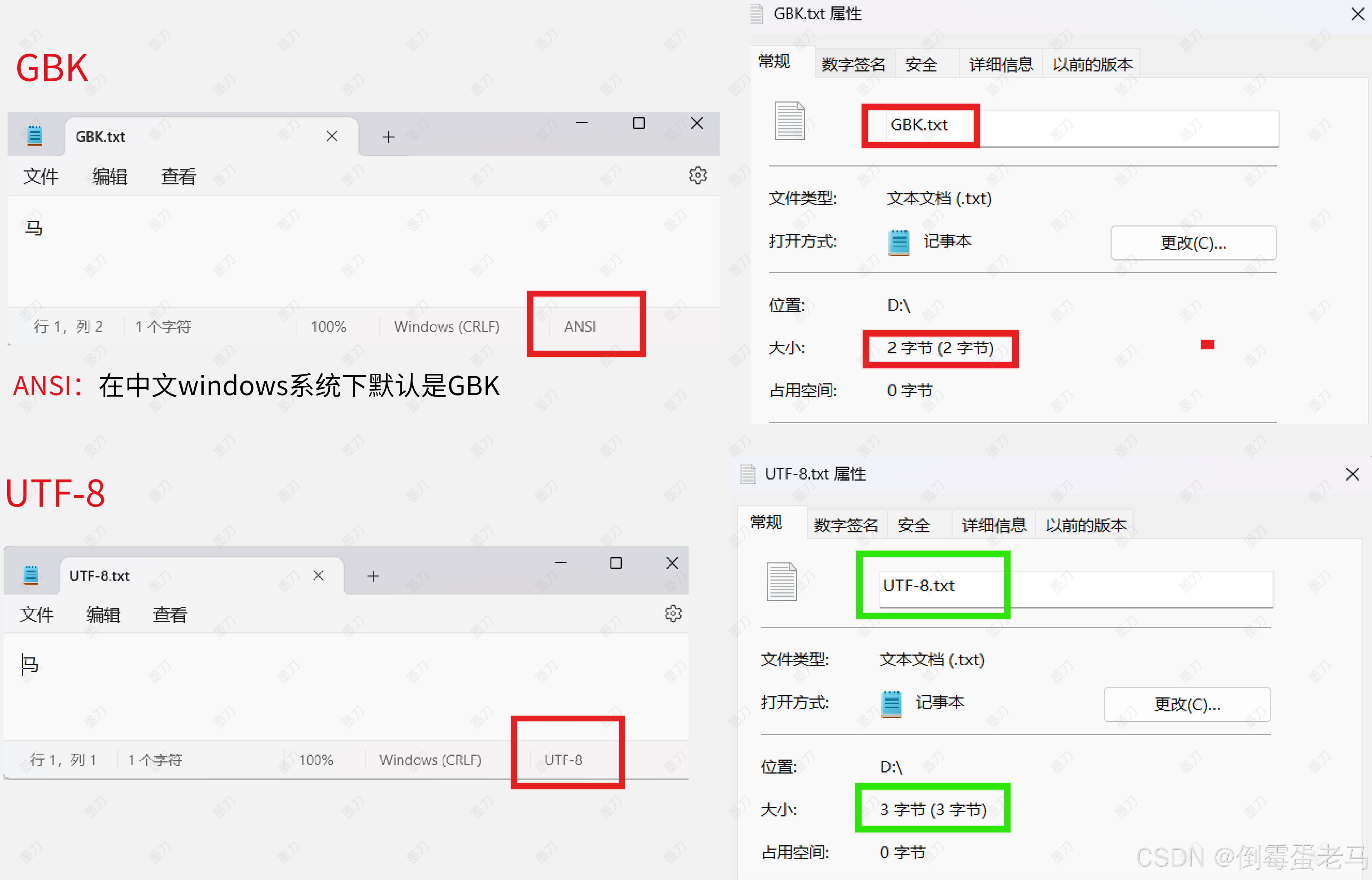
可以看到,在 GBK 编码规范下,'马' 存储到文本文件时所占的字节数确实是 2 ,在 UTF-8 编码下,所占的字节数是 3
1.4 字符集
字符集包括:ASCII、GB2312、GBK、Big5、Unicode 等等
字符集中定义了字符与唯一编号(Code Point)(直译为码点或码位)的映射表
字符集的作用:规定哪些字符可以被表示,并为每个字符分配一个唯一的编号/码点 Code Point ,也就是说字符和编号是一一对应的关系
注意:字符集只是定义了每个字符对应的编号是多少!字符集只是一个映射表!!映射表!!!
这些字符要如何存储到文本文件中、如何进行网络通信还要根据编码规范/字符编码来决定!!!🆗,看我这么激动,就是不想大家弄混了
1.5 编码规范/字符编码
编码规范:可以看作是一种规则,制定了将字符集中的码点转换为计算机可以存储和传输的字节序列的规则,作用是解决字符如何在计算机中存储和传输的问题
这么看还是优点抽象,下面举一个具体的例子
例如:使用的是 Unicode 字符集,Unicode 字符集中定义了每个字符对应的编号
'严':在 Unicode 字符集中的编号是 20005 (十进制),对应的二进制形式是: 01001110 00100101
'N':在 Unicode 字符集中的编号是在 78 (十进制),对应的二进制形式是:01001110
'%':在 Unicode 字符集中的编号是 37(十进制),对应二进制形式是:00100101
🆗,假设我们现在只使用了 Unicode 字符集,没有定义编码规范,直接把字符的编号/码点的二进制形式进行存储和传输,那在下面的场景中就会出现严重的问题,如下:
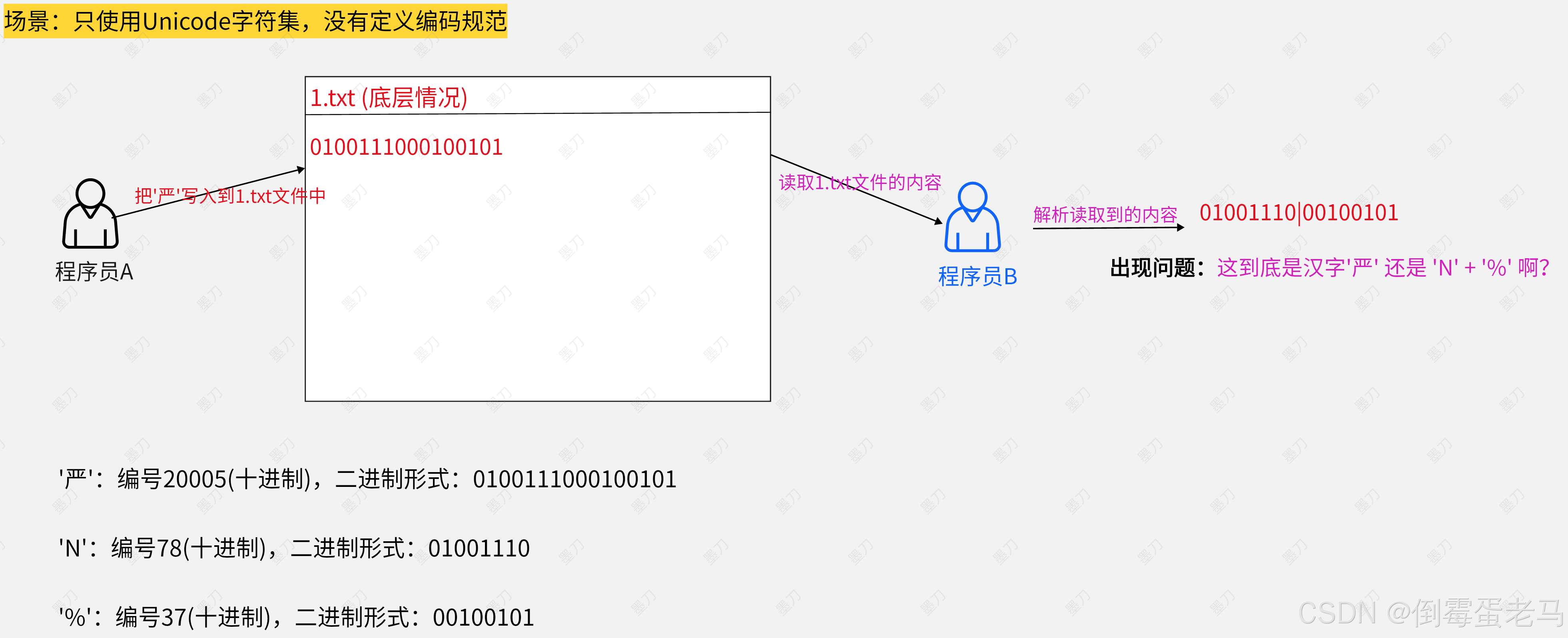
可以看到,程序员 B 这边它是无法解析读取到的内容到底是字 '严' 还是 'N' + '%',图中的程序员 B 如果换成计算机也是一样,这就是不使用编码规范/字符编码的后果
到此,大家应该能够理解编码规范/字符编码的作用了吧?编码规范就是指定了一种规则,在原有的字符码点上作了一点"手脚",使得字符能够被计算机唯一识别,解决了在计算机中存储和传输的问题
Unicode 字符集常用的编码规范有:UTF-8、UTF-16、UTF-32 。具体是怎么实现这里先不说,后文讲到 Unicode 字符集的时候会说
🆗,一些名词解释清楚了,下面就开始本文的重点内容了!!
