







本文基于Andrew_Ng的ML课程作业
1-Regularized Linear Regression with scipy.optimize.minimize:对一个水库的流出水量以及水库水位进行正则化线性回归
导入库
import numpy as np
from scipy.io import loadmat
import scipy.optimize as opt
import matplotlib.pyplot as plt函数:计算正则化的代价函数J(theta)
def computeRegCost(theta,X,y,lambada): #计算正则化的代价函数J(theta)
X,y,theta=map(np.matrix,(X,y,theta))
m=X.shape[0]
inner=np.power(X*theta.T-y,2) #num_of_X'features=2
cost=np.sum(inner)/(2*m)
reg=(lambada/(2*m))*np.sum(np.power(theta[:,1:theta.shape[1]],2))
regcost=cost+reg
return regcost函数:计算正则化的梯度grad
def computeRegGradient(theta,X,y,lambada): #计算正则化的梯度grad
X,y,theta=map(np.matrix,(X,y,theta))
m=X.shape[0]
parameters=int(theta.shape[1])
grad=np.zeros(parameters) #梯度grad是和theta同维的数组
error=X*theta.T-y
for i in range(parameters):
term=np.multiply(error,X[:,i])
if (i==0):
grad[i]=np.sum(term)/m
else:
grad[i]=np.sum(term)/m+(lambada/m)*theta[:,i]
return grad函数:拟合正则化线性回归的可视化函数
def visualizing(final_theta): #拟合正则化线性回归的可视化函数
b = final_theta[0]
k = final_theta[1]
fig,ax=plt.subplots(figsize=(12,8))
plt.scatter(X[:,1],y,c='r',label="Training Data")
plt.plot(X[:,1],X[:,1]*k+b,c='b',label="Prediction")
ax.legend(loc='upper left')
ax.set_xlabel("Water Level")
ax.set_ylabel("Flow")
plt.show()主函数:
#Regularized Linear Regression with scipy.optimize.minimize:对一个水库的流出水量以及水库水位进行正则化线性回归
data=loadmat("ex5data1.mat")
X,y,Xval,yval,Xtest,ytest=data['X'],data['y'],data['Xval'],data['yval'],data['Xtest'],data['ytest']
X,Xval,Xtest=[np.insert(x,0,values=1,axis=1) for x in (X,Xval,Xtest)] #X.shape=(12,2),Xval.shape=(21,2),Xtest.shape=(21,2)
theta=np.ones(X.shape[1])
lambada=1
