







本文基于Andrew_Ng的ML课程作业
1-Anomaly detection:Use Gaussian distribution to detect whether unlabeled examples in simple two-dimensional datasets should be considered anomalies:异常检测:使用高斯模型检测简单二维数据集中未标记的示例是否应被视为异常
导入库
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat函数:计算高斯分布参数miu和sigma
def compute_Gaussian_params(X): #计算高斯分布参数miu和sigma
miu=X.mean(axis=0) #np.mean(data,axis=0/1):axis=0,输出矩阵是1行,对每一列求平均;axis=1,输出矩阵是1列,对每一行求平均
sigma=X.var(axis=0) #np.var():求方差
#miu=X.sum(axis=0)/X.shape[0] #计算均值
#sigma=(((X-miu).T)@(X-miu))/X.shape[0] #计算协方差cov
return miu,sigma函数:计算高斯分布概率p(x)
def Gaussian(X,miu,sigma): #计算高斯分布概率p(x)
p=(1/np.sqrt(2*np.pi*sigma))*np.exp(-(X-miu)**2/2*sigma) #注意这里sigma是方差不是标准差
return np.prod(p,axis=1) #np.prod( ,axis=0/1):返回给定轴上数组元素的乘积;axis=0,输出矩阵是1行,对每一列求乘积;axis=1,输出矩阵是1列,对每一行求乘积函数:使用多元高斯分布模型计算概率p(x) #输出结果中把所有点都圈起来了,还未解决此问题
#def Multivariate_Gaussian(X,miu,sigma): #使用多元高斯分布模型计算概率p(x) #输出结果中把所有点都圈起来了,还未解决此问题
# p=np.zeros((len(X),1)) #(307,1)
# n=len(miu) #2
# if np.ndim(sigma)==1: #np.ndim:返回一个数,表示数组维度(在几维空间中)
# sigma=np.diag(sigma) #sigma(2,2) #np.diag(array):返回以array为对角线元素其余元素均为0的矩阵
# for i in range(len(X)):
# p[i]=(2*np.pi)**(-n/2)*np.linalg.det(sigma)**(-1/2)*np.exp(-0.5*(X[i,:]-miu).T@np.linalg.inv(sigma)@(X[i,:]-miu)) #np.linalg.det():矩阵求行列式 #np.linalg.inv():矩阵求逆
# return p函数:可视化高斯分布的轮廓
def plot_Gaussian_contour(X,miu,sigma): #可视化高斯分布的轮廓
xplot=np.linspace(5,25,100)
yplot=np.linspace(5,25,100)
Xplot,Yplot=np.meshgrid(xplot,yplot) #(100,100)
zplot=np.c_[Xplot.flatten(),Yplot.flatten()] #(10000,2) #np.c_[,]:把两矩阵左右连接;np.r_[,]:把两矩阵上下连接
Zplot=Gaussian(zplot,miu,sigma)
Zplot=Zplot.reshape(Xplot.shape) #(100,100)
levels=[10**h for h in range(-20,0,3)]
