







接下来是MoCo这篇论文,facebook于20年2月发表。

这篇论文研究的是对比学习。
受NLP自监督预训练的模型影响,CV这边也希望能有一个自监督预训练的特征提取器,这样就能很方便的在其他下游任务微调了。而对比学习的目的就是能够自监督预训练得到一个特征提取器。
这篇论文从字典查询的视角来看待对比学习,要想对比学习效果好,作者认为有两个条件:第一点是字典要足够大,第二点是字典中一致性要高。

接下来详细解释一下为什么要满足这两点。
字典要大,当然最好情况下是对每个负样本计算相似性,但由于负样本个数太多,无论是从时间上还是内存上考虑,全部计算一遍都不现实,所以只能进行采样,字典越大存储的负样本越多采样效果越接近理想情况。
字典中特征向量要保持一致性,一致性指的是这些特征向量尽量从同一个编码器运算得到,也就是希望这些向量尽量在一个batch中编码得到。这是避免模型学到捷径,比如根据编码器的差别来分类。
现有的工作都很难同时做到这两点,SimCLR模型是两个编码器,因为是即时计算样本特征,所以特征一致性很好。但是一个batch内能容纳的负样本个数很少,也就是这个模型的字典很小。InstDisc模型是一个编码器,它把所有负样本都提前运算得到128维特征向量,并保存在内存中,这样每次可以抽样拿出来很多负样本向量,不受batch大小限制了,不过它的特征一致性就很差了。
最后是本篇论文提出的模型,它有两个编码器,但只有一个参与梯度更新,另一个是动量编码器,不参与梯度更新,需要手动更新参数。动量编码器更新方式如图,当超参数m很大时,动量编码器更新缓慢,保证计算得到的样本一致性很高。同时使用先进先出的队列维护之前计算得到的负样本,队列长度和batch大小同样没关系,这样字典就可以很大。
一次看的负样本多和负样本一致性好是一对互斥的概念,MoCo在两者取了个折中。

接下来是代码部分,moco的代码非常简洁,特征提取然后矩阵相乘计算相似度,然后就可以计算损失了。损失其实是一个交叉熵损失,因为希望正样本相似度最大,负样本相似度最小。
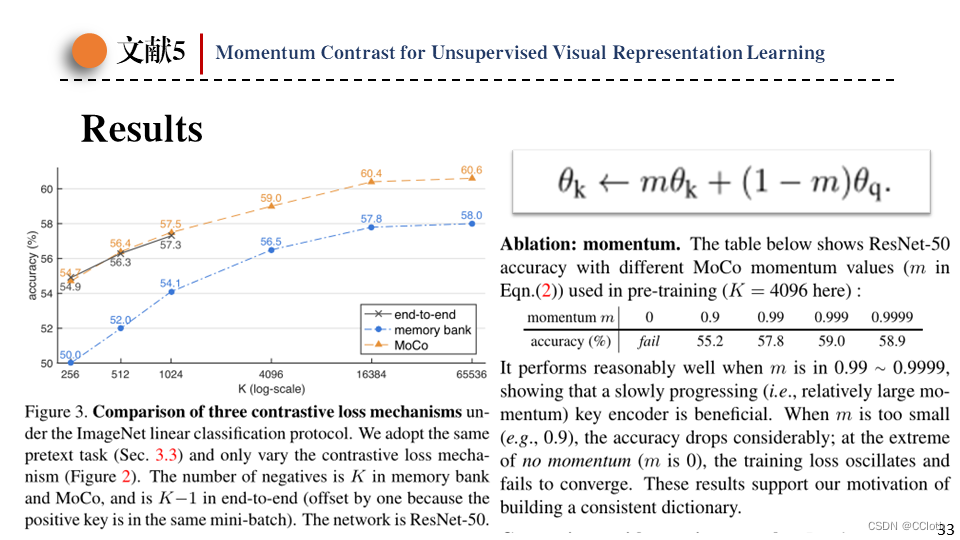
这是实验结果,左图中可以看到端到端的形式字典很小,受batchsize限制实验最多只做到了1024,而memory bank的形式虽然字典可以很大,但是一致性太差导致效果不好。
右图为动量值的消融,动量为0,那动量编码器就成了普通编码器的copy,模型直接无法收敛。这时候模型就因为字典一致性差学习到了一条捷径。(因为两个编码器相同,所以anchor和正样本的特征向量之间的相似度就近似成了向量长度,所以编码器只需要把特征向量长度尽可能拉长。)















 1233
1233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









