






解决思路
定义问题——>数据收集——>数据清洗——>分析——>建模——>验证——>优化
该问题下前两步已经完成,本文从数据清洗开始
数据集的特征解读
| 英 | 中 | 分析 |
|---|---|---|
| PassengeID | 乘客ID | 乘客ID不影响Survive与否,但可标识身份 |
| Pclass | 船舱等级 | 高等船舱靠近甲板,更容易Survive |
| Name | 姓名 | 标记 |
| Sex | 性别 | 男女生理差别,对Survive有影响 |
| Age | 年龄 | 同上 |
| SibSp | 兄弟配偶数 | 有无同行兄弟or配偶,同行会影响决策 |
| Parch | 父母孩子数 | 有无同行父母or孩子,从而影响Survive |
| Ticket | 船票信息 | / |
| Fare | 票价 | 票价跟Pclass也是正相关 |
| Cabin | 船舱信息 | / |
| Embarked | 港口 | / |
| Survived | 存活与否 | / |
以上信息中
- 有些特征对分析没什么意义,建模时可以不扔进算法
- 有些特征之间互相有关联,可以多特征线性合并
- 部分数据需要清洗
- Train集中的Survived变量要放入模型训练
- Test集中的Survived变量作为验证标准
库和数据导入,简单分析
import pandas as pd
import numpy as np
import time
import sklearn
from sklearn import ensemble#集成学习,包括了随机森林,SVM等集成学习算法
from sklearn import feature_selection#特征值选择,分类回归都需要的特征值如F和P
from sklearn import model_selection#模型选择,包括了交叉验证,网格搜索等
from sklearn import metrics#包括了多个计算模型评估的算法
from sklearn.preprocessing import LabelEncoder#将Label标准化,如:字符串——>数字,以便代入模型
##绘图
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns#一个封装好的matplotlib,底层是matplotlib,使用更方便
#mpl.style_use("ggplot")#设置matplotlib的绘图风格,可有可无
data_train = pd.read_csv("train.csv")
data_test = pd.read_csv("test.csv")
#显示数据集信息
print(data_train.info())
print(data_test.head(10))
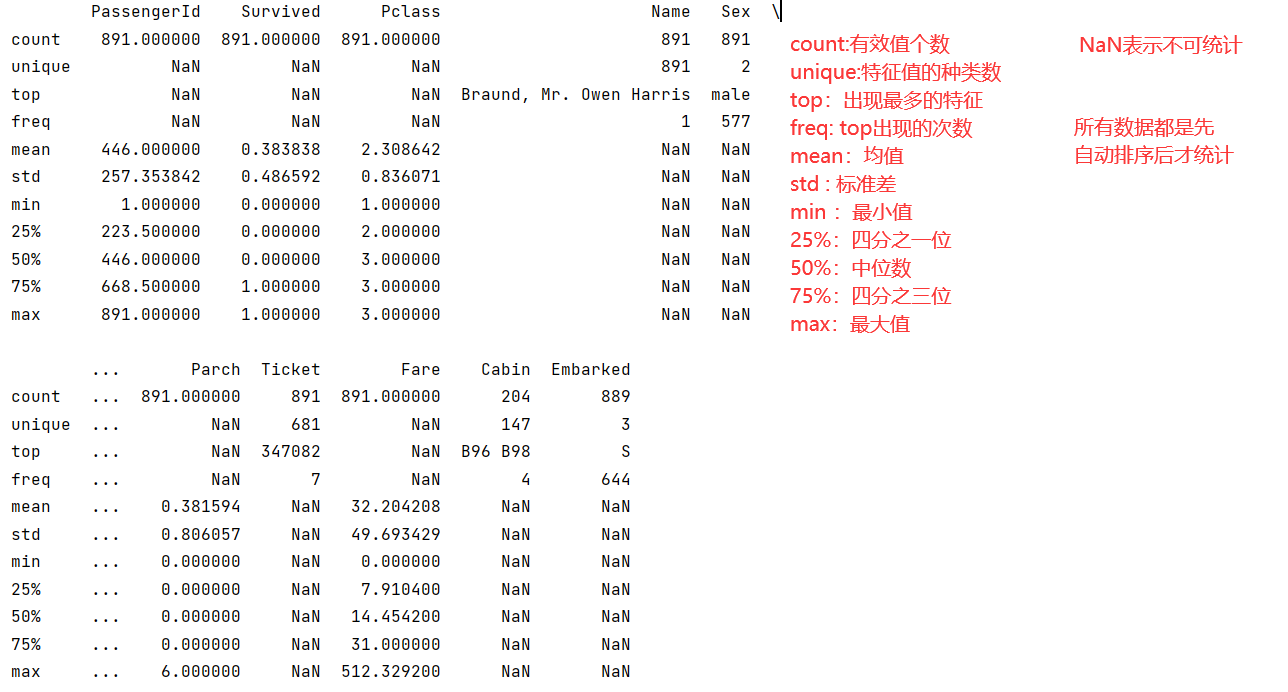
完整显示数据集统计信息(完整描述)set_option
pd.set_option('display.max_columns',11)
#train集中有11列属性,设置最大列数为11
print(data_train.describe())
- 同样的,pd.set_option(‘display.max_columns’,10)也可以让原本显示不全的head()显示全
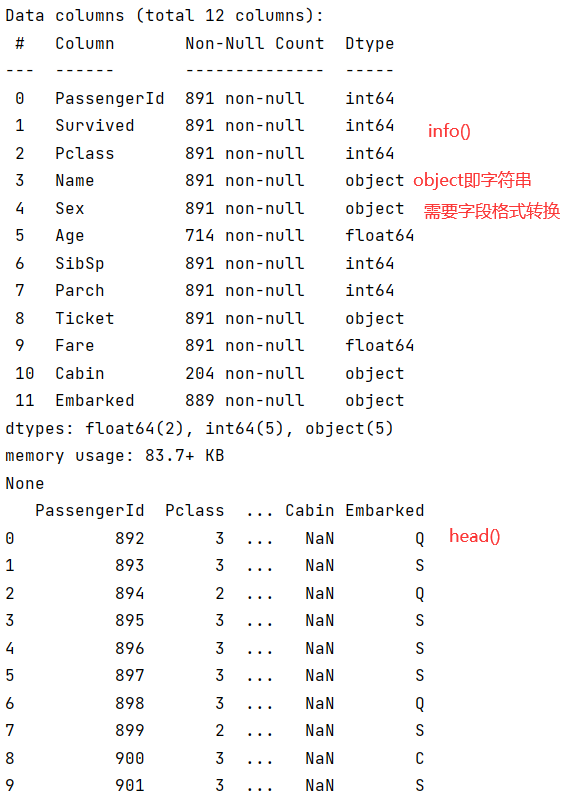
count:有效值个数(非空值)
unique:特征值的种类数
top:出现最多的特征
freq: top出现的次数
mean:均值
std : 标准差
min :最小值
25%:四分之一位
50%:中位数
75%:四分之三位
max:最大值
- 一共有891行数据,但Age、Cabin属性明显缺失,此案例下的缺失值暂时用中位数代替
数据清洗
数据清洗是数据分析中耗时最长最麻烦的阶段
准备工作
#列名小写,方便后续
data_test.columns = data_test.columns.str.lower()
data_train.columns = data_train.columns.str.lower()