plt.contour(Xplot,Yplot,Zplot,levels) #plt.contour(X,Y,Z,levels):X,Y表示坐标位置;Z表示每个坐标对应的高度值;levels传入整数表示想绘制的等高线的条数,传入包含高度值的值递增的一维数组python会画出传入的高度值对应的等高线
plt.scatter(X[:,0],X[:,1])函数:计算F1-score
def computeF1(yval,pval): #计算F1-score
tp,fp,fn,tn=0,0,0,0 #tp:True positive; fp:False positive; fn:False negative; tn:True negative
for i in range(len(yval)):
if yval[i]==pval[i]:
if pval[i]==1:
tp+=1
else:
tn+=1
else:
if pval[i]==1:
fp+=1
else:
fn+=1
precision=tp/(tp+fp) if (tp+fp) else 0 #if (tp+fp) else 0用来检测分母tp+fp是否为0;tp+fp不为0则正常输出;tp+fp为0则输出0
recall=tp/(tp+fn) if (tp+fn) else 0
f1=2*precision*recall/(precision+recall) if (precision+recall) else 0
return f1函数:尝试不同阈值,选择最高F1-score对应的阈值
def select_threshold(yval,pval): #尝试不同阈值,选择最高F1-score对应的阈值
rang=np.linspace(min(pval),max(pval),1000)
highest_f1=0
best_threshold=0
for i in rang:
ypre=(pval<i).astype(float) #ypre=pval<i:ypre即为把pval每个小于i的位置记为False,大于i的位置记为True,再用astype转换类型为浮点数1./0.;这就解释了为什么computeF1函数中有if pval[i]==1的判断,因为pval(概率)代入的实际上是ypre(预测0/1) #np.astype():转换数据类型
f1=computeF1(yval,ypre)
if f1>highest_f1:
highest_f1=f1
best_threshold=i
return highest_f1,best_threshold主函数:
#Anomaly detection:Use Gaussian distribution to detect whether unlabeled examples in simple two-dimensional datasets should be considered anomalies
#异常检测:使用高斯模型检测简单二维数据集中未标记的示例是否应被视为异常
data=loadmat('ex8data1.mat')
X=data['X'] #(307,2)
Xval=data['Xval'] #(307,2)
yval=data['yval'] #(307,1)
miu,sigma=compute_Gaussian_params(X)
print(miu,sigma)
#plot_Gaussian_contour(X,miu,sigma)
pval=Gaussian(Xval,miu,sigma) #计算交叉验证集的高斯分布概率使用的是训练集的miu和sigma
highest_f1,best_threshold=select_threshold(yval,pval)
print(highest_f1,best_threshold)
ptrain=Gaussian(X,miu,sigma)
anomaly_dot=np.where(ptrain<best_threshold)
plot_Gaussian_contour(X,miu,sigma)
plt.scatter(X[anomaly_dot,0],X[anomaly_dot,1],s=80,facecolors='none', edgecolors='r')