2.ASCII
2.1 ASCII字符集
在 1963 年,ANSI 美国国家标准学会就推出了 ASCII 字符集,ASCII 字符集中定义了 128 个字符以及对应的编号/码点,包含 95 个 可见字符:大小写英文字母 a~z/A~Z 、数字 0~9、标点符号,33 个不可见字符:即控制字符,回车键、换行键、空格等,如下:
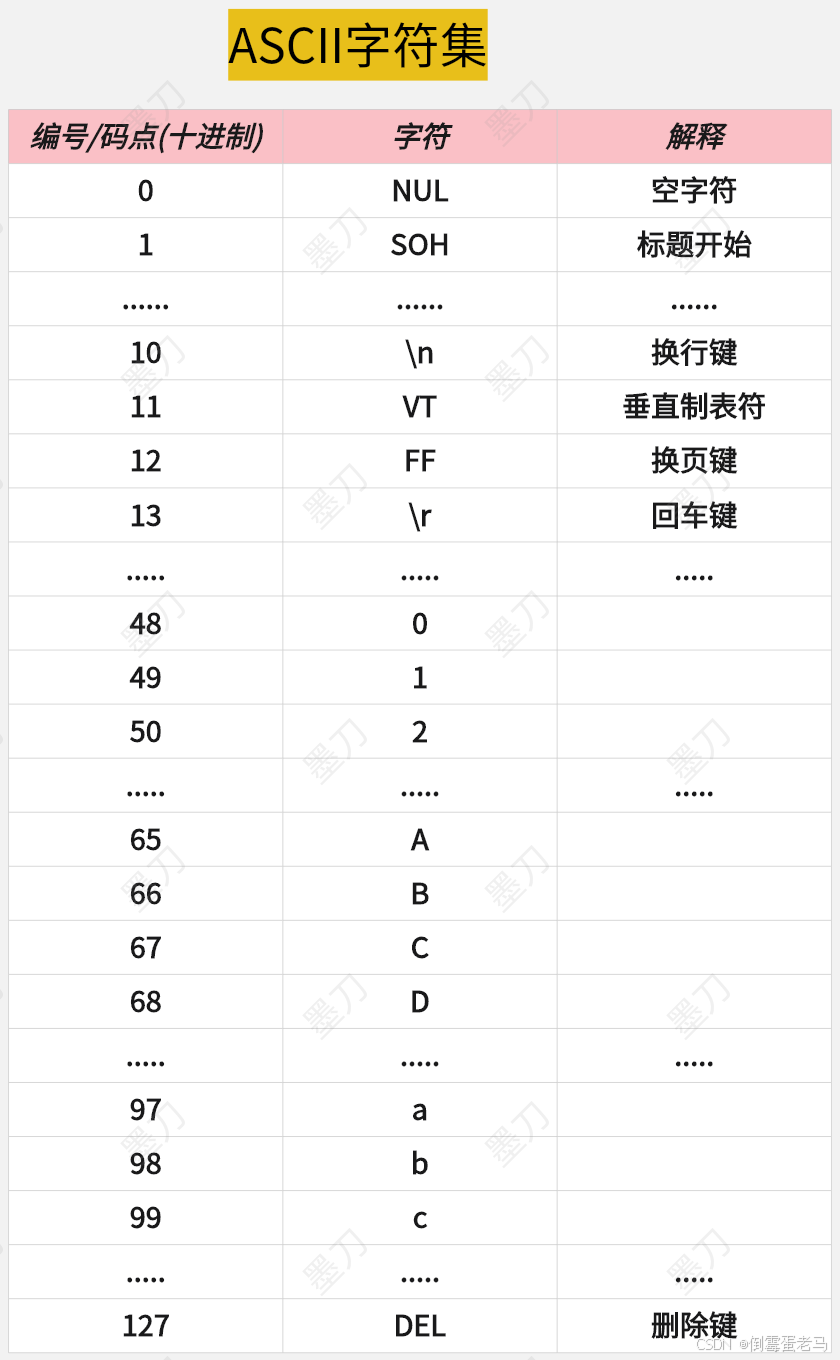
🆗,有了 ASCII 字符集,下一步就该考虑如何将 ASCII 字符集中的字符存储到计算机中,于是有了针对于 ASCII 字符集的编码规范 ASCII编码
2.2 ASCII编码
ASCII 编码的想法比较简单:在计算机存储和传输 ASCII 字符集中的字符时,直接将每个字符的码点转换为二进制即可,如下:
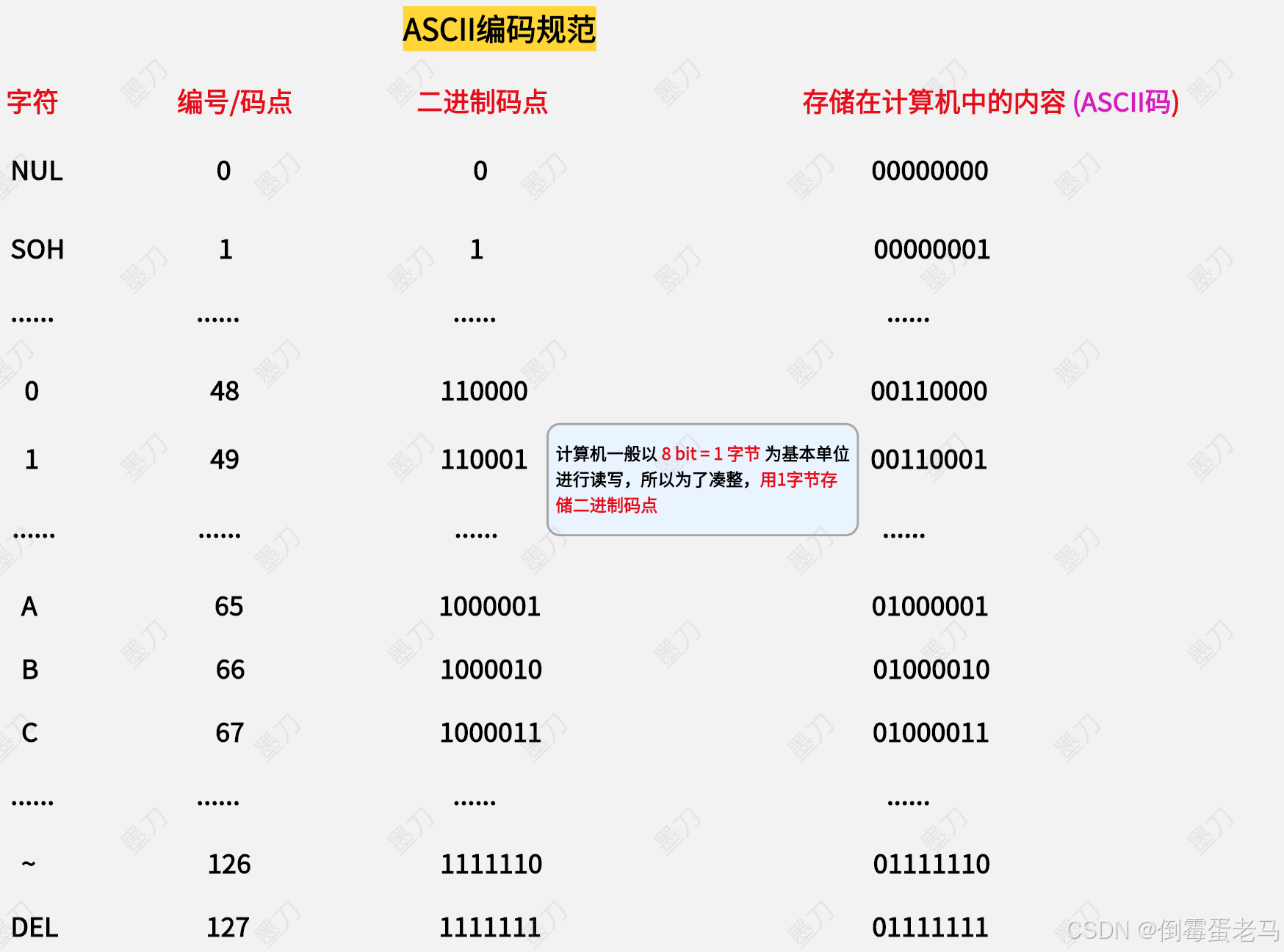
由于最大的编号/码点是 127 ,ASCII 字符集中的二进制码点都 <= 7 bit ,但由于计算机一般以 8 bit = 1字节 为基本单位进行读写,所以为了凑整,ASCII编码规范决定用 1 字节来存储字符的二进制码点
所以,从上图中可以看到,ASCII 字符集中每个字符经过 ASCII 编码之后,存储在计算机中的内容的最高位都为 0
2.3 案例演示
🆗,现在我们有了 ASCII 字符集 + ASCII 编码,举一些案例看看字符是如何在计算机中存储和传输的
案例1:计算机存储字符到文本文件中
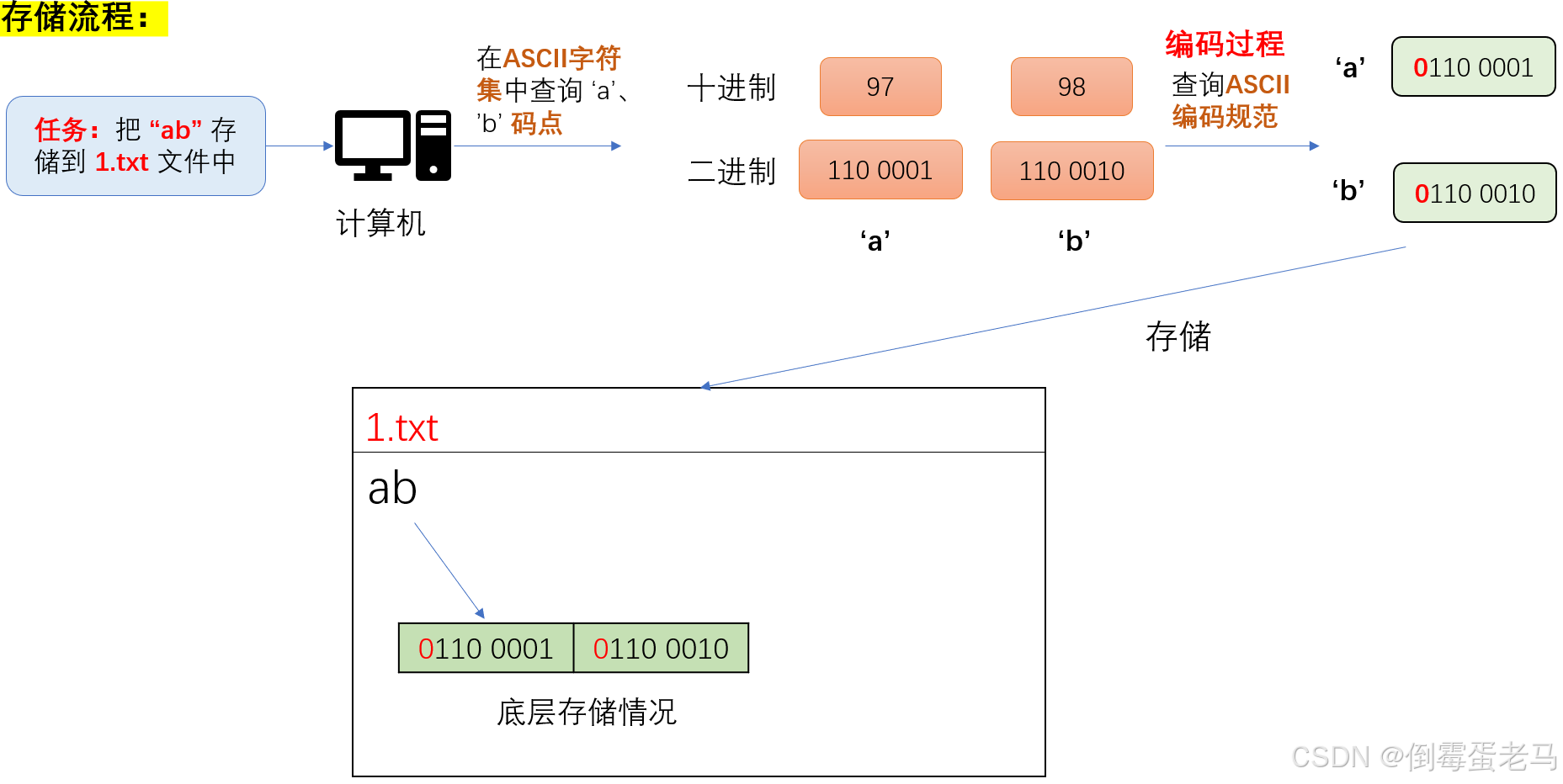
案例2:计算机读取文本文件
现有1.txt 文本文件,采用 ASCII 编码规范编码,其内容是 "ab"。演示计算机读取 1.txt 文件的过程,如下所示:
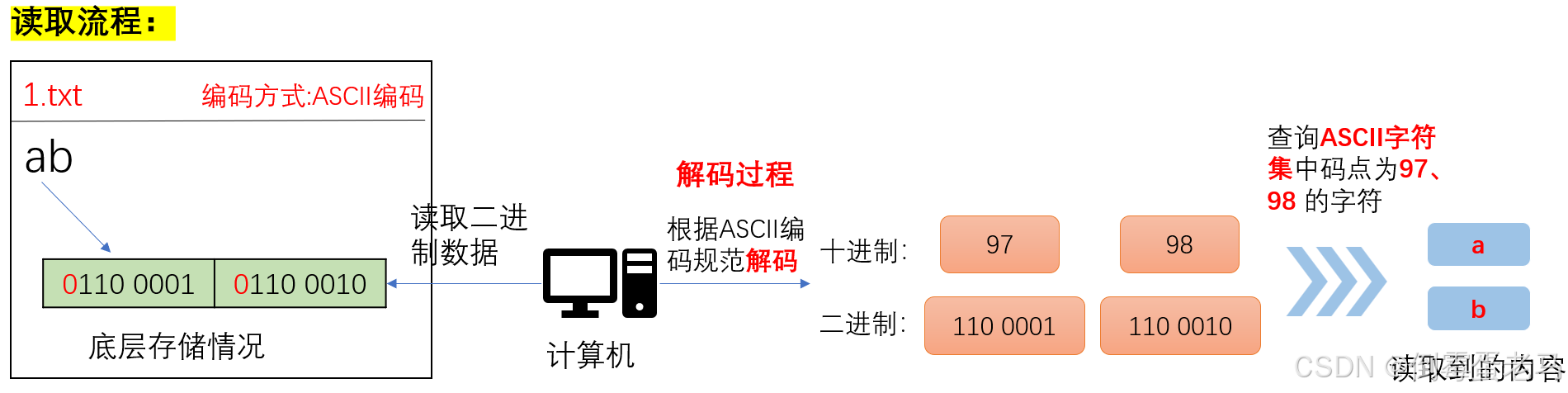
2.4 ASCII存在的问题
前面我们已经说到,ASCII 字符集中共有 128 个字符,包含英文字母、数字、标点符号、控制字符等
但是随着科技和经济的高速发展,越来越多的国家也开始使用计算机。这时候就会出现一个非常关键的问题:如果 ASCII 字符集只在其创造者美丽国使用的话,那肯定是够用的,但对于其他国家怎么办呢?
其他国家的母语不一定就是英语啊,比如中国、日本、韩国、巴基斯坦等等,难道这些国家的计算机使用者们在编写文本文件的时候都要将自己国家的语言手动转换为英文,使得计算机能够正确存储和传输字符吗?