data_train.info()#查看属性小写后的info
#合并Train和Test以便统一数据清洗
data_sum = [data_train , data_test]
#但由于这个sum是一个list,会缺少很多原本train和test能用的属性or方法,如columns
#注意:此处的合并不是直接合并数据集,而是创建一个list,实现一键操作
#一定是先分别lower再合并成sum
要想调用方法,需要使用for循环
查看survived的统计直方图
#查看属性统计量seaborn下的countplot,绘制图像
sns.countplot(x = data_train['survived'] )
#sns.coutplot(x = "survived" , data = data_train)
#两种表达方式
plt.show()#olt.show()是生成图的操作,必不可少
补全缺失值fillna
#分别查看train和test集中为null值的汇总
print(data_train.isnull().sum())
print('\n')
print(data_test.isnull().sum())
- age embarked的缺失值占比比较少,可以替换值
- cabin的缺失值占比很高,建模时直接把cabin属性全扔掉
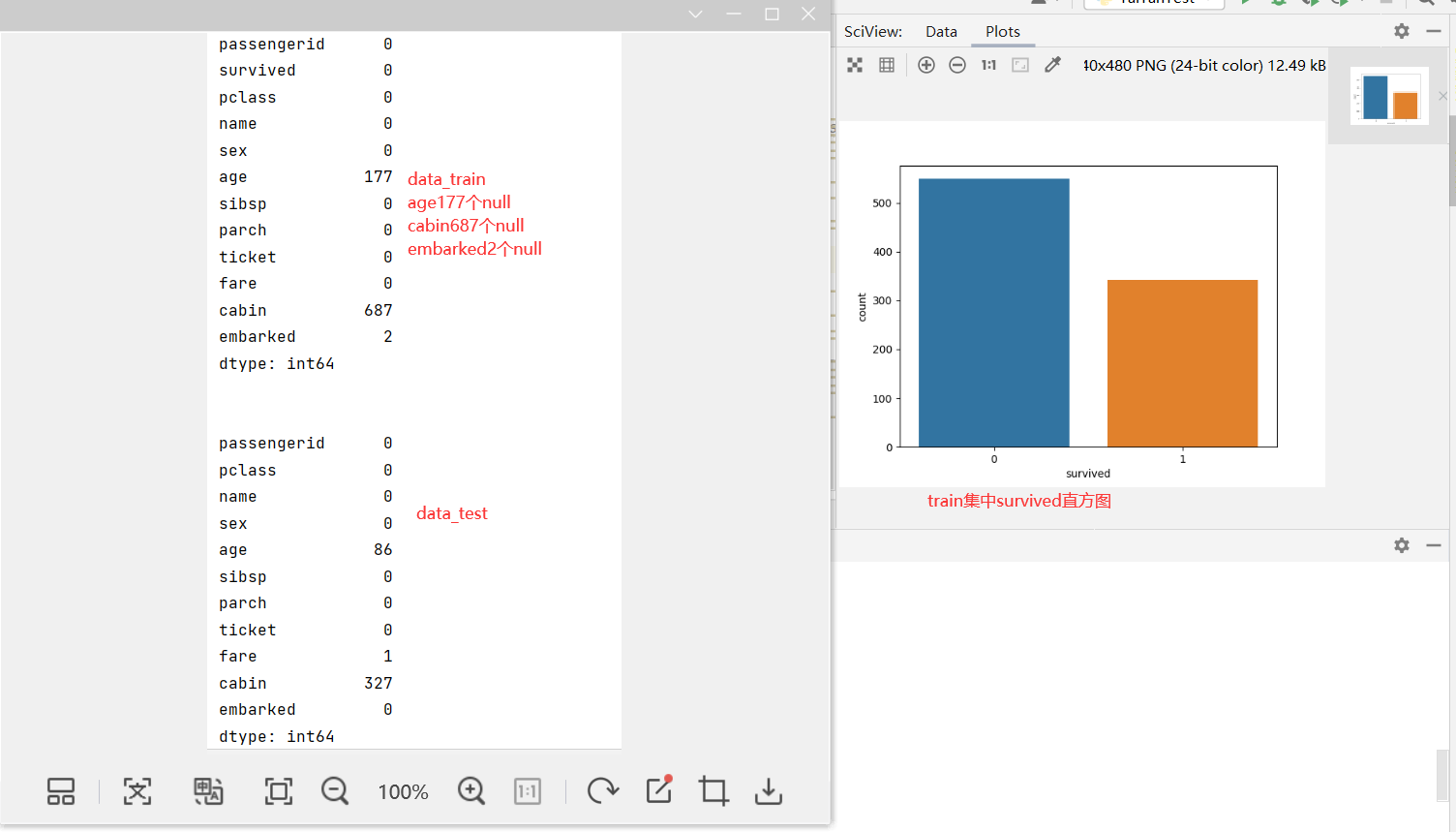
利用for循环对样本集一键纠正
for dataset in data_sum:
dataset['age'].fillna(dataset['age'].median() , inplace=True)
dataset['fare'].fillna(dataset['fare'].median() , inplace=True)
###因为age、fare都是数字类型,因此可以调用median中位数
###而像属性值位字符串的特征则不能调用median
dataset['embarked'].fillna(dataset['embarked'].mode()[0] , inplace=True)
#mode返回的是 众数,因为即便是字符串,也可以调用
- 注意:mode和median的用法场景区别
- 注意fillna的使用格式
- inplace=True表示更改原数据集,而不是返回一个新的数据集
- mode是pandas下的一个方法,返回按索引号排序的众数,mode()[索引号]的索引号很重要,如果省略则不填充
删除无用字段(特征)drop
drop_columns = ['cabin','passengerid','ticket']#创建一个list
#分析认为:cabin缺失值太多,需要删除
#passengerid无关survive,删除
#ticket都是编号,删除
data_train.drop(drop_columns,axis=1,inplace=True)
data_test.drop(drop_columns,axis=1,inplace=True)
#drop参数的意义(行or列 , axis=0删行 axis=1删列 , inplace=True直接更改调用者数据集本身)
- 注意:drop的参数含义
- 可以构建for循环 + drop_columns一次操作
纠正异常值
利用for循环的样本集一键纠正
因为这个案例中信息来源准确,可以认为没有异常值,故在此案例中不做处理
构建新特征
- 连续值用cut或者qcut来划分
- 离散值直接划分,合并数量少的值
同行规模
#同行规模 = 配偶 + 兄弟姐妹 + 1(自己)
dataset['together_size'] = dataset['sibsp'] + dataset['parch'] + 1
是否单身
#是否单身:单身可以不顾别人,会影响survive
dataset['isSingle'] = 0
dataset['isSingle'].loc[dataset['together_size'] > 1] = 1
票价分段:cut
#票价分段fare_bin:票价的离散值太多,应该划分为几个集
#数据集中票价0~512,并且绝大多数都是便宜票,所以用cut等宽划分