plt.show()二维数据集可视化
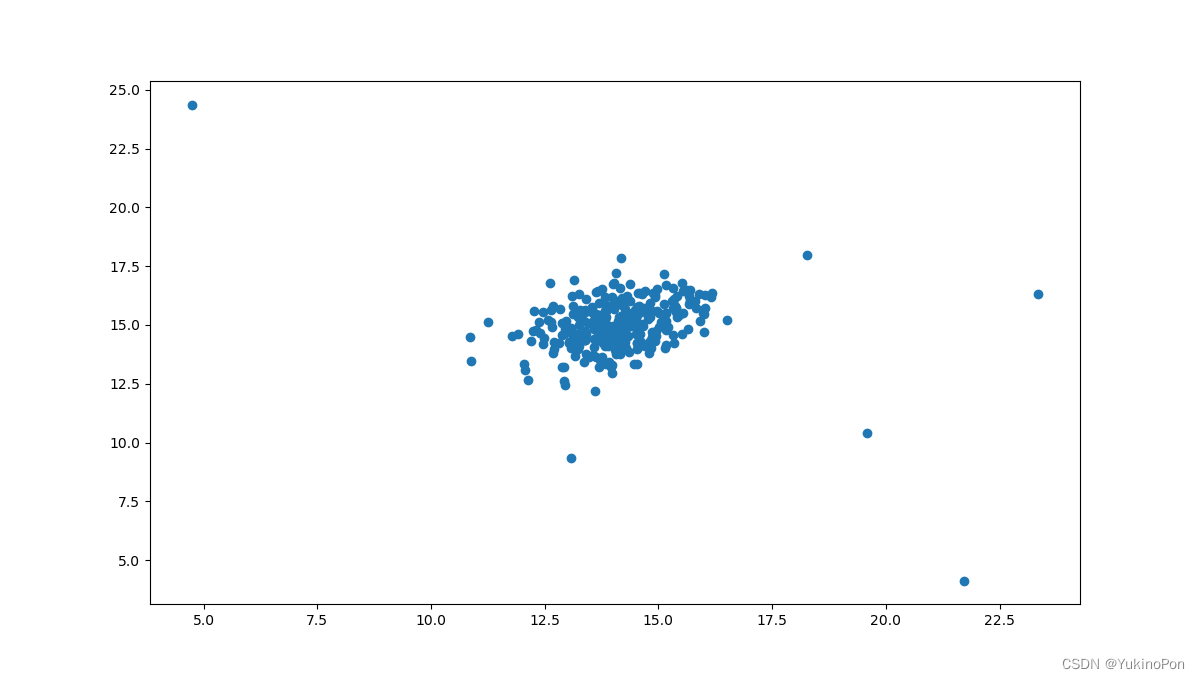
miu,sigma取值
![]()
高斯分布拟合后可视化
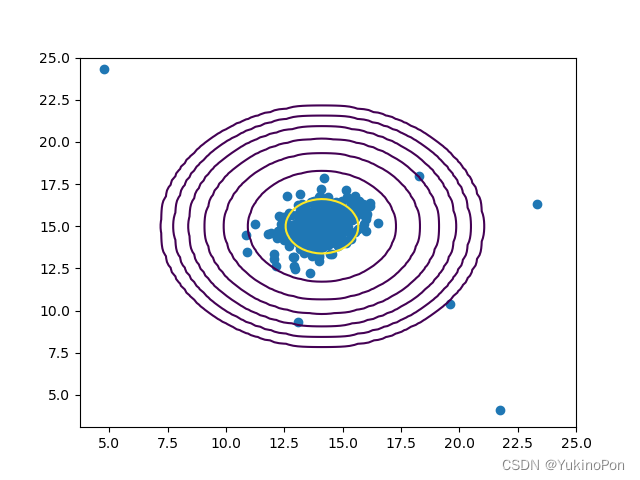
highest_f1,best_threshold
![]()
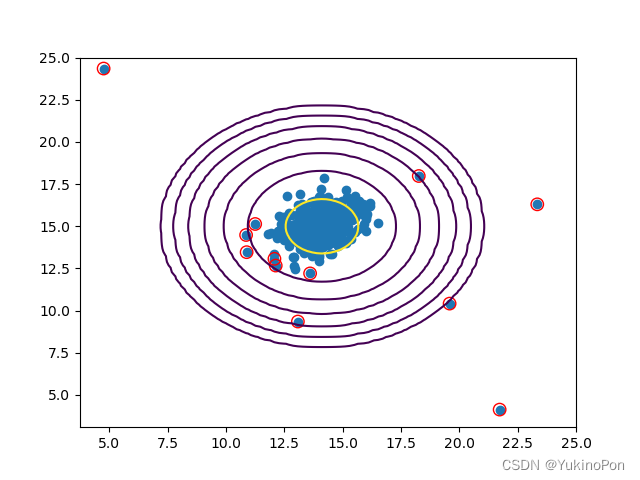
将异常点用红色圈出
2-Collaborative filtering:Implement a recommendation system algorithm and apply it to movie rating dataset:协同过滤:实现称为协同过滤的推荐系统算法并将其应用于电影评分的数据集
导入库
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat函数:将矩阵渲染成图像可视化数据帮助我们了解用户和电影的相对密度
def data_visualize(Y): #将矩阵渲染成图像可视化数据帮助我们了解用户和电影的相对密度
fig,ax=plt.subplots(figsize=(8,6))
ax.imshow(Y) #ax.imshow(X):热图(heatmap)通过色差、亮度来展示数据的差异;X(M,N)表示坐标:数为浮点型,其中值为该坐标的灰度
ax.set_xlabel('Users')
ax.set_ylabel('Movies')
fig.tight_layout() #plt.tight_layout():自动调整子图参数使之填充整个图像区域,避免出现画多幅图时图形部分重叠的问题
plt.show()函数:序列化矩阵X和theta,目的在于稍后可以使用scipy优化包minimize
def serialize(X,theta): #序列化矩阵X和theta,目的在于稍后可以使用scipy优化包minimize
return np.concatenate((X.ravel(),theta.ravel())) #把X,theta都平铺开,再把两个连接在一起函数:逆序列化矩阵X和theta,回到原来样子
def deserialize(param,n_movie,n_user,n_features): #逆序列化矩阵X和theta,回到原来样子
return param[:n_movie*n_features].reshape(n_movie,n_features),param[n_movie*n_features:].reshape(n_user,n_features)函数:计算代价对每一个r(i,j)=1;直觉上,代价是指一组电影评级预测偏离真实预测的程度
def compute_cost(param,Y,R,n_features): #计算代价对每一个r(i,j)=1;直觉上,代价是指一组电影评级预测偏离真实预测的程度
n_movie,n_user=Y.shape
X,theta=deserialize(param,n_movie,n_user,n_features) #X(1682,10),theta(943,10)
inner=np.multiply(X@theta.T-Y,R)
unregularized_term=np.power(inner,2).sum()/2
return unregularized_term函数:计算梯度,序列化后的X_grad和theta_grad,目的在于稍后可以使用scipy优化包minimize
def compute_gradient(param,Y,R,n_features): #计算梯度,序列化后的X_grad和theta_grad,目的在于稍后可以使用scipy优化包minimize
n_movie,n_user=Y.shape
X,theta=deserialize(param,n_movie,n_user,n_features) #X(1682,10),theta(943,10)