final_theta=opt.minimize(fun=computeRegCost,x0=theta,args=(X,y,lambada),method='TNC',jac=computeRegGradient,options={'disp':True}).x
print(final_theta)
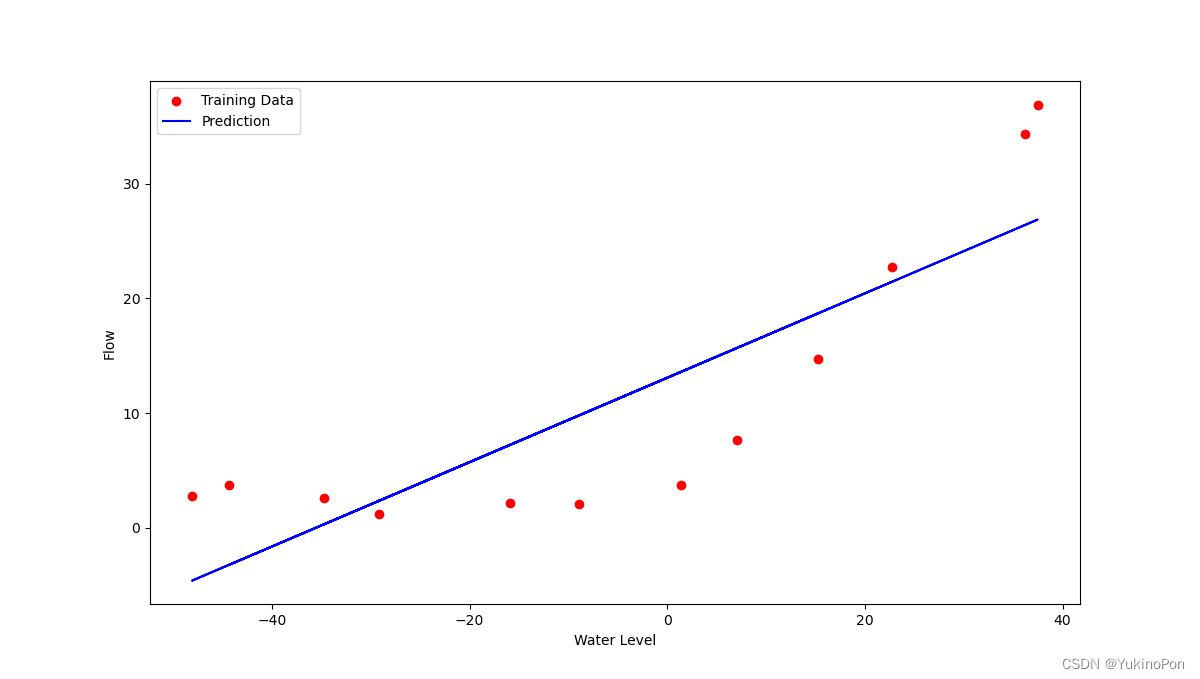
visualizing(final_theta)final_theta
![]()
拟合正则化线性回归可视化结果
正则化线性回归梯度
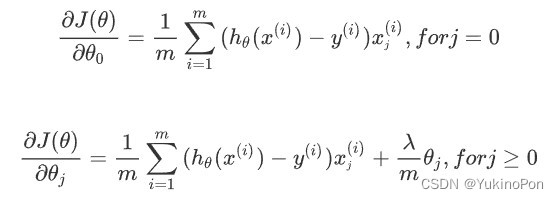
2-Plot learning curves to decide whether a bias or a variance problem:绘制学习曲线判断欠拟合还是过拟合
导入库
import numpy as np
from scipy.io import loadmat
import scipy.optimize as opt
import matplotlib.pyplot as plt函数:计算正则化的代价函数J(theta)
def computeRegCost(theta,X,y,lambada): #计算正则化的代价函数J(theta)
X,y,theta=map(np.matrix,(X,y,theta))
m=X.shape[0]
inner=np.power(X*theta.T-y,2) #num_of_X'features=2
cost=np.sum(inner)/(2*m)
reg=(lambada/(2*m))*np.sum(np.power(theta[:,1:theta.shape[1]],2))
regcost=cost+reg
return regcost函数:计算正则化的梯度grad
def computeRegGradient(theta,X,y,lambada): #计算正则化的梯度grad
X,y,theta=map(np.matrix,(X,y,theta))
m=X.shape[0]
parameters=int(theta.shape[1])
grad=np.zeros(parameters) #梯度grad是和theta同维的数组
error=X*theta.T-y
for i in range(parameters):
term=np.multiply(error,X[:,i])
if (i==0):
grad[i]=np.sum(term)/m
else:
grad[i]=np.sum(term)/m+(lambada/m)*theta[:,i]
return grad函数:正则化线性回归函数
def reg_linear_regression(X,y,lambada=1): #正则化线性回归函数
theta = np.ones(X.shape[1])
final_theta = opt.minimize(fun=computeRegCost, x0=theta, args=(X, y, lambada), method='TNC', jac=computeRegGradient,options={'disp': True}).x
return final_theta函数:绘制学习曲线:error(J_theta)-m(training set size)
def plot_learning_curve(X,y,Xval,yval): #绘制学习曲线:error(J_theta)-m(training set size)
tr_cost, cv_cost = [], []
m = X.shape[0]
for i in range(1,m+1):
