






WaveSpeed 简介
WaveSpeed 是一款致力于ComfyUI 的一体化推理优化解决方案,通用、灵活、快速的插件;目前功能还在完善中,不过仅目前发布的功能对 Flux 、LTXV 、HunyuanVideo 等模型的加速还是很明显的。
下面我们使用 WaveSpeed 对Flux进行加速测试。
官方地址:
https://github.com/chengzeyi/Comfy-WaveSpeed
主要的加速节点分两个 :
- Dynamic Caching (First Block Cache)
受 TeaCache 和其他去噪缓存算法的启发,我们引入了第一个块缓存 (FBCache),以第一个 transformer 块的残差输出作为缓存指示符。如果第一个 transformer 模块的电流和前一个 transformer 模块的剩余输出之间的差异足够小,我们可以重用前一个最终的残余输出,并跳过所有后续 transformer 模块的计算。这可以显著降低模型的计算成本,在保持高精度的同时实现高达 2 倍的加速。
要使用第一个数据块缓存,只需在 Load Diffusion Model 节点之后将 wavespeed->Apply First Block Cache 节点添加到工作流中,并将 residual_diff_threashold 值调整为适合模型的值,例如:0.12 表示具有 fp8_e4m3fn_fast 和 28 步的 flux-dev.safetensors。预计速度将提高 1.5 到 3.0 倍,而精度损失可接受。
-
Enhanced torch.compile
要使用增强的 torch.compile,只需在 Load Diffusion Model 节点或 Apply First Block Cache 节点之后将 wavespeed->Compile Model+ 节点添加到您的工作流程中。编译过程在您第一次运行工作流程时发生,这需要相当长的时间,但会缓存以供将来运行。您可以传递不同的模式值以使其运行得更快,例如 max-autotune 或 max-autotune-no-cudagraphs。与原始 TorchCompileModel 节点相比,此节点的优势之一是它与 LoRA 一起使用。
注意:使用 FP8 量化编译模型在 RTX 3090 等 Ada 之前的 GPU 上不起作用,您 应该尝试使用 FP16/BF16 模型或删除编译节点。
在官方建议使用 torch.compile 时还需要在启动时设置
comfy launch -- --gpu-only
但是参照设置后运行会产生显存溢出的错误(16G)所以在下面的测试中没有添加此参数进行 Comfyui 启动;如果有添加该参数测试成功的小伙伴可以分享一下
安装
- 通过 Comfyui-Manager 安装
- 通过 git 手动安装;启动命令行,进入custom_nodes目录,执行 git clone 命令
git clone https://github.com/chengzeyi/Comfy-WaveSpeed.git

工作流实战
具体工作流如下图所示
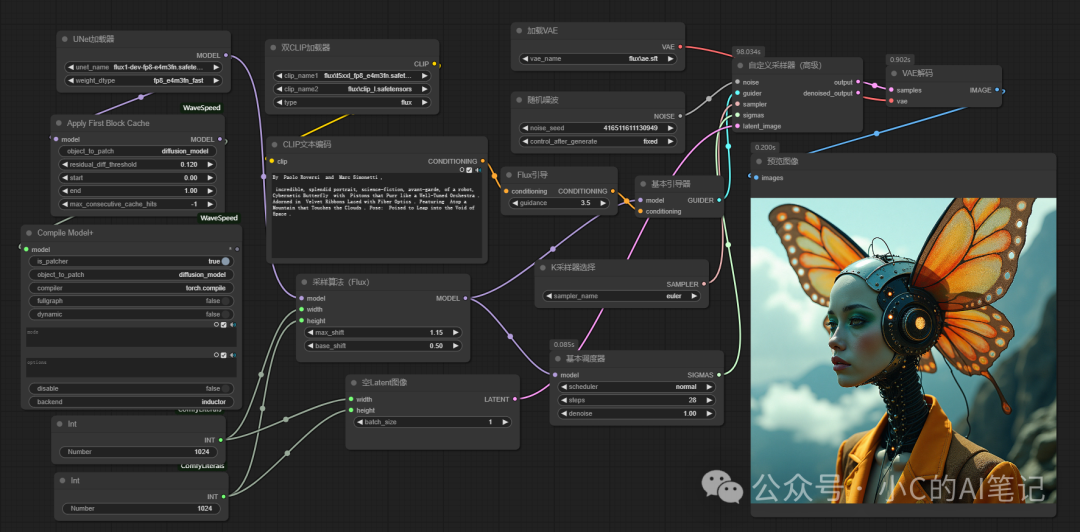
主要节点解析
1. Apply First Block Cache
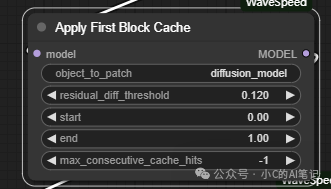
重要参数为 :
residual_diff_threashold
以下是该参数使用最佳配置;对应的模型配置不一样,使用以下配置可以在加速的同时达到最小精度损失