inner=np.multiply(X@theta.T-Y,R) #(1682,943)
X_grad=inner@theta #(1682,10)
theta_grad=inner.T@X #(943,10)
return serialize(X_grad,theta_grad)函数:在之前的代价函数中添加正则化项
def compute_regularizedcost(param,Y,R,n_features,lambada): #在之前的代价函数中添加正则化项
reg_term=np.power(param,2).sum()*(lambada/2) #因为X和theta最后还是要加在一起所以可以用sum()
return compute_cost(param,Y,R,n_features)+reg_term函数:在之前的梯度函数中添加正则化项
def compute_regularizedgradient(param,Y,R,n_features,lambada): #在之前的梯度函数中添加正则化项
grad=compute_gradient(param,Y,R,n_features)
reg_term=lambada*param
return grad+reg_term #直接相加就行,grad和reg_term维数相同,对应位置表示的参数也是同一个主函数:
#Collaborative filtering:Implement a recommendation system algorithm and apply it to movie rating dataset:协同过滤:实现称为协同过滤的推荐系统算法并将其应用于电影评分的数据集
data=loadmat('ex8_movies.mat')
Y=data['Y'] #(1682,943):943个用户对1682部电影从1-5星级的评分
R=data['R'] #(1682,943):943个用户对1682部电影是否评分的1/0的数组
aver_y_movie1=Y[1,np.where(R[1,:]==1)].mean() #movie1的平均星级
print(aver_y_movie1)
data_visualize(Y)
params=loadmat('ex8_movieParams.mat')
X=params['X'] #(1682,10) #movie features
theta=params['Theta'] #(943,10) #user preferences
param=serialize(X,theta) #(26250,) #把X和theta所有参数平铺展开的集合
print(compute_cost(param,Y,R,X.shape[1])) #计算初始化数据代价
n_movie,n_user=Y.shape
X_grad,theta_grad=deserialize(compute_gradient(param,Y,R,10),n_movie,n_user,10)
print(X_grad,theta_grad)
lambada=1
print(compute_regularizedcost(param,Y,R,10,lambada))movie1的平均星级
![]()
movies数据集可视化

初始数据总代价
![]()
初始数据梯度

正则化后初始数据总代价
![]()
3-Create your own movie ratings:Use this model to generate personalized movie recommendations:创建自己的电影评分:使用该模型生成个性化的电影推荐
导入库
import numpy as np
from scipy.io import loadmat
from scipy.optimize import minimize
函数:序列化矩阵X和theta,目的在于稍后可以使用scipy优化包minimize