这显然是不现实的,由此不同的国家和地区开始制定自己的字符集和编码规范
当然这也怪不了美丽国,在之后的几十年谁也想不到计算机技术的发展如此迅速,说计算机改变了整个世界的格局都不为过
3.GB2312
在 1980 年由中国国家标准总局发布了第一个中文标准 GB2312 ,共收录了 6763 个汉字,其中一级汉字(常用汉字)3755个,二级汉字(次常用汉字)3008 个
① GB2312 的出现,基本满足了汉字的计算机处理需要,收录的汉字覆大陆 99.75% 的使用频率
② 但对于古汉语、生僻字等罕用字,GB2312 不能处理,这也导致后来 GBK 字符集的出现
3.1 GB2312字符集
① GB2312 字符集默认兼容 ASCII 码(0-127)。举个例子,ASCII 字符集中的 'a' 经过 ASCII 编码之后存储在计算中的内容是 01100001 ,那么 'a' 经过 GB2312 编码之后存储在计算机中的内容同样是 01100001 ,这就是兼容的意思(没办法,毕竟计算机里英文更通用,谁让计算机的发明者是美丽国呢)
注: GB2312 字符集中并没有显式定义 ASCII 字符集的码点,后续是通过 GB2312 编码规范来默认兼容 ASCII 码的
② GB2312 还收录了 682 个全角字符:包括拉丁字母、希腊字母、日本平假名及片假名字母、俄语西里尔字母
拉丁字母:a~z、A~Z。但需要非常注意的是这里指的是收录全角状态的 a~z、A~Z,不是ASCII 字符集中半角状态的 a~z、A~Z
③ GB2312 字符集使用分区管理,分成 94 个区,每个区含 94 个码点,共 94 x 94 = 8836 个码点,当然并不是所有码点都分配了字符噢
-
01-09区:收录除汉字外的 682 个全角字符
-
10-15区:空白区,没有使用
-
16-55区:收录 3755 个一级汉字
-
56-87区:收录 3008 个二级汉字
-
88-94区:空白区,没有使用
④ GB2312 字符集中字符的码点是:区号 + 行号 + 列号,也可以说是 区号 + 位号 。后面会举例
01-09区:除汉字外的 682 个全角字符

注:
(1)每个区的 (0,0) 处是没有定义字符的,每个区有定义字符的区域在 (0,1) ~ (9,4),所以每个区刚好包含 94 个码点
(2)区号 > = 1,行号 + 列号 = 位号 > = 1
16-55区:收录 3755 个一级汉字,即常用汉字

可以看到,'饼' 在第 17 区的第 9 行第 3 列,所以其对应的码点 = 区号 + 行号 + 列号 = 1793,或者说 区号 + 位号 = 1793
16-55区:收录 3088 个二级汉字,即次常用汉字

'侃' 在第 57 区的第 0 行第 9 列,所以其对应的码点 = 区号 + 位号 = 5709
🆗,有了 GB2312 字符集,下一步就该考虑如何将 GB2312 字符集中的字符存储到计算机中,于是有了针对于 GB2312 字符集的编码规范:GB2312编码
3.2 GB2312编码
在前文已经提到,GB2312 编码要考虑兼容 ASCII 码(0-127)的问题
在 GB2312 编码中,对于 ASCII 字符集中的字符,经过 GB2312 编码之后得到内容仍然采用 1 字节存储即可,这里不再赘述;GB2312 字符集中的字符,经过 GB2312 编码之后得到的内容固定采用 2 字节存储
案例1:GB2312编码演示---计算机存储 '侃' 的过程
在前面已经知道, '侃' 的码点是:区号 + 位号 = 5709,'侃' 的 GB2312 编码过程如下:
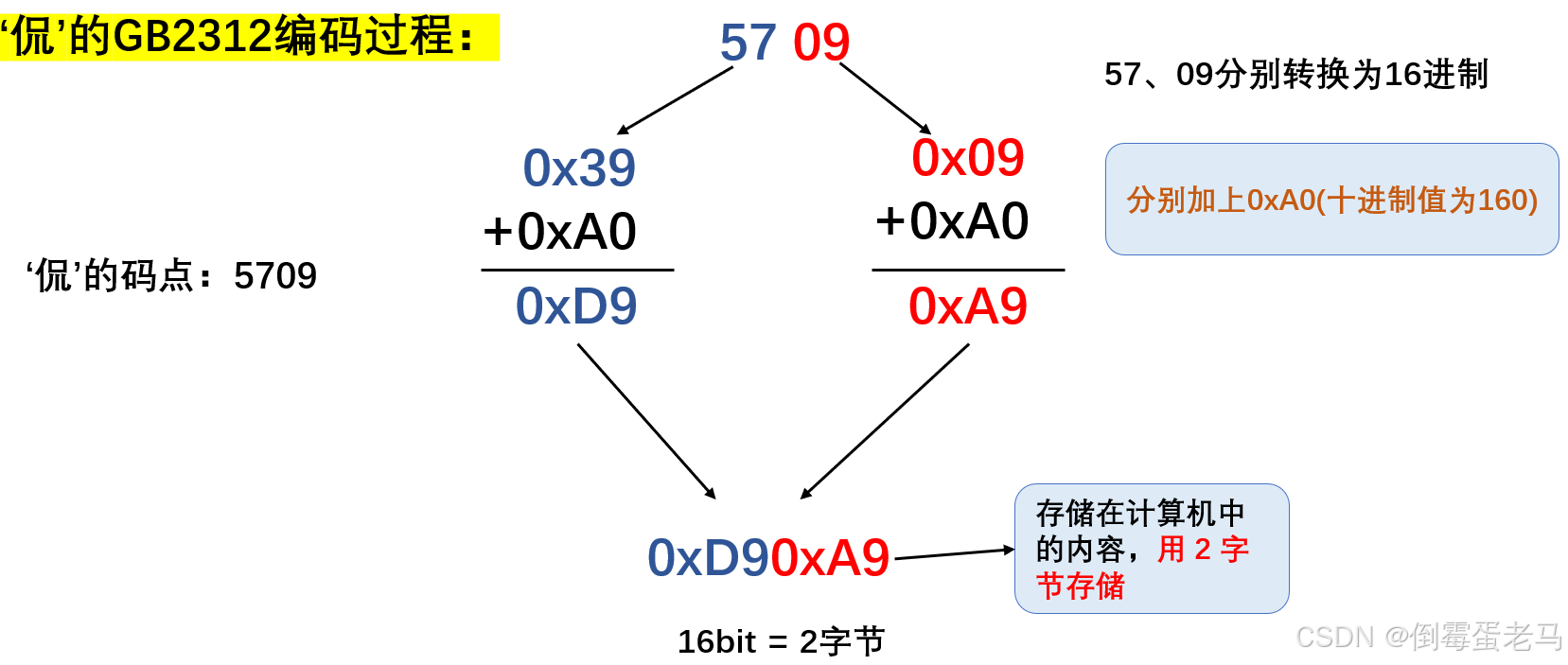
可以看到,GB2312 编码其实就是先将码点分为 区号 + 位号,分别加上 0xA0(十进制为160)后再进行合并,作为存储在计算机中的内容,用 2 字节进行存储,第一个字节存储处理后的区号,第二个字节存储处理后的位号
思考:想想为什么这里每个字节的存储内容都要加上 0xA0(十进制为160) 呢?因为 ASCII 字符集中的码点范围是 0 ~ 127,为 区号 和 位号 分别加上 0xA0 后,每个字节的内容都 > = 161,最高位都是 1 ,这样就可以规避 ASCII 字符集中的字符,避免冲突
使用 Python 验证:'侃' 用 GB2312 编码之后的内容是 0xD9 0xA9
#输出'侃'用GB2312编码之后的内容
print('侃'.encode('GB2312'))输出结果:
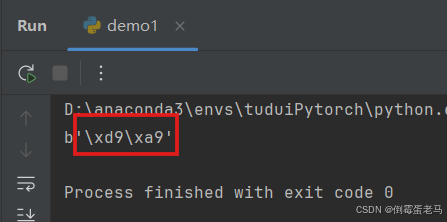
可以看到,'侃' 经过 GB2312 编码之后,存储在计算机中的内容确实是 0xD9 0xA9
🆗,GB2312 编码过程清楚了,下面举一个 GB2312 的解码例子
案例2:GB2312解码演示---计算机读取文本文件
现有1.txt 文本文件,采用 GB2312 编码方式,其内容是 "a侃"。演示计算机读取 1.txt 文件的过程,如下所示:
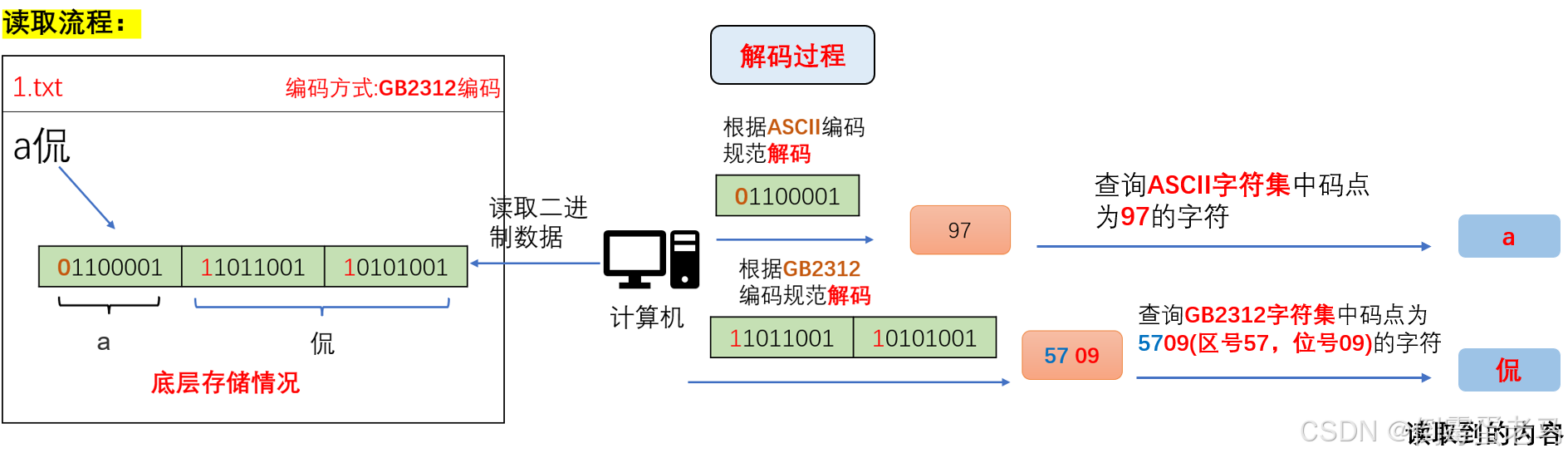
可以看到,对于 ASCII 字符集中的字符,字节的首位一定为 0 ,对该字节按 ASCII 编码规范解码;如果是 GB2312 字符集中的字符,字节的首位一定是 1 ,由于 GB2312 字符集中的字符编码之后的内容固定用 2 字节存储,所以对该字节与其后面紧跟着的 1 字节一起按照 GB2312 编码规范解码
因此,GB2312 编码规范能够使得计算机区分 ASCII 码和 GB2312 码,正确解析读取到的内容
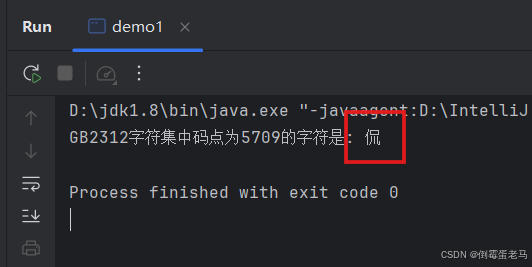
案例3:使用Java演示字符 '侃' 的GB2312编码、解码流程
public class demo1 {
public static void main(String[] args) throws Exception {
//'侃'的码点是 区号 + 位号 = 5709
int areaCode = 57; // 区号
int positionCode = 9; // 位号
/**编码**/
//将区号和位号转换为GB2312编码的字节
byte areaCodeByte = (byte) (areaCode + 0xA0);//区号+0xA0
byte positionCodeByte = (byte) (positionCode + 0xA0);//位号+0xA0
//存放区号、位号经过GB2312编号之后的两个字节
byte[] gb2312Bytes = {areaCodeByte, positionCodeByte};
/**解码*/
//将GB2312字节数组解码为字符串,第二个参数是解码方式
String result = new String(gb2312Bytes, "GB2312");
System.out.println("GB2312字符集中码点为5709的字符是: " + result);
}
}运行结果:
3.3 GB2312存在的问题
前面我们说到,GB2312 字符集中收录了 6763 个汉字,但是中华文化,博大精深啊![]() 。其实还有很多汉字是没有被收录在 GB231 字符集中的,于是就有了后来的针对 GB2312 的扩充字符集 GBK
。其实还有很多汉字是没有被收录在 GB231 字符集中的,于是就有了后来的针对 GB2312 的扩充字符集 GBK
4.GBK
GBK 字符集 共收录 21886 个汉字、一些其他字符,如下:
-
GB2312 中的全部内容
-
Big5中的全部汉字(注意:GBK 编码与台湾 Big5 编码不兼容,同一个繁体字很可能在 GBK 编码和 Big5 编码是不一样的)
-
与 ISO 10646 相应的国家标准 GB 13000 中的其他 CJK(中日韩) 汉字
-
其他汉字、部首、符号,共计 984 个
4.1 GBK字符集
① GBK 字符集其实就是在 GB2312 的基础上进行扩充,兼容 GB2312、ASCII
例如 ASCII 字符 'a' 经过 ASCII 编码之后存储在计算机中的内容是 01100001,那么 'a' 经过 GBK 编码之后存储在计算中的内容同样是 01100001 ;GB2312 字符 '侃' 经过 GB2312 编码之后存储在计算机的内容是 11011001 10101001,经过 GBK 编码之后同样如此
② GBK 字符集里扩增的字符的码点是如何定义的up在网上并没有找到很确切的资料,所以这里就不讲了,我们直接看 GBK 编码就行,这也不影响
4.2 GBK编码
GBK 字符集里扩充的字符在编码之后存储在计算机中的内容固定采用 2 字节来存储,这与 GB2312 编码是一致的
在前文提到,GB2312 字符集中的字符在编码之后,第 1 个字节和第 2 个字节的首位都为 1 ,这样可以规避 ASCII 字符集中的字符,避免冲突
而 GBK 字符集扩充的字符在经过 GBK 编码之后,第 1 个字节的首位必须为 1 ,第 2 个字节的首位可以为 0 或 1 。![]() 看到这里大伙是不是很疑惑,你 TM 的不是说 GBK 要兼容 ASCII 吗,如果第 2 个字节的首位为 0 的话不就可能与 ASCII 字符发生冲突吗?那怎么让计算机正确解析读取到的内容呢?
看到这里大伙是不是很疑惑,你 TM 的不是说 GBK 要兼容 ASCII 吗,如果第 2 个字节的首位为 0 的话不就可能与 ASCII 字符发生冲突吗?那怎么让计算机正确解析读取到的内容呢?