res=reg_linear_regression(X[:i,:],y[:i],0) #不使用正则化 #使用限制size的training_set来拟合模型
tr=computeRegCost(res,X[:i,:],y[:i],0) #使用相同的training_set来训练代价
cv=computeRegCost(res,Xval,yval,0)
tr_cost.append(tr)
cv_cost.append(cv)
fig,ax=plt.subplots(figsize=(12,8))
plt.plot(np.arange(1,m+1),tr_cost,label="Training Cost")
plt.plot(np.arange(1,m+1),cv_cost,label="Cross Validation Cost")
plt.legend(loc='upper right')
plt.show()主函数:
#Plot learning curves to decide whether a bias or a variance problem:绘制学习曲线判断欠拟合还是过拟合
data=loadmat("ex5data1.mat")
X,y,Xval,yval,Xtest,ytest=data['X'],data['y'],data['Xval'],data['yval'],data['Xtest'],data['ytest']
X,Xval,Xtest=[np.insert(x,0,values=1,axis=1) for x in (X,Xval,Xtest)] #X.shape=(12,2),Xval.shape=(21,2),Xtest.shape=(21,2)
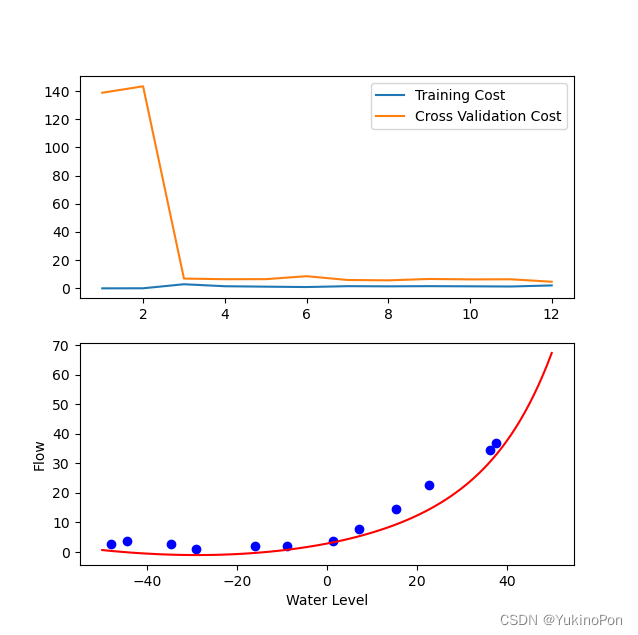
plot_learning_curve(X,y,Xval,yval)学习曲线(lambada=0无正则化)
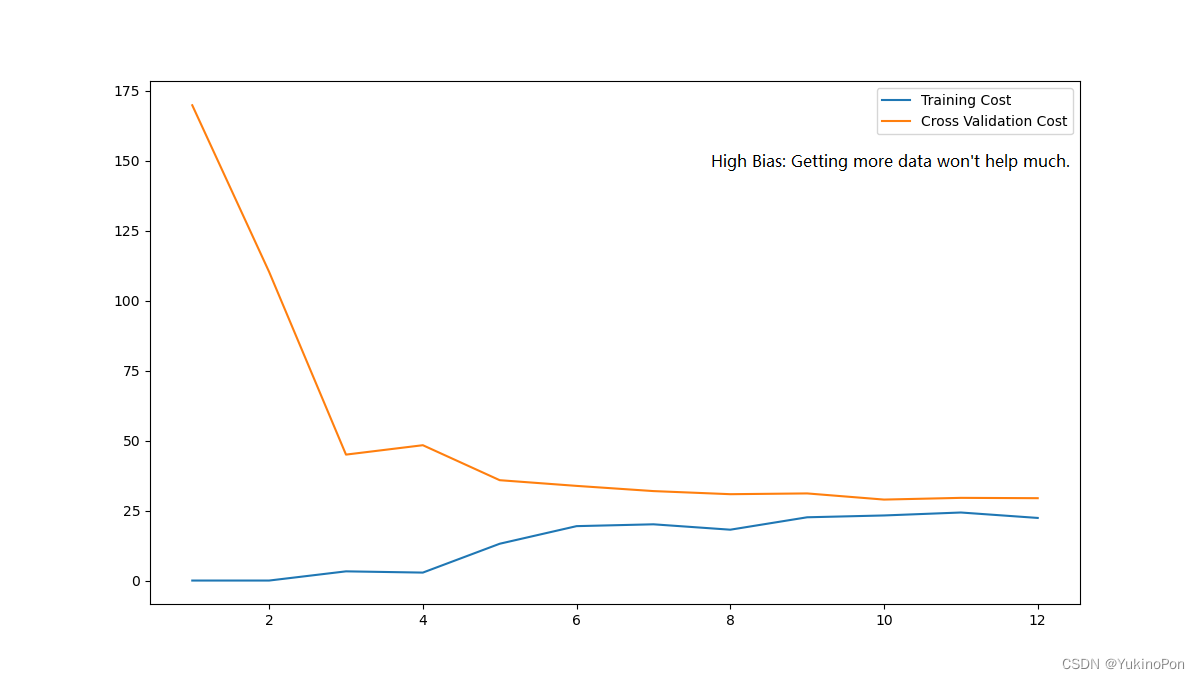
3-Integrate regularized polynomial linear regression,bias/variance,underfitting/overfitting,training set/cross-validation set/test set to get the optimal x:获得最佳的lambada
导入库
import numpy as np
import pandas as pd
from scipy.io import loadmat
import scipy.optimize as opt
import matplotlib.pyplot as plt函数:添加多项式特征函数(输入原始X和幂次power,返回X的1-power次幂)
def add_poly_features(X,power): #添加多项式特征函数(输入原始X和幂次power,返回X的1-power次幂)
data={'f{}'.format(i): np.power(X,i) for i in range(1,power+1)}
#'...{}'.format(x):format中的内容填充到花括号里
df=pd.DataFrame(data)
return df函数:均值归一化函数
def mean_normalize_features(df): #均值归一化函数
return df.apply(lambda column:(column-column.mean())/column.std())
#关键字lambda函数:lambda argument_list(输入:参数列表):expression(输出:单行参数表达式)
#pd.apply():自动遍历整个Series或DataFrame,对每一个元素运行()内的函数