- 对于 Flux 模型最佳配置为
0.12 ,采样步数为28步
2. Compile Model+
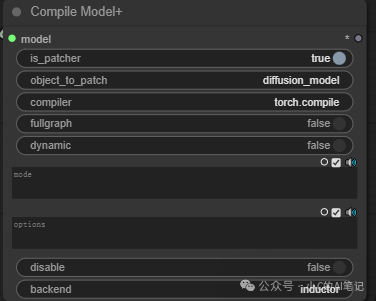
该节点无需多余更改保持默认即可
效果对比
- 不使用任何加速,28步采样
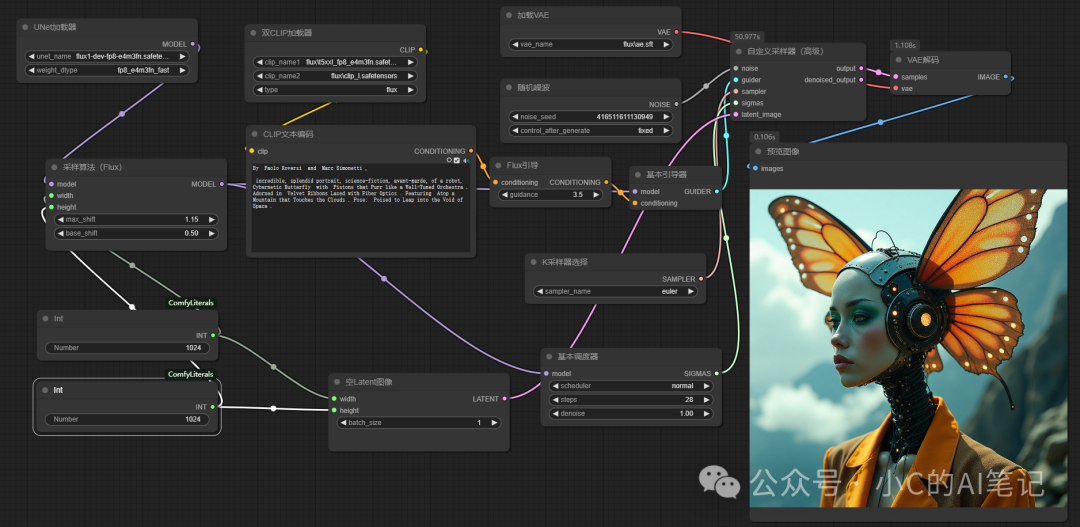
耗时 :104 s
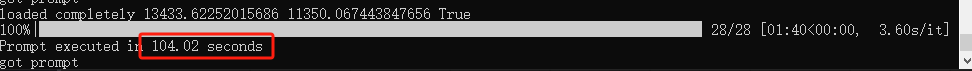
- 使用 Dynamic Caching (First Block Cache) 加速
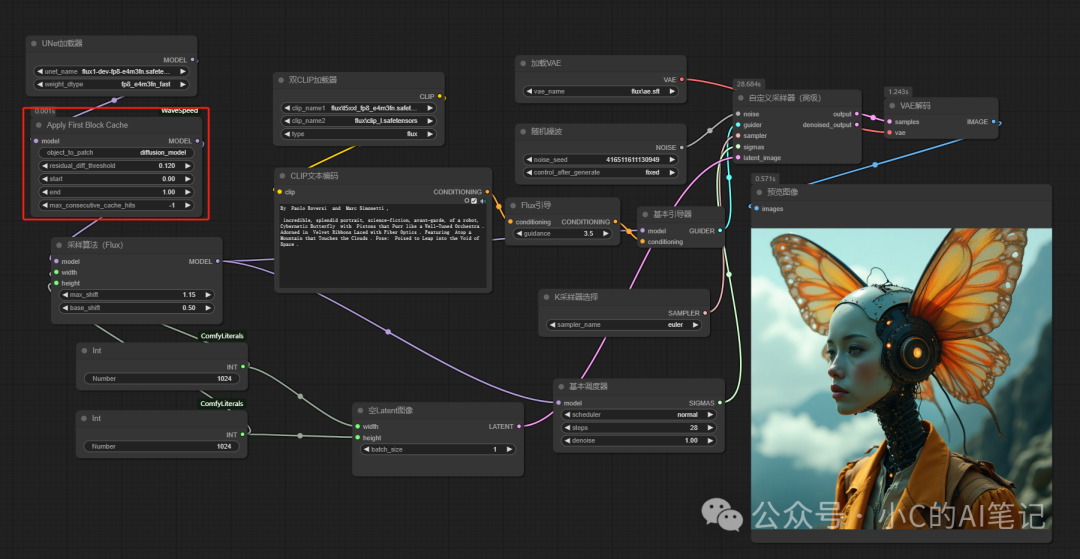
耗时:

- 使用 Dynamic Caching (First Block Cache) + (Compile Model+)
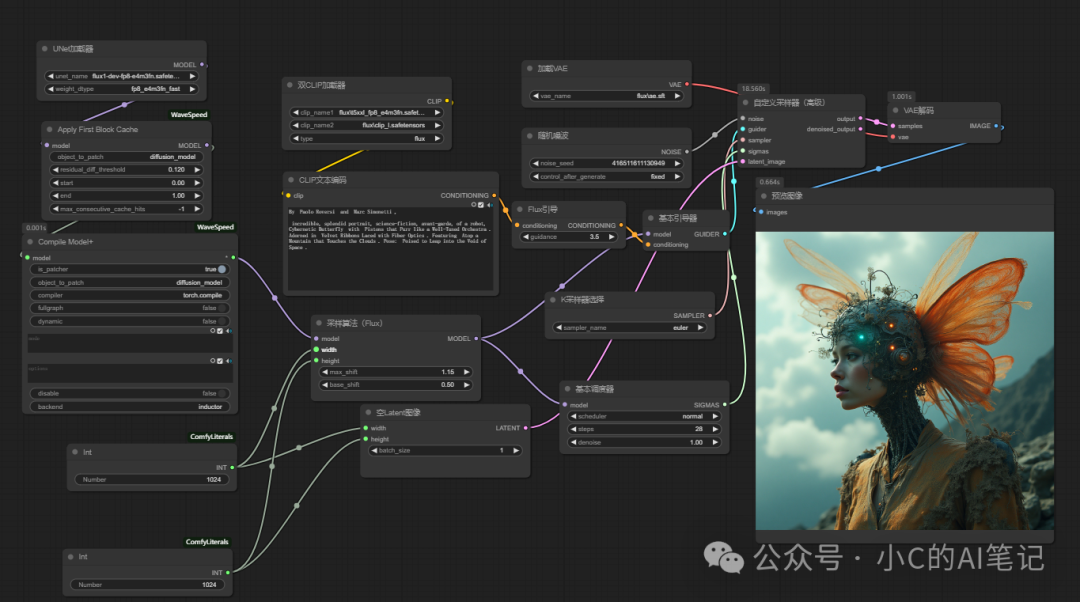
耗时: 19.76s

在本次测试中,速度由104s 提速至了 19.76s 加速 5 倍左右;所以这个插件对于 Flux 提速还是相当明显的。
**图片质量对比**



从上到下分别为原始生成,使用Dynamic Caching (First Block Cache) 加速,使用 Dynamic Caching (First Block Cache) + (Compile Model+) 加速生成;可以看到,最后一张与之前两张的差异还是有的,但是差异主要在物体的形态上,但是质量上基本上还是很不错的。我们可以进行继续抽卡得到我们想要的图片。
以上就是使用 wavespeed 加速 Flux 生图的全部流程了,本次的工作流已上传分享,需要的小伙伴自取,喜欢的小伙伴可以点个收藏+关注哦。
工作流分享看下图:

关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 2714
2714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









