







这篇论文是24年1月的,提出了基于原理的prompt方法,有效提升了学生模型的表现。

由于对模型微调代价大,且微调过后模型在其它任务上的适用性变差,所以作者提出了针对于prompt的改进方法。作者提出的TPD prompt方法在八个推理任务上相对于CoT prompt方法平均提升了6.2%的性能。下图是TPD的大体思想,通过教师模型将问题转为一系列解决问题的指令,然后让学生回答问题,这时候学生可能会出错,再把学生错误回答交给教师模型,让教师模型更正指令,并根据错误回答总结生成一些原理,学生在更正后的指令和原理列表的指导下给出更完善的回答。

TPD框架分两个阶段,第一阶段是生成原理,第二阶段是使用原理。下图中的前三步是在生成原理,最后一步是在使用原理。

生成原理分三步,第一步作者从训练集中采样了几个问题和回答,然后交给教师模型,让教师模型总结解决此类问题的指令以及添加了一个示例,这个示例来自于之前抽样的那批问答,下图显示了教师模型生成的指令。
第二步让学生模型回答验证集中的问题,上一步生成的指令作为prompt一并输入给学生。

第三步收集学生的错误回答,这时候要过滤一下,因为教师LLM也可能出错,所以把这些问题让教师模型回答一下,如果教师模型也回答错误那就剔除掉。最后保留下来的问题就是教师回答正确但学生回答错误的问题了。接下来使用下图的伪代码从错误集中总结出一系列原理。
先从错误集E中挑出一个子集Es,让教师模型对于子集Es给出解决问题的原理,然后错误集剩下的部分为Er,遍历Er中每个错误回答,由教师模型决定现有的原理列表是否能够纠正这个错误回答,如果可以那就跳过,如果不行那就根据这个回答总结出新的原理并加入原理列表。最后人类介入生成的原理列表,删除一些不正确的或者令人困惑的内容,保证最终原理列表的可靠性和清晰度。

接下来是如何使用这些原理,作者提到有很多方法可以操作,例如直接把原理列表作为prompt输入给学生等等,最终作者选择利用原理列表更新解决问题的指令以及示例。具体操作很简单,选取的示例来自于之前的错误集,按照错误集中违反原理条数来排序,取违例条数最多的那几个示例,然后让教师模型生成正确回答,把这几个示例添加到prompt中,并且prompt中的解决问题的指令也基于原理列表进行了修正,最后的prompt就是上面这张图展示的样子。要注意之前从训练集抽样的示例仍然存在。
然后下图是针对不同的原理使用方法进行的实验,可以看到直接把原理列表插入prompt带来提升很小,作者给出的解释是原理比较抽象,直接作为上下文给学生模型不一定能理解,另外过长的上下文也可能导致模型丢失信息。然后批评再改进策略反而使性能下降,作者认为是反馈或批评这类术语导致模型质疑自己一开始的回答,然后对一开始的回答进行重大修改。

这篇论文使用GPT-3.5作为学生模型,GPT-4作为教师模型。
接下来是消融实验,首先作者对于解决问题的指令中示例个数进行了消融,要注意这里的示例是从训练集中抽样得到的,并非之后从验证集挑选的示例。可以看到示例数越多,学生模型解决问题的能力越强。
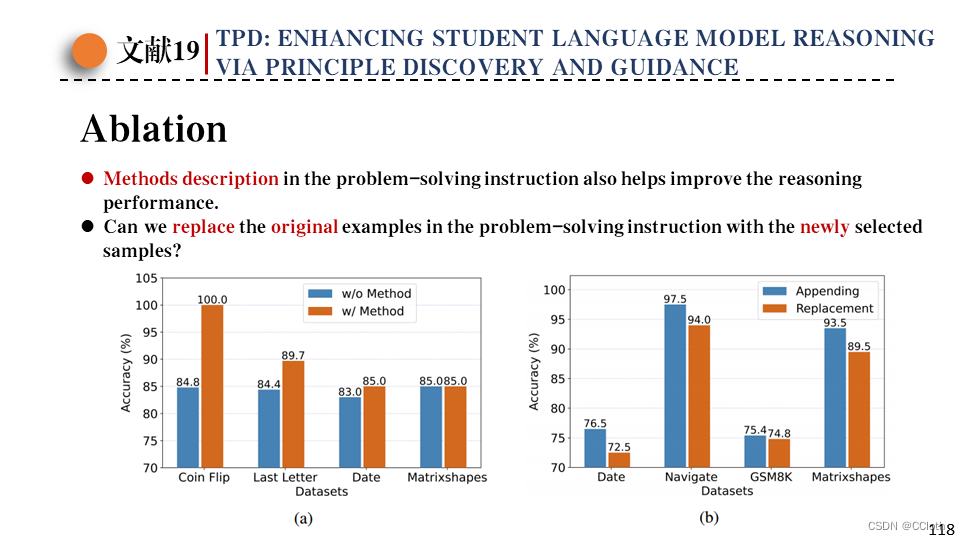
接下来是作者对于解决问题的方法描述做了一个消融,这个方法描述就是之前教师模型生成的。从下面左图中可以看到加上方法描述模型性能更好一点。之后是从验证集中挑选出了新的示例,这里是否要替换掉之前训练集中采样得到的示例呢,通过实验发现二者直接拼接效果最好。

最后一个消融实验,在错误集挑选示例的时候挑违例数最高的几个示例?视任务不同所需要的数量不同,最后为了统一和简单,作者每个任务都挑前三个示例。

最后是结果展示,学生模型是GPT-3.5,教师模型是GPT-4,在除了Shuffled任务的七个其他任务都取得了最好的表现。















 1413
1413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









