






博文介绍:记录在 University of Southampton 的 “Data Mining & Analystics” 硕士课程的学习内容,为自己的复习提供笔记资料,并且希望对刚接触数据挖掘与数据分析的小伙伴提供帮助。(在本博文中会出现较多英语,但都会有解释说明,无需担心。添加英语的目的并不是为了显得高大上,是因为原语言往往更容易能让读者理解原句的意思,翻译难免会添加上我个人想法。)
一、SQL
Introduction
介绍
SQL 是进行数据挖掘的第一步,也是最关键的技能之一。因此,让我们回顾一下 SQL,使我们在这项技术上变得更加精湛,从而为我们的数据挖掘的学习打下基础。
练习以图书馆为例。该数据库的目的是跟踪一个小型借阅图书馆的图书供应情况,以及谁目前借阅了这些图书。图书馆希望能联系到有过期书籍的客户,客户也希望能搜索不同主题的书籍。如果您在个人信息中提出要求,可以下载 library.dbd 数据库。我们还将考虑 fruitandveg.db 中的示例,该数据库描述了水果和蔬菜通过仓库在供应商和客户之间流动的交易情况。
The SQL is one of the most crucial skills and first step when carrying out Data Mining. So let's review SQL making you more exquisite.
The exercises are based on the library example. The purpose of this database is to keep track of the availability of books in a small lending library and who currently has these books on loan. The library would like to be able to contact customers who have overdue books and customers would like to be able to search for books on different subjects. The library.dbdatabase is available for download if you ask in personal message. We will also consider examples from fruitandveg.db, a database describing transactions the movement of fruit and vegetables between suppliers and customers via a warehouse.
The SELECT Statement
1.WHERE:指定搜索条件
2.GROUP BY:计算一列中数据的聚合函数,按第二列的数据分组列
3.HAVING:过滤受条件限制显示的组
4.排序方式:对要显示的数据进行排序。
每个条款都是可选的,但顺序必须保持不变。

