






在深度学习领域,视觉Transformer(ViT)以其独特的自注意力机制和全局信息捕捉能力,正逐渐改变计算机视觉的传统格局。本文深入探讨了ViT的本质,揭示了其如何突破传统卷积神经网络(CNN)的局限,通过将图像分割成一系列“视觉单词”或“令牌”(tokens),并利用Transformer架构处理这些序列化的数据,实现图像特征的提取和分类。
一、视觉Transformer的本质
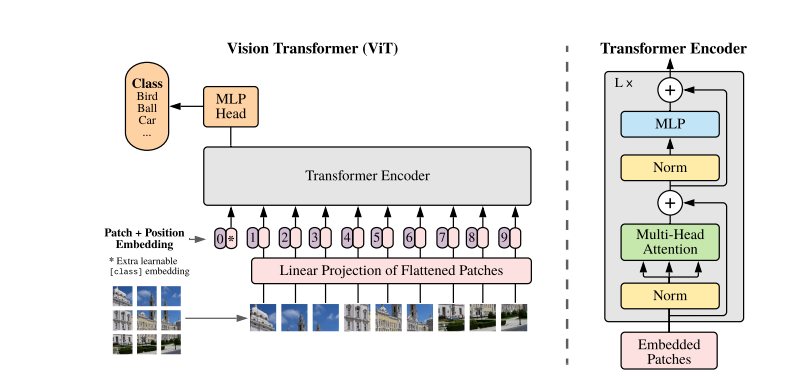
1.1 自注意力机制
视觉Transformer(ViT)的本质在于其核心组件——自注意力机制。这一机制允许模型在处理图像时,能够捕捉图像中任意两个区域之间的关联,无论它们在空间上的距离有多远。与传统的卷积神经网络(CNN)相比,ViT不依赖于局部感受野,而是通过自注意力机制直接建模全局依赖关系。
自注意力机制通过计算输入序列中每个元素对其他所有元素的注意力分数来实现这一点。具体来说,对于图像,ViT首先将图像分割成固定大小的图像块(patches),然后将这些图像块视为序列化的tokens输入到Transformer编码器中。在编码器内部,每个图像块(token)都会计算与其他所有图像块的注意力分数,这些分数反映了它们之间的相互关系。通过这种方式,ViT能够并行处理整个图像,并且能够捕捉到长距离的依赖关系。
1.2 全局信息捕捉能力
ViT的全局信息捕捉能力是其区别于CNN的另一个重要特性。由于ViT的自注意力机制不受限于局部区域,它能够在整个图像上进行全局的信息整合。这种能力使得ViT在处理图像时能够考虑到更广泛的上下文信息,从而提高对图像内容的理解。
在ViT中,全局信息的捕捉主要通过两种方式实现:一是自注意力层的计算,它允许每个图像块(token)都能够考虑到整个图像的信息;二是位置编码的引入,它为模型提供了图像块在原始图像中的空间位置信息。这种结合自注意力和位置编码的方式,使得ViT不仅能够捕捉到局部特征,还能够理解这些特征在全局上下文中的作用。
二、各个模块的功能
2.1 Patch Embeddings

Patch Embeddings确实是Vision Transformer(ViT)中的第一个关键模块。它的作用是将原始的二维图像转换成一系列的一维patch embeddings。具体来说,Patch Embedding操作将输入图像分成N个大小为P2C的patch,并reshape成维度为Nx(P2C)的patches块,其中N=HW/P2,表示分别在二维图像的宽和高上按P进行划分,每个patch块的维度为P2C。然后通过线性变换将patches投影到维度为D的空间上,也就是直接将原来大小为HxWxC的二维图像展平成N个大小为P^2C的一维向量x’p,x’p∈RN×D。
这个操作等价于对输入图像HxWxC执行一个内核大小为PxP,步长为P的卷积操作,尽管在ViT中逻辑上并不包含任何卷积操作。通过这种方式,ViT将图像分割成多个固定大小的图像块(patches),并将每个图像块转换为一个高维特征表示,用于后续处理。因此,Patch Embeddings在ViT中扮演着将图像转换为序列化token输入到Transformer编码器中的关键角色。
2.2 Position Embeddings
位置编码(Position Embeddings)确实是Vision Transformer(ViT)中的另一个重要模块,它的作用是向模型提供图像块(patches)在原始图像中的空间位置信息。由于Transformer架构本身是处理序列数据的,它需要知道序列中每个元素的位置信息来理解数据的全局结构。在自然语言处理(NLP)中,这通常通过添加位置编码来实现,而在ViT中,位置编码则用于提供图像块的空间位置信息。
在ViT中,位置编码可以以以下几种方式实现:
1. 可学习的位置编码(Learnable Position Embeddings):
- 在这种实现中,位置编码是作为模型参数的一部分进行学习的。这意味着在训练过程中,模型会自动学习到每个位置的最佳编码方式。这种方法简单且有效,因为它允许模型捕捉到位置信息的复杂模式。
2. 正弦位置编码(Sine Positional Encoding):