def serialize(X,theta): #序列化矩阵X和theta,目的在于稍后可以使用scipy优化包minimize
return np.concatenate((X.ravel(),theta.ravel()))函数:逆序列化矩阵X和theta,回到原来样子
def deserialize(param,n_movie,n_user,n_features): #逆序列化矩阵X和theta,回到原来样子
return param[:n_movie*n_features].reshape(n_movie,n_features),param[n_movie*n_features:].reshape(n_user,n_features)函数:计算代价对每一个r(i,j)=1;直觉上,代价是指一组电影评级预测偏离真实预测的程度
def compute_cost(param,Y,R,n_features): #计算代价对每一个r(i,j)=1;直觉上,代价是指一组电影评级预测偏离真实预测的程度
n_movie,n_user=Y.shape
X,theta=deserialize(param,n_movie,n_user,n_features)
inner=np.multiply(X@theta.T-Y,R)
unregularized_term=np.power(inner,2).sum()/2
return unregularized_term函数:计算梯度,序列化后的X_grad和theta_grad,目的在于稍后可以使用scipy优化包minimize
def compute_gradient(param,Y,R,n_features): #计算梯度,序列化后的X_grad和theta_grad,目的在于稍后可以使用scipy优化包minimize
n_movie,n_user=Y.shape
X,theta=deserialize(param,n_movie,n_user,n_features)
inner=np.multiply(X@theta.T-Y,R)
X_grad=inner@theta
theta_grad=inner.T@X
return serialize(X_grad,theta_grad)函数:在之前的代价函数中添加正则化项
def compute_regularizedcost(param,Y,R,n_features,lambada): #在之前的代价函数中添加正则化项
reg_term=np.power(param,2).sum()*(lambada/2)
return compute_cost(param,Y,R,n_features)+reg_term函数:在之前的梯度函数中添加正则化项
def compute_regularizedgradient(param,Y,R,n_features,lambada): #在之前的梯度函数中添加正则化项
grad=compute_gradient(param,Y,R,n_features)
reg_term=lambada*param
return grad+reg_term主函数:
#Create your own movie ratings:Use this model to generate personalized movie recommendations:创建自己的电影评分:使用该模型生成个性化的电影推荐
data=loadmat('ex8_movies.mat')
Y=data['Y']
R=data['R']
f=open('movie_ids.txt',encoding='gbk')
#把文件里的内容先转换为列表最后放到数组里
movie_list=[]
for line in f:
tokens=line.strip().split(' ') #strip()用于移除字符串头尾指定字符(默认空格/换行符,)这里删掉数据中的换行符,split(' ')表示数据中遇到' '就隔开
movie_list.append(' '.join(tokens[1:])) #'sep'.join(seq):以sep为分隔符,将seq所有元素合并成一个新的字符串