#这里默认对每一列(column也可用x或其他表示)进行遍历,即依次对f1,f2,f3列进行(column-column.mean())/column.std()的操作函数:数据预处理整合函数
def data_preprocessing(*args,power): #数据预处理整合函数
#def function( ,*args):传入参数个数未知,且不需要知道参数名称时(在函数定义中将接纳任意数量实参的形参放最前面);使用参数时for arg in args:(顺序同传入参数顺序)
def embedded_for_args(arg): #使用*args时为了返回多个值需要内嵌一个函数,使用return [embedded_for_args(arg) for arg in args]依次返回多个值
df=add_poly_features(arg,power)
ndarr=mean_normalize_features(df).values #dict.values():获取当前字典中所有键值对中的值,返回一个数组;返回ndarr是一个12行power列的数组
ndarr=np.insert(ndarr,0,values=1,axis=1)
return ndarr
return [embedded_for_args(arg) for arg in args]函数:计算正则化的代价函数J(theta)
def computeRegCost(theta,X,y,lambada): #计算正则化的代价函数J(theta)
X,y,theta=map(np.matrix,(X,y,theta))
m=X.shape[0]
inner=np.power(X*theta.T-y,2) #num_of_X'features=2
cost=np.sum(inner)/(2*m)
reg=(lambada/(2*m))*np.sum(np.power(theta[:,1:theta.shape[1]],2))
regcost=cost+reg
return regcost函数:计算正则化的梯度grad
def computeRegGradient(theta,X,y,lambada): #计算正则化的梯度grad
X,y,theta=map(np.matrix,(X,y,theta))
m=X.shape[0]
parameters=int(theta.shape[1])
grad=np.zeros(parameters) #梯度grad是和theta同维的数组
error=X*theta.T-y
for i in range(parameters):
term=np.multiply(error,X[:,i])
if (i==0):
grad[i]=np.sum(term)/m
else:
grad[i]=np.sum(term)/m+(lambada/m)*theta[:,i]
return grad函数:正则化线性回归函数
def reg_linear_regression(X,y,lambada): #正则化线性回归函数
theta = np.ones(X.shape[1])
final_theta = opt.minimize(fun=computeRegCost, x0=theta, args=(X, y, lambada), method='TNC', jac=computeRegGradient,options={'disp': True}).x
return final_theta函数:绘制学习曲线:error(J_theta)-m(training set size)
def plot_learning_curve(X_poly,X,y,Xval_poly,yval,lambada): #绘制学习曲线:error(J_theta)-m(training set size)