其实很简单,因为 ASCII 字符在经过 ASCII 编码之后是用 1 字节来存储的,该字节的首位一定为 0 。非 ASCII 字符的 GBK 字符、GB2312 字符都是用 2 字节存储的,并且第 1 个字节的首位都是 1 ,因此计算机在解析二进制数据的时候,如果发现第一个字节的首位为 1 ,那就肯定是非 ASCII 字符,把该字节和紧接在后面的 1 字节读进来一起解析;如果发现第一个字节的首位为 0 ,那就一定是 ASCII 字符,只解析该字节即可
劈里啪啦说了这么多,还是举例子来帮助大家理解哈
案例1:GBK编码演示---计算机存储 '侃a繼' 到文本文件中的过程
'侃':GB2312 字符集中的字符,编码之后存储的内容是:11011001 10101001
'a':ASCII 字符集中的字符,编码之后存储的内容是:01100001
'繼':GBK 字符集中的字符,编码之后存储的内容是:10111110 01000000
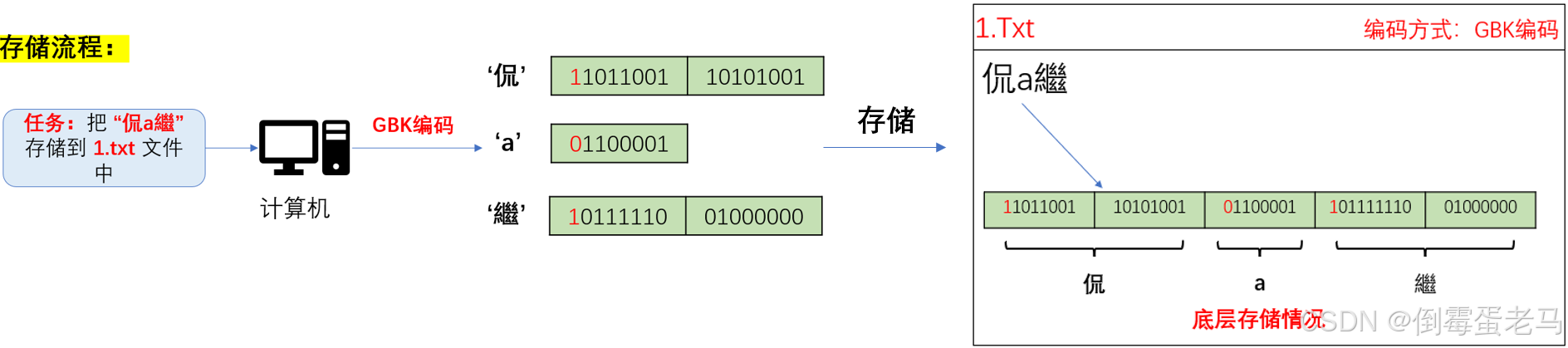
可以看到,ASCII 字符 'a' 编码之后用 1 字节存储,首位必为 0 ;非 ASCII 字符编码之后用 2 字节存储,第 1 个字节首位必为 1 ,第二个字节的首页为 0或1
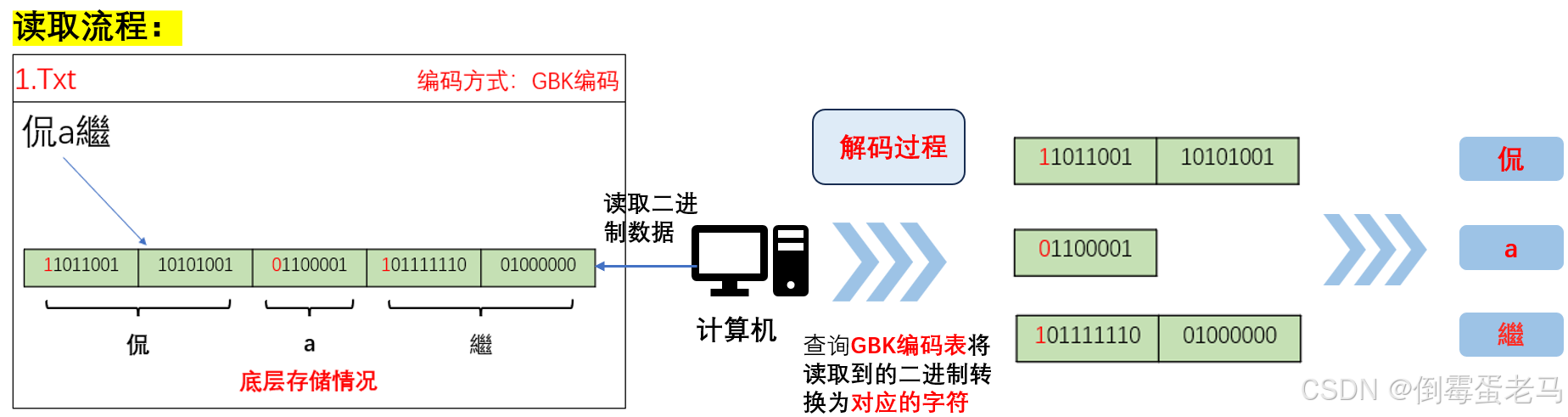
案例2:GBK解码演示---计算机读取文本文件的过程
现有1.txt 文本文件,采用 GBK 编码,其内容是 "侃a繼"。演示计算机读取 1.txt 文件的过程,如下所示:
5.不同国家制定自己的编码标准带来的问题
既然中国能制定自己的编码标准,那其他国家肯定也行啊。如果世界上每个国家纷纷制定属于自己的编码标准,那就会诞生巴基斯坦码、印度码、巴勒斯坦码等各种乱起八糟的编码标准
如果世界上有很多套编码标准,即编码标准不统一时,不同国家在进行信息交流的时候就会乱码现象频发。因为计算机读取到的二进制数据,在不同的字符集和编码方式下对应的可能是完全不同的字符,如下:
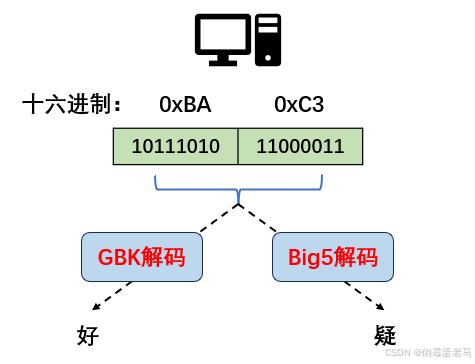
对于二进制数据 10111010 11000011,使用 GBK 解码得到 '好',使用 Big5 编码得到的是 '疑'
我们使用 python 验证一下,查看 '好' 经过 GBK 编码之后得到的内容, '疑' 经过 Big5 编码之后得到的内容,如下:
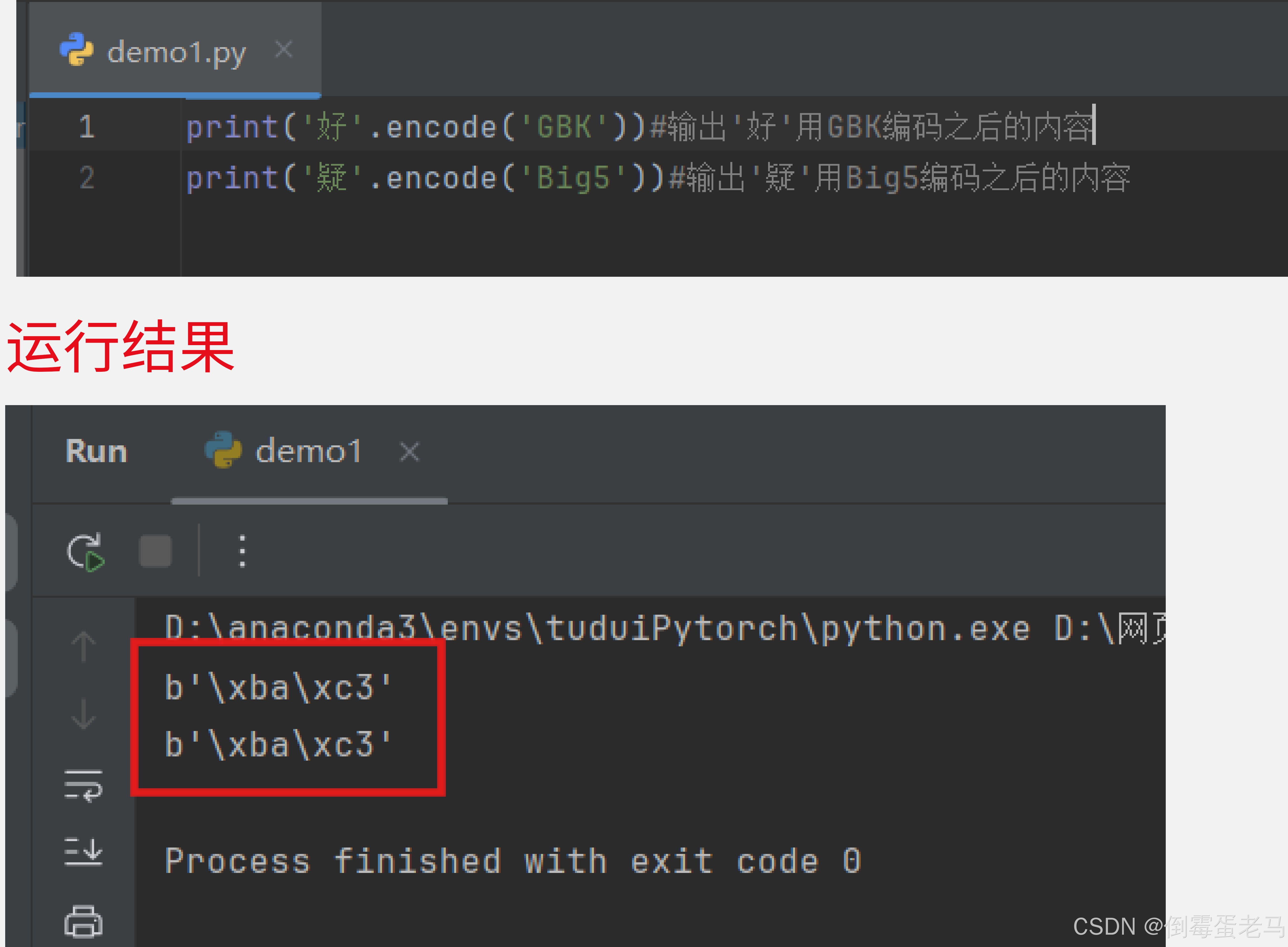
可以看到, '好' 经过 GBK 编码和 '疑' 经过 Big5 编码之后得到的内容的十六进制形式均为:0xBA 0xC3
再举一个案例
例如,如果你使用 GBK 编码的文本编辑器编写好一个文件,然后发送给香港的朋友。香港的朋友用 Big5 编码的文本编辑器打开该文件时,就会发生乱码现象,如下:
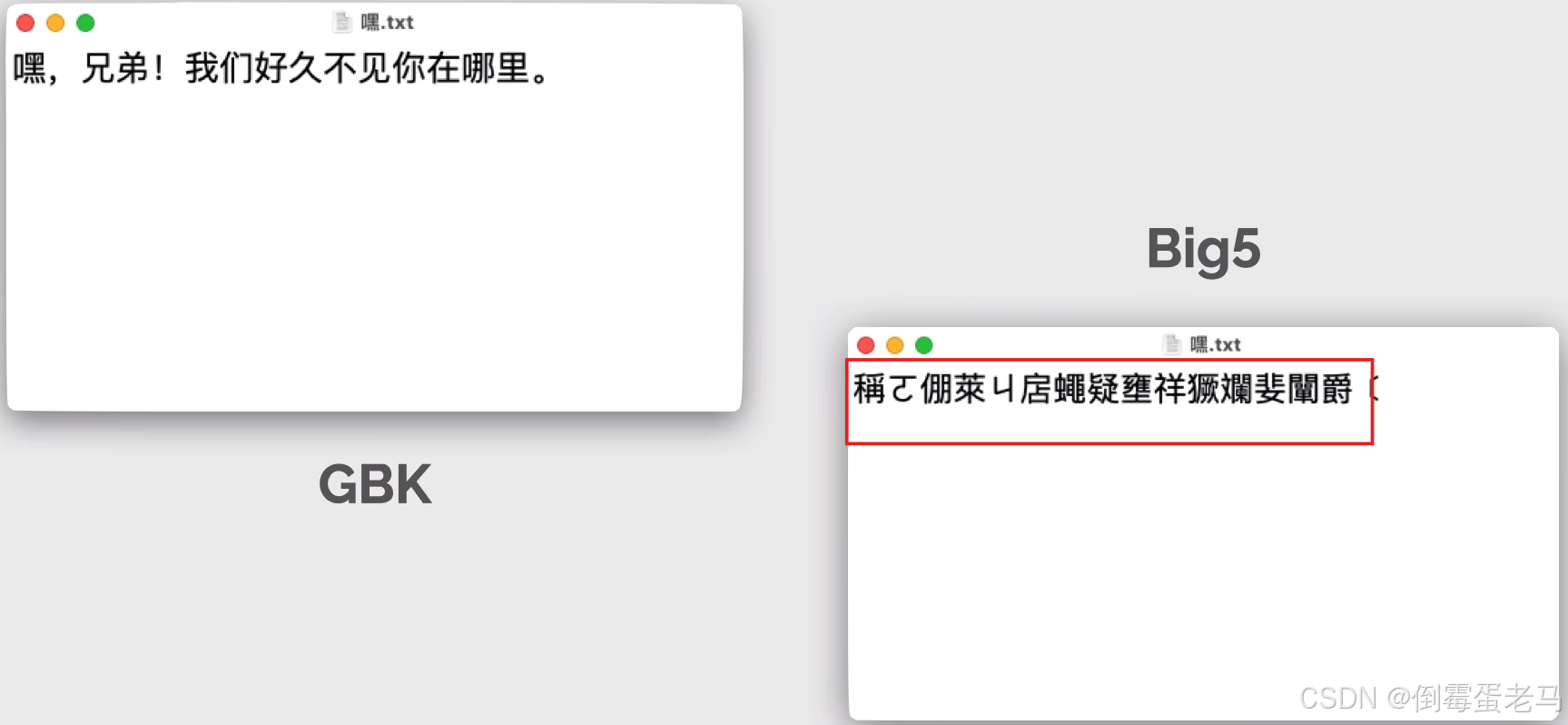
Big5 是港澳台地区流行使用的编码,Big5 字符集中收录的是繁体字。虽然 GBK 字符集中也有收录繁体字,但并不与 Big5 完全兼容噢。即同一个繁体字体,经过 GBK 编码之后和经过 Big5 编码之后得到的内容可能是不相同的
于是,世界急需一种更通用的字符编码标准,支持不同的语言文字,使用该字符编码标准后,用户就不再需要担心乱码问题。所以由美丽国在 1994 发布了 Unicode 字符集,后续推出了针对于 Unicode 字符集的 UTF-32、UTF-16、UTF-8 字符编码规范
6.Unicode(万国码)
Unicode官网:Unicode – 文本和表情符号的世界标准
① Unicode 字符集给全世界所有文字和符号一个独一无二的编号/码点,甚至在2010年,一些表情符号 emoji 比如😈👴都被 Unicode 字符集收录了
② Unicode 字符集码点的 取值范围是 0x0000 ~ 0x10FFFF(十六进制),共 1,114,112 个可用码点。但目前在用的码点大约是 14 万个,换言之,Unicode 字符集收录了大约 14 万个字符
③ Unicode 字符集将码点空间划分为 17 个平面(Planes),每个平面可定义 65,536(2^16)个码点,如下所示:

通常我们只需要关注平面1:基本多语言平面(BMP) 即可,日常生活中用的绝大多数字符的码点就在该范围内,平面2~17的辅助平面了解下就行
④ 与其他字符集一样,Unicode 字符集只是给字符分配了唯一编号/码点!!!只是给字符分配了唯一码点!!!并没有规定这个码点要如何存储到计算机中,如何存储到计算机中还要编码方案
7.Unicode字符集的编码方案
UTF-8、UTF-16、UTF-32 是 Unicode 字符集的三种主要编码方案,制定了一套规则:如何将 Unicode 字符的码点存储到计算机中。目前用的最多的编码方案是 UTF-8,UTF-16 次之,UTF-32几乎很少使用
7.1 UTF-32
UTF- 32 是定长编码,其基本码元是 32 位 (4字节),这也是 UTF-32 的 "32" 的含义。对于一个Unicode 字符,通过 UTF-32 编码之后,存储在计算机中的内容均用 4 字节存储
7.1.1 编码规则
UTF-32 编码属于定长编码,它的思想非常简单:对于所有的 Unicode 字符,编码时将其码点转化为二进制形式,然后用 4 字节存储在计算机中
7.1.2 案例演示
UTF-32编码演示:计算机存储 'a' 到文本文件中的过程