dataset['fare_bin'] = pd.cut(dataset['fare'] , 4)
年龄分段:qcut
#年龄分段age_bin
dataset['age_bin'] = pd.qcut(dataset['age'] , 4)
身份分类:合少为1
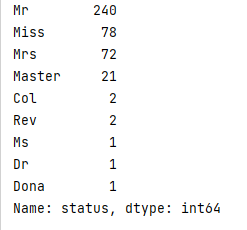
#身份 status:因为英国人的名字会加入跟身份有关的职业,身份也会影响获救概率
dataset['status'] = dataset['name'].str.split(', ' , expand = True)[1].str.split('.' , expand = True)[0]
###参数含义:str是返回字符串,expand要为True值
###按引号中的符号进行split拆分,[0]表示取前半段,[1]表示取后半段
print(dataset['status'].value_counts())#查看统计
#把少的分为一类other
othersSum = dataset['status'].value_counts() < 10
#other对象 = 小于10的
dataset['status'] = dataset['status'].apply(lambda x : 'ohter' if othersSum[x] else x)
#更新后的status属性 = 之前的status.aooly(lambda x : '新的名字' if other对象[x] else x)
print(dataset['status'].value_counts())
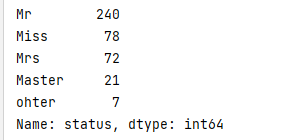
新特征分析:评估新特征划分的好坏
以不同的特征分类计算各属性值的均值,以标签survived的均值为参考,不同特征值的标签均值差别越大越好
#简单分析上述构建特征是否有效:groupby根据属性值分组
print(data_train['survived'].groupby(data_train['status']).mean())
#查看按这样构建的特征status的不同值survived对应的均值
print(data_train['survived'].groupby(data_train['age_bin']).mean())
print(data_train['survived'].groupby(data_train['fare_bin']).mean())
print(data_train['survived'].groupby(data_train['isSingle']).mean())
print(data_train['survived'].groupby(data_train['together_size']).mean())
 于是对age_bin进行修改,最终尝试结果是qcut改cut,区分度提升最明显
于是对age_bin进行修改,最终尝试结果是qcut改cut,区分度提升最明显
格式替换,构建新字段,
1,基于scikit-learn中的LabelEncoder()
把属性值为字符串的特征转化为“特征_code”,字符串——>数字,以便放入模型中跑
机器学习模型只能处理int和float的数据
#实例化
label = LabelEncoder()
#字符串——>数字
for dataset in data_sum:
# (1)新字段:sex_code
dataset['sex_code'] = label.fit_transform(dataset['sex'])
# (2)新字段:embarked_code
dataset['embarked_code'] = label.fit_transform(dataset['embarked'])
# (3)新字段:status_code
dataset['status_code'] = label.fit_transform(dataset['status'])
# (4)新字段:age_bin_code
dataset['age_bin_code'] = label.fit_transform(dataset['age_bin'])
