







接下来是vision transformer这篇论文,谷歌于21年1月发表。

在这篇论文发表之前,就有很多把transformer引入CV领域的工作了,但是它们的效果都不如传统卷积好,作者认为是他们用于训练的数据不够大。然后作者在一个有3亿张图片的大数据集上预训练,发现得到的效果比用卷积还要好。它证明了完全不用卷积也可以很好地提取图像特征。它的结构也很简单,只需要对图片进行截patch处理,之后的结构就和Bert类似。
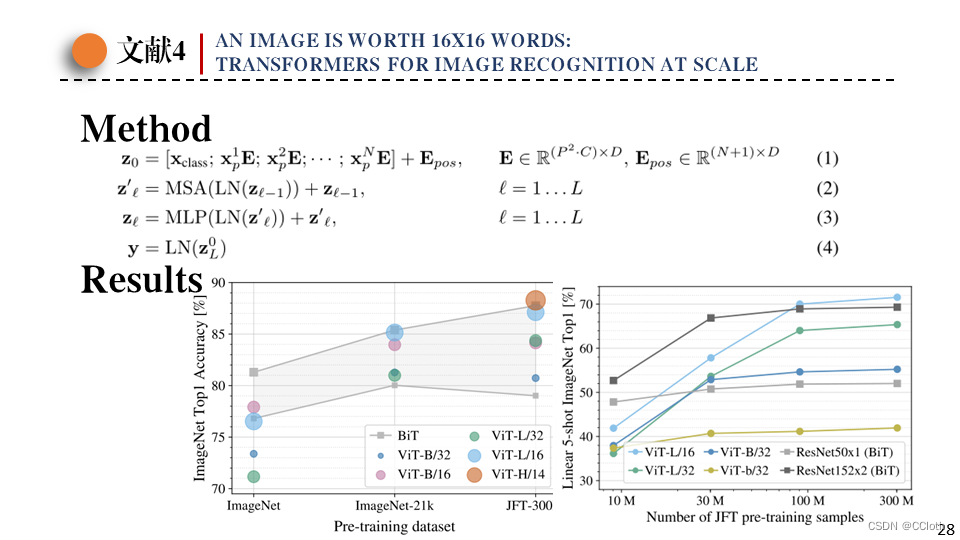
这是整个模型的流程,不需要进行什么特殊处理,就像在文本上处理一样。得到的结果也和作者说的一样,如果数据量比较小,那么transformer是不如卷积的,但是数据量大了以后transformer基本就比卷积效果好了。















 2090
2090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