'a':Unicode 字符集中码点的十进制形式为 97,其二进制形式为 1100001
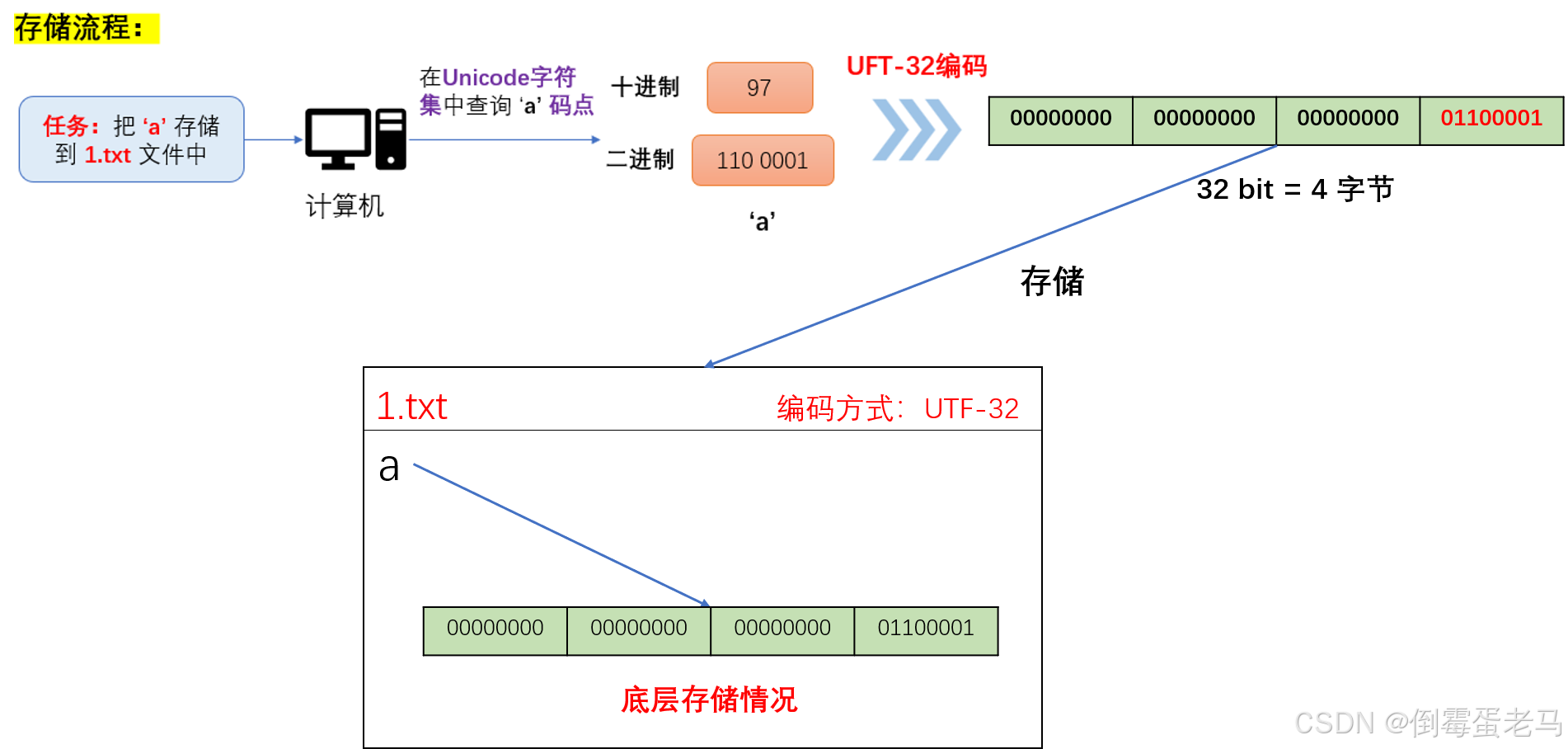
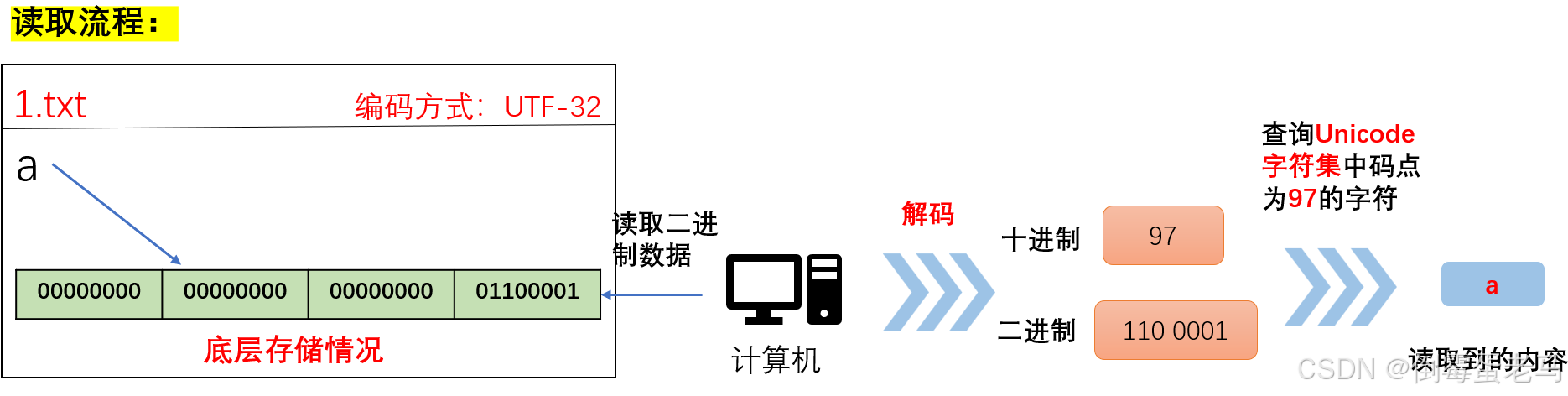
UTF-32解码演示:计算机读取文本文件的过程
解码的流程其实就是编码流程逆过来,挺简单的,不过这里还是演示一下吧
现有1.txt 文本文件,采用 UTF-32 编码,其内容是 'a'。演示计算机读取 1.txt 文件的过程,如下所示:
7.1.3 UTF-32的优缺点
优点:编码、解码过程简单高效
缺点:
① 由于 UTF-32 是定长编码,每个字符编码之后存储在计算机中的内容都需要用 4 字节来存储,占用大量的存储空间
② 造成存储空间浪费:
(1)相同内容的英文文本,使用 UTF-32 编码所占空间是 ASCII 编码的 4 倍,如下所示:
复习亿下:ASCII 编码每个英文字符只需要用 1 字节存储
(2)相同内容的中文文本,使用 UTF-32 编码所占空间是 GBK 编码的 2 倍,如下所示:
复习亿下:GBK 编码每个中文字符只需要用 2 字节存储
由于 UTF-32 编码占用大量的存储空间,所以 UTF-32 几乎很少使用。而且在如今的windows 系统上,编码方式都找不到 UTF-32 了,如下:
7.2 UTF-16
UTF-16 是变长编码,其基本码元是 16 位 (2字节),这也是 UTF-16 中的 "16" 的含义。对于一个 Unicode 字符,通过 UTF-16 编码之后,存储在计算机中的内容用 2 字节 或 4 字节来存储
7.2.1 编码规则
① 基本多语言平面(BMP):
-
码点范围:16进制形式表示:0x0000 ~ 0xFFFF,十进制形式表示:0 ~ 65535
-
编码方式:直接将字符的码点转换为二进制然后用 2 字节存储
-
例如:字符 'A',码点:97,经过 UTF-16 编码之后,存储在计算机种的内容为:00000000 01000001(二进制形式),0x00 0x41(十六进制形式)
-
注意:
(1)虽然基本多语言平面(BMP)的码点范围是 0x0000 ~ 0xFFFF ,但该范围内仍然有未被分配字符的空白码点区域噢,真正已经分配字符的码点范围是:0x0000 ~ 0xD7FF 和 0xE000 ~ 0xFFFF
(2)BMP 的空白码点区域不止一个,但这里我们只需要记住一个比较重要的区域:0xD800 ~ 0xDFFF,这个区域被专门用作代理对编码,使得计算机在使用 UTF-16 解码的时候能够正确区分 2 字节字符和 4 字节字符
② 辅助平面1~16:存放表情符号 emoji 😈✌👴、古文字、罕见文字、生僻字等
-
码点范围:16进制形式表示:0x10000 ~ 0x10FFFF,十进制形式表示:65536 ~ 1114111
-
编码长度:辅助平面 1~16 的字符经过 UTF-16 编码之后的内容用 4 字节存储
说明:称 UTF-16 编码之后的前 2 个字节为高位代理 High Surrogate,后 2 个字节为低位代理 Low Surrogate
-
编码方式:以表情符号emoji
😊为例,其码点的十六进制形式为:0x1F60A-
计算代理对:
-
码点偏移:0x1F60A - 0x10000 = 0x0F60A
-
高位代理:0xD800 + (0x0F60A >> 10) = 0xD83D
-
低位代理:0xDC00 + (0x0F60A & 0x3FF) = 0xDE0A
-
-
编码结果(16进制表示):D8 3D DE 0A
-
所以表情符号😊经过 UTF-16 编码之后,存储在计算机中的内容是:D8 3D DE 0A,用 4 字节存储,D8 3D 称为高位代理,DE 0A 称为低位代理
-
解码方式:通过前面的编码方式可以使得高位代理、低位代理的范围如下:
高位代理(2字节):0xD800 ~ 0xDBFF
低位代理(2字节):0xDC00 ~ 0xDFFF
可以发现,高位代理和低位代理的范围正好是基本多语言平面(BMP)的空白码点区域,这可以使得计算机能够正确分辨是 2 字节字符还是 4 字节字符,解码流程大概如下:
-
每次读取两个字节
-
若 2 个字节存储的内容的范围是:0x0000 ~ 0xD7FF 或 0xE000 ~ 0xFFFF,就代表是一个 BMP 字符,属于 2 字节字符,直接将其转换为 Unicode 码点查找对应的字符即可
-
若 2 个字节的存储内容的范围是:0xD800 ~ 0xDBFF,就代表是一个 4 字节字符的高位代理,紧跟在之后的 2 字节一定是 4 字节字符的低位代理,低位代理存储的内容范围是: 0xDC00 ~ 0xDFFF。读取到高位代理和低位代理之后,解码公式是:码点 = (高位代理 − 0xD800) × 0x400 + (低位代理 − 0xDC00) + 0x10000。计算出码点之后,在 Unicode 字符集中查找对应字符即可
-
7.2.2 案例演示
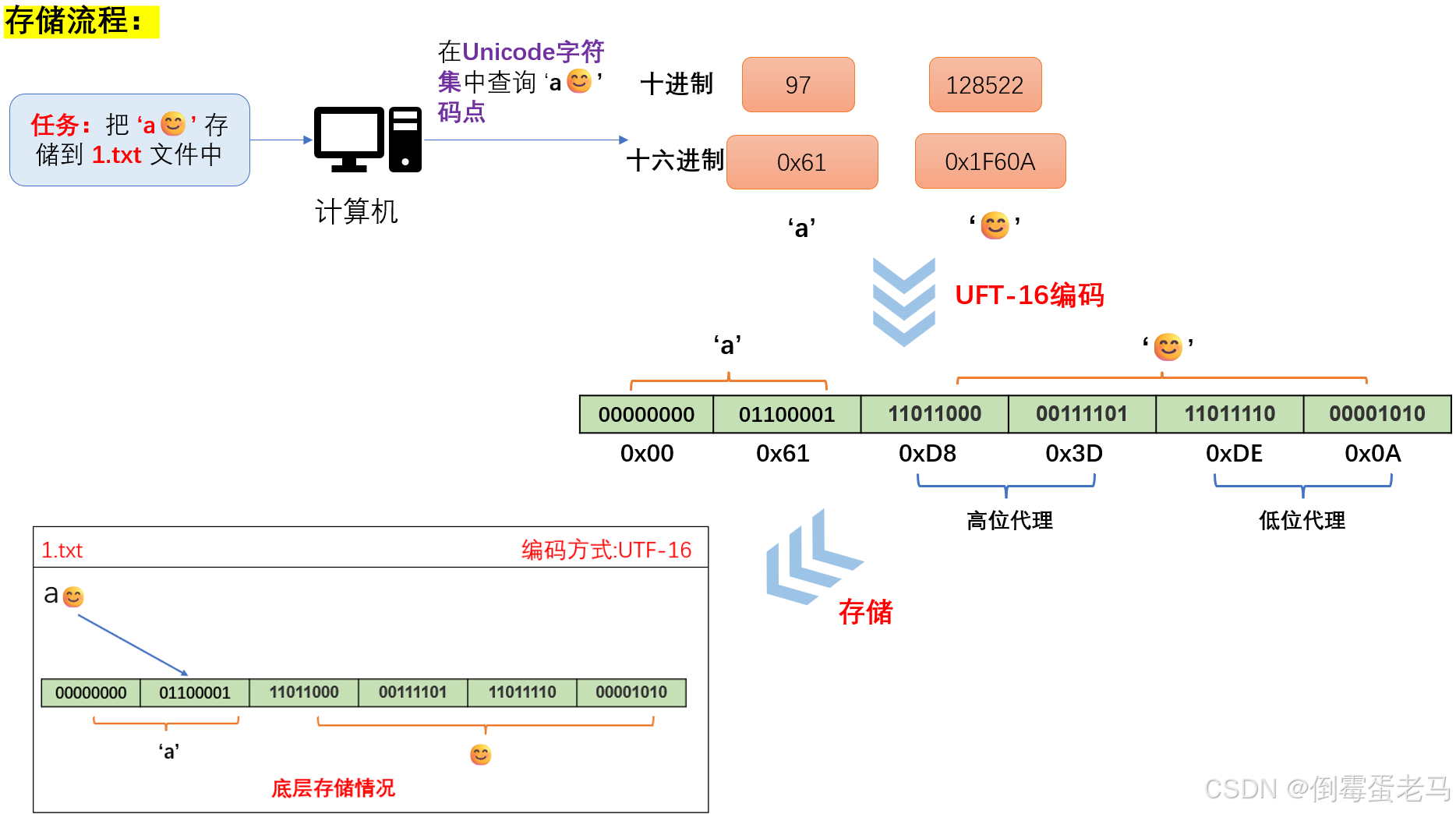
UTF-16编码演示:计算机存储 'a
😊' 到文本文件中的过程(为演示方便,我们这里都采用十六进制表示吧)
'a':BMP 字符,编码后用 2 字节存储。Unicode 码点 ---> 十进制:97,十六进制:0x61,经过 UTF-16 编码之后存储在计算机的内容是 ---> 十六进制:0x0061,二进制:00000000 01100001