Where
WHERE语句确保只显示满足指定条件的数据。按顺序要输出表格的所有列,使用∗作为速记(i.e. SELECT ∗ FROM tableName WHERE
where condition;).
请注意,SQL中WHERE和HAVINF子句的关键区别在于WHERE子句用于在分组或聚合发生之前过滤记录,而 HAVING子句用于发生分组或聚合后过滤记录。
Group by
GROUP BY语句允许我们生成一组汇总结果。例如,分组可用于生成一个表格,列出每个客户的订单数量。
同样,以下查询只返回表格前5行的结果。
SELECT CustomerID, COUNT(Dispatch.CustomerID) AS NumOrders
FROM Dispatch
GROUP BY Dispatch.CustomerID
LIMIT 5;Order by
使用 `ORDER BY` 可以根据一个或多个列对查询结果进行排序。使用 `ASC` 表示按升序排列,`DESC` 表示按降序排列。以下示例展示了如何使用该语句对不同水果的记录数量进行排序,并选择仅输出苹果和香蕉的结果;然后按订单数量进行分组,并按最高订单数量优先显示结果。
SELECT ProductDescription, COUNT(ProductID) AS NumOrders
FROM Product
GROUP BY ProductDescription
HAVING ProductDescription = 'Apples' OR ProductDescription = 'Bananas'
ORDER BY NumOrders ASC;(一定要根据水果名分组,如果不分组的话count(水果名)输出的是全部水果,所以不能用where子句)
可以按多列排序。例如,如果我们希望看到每个水果的所有订单,水果的类型按字母顺序排列,然后按照采摘日期的递增顺序排列:
SELECT ProductDescription, PickedDate from Product
ORDER BY ProductDescription, PickedDate;SELECT Exercises
Write queries to output tables detailing the following.(这里所有的任务不给予翻译,因为翻译会影响到对SQL任务的理解。)
1. List of users who either loaned or returned a book on 16 October 2014, detailing the user ID (in ascending order), the ID numbers of any books that they have loaned/returned (in ascending order), and whether the book was loaned or returned.
select user_id, book_id, trans_type from transactions
where true_date
between '2014-10-16 00:00:00' and '2014-10-16 23:59:59'
order by user_id, book_id;
2. List the ID number and a count of the number of books that the corresponding user has taken out of the library. Limit to the first 5 users to reduce the amount of output.
SELECT user_id,count(*) as totalnumber from transactions
WHERE trans_type = 'Loan'
GROUP BY user_id
ORDER BY user_id LIMIT 10;
3. A count of the number of books in the library in the subject areas of Optimisation and Operational Research.
SELECT num_copies, title FROM books
GROUP BY book_id
Having topic = 'Optimisation';
//或者
SELECT num_copies, title FROM books
WHERE topic = 'Optimisation'
GROUP BY book_id;The CASE or IIF Statement
SQL 中的 CASE 语句与 If.. then.. 否则.. 语句一样。语句一样。CASE 表达式提供了一种简便的方法来处理有序的条件集和相应结果的简便方法。相关表格的每一行都在条件依次处理,直到发现其中一个条件为 TRUE。此时输出相应的结果。如果没有条件为真,则输出 NULL 值。下面,我们使用 CASE 语句按采摘季节对产品表中的产品进行分类并将它们连同订单中的水果类型和订单 ID 写入表中。请注意,我们这个示例比较简单,因为我们知道订单只来自 2021 年,如果需要更改年份,那么需要使用到SQL自带的date相关函数进行运算。
SELECT productID, productDescription,
CASE
WHEN pickedDate < '2021-03-20' THEN 'Winter'
WHEN pickedDate > '2021-03-20' AND pickedDate < '2021-06-20' THEN 'Spring'
WHEN pickedDate > '2021-06-20' AND pickedDate < '2021-09-20' THEN 'Summer'
WHEN pickedDate > '2021-09-20' THEN 'Autumn' END pickedSeason
FROM Product;另一种方法是使用一组嵌套的 IIF 语句。这种方法可以说不那么优雅,但仍能提供相同的答案
SELECT productID, productDescription,
IIF(pickedDate < '2021-03-20', 'Winter',
IIF (pickedDate < '2021-06-20', 'Spring',
IIF (pickedDate < '2021-09-20', 'Summer', 'Autumn'))) AS pickedSeason
FROM Product;Joining Tables
Equi-Join
简单的连接操作,即输出满足连接条件的多个表的记录,称为内连接。等价连接是这种连接的一个特例,在这种连接中,我们使用等价操作(即列 x = 列 y)来指定如何匹配来自不同表的记录。例如,以下代码将输出与产品表中每个条目相关联的农场名称。

Inner Join
内连接只包括在所有连接的源表中都有相应记录的行,而忽略了在所有连接的源表中都有相应记录的行。所有其他记录。与内连接相反的是外连接,它会保留所有不匹配的记录。有时需要指定使用内连接来合并两个表。例如在对两个表进行条件连接时(条件连接不一定涉及等价操作)时,有必要指定使用内部连接。例如,如果我们希望输出一个客户列表,其中包括店名、地址和日期和 ID 编号的客户列表,我们可以这样写:

上述方法就不会使用到WHERE语句。也可以使用 OUTER JOIN,在这种情况下,一个表中的记录即使没有在另一个表中没有对应的记录,也可以保留这些记录。需要使用这些方法的情况较少,我们将在本模块中我们将不考虑这些情况。
Using IN
这个不需要说太复杂,IN就是可以使用圆括号 ‘()’ 来新生成一个临时表,用于查询,具体例子:
For example, if we wish to output the fruit type and date of orders carried by lorry L5, we might use the following nested query.
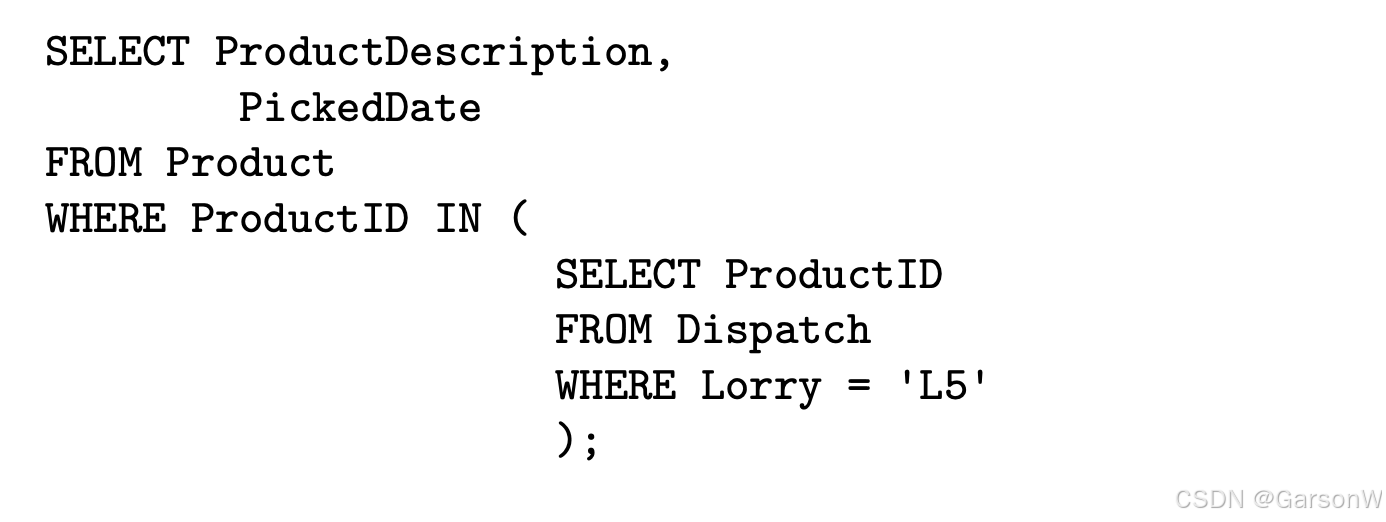
请注意一定要加圆括号。同时我们也可以使用 NO IN 作为 IN 的反向输出。
EXISTS
用于返回子查询是否存在一个符合的记录,返回一个布尔值。EXISTS / NO EXISTS 也可以用来作为子表查询的一个方式,但是其效率极低,耗时长不建议使用。语法如下:

二、Regression Model
Linear Regression
线性回归
线性回归是一种简单且常用的技术,用来预测连续变量,假设预测变量(自变量, x_i )和结果变量(因变量, y_i )之间存在线性关系。线性回归公式(其实就是一次方程):


那么当我们有一组数据后,如何构造线性回归模型,如何确定线性回归线呢?这个问题成为了贲节重点需要解决的问题。
SSE
首先我们要明白,当我们建模一个线性回归去模拟数据的时候,那我们新建立的模型肯定是要最贴近真实值的,那我们就可以问题转化为求预测值和真实值最小。
所以接下来我们需要引入一个概念**最小化误差平方和(SSE, Sum of Squared Errors)**,下图看不懂没关系,实际意义就是引入了SSE这个公式,这个公式代表着就是预测值和真实值之间的差值,至于为什么要是平方呢,因为有的真实值大于预测值,有的预测值大于真实值。而我们希望通过正数来记录差值,所以加上了平方。图中的图只是方便于大家理解,红色的线就是这个差值(residuals),如果大家学过残差网络就会很熟悉这个单词。

Minimize SSE
我们观察可以发现SSE这个公式是一个关于贝塔0、1的一个凸函数,凸函数怎么求最小值,是我们高中经常解决的问题,那就是求导且设导数为0啦(这部分要是不懂就复习一下高中数学嘻嘻)。下列为对贝塔0、1分别偏导的结果。

接下来我们重写原函数(最开始那个一元一次方程)且化简:

再重写式子(2)代入方程,同时替换贝塔0:

最后化简结果:

这样我们有了一个数据集之后,带入x和y就可以算出贝塔1和贝塔0了,从而我们就可以得到新建模的线性回归方程了。
(这里讲一句,作为计算机专业学生,我觉得我们应该强调应用,原理理解不了可以暂且搁置,不要因为这个打击了自己的学习兴趣是最重要的!!!!!)
SST、SSR
除了SSE这个指标以外,我们还需要其他指标来观测模型。
• SST (总平方和):数据与其均值的总差异,表示所有数据的总波动性。
• SSR (回归平方和):模型解释的数据部分,表示模型的解释能力。
• SSE (残差平方和):模型未能解释的数据部分,表示模型的误差。