movie_list=np.array(movie_list) #将列表转换为数组
#把我们自己的评分添加到数据集中
ratings=np.zeros((1682,1))
ratings[0]=4
ratings[6]=3
ratings[11]=5
ratings[53]=4
ratings[63]=5
ratings[65]=3
ratings[68]=5
ratings[97]=2
ratings[182]=4
ratings[225]=5
Y_plusme=np.append(ratings,Y,axis=1) #(1682,944) #np.append(arr,values,axis=None):为arr添加values,axis=1表示增加列数的添加
R_plusme=np.append(ratings!=0,R,axis=1) #(1682,944) #ratings!=0是一个True/False判断,返回的是把ratings相应元素用True/False替换后的结果
n_movies,n_users=Y_plusme.shape
n_features=10
lambada=10
X=np.random.random(size=(n_movies,n_features)) #(1682,10)
theta=np.random.random(size=(n_users,n_features)) #(944,10)
param=serialize(X,theta) #(26260,10)
#Mean Normalization
miu=(Y_plusme.sum(axis=1)/R_plusme.sum(axis=1)).reshape(1682,1) #(1682,1) #np.sum(axis=1):每一行元素相加,行数不变
Y_norm=(Y_plusme-miu)*R_plusme #(1682,944)和(1682,1)可以作相减操作,相当于Y每一行每一个数减去同一个数
#使用minimize函数训练模型
fmin=minimize(fun=compute_regularizedcost,x0=param,args=(Y_norm,R_plusme,n_features,lambada),method='TNC',jac=compute_regularizedgradient)
X_trained,theta_trained=deserialize(fmin.x,n_movies,n_users,n_features) #(1682,10),(944,10)
#使用训练出的X和theta给出推荐电影
prediction=X_trained@theta_trained.T #(1682,944)
my_pred=prediction[:,0]+miu.flatten() #(1682,)
idx=np.argsort(my_pred)[::-1] #(1682,)
#np.argsort():将x中的元素从小到大排列,返回其对应的index(索引)
# #a[::-1]相当于a[-1:-len(a)-1:-1],从最后一个元素到第一个元素进行操作,这里相当于把np.argsort的返回反向输出即从大到小的索引;另:[:-1]:读取倒数第一个元素
for i in range(15):
print("Top recommendations for you:")
print('Predicting rating %0.1f for movie %s.' %(my_pred[idx[i]],movie_list[idx[i]]))使用minimize函数训练好后的结果

对于我前15排名的电影推荐
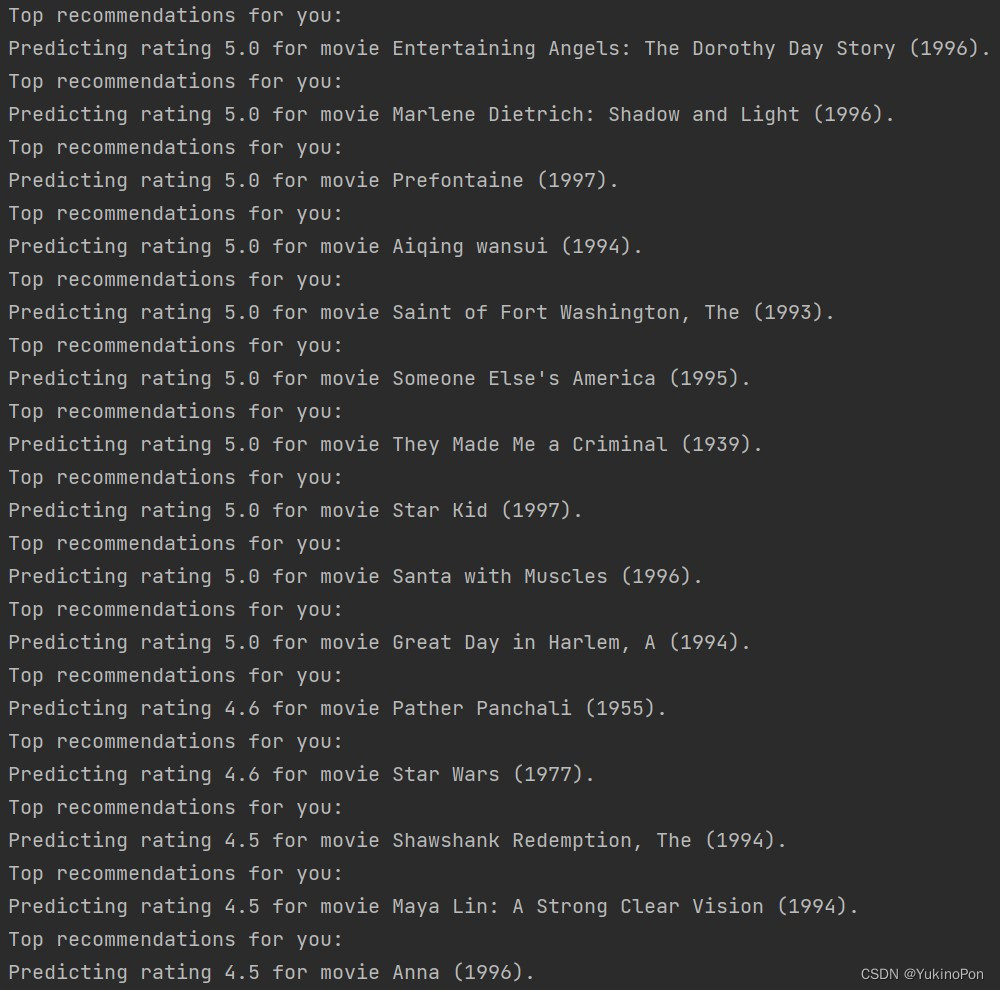















 3714
3714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