tr_cost, cv_cost = [], []
m = X_poly.shape[0]
for i in range(1,m+1):
res=reg_linear_regression(X_poly[:i,:],y[:i],lambada)
tr=computeRegCost(res,X_poly[:i,:],y[:i],0) #when you compute cost here,you are computing non-regularized cost
cv=computeRegCost(res,Xval_poly,yval,0) #Regularization is only used to fit parameters
tr_cost.append(tr)
cv_cost.append(cv)
fig,ax=plt.subplots(nrows=2,ncols=1,figsize=(12,12))
#ax[0]:第一个区域
ax[0].plot(np.arange(1,m+1),tr_cost,label="Training Cost")
#plt.plot:先生成了一个figure画布,然后在这个画布上隐式生成一个画图区域画图
#ax.plot:同时生成figure和axes两个对象,用ax对象在其区域内画图
#ax[0]表示figure中的第一个区域
ax[0].plot(np.arange(1,m+1),cv_cost,label="Cross Validation Cost")
ax[0].legend(loc='upper right')
#ax[1]:第二个区域
fitx=np.linspace(-50,50,100)
fitxtmp=data_preprocessing(fitx,power=8)[0]
thetatmp=reg_linear_regression(X_poly,y,lambada).T
fity=fitxtmp@thetatmp
ax[1].plot(fitx,fity,c='r',label="Fitted Curve")
X,y=map(np.ravel,(X,y))
ax[1].scatter(X,y,c='b',label="Initial X and y")
ax[1].set_xlabel("Water Level")
ax[1].set_ylabel("Flow")
plt.show()函数:绘制曲线:error(J_theta)-lambada;观察曲线找到使Jcv(theta)最小的lambada
def find_best_lambada(X_poly,y,Xval_poly,yval): #绘制曲线:error(J_theta)-lambada;观察曲线找到使Jcv(theta)最小的lambada
lambada_candidate=[0,0.001,0.003,0.01,0.03,0.1,0.3,1,3,10]
tr_cost,cv_cost=[],[]
for lambada in lambada_candidate:
res=reg_linear_regression(X_poly,y,lambada)
tr=computeRegCost(res,X_poly,y,0) #when you compute cost here,you are computing non-regularized cost
cv=computeRegCost(res,Xval_poly,yval,0) #Regularization is only used to fit parameters
tr_cost.append(tr)
cv_cost.append(cv)