'😊' :辅助平面字符,编码后用4 字节存储。Unciode 码点 ---> 十进制:128522,十六进制:0x1F60A,经过 UTF-16 编码之后存储在计算机的内容是 ----> 十六进制:0xD83DDE0A,二进制:11011000 00111101 1101110 00001010
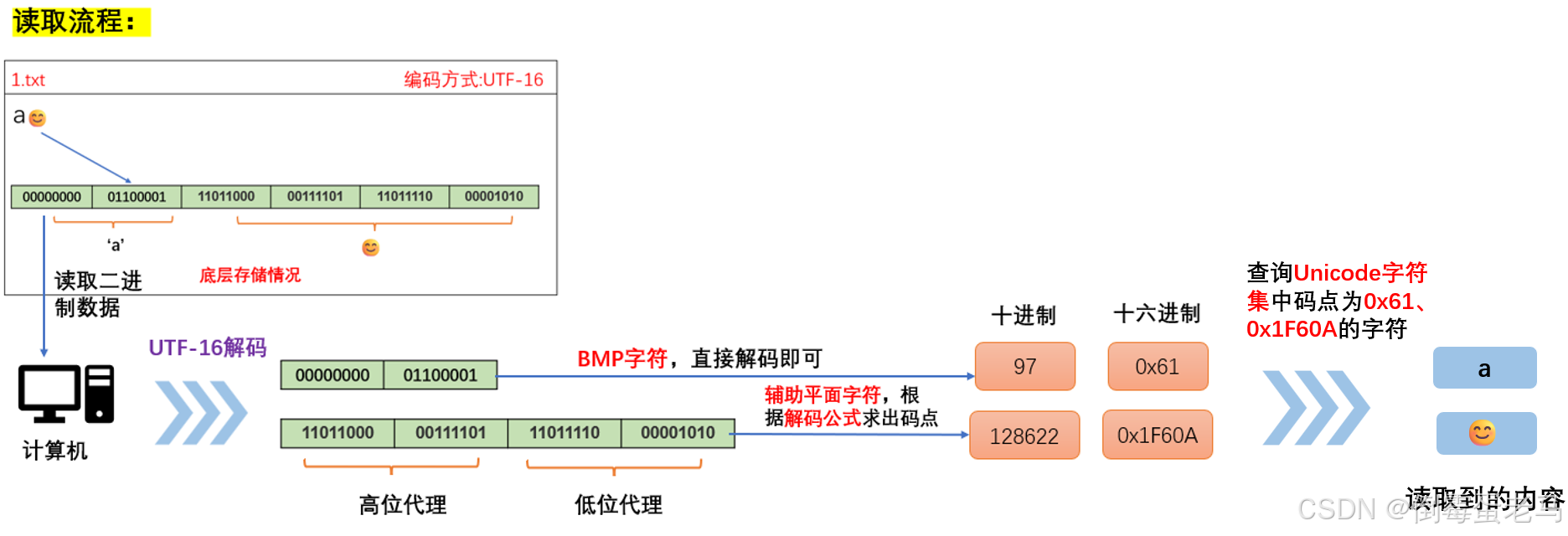
UTF-16解码演示:计算机读取文本文件的过程
解码的流程前文很详细解释过了,其实也不难的
现有1.txt 文本文件,采用 UTF-16 编码,其内容是 'a😊'。演示计算机读取 1.txt 文件的过程,如下所示:
7.2.3 UTF-16 BE、UTF-16 LE
UTF-16 编码根据字节序可以细分为 UTF-16 BE、UTF-16 LE 。如下:
在前文我们举的 UTF-16 例子都是大端字节序。不用慌,字节序是很简单的东西,听我娓娓道来
字节序描述的是多字节数据存储到计算机中时字节的排列顺序。在计算机系统里,主要存在两种字节序: 大端存储、小端存储方式,相信学习过《操作系统》、《计算机组成原理》的同学都知道
-
大端字节序(Big -Endian,BE):高位字节存于低地址,低位字节存于高地址。例如:2 字节整数 0x1234 ,在计算机中按大端字节序是这样存储的:0x12 0x34; 4 字节整数 0x12345678 ,在计算机中按大端字节序是这样存储的:0x12 0x34 0x56 0x78
-
小端字节序(Little-Endian,LE):低位字节存于低地址,高位字节存于低地址。例如:2 字节整数 0x1234,在计算机中按小端字节序是这样存储的:0x34 0x12; 4 字节整数 0x12345678,在计算机中按小端字节序是这样存储的:0x34 0x12 0x78 0x56
PS:
(1)大端字节序更接近人类的逻辑
(2)UTF-32 其实也可以分为 UTF-32 BE、UTF-32 LE,但由于 UTF-32 编码在现今的windows 下都没有了,所以我们在前文没讲
7.2.4 BOM(字节序标记)
前文提到,UTF-16 可以分为 UTF-16 BE、UTF-16 LE
但现在有个问题:发送方以 UTF-16 BE 编码方式编写好文件,发给接收方时,接收方如何知道发送方采用的是大端字节序还是小端字节呢?如果接收方不清楚发送方采用的字节序,就无法正确解码字符
因此就有了 BOM:Byte order Mark,翻译成中文是:字节序标记。主要用于文本编码中,标识数据存储的字节顺序。业界统一的做法是:在文件的开头加入一个 Unicode 的特殊字符 "零宽无中断空格" 来表示,该字符经过 UTF-16 编码之后是 0xFEFF:
-
在 UTF-16 BE 文件中,BOM 是 0xFE 0xFF
-
在 UTF-16 LE 文件中,BOM 是 0xFF 0xFE
-
在 UTF-32 BE 文件中,BOM 是 0x00 0x00 0xFE 0xFF
-
在 UTF-32 BE 文件中,BOM 是 0x00 0x00 0xFF 0xFE
验证案例1:UTF-16 BE(大端字节序)
用 UTF-16 LE 编码方式编写 1.txt 文件,文件内容是"a😊" ,在前面已经知道经过 UTF-16 编码之后 'a':0x0061 ,'😊':0xD83DDE0A
🆗,编写好文件后,使用 Editplus 查看 1.txt 的十六进制形式,验证 BOM 是否为 0xFE 0xFF,如下:
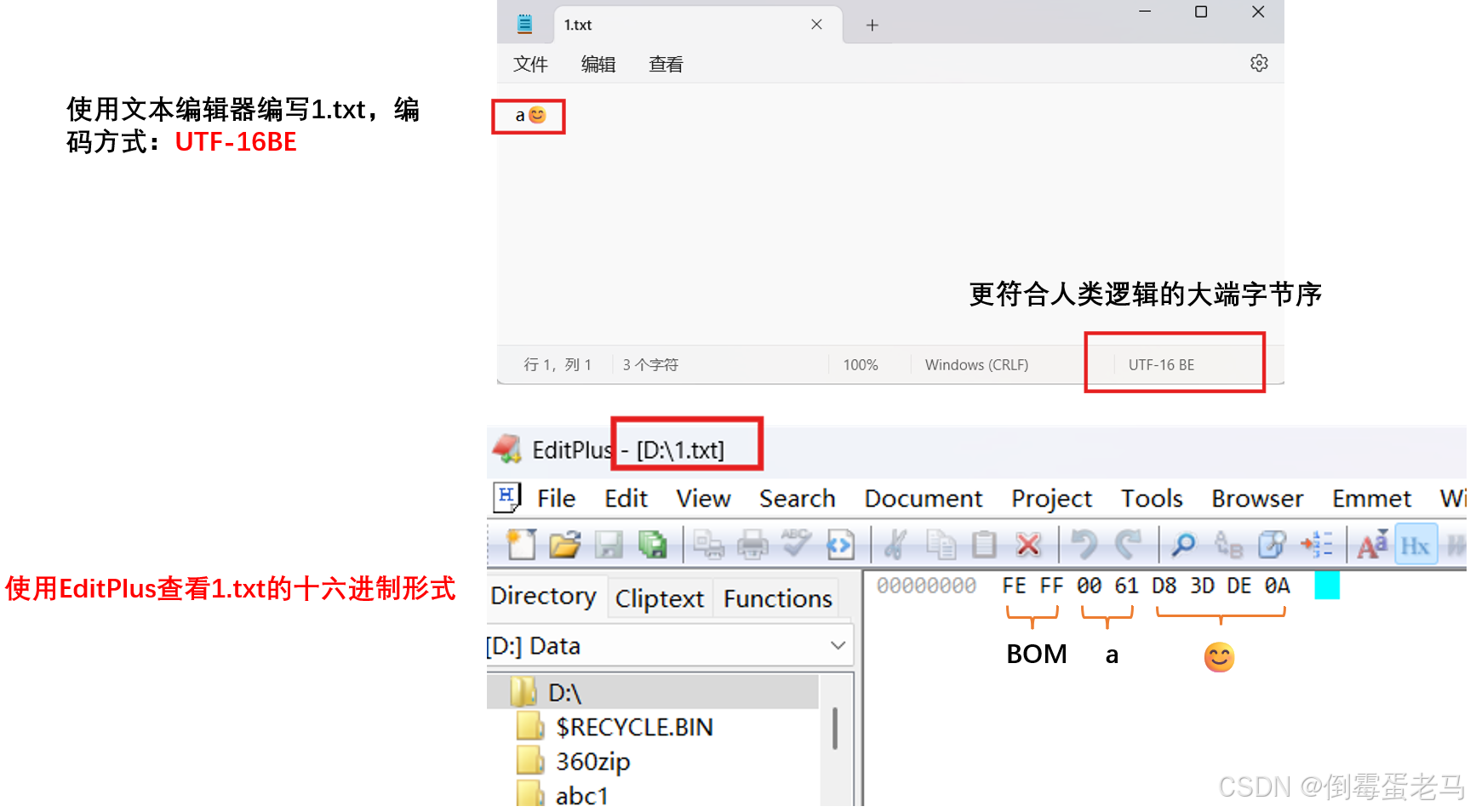
可以看到,UTF-16 LE 编码方式下,BOM 确实是 0xFE 0XFF,文本的内容对应的十六进制是 00 61 D8 3D DE 0A
验证案例2:UTF-16 LE(小端字节序)
用 UTF-16 LE 编码方式编写 1.txt 文件,文件内容依然是 "a😊" ,在前面已经知道经过 UTF-16 编码之后 'a':0x0061 ,'😊':0xD83DDE0A
🆗,在小端字节序下,该文本的十六进制形式应当如下:
BOM :0xFE 0xFF;
'a':0x61 0x00;
'😊':0x3D 0xD8 0x0A 0xDE
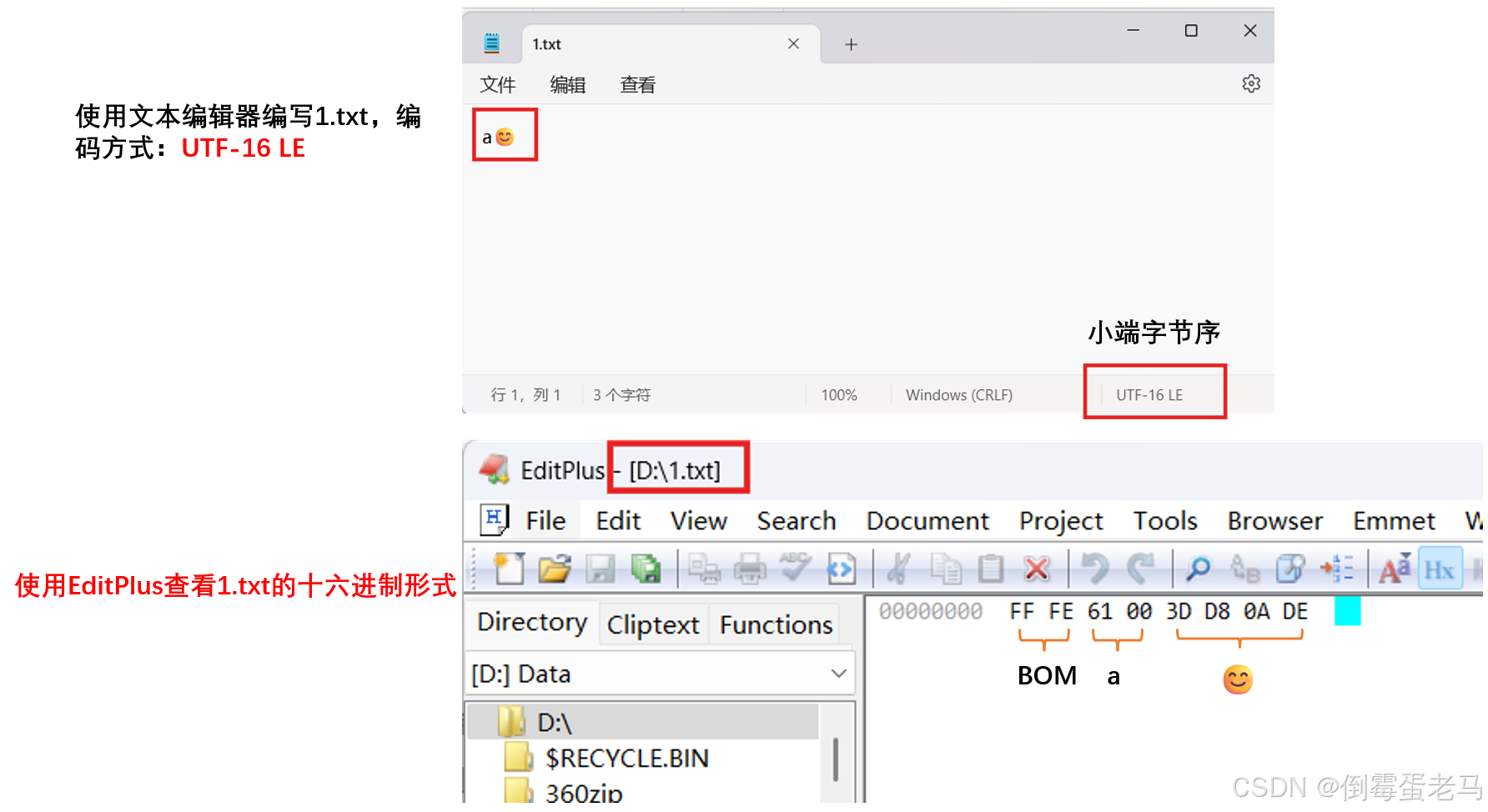
7.2.3 UTF-16的缺陷
① UTF-16 是变长编码,虽然 UTF-16 比 UTF-32 节省了很多空间,但是任何一个字符编码之后至少需要用 2 个字节存储,所以对以英语为母语的美国和西欧国家而言,UTF-16并没有太大的优势,因为使用ASCII编码只需要用1个字节存储
② 字节序敏感:必须明确标记 BOM ,否则跨平台传输可能乱码
7.3 UTF-8
后续提出的 UTF-8 在与 UTF-32、UTF-16 的角逐中取得胜利,是如今互联网使用最多的一种编码方案,大部分时候都是默认选择

UTF-8 是变长编码,其基本码元是 8 位 (1字节),这也是 UTF-8 中的 "8" 的含义。针对不同的 Unicode 字符,通过 UTF-8 编码之后,存储在计算机中的内容用 1 ~ 4 字节来存储
7.3.1 编码规则
UTF-8 针对不同的 Unicode 字符的编码规则如下表所示:

不同字符通过 UTF-8 编码之后,存储在计算机中的内容用 1~4 字节来存储,那计算机解码的时候是怎么区分该字符是几字节字符呢?