# (5)新字段:fare_bin_code
dataset['fare_bin_code'] = label.fit_transform(dataset['fare_bin'])
print(data_train.columns.to_list)


2,通过Pandas中的get_dummies() 进行编码
建模
标签、特征选择
标签选择
target = ['survived']
特征选择
data_feature_one = ['sex', 'pclass', 'embarked', 'status', 'sibsp', 'parch', 'age', 'fare', 'together_size',
'isSingle']
通过Pandas中的get_dummies() 进行编码
这是一个暴力转码(字符串——>数字代号)的方法,十分简单,且更好用
data_one_dummy = pd.get_dummies(data_train[data_feature_one])
#把data_feature_one中需要转码的如:status、embarked转为数字代号
data_one_dummy_list = data_one_dummy.columns.tolist()
#转list,以便放入网格搜索的形参中去跑
把train集拆分为训练集和测试
X_train_one, X_test_one, y_train_one, y_test_one = model_selection.train_test_split(data_one_dummy[data_one_dummy_list],#转码后的list格式的train[feature]
data_train[target],#标签
random_state = 0)#随机种子
print(X_train_one.shape)
print(X_test_one.shape)
#shape查看分割的大小,也可以通过size参数自己设置分割比例,数据量很大时通常使用2 8分,train_size=0.8
print(y_train_one.shape)
print(y_test_one.shape)
#大X表示:特征 小y表示:标签

网格搜索:寻找最优
准备
from sklearn.model_selection import GridSearchCV #网格搜索
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
rfc = RandomForestClassifier(max_features='auto' , random_state= 0 , n_jobs=-1 )
#实例化一个RandomForestClassifier对象
#简单选取所有特征 , 随机种子=0 , 利用所有线程
#这里实例化RandomForestClassifier时可以不用写入太多参数,参数可以放进网格里面自己跑出最优的
搜索
param_gird = {#需要最优化的参数对象
'criterion' : ['gini', 'entropy'],#标准选择
'min_samples_leaf' : [ 1,3,5, 10],#最小子叶数
'min_samples_split' : [10, 12, 16,20,24],#最小样本数
'n_estimators' : [20,35,50,100]#决策树的个数选择
}
gscv = GridSearchCV(#网格搜索交叉验证对象
estimator=rfc,#rf带入网格算
param_grid=param_gird,#需要最优化的参数带入
scoring= 'accuracy', #得分评判————准确度
cv=3,#交叉验证次数
n_jobs=-1)#-1 利用CPU所有线程
gs = gscv.fit(X_train_one , y_train_one.values.ravel())#自动训练,两个参数都是train集
#.values.ravel()是为了防止warning
#自动训练的所有结果返回在gs中,这个
print(gs.best_score_)#最高分数