fig,ax=plt.subplots(figsize=(12,8))
ax.plot(lambada_candidate,tr_cost,label="Training Cost")
ax.plot(lambada_candidate,cv_cost,label="Cross Validation Cost")
plt.legend(loc='upper left')
plt.xlabel("Value of Lambada")
plt.ylabel("Cost")
plt.show()函数:验证模型在test_set上的泛化效果(training_set用来选择theta,cross_validation_set用来选择lambada),进一步选择更合适的lambada
def generalize_on_test_set(X_poly,y,Xtest_poly,ytest): #验证模型在test_set上的泛化效果(training_set用来选择theta,cross_validation_set用来选择lambada),进一步选择更合适的lambada
lambada_candidate=[0.1,0.3,0.6,1,1.2,1.5]
for lambada in lambada_candidate:
theta=reg_linear_regression(X_poly,y,lambada)
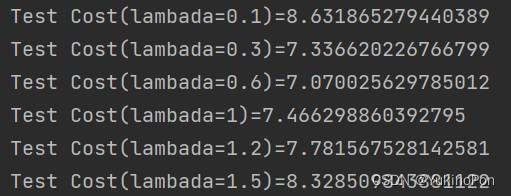
print("Test Cost(lambada={})={}".format(lambada,computeRegCost(theta,Xtest_poly,ytest,0)))主函数:
#Integrate regularized polynomial linear regression,bias/variance,underfitting/overfitting,training set/cross-validation set/test set to get the optimal x:获得最佳的lambada
data=loadmat("ex5data1.mat")
X,Xval,Xtest=map(np.ravel,(data['X'],data['Xval'],data['Xtest']))
y,yval,ytest=data['y'],data['yval'],data['ytest'] #注意y,yval,ytest无需ravel展成一维数组,否则影响结果
X_poly,Xval_poly,Xtest_poly=data_preprocessing(X,Xval,Xtest,power=8)
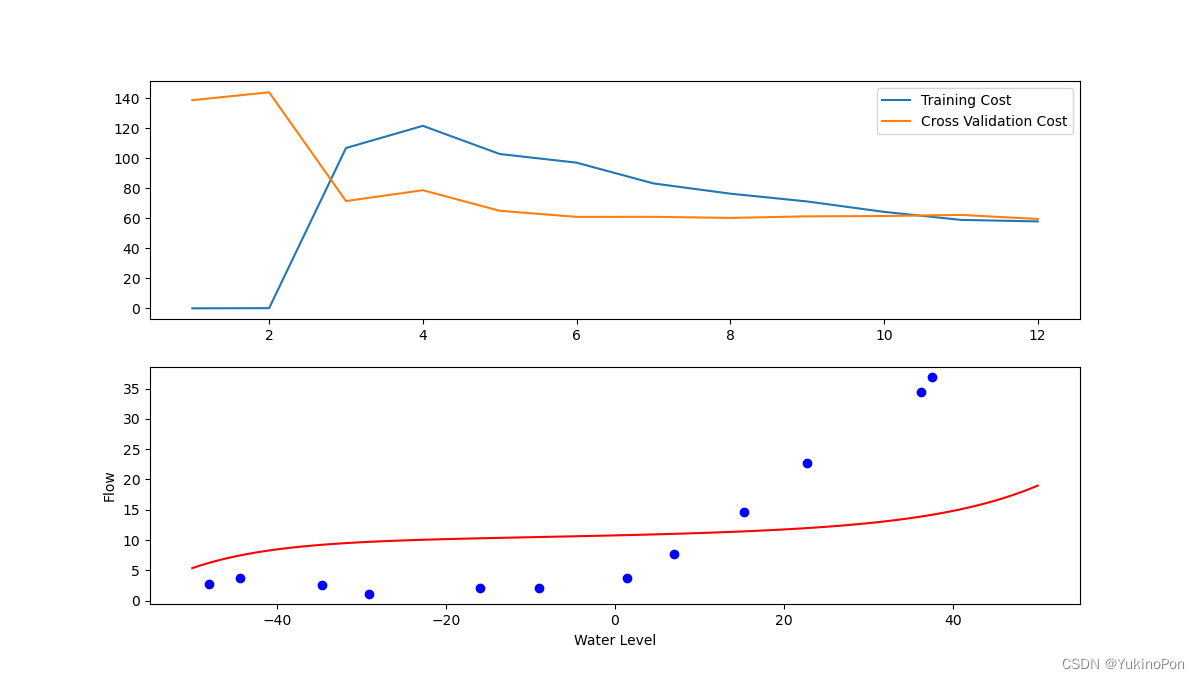
plot_learning_curve(X_poly,X,y,Xval_poly,yval,lambada=1)
find_best_lambada(X_poly,y,Xval_poly,yval)
generalize_on_test_set(X_poly,y,Xtest_poly,ytest)学习曲线(lambada=0无正则化-过拟合)
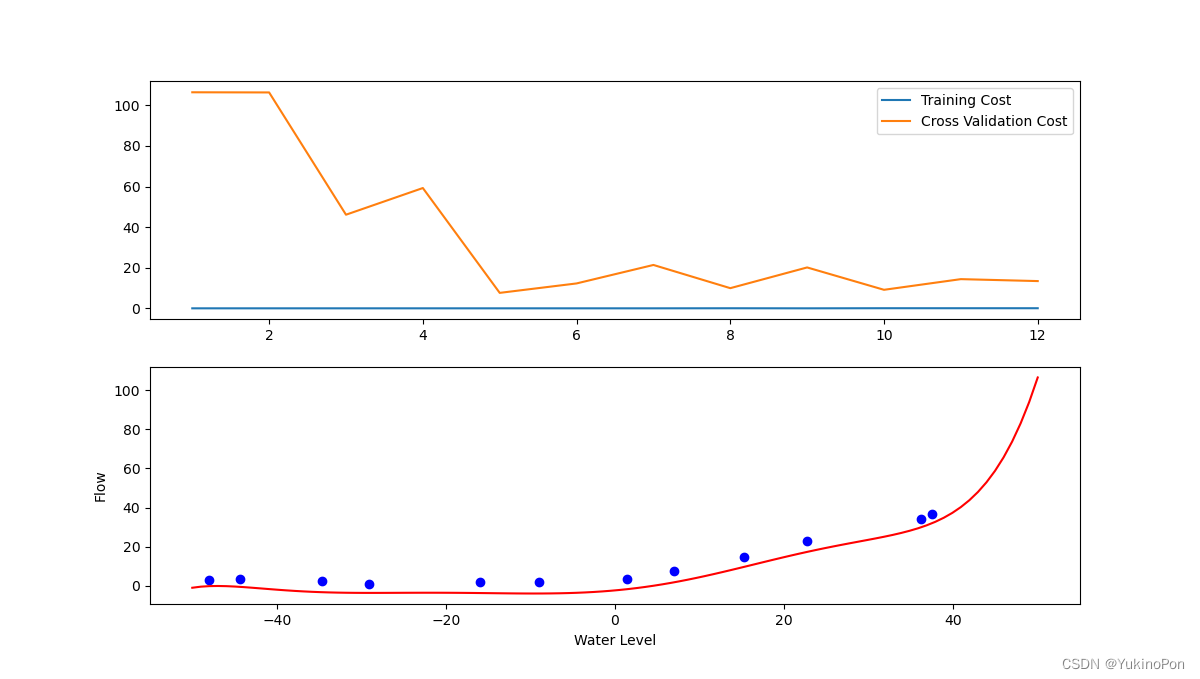
学习曲线(lambada=1-减轻过拟合)
学习曲线(lambada=100-欠拟合)
曲线:error(J_theta)-lambada:当lambada在0.1-1.5时,Jcv(theta)有最小值约为4

测试代价:lambada=0.6是最优选择,此时测试代价最小















 2135
2135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