从表中可以看到,经过 UTF-8 编码之后,各字节字符的前缀信息是唯一的,计算机可以通过前缀信息正确解码。至于 0xxxxxxx 中的 xxxxxxx 是什么,下面结合具体的案例来说明
7.3.2 编码过程演示
以汉字 '中' 为例,其 Unicode 码点为 --> 10进制:20013
① 确定所需字节数
码点 20013 属于 2048 ~ 65535 范围,编码之后需要用 3 字节存储
② 将码点转换为二进制:
20013 ---> 01001110 00101101(需要凑整,空缺位置用 0 填充,凑到 8bit 的整数倍)
③ 开始编码:
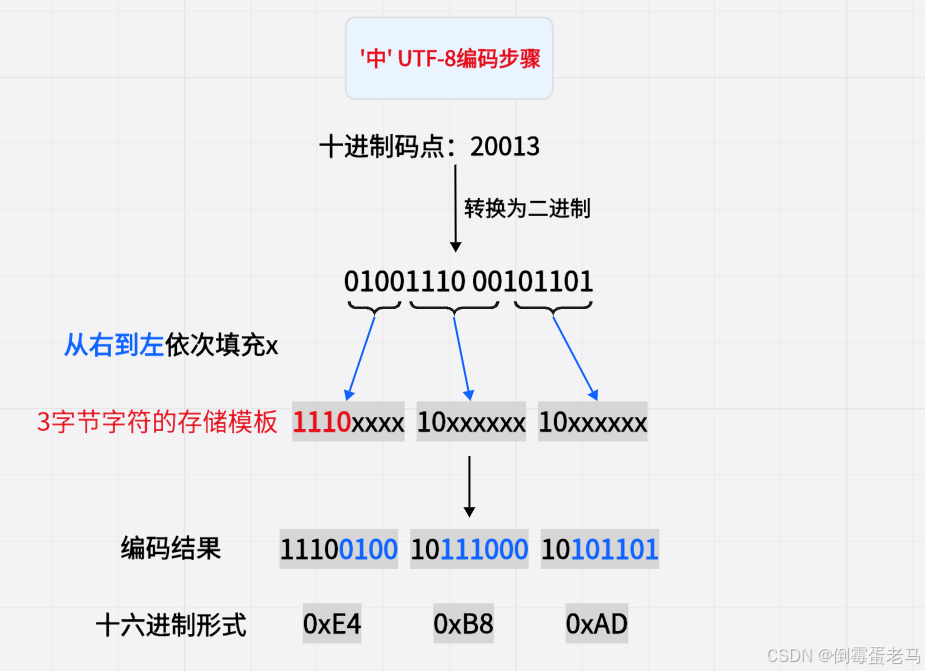
🆗,以上就是字符 '中' UTF-8 的编码过程,最终存储在计算机中的内容用 3 字节存储,其十六进制形式是 0xE4 0xB8 0xAD
验证:'中' 经过 UTF-8 编码之后,存储在计算机中的内容的十六进制形式是: 0xE4 0xB8 0xAD
用 UTF-8 编码方式编写 1.txt 文件,文件内容是 "中"
🆗,编写好文件后,使用 Editplus 查看 1.txt 的十六进制形式,如下:
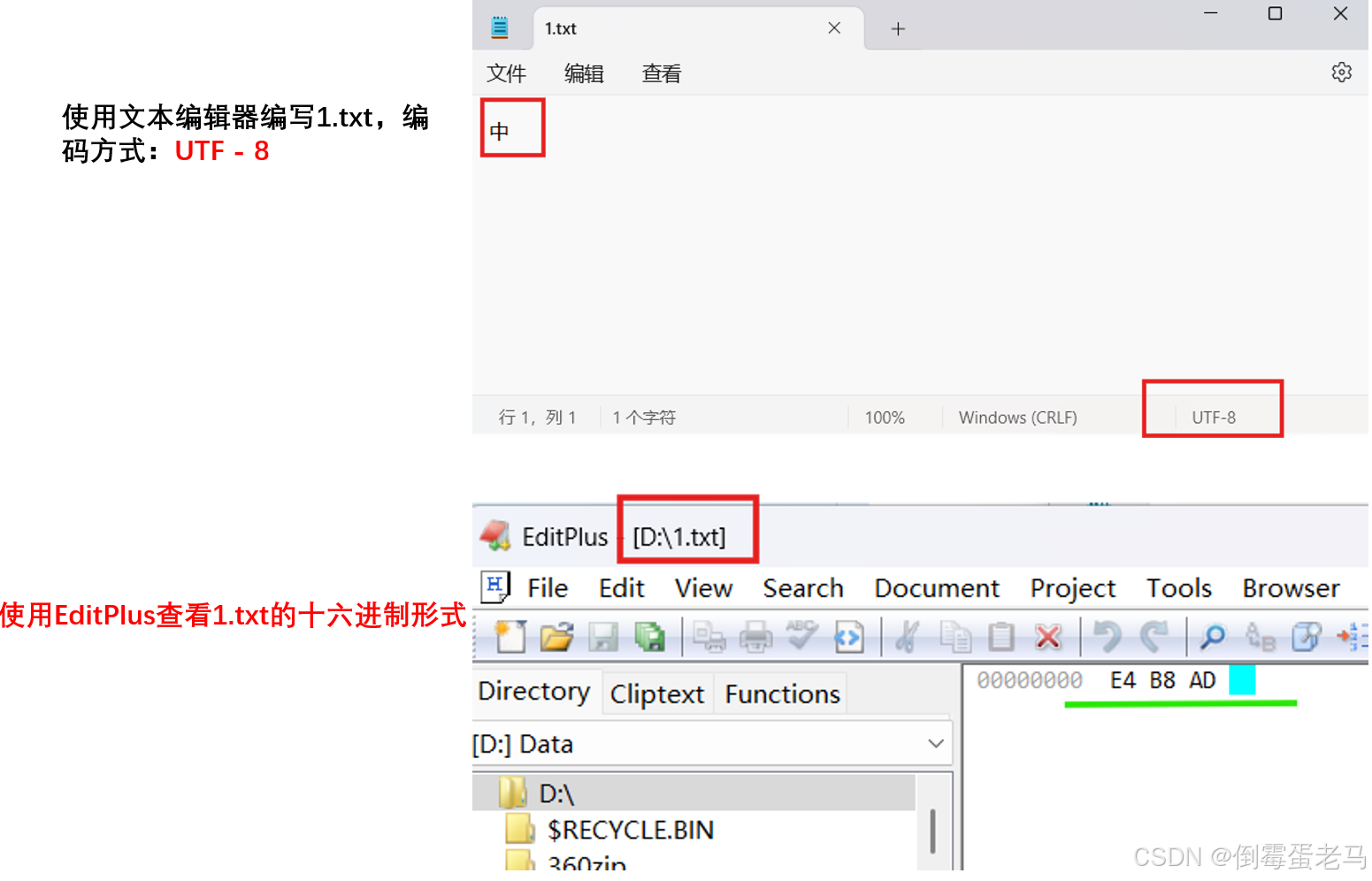
可以看到,'中' 经过 UTF-8 编码之后,存储在计算机中的内容用 3 字节存储,其十六进制形式确实是 0xE4 0xB8 0xAD
再看一个案例: 'a'(Unicode码点:97) 经过UTF-8编码之后,存储在计算机中的内容的十六进制形式是否是:0x61
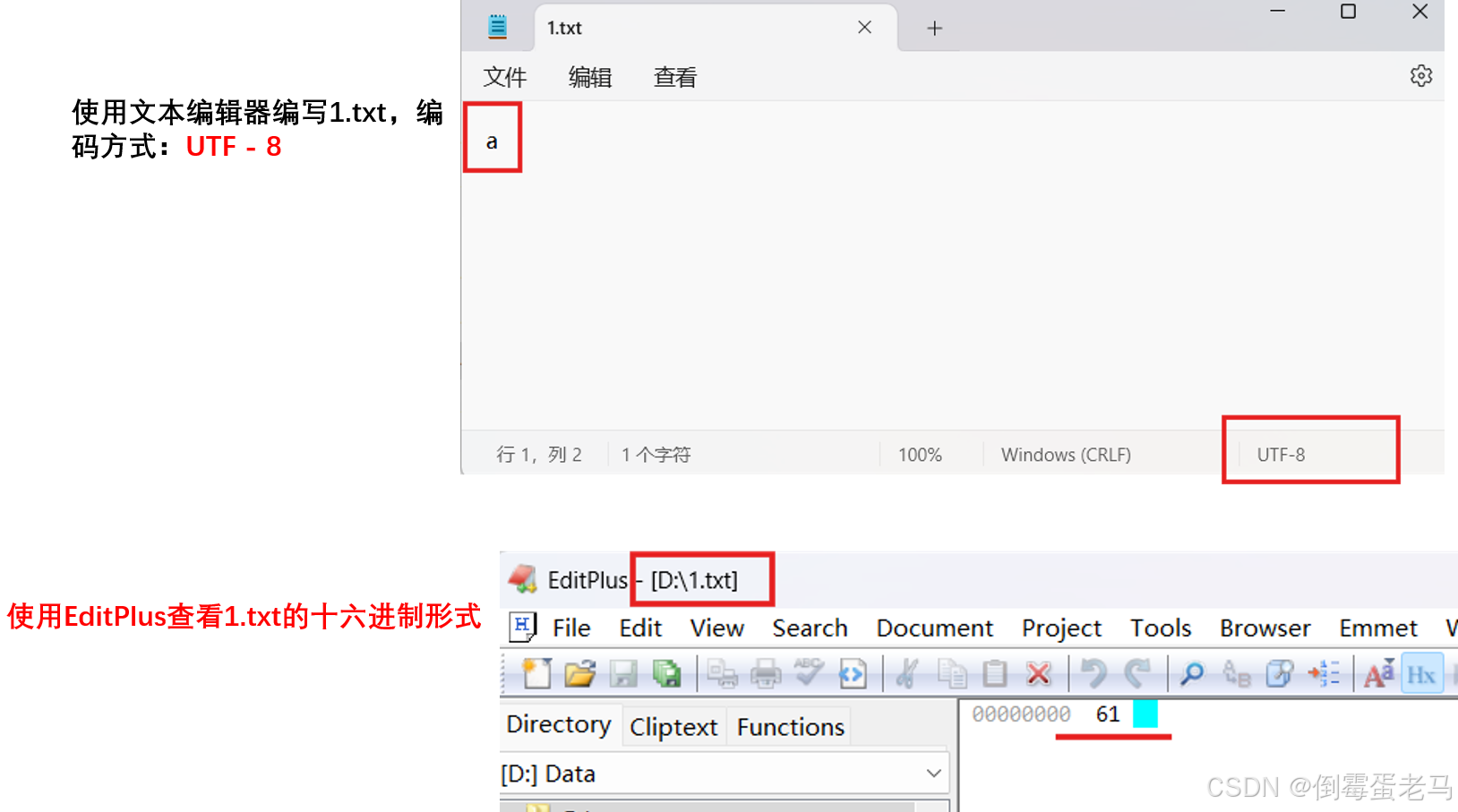
可以看到,'a' 经过 UTF-8 编码之后,存储在计算机中的内容用 1 字节存储,其十六进制形式确实是 0x61
🆗,UTF-8的解码过程就不演示了吧,就是UTF-8编码的逆过程而已,很简单,这里就不再赘述了
7.3.3 Windows下为什么会有 UTF-8 和 UTF-8 BOM ?
其实 UTF-8 编码是不涉及字节序问题的,无需 BOM 标识。但是熟悉 Windows 系统的同学应该知道,Windows 的文本编辑器的编码方式有 UTF-8、UTF-8 BOM,如下所示:
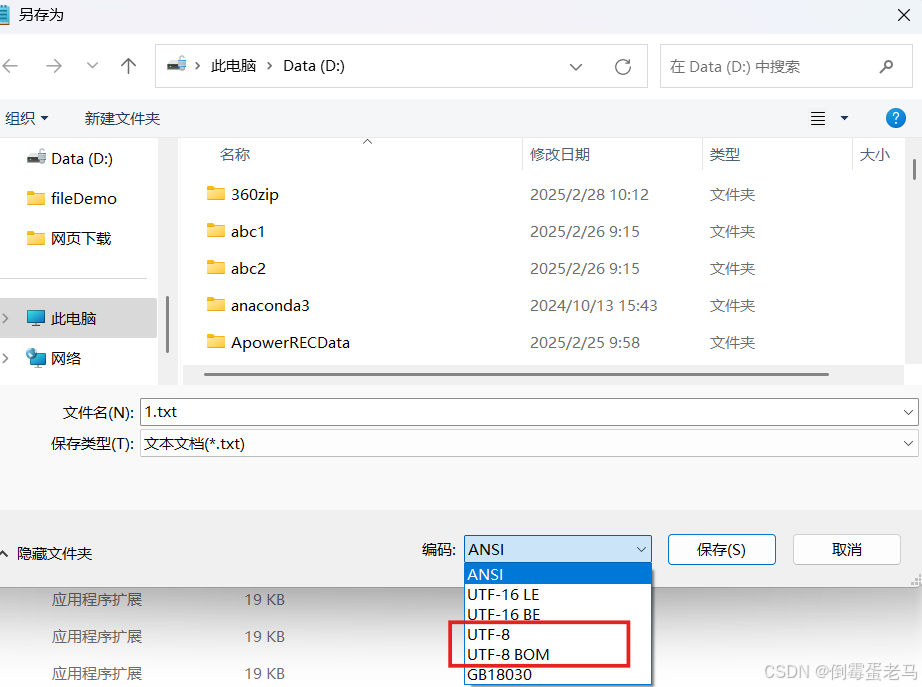
为什么 Windows 下有 UTF-8 BOM 已经无从查证,很可能是 Windows 历史发展的遗留产物,大家也不需要管
验证:UTF-8 的 BOM 是:0xEF 0xBB 0xBF
用 UTF-8 BOM 编码方式编写 1.txt 文件,文件内容是 "中",在前面的案例我们已经知道,"中" 经过 UTF-8 编码之后其十六进制形式是:0xE4 0xB8 0xAD
🆗,编写好文件后,使用 Editplus 查看 1.txt 的十六进制形式,查看 BOM 标识是否为 0xEF 0xBB 0xBF。如下:
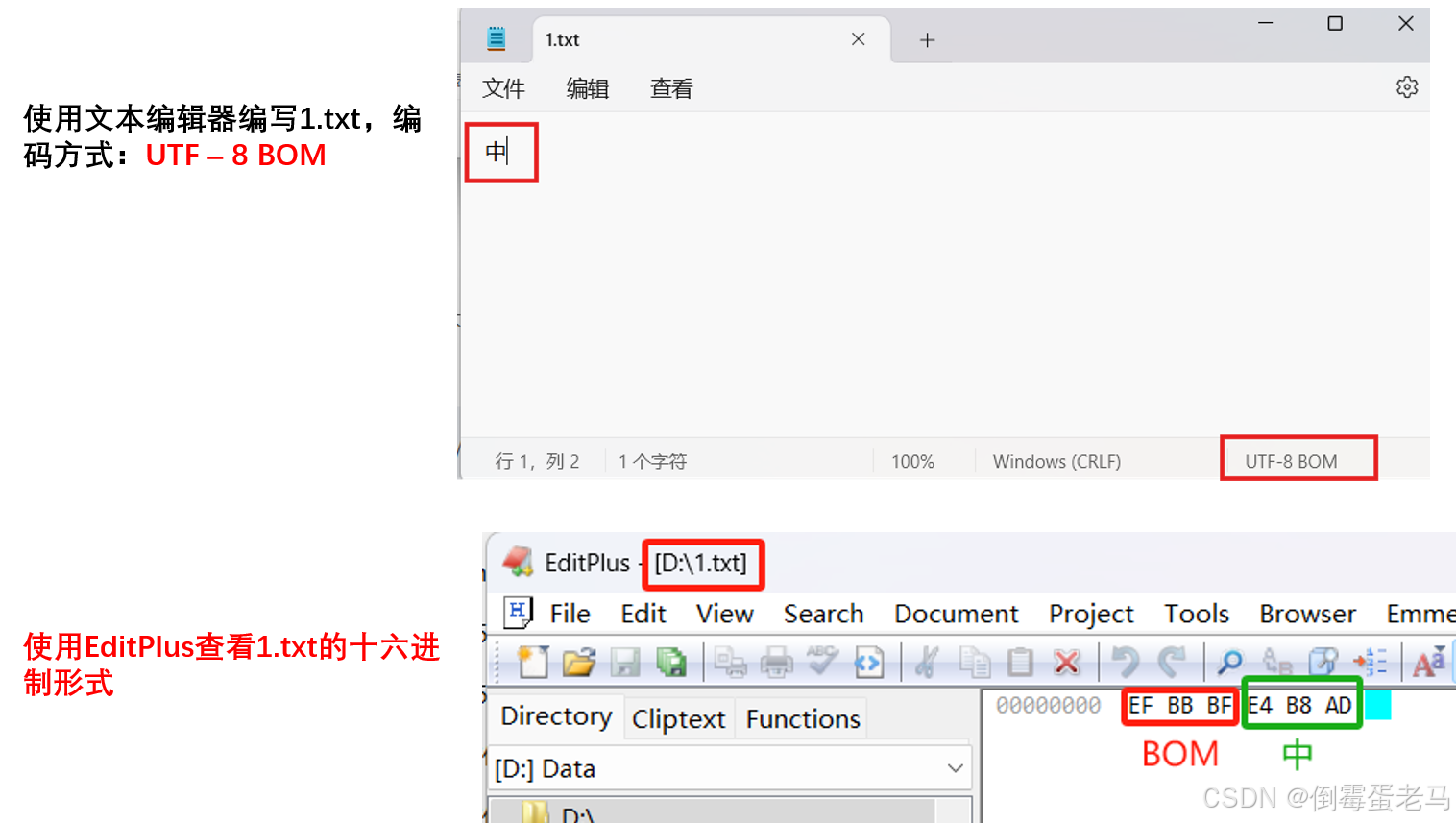
可以看到,UTF-8 BOM 编码方式下,BOM 标识确实是 0xEF 0xBB 0xBF ,除了文件开头的 BOM 标识,UTF-8 BOM 与 UTF-8 是完全一致的,所以说UTF-8是不涉及字节序问题的
问题:是否使用UTF-8 BOM编码?
现在几乎不使用 UTF-8 BOM ,Windows 的记事本也会默认以 UTF-8 编码方式保存。就跨平台的兼容性而言,UTF-8 也比 UTF-8 BOM 更好,所以直接使用 UTF-8 即可
7.3.4 UTF-8的优缺点
优点
① 完全兼容ASCII码:ASCII 字符集中的字符分别经过 ASCII 编码与 UTF-8 编码得到的内容完全一致
② 变长编码:
-
英文字母、数字:1 字节
-
希腊文、西里尔文:2 字节
-
中文、日文等:3 字节
-
Emoji👴、生僻字:4 字节
③ 空间利用率:相比 UTF-16/32,对英文为主的文本节省 50%~75% 空间
④ 无字节序问题:单字节为最小单位,不涉及字节序问题,适合跨平台传输
缺点
① 变长编码导致处理效率低:需逐字节解析前缀才能确定该字符是几字节字符,不如定长编码 UTF-32 高效
② 对某些非英文文字存储效率不足:例如中文,常用的汉字经过 UTF-8 编码之后需要用 3 字节存储,一些非常用的汉字需要用 4 字节存储。相同汉字下,GBK编码、GB2312编码 只需要用 2 字节存储。所以,在数据大部分都是中文的情况下采用 GBK编码、GB2312编码 的可以节省下不少空间
7.4 总结
| UTF-8 | UTF-16 | UTF-32 | |
|---|---|---|---|
| 最小单位 | 1 字节 | 2 字节 | 4 字节 |
| 编码类型 | 变长,1 ~ 4字节 | 变长,2 或 4 字节 | 定长,4字节 |
| 字节序问题 | 无 | 需 BOM 标识 UTF-16 BE:0xFE 0XFF UTF-16 LE:0XFF 0XFE | 需 BOM 标识 UTF-32 BE:0x00 0x00 0xFE 0xFF UTF-16 LE:0x00 0x00 0xFF 0xFE |
| 存储效率 | |||
| - ASCII 字符 | 1 字节(最优) | 2 字节(浪费) | 4 字节(极浪费) |
| - 汉字(BMP 内) | 3 字节 | 2 字节(最优) | 4 字节 |
| - Emoji(辅助平面) | 4 字节 | 4 字节(代理对) | 4 字节 |
8.补充:关于ANSI编码
在 windows 系统下记事本的编码方式还可以选择 ANSI 编码,如下:
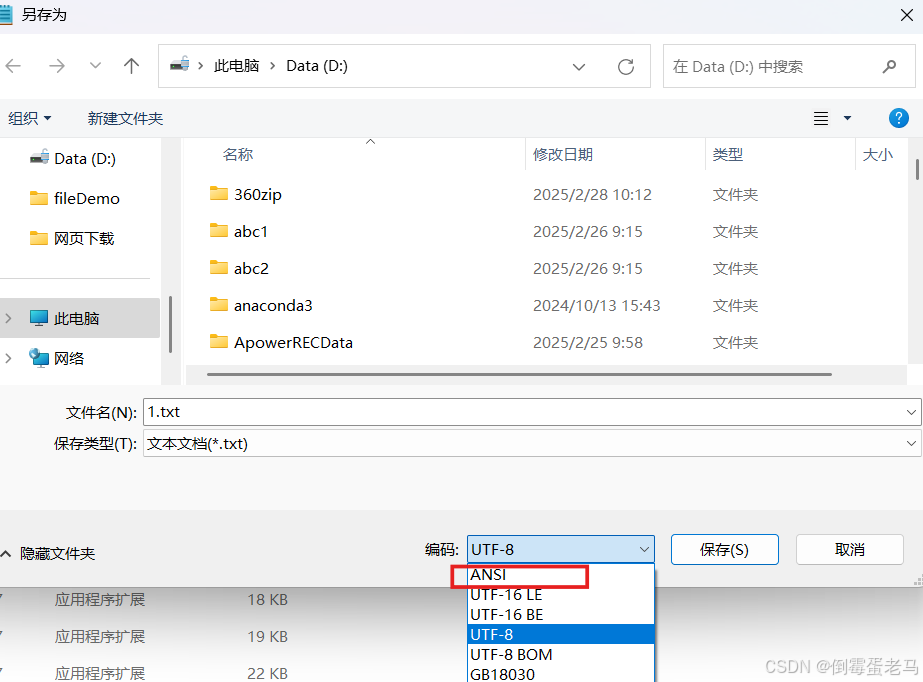
那这个 ANSI 编码到底是何方神圣呢? 其实 ANSI 编码并不是一种新的编码方案,ANSI 是泛指各个地区默认的字符编码。在 windows 系统下,中国大陆ANSI编码默认是是 GBK ,台港澳地区是 Big5 ,韩国是 EUC-KR 。另外 ANSI 编码在不同的操作系统下也会有差异,例如在 Mac 系统下,ANSI编码默认是 UTF-8
9.乱码的本质原因
🆗,讲到这里,大家应该都知道了乱码的原因了吧?
仍然是举例子,比如说发送方用 GBK 编码方式编写好一个文本文件 1.txt ,文本内容是:"宝子"。接收方以 UTF-8 编码打开文本文件,情况如下:
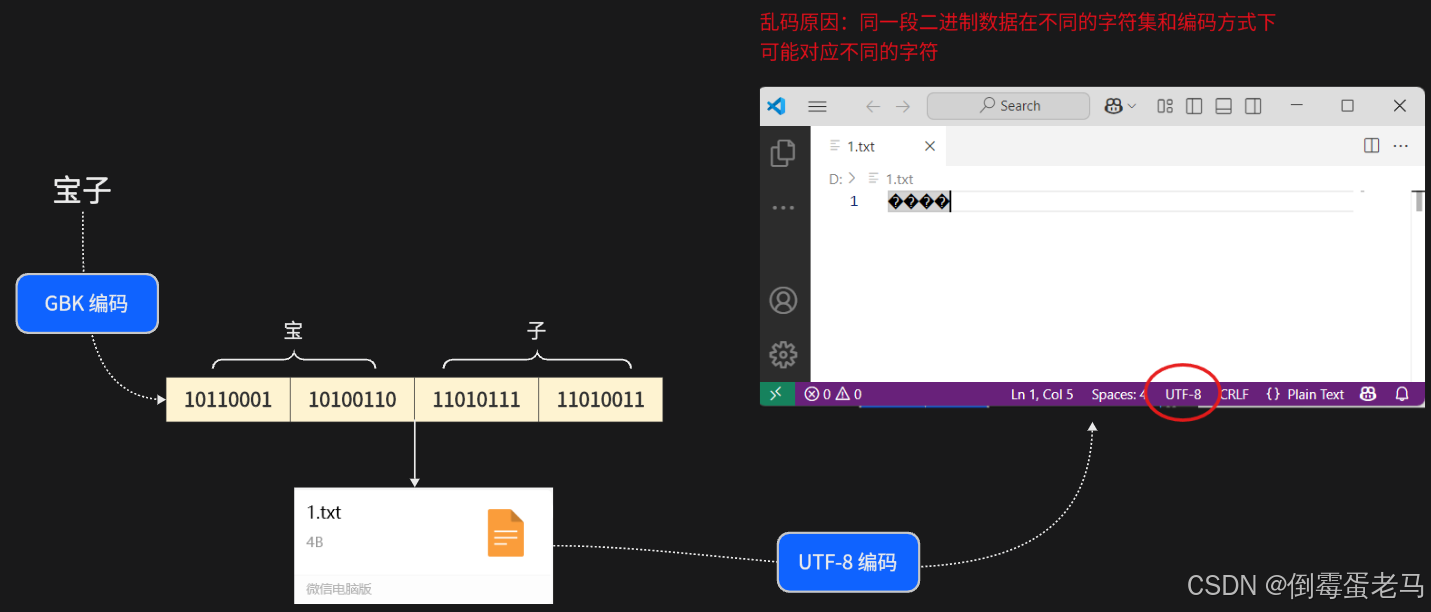
文本文件发生乱码的本质原因:同一段二进制数据在不同的字符集和编码方式下可能对应不同的字符。而 Unicode 字符集中有一个专门用于标识无法识别或者展示的字符 � ,所以当使用 UTF-8 编码方式打开某个文本文件时,如果遇到无法正确解析的内容,就会替换为 �
上图中,发送方以 GBK 编码方式编写文本文件 1.txt ,接收方以 UTF-8 编码方式打开,接收方计算机按 UTF-8 编码方式对该文本文件进行解码,由于每个字节的内容都无法正确解析,所以显示了 4 个 �

















 3586
3586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