print(gs.best_params_)#最佳组合

网格搜索调参
- 如果某特征的最优值是在罗列的数的中间,那么认为比较优秀
- 如果在边上,就需要往那个方向调参重新跑
- 同时有多个参数需要调时,先调差距最大的
- 即使是位于中间的参数也可以细分调整
- 类似高中生物实验探究题《寻找最佳浓度》的思想
用最优参数训练随机森林
#实例化RandomForestClassifier对象
rfc2 = RandomForestClassifier(criterion='entropy',
min_samples_leaf=5,
min_samples_split=16,
n_estimators=35,
n_jobs=-1,
random_state=1)
#训练
rfc2.fit(X_train_one, y_train_one.values.ravel())
此时训练完成,等待后续用split分割出来的测试集test来测试
根据特征的重要性排序
print(pd.concat((pd.DataFrame(X_train_one.iloc[:, 1:].columns, columns=['Variable']),
pd.DataFrame(rfc2.feature_importances_, columns=['importance'])),
axis=1).sort_values(by='importance', ascending=False))
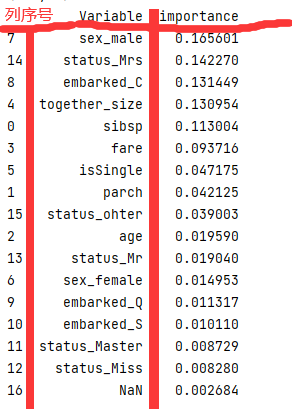
- 重要性:重要性是特征在模型中的决定能力,而不是越高就代表标签越接近1
在test上预测:是split分割出来的test
predict_test = rfc2.predict(X_test_one)#test集中的特征数据X
pred_df = pd.DataFrame(predict_test, columns=['survived'])#预测结果表
print(pred_df)#test集的验证结果
print('随机森林 AUC...')
fpr_test, tpr_test, th_test = metrics.roc_curve(predict_test, y_test_one)
# 构造 roc 曲线
print('AUC = %.4f' %metrics.auc(fpr_test, tpr_test))#参考意义最大的就是AUC
print('随机森林精确度...')
print(metrics.classification_report(predict_test, y_test_one))#精准度表格

验证:不是split分割出来的test,而是test.csv
data_val_dummy = pd.get_dummies(data_test[data_feature_one])#转码
data_val_dummy_list = data_val_dummy.columns.tolist()
print(data_val_dummy_list)#查看转码后的列名,拿着这些列名预测
pred_val = rfc2.predict(data_val_dummy[[#根据上一条语句的结果,copy了列名
'pclass', 'sibsp', 'parch', 'age',
'fare', 'together_size', 'isSingle',
'sex_female', 'sex_male', 'embarked_C',
'embarked_Q', 'embarked_S', 'status_Master',
'status_Miss', 'status_Mr', 'status_Mrs',
'status_ohter']])
pred_val_df = pd.DataFrame(pred_val, columns=['survived'])
print(pred_val_df.head(10))#展示前10个数据
















 929
929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