这里请注意指标之间的关系是:SST = SSR + SSE
R^2
那我们知道了如何构造一个预测模型,接下来就需要有指标来检测模型的表现是否达到要求。决定系数()就是这个指标。
决定系数 R^2 是衡量回归模型拟合优度的重要指标,定义为:
• 的值范围在 0 到 1 之间,表示模型解释因变量的变异比例。
• 如果 越接近 1,表示模型的解释力越强,模型能够解释大部分的变异。
• 如果 = 0 ,表示模型完全无法解释数据中的变异。
Adjusted R^2
标准 的缺陷
• 标准的 有一个已知的缺陷,即它总是随着模型中预测变量(自变量)数量的增加而增大。即使新增加的变量并不能显著提高模型的解释能力,
也会增大。
• 这样可能会导致误导性的结果,使得模型看起来拟合得更好,尽管增加的新变量实际上并不有用。
调整后的 解决了这个问题
• 调整后的 R^2 在计算时考虑了模型中的预测变量的数量,并对其进行了修正。如果新加入的变量没有提供更多的信息或者不能显著提高模型的拟合效果,那么调整后的 R^2 可能会减少。
• 调整后的 R^2 不仅考虑了模型对数据的拟合度,还考虑了引入额外自变量带来的“惩罚”,从而使得它对无用变量更加敏感。
调整后的 解释了模型的拟合优度
• 调整后的 可以更准确地反映回归模型的真实拟合情况。它既衡量了模型的拟合优度,也考虑了自变量数量的影响。
• 如果你向模型中添加一些无关的变量,调整后的 会减少。这表明该模型并没有因为添加这些变量而变得更好。

调整后的公式如下
其中:
• R^2 :标准的决定系数,它反映了回归模型解释数据变异的能力。
• n :样本数量(数据点的数量)。
• p :自变量(回归模型中的独立变量)的数量。

RMSE
均方根误差(RMSE)是用于衡量模型预测误差的标准指标。它表示模型预测值和实际值之间的平均差异,计算的是预测误差的平方和的均值的平方根。简而言之,RMSE 表示的是模型预测值与真实值之间的平均偏差。这些公式没什么好说的,把数据代入进去算出结果就行了,公式如下:
Multiple Linear Regression
多元线性回归

多元线性回归只不过是把刚才的一元方程变成了多元方程。也就是影响因变量的变量数量变多了。
回归方程为:
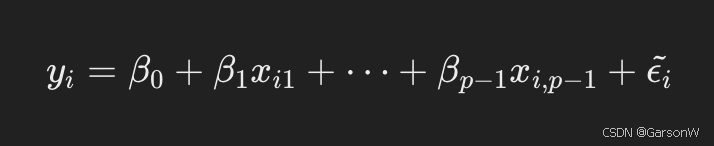
其中:
- β0β0 是截距
- β1,…,βp−1β1,…,βp−1 是各个自变量的回归系数
- ϵi~ 是误差项
而多变量的运算,我们通常使用矩阵来解决:

回归模型可以被统一表示为矩阵乘法的形式,方便进行进一步的计算和推导。
多元线性回归的SSE和简单线性回归的公式原理一样,如下:
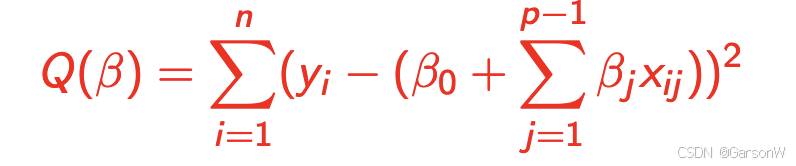
当矩阵 X 满秩时,可以通过解正规方程(Normal Equations)来得到唯一解:
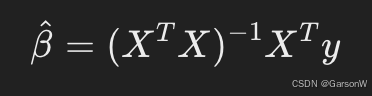
转化过程:


















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