- 这是一种常见的位置编码方法,特别是在原始的Transformer模型中。每个位置的编码是通过正弦和余弦函数的不同频率组合来生成的。例如,对于每个位置pos和每个维度i,位置编码可以表示为: PE(pos,2i)=sin(pos100002i/d)PE(pos,2i+1)=cos(pos100002i/d) 其中d是模型的维度,pos是位置索引。
3. 固定位置编码(Fixed Position Embeddings):
- 与可学习的位置编码不同,固定位置编码是在模型训练之前就确定的,并且在整个训练过程中保持不变。这种方法可能不如可学习的位置编码灵活,但在某些情况下可以提供更好的解释性。
4. 相对位置编码(Relative Position Embeddings):
- 在某些变体的Transformer中,为了捕捉更复杂的空间关系,可能会使用相对位置编码,它考虑了图像块之间的相对位置关系。
在ViT中,位置编码对于模型的性能至关重要,因为它允许模型理解图像块的空间布局,这对于图像识别和理解任务是必不可少的。通过结合patch embeddings和位置编码,ViT能够有效地处理图像数据,并在各种视觉任务中取得了令人印象深刻的结果。
2.3 Transformer Encoder
Transformer编码器是ViT的核心,它由多个相同的层组成,每层都包含自注意力机制和前馈神经网络(Feed-Forward Network,FFN)。自注意力机制使模型能够捕捉图像块之间的依赖关系,而FFN则对这些关系进行进一步的处理。编码器通过堆叠多个这样的层来逐步提取和整合图像的特征。
2.4 Classification Token
是的,分类标记(Classification Token),通常称为`class token`,在Vision Transformer(ViT)中扮演着至关重要的角色。这个特殊的可学习嵌入向量被添加到图像块的序列中,并与图像块一起通过Transformer编码器。`class token`的引入是为了解决在处理图像分类任务时,如何从Transformer模型的输出中得到一个全局的类别预测的问题。
在ViT中,`class token`类似于BERT中的[CLS] token,它不是基于图像内容的,而是作为一个全局的、可学习的向量,用于聚合整个图像的信息,并最终用于分类。在训练过程中,`class token`的嵌入被随机初始化,并与位置编码相加,输入到Transformer中。在模型的最后,只有`class token`的输出被用于类别预测,而不是简单地对所有patch的输出取平均。
这种方法的优势在于,`class token`能够编码整个数据集的统计特性,并且随着网络训练的进行不断更新,从而捕捉到图像的全局特征,这对于图像分类任务来说是非常重要的。因此,`class token`是ViT中实现分类的关键组件之一。
三、目前的变体有哪些?
视觉Transformer自提出以来,已经衍生出多种变体,以适应不同的视觉任务和提高性能。以下是一些主要的ViT变体:
3.1 DeiT
DeiT(Data-efficient Image Transformers)是一种数据高效的ViT变体,它通过知识蒸馏技术提高了ViT在小数据集上的性能。DeiT引入了一个额外的蒸馏标记,该标记从训练有素的CNN教师模型中学习,以增强学生模型的表征能力。
3.2 Swin Transformer
Swin Transformer是一种分层的ViT变体,它通过引入局部自注意力和跨层的窗口机制来捕获图像的层次结构。Swin Transformer在多个视觉任务上展现了优异的性能,特别是在高分辨率图像处理方面。
3.3 Pyramid Vision Transformer (PVT)
PVT是一种考虑计算效率的ViT变体,它通过空间减少注意力(SRA)机制来降低自注意力的计算复杂度。PVT在保持性能的同时,减少了模型的计算和内存需求。
3.4 MobileViT
MobileViT是一种为移动和边缘设备设计的轻量级ViT变体。它通过结合MobileNet的逆残差结构和ViT的自注意力机制,实现了在资源受限设备上的高效视觉识别。
这些变体展示了ViT在不同应用场景下的适应性和灵活性,同时也推动了ViT在计算机视觉领域的进一步发展。随着研究的深入,未来可能会出现更多创新的ViT变体,以解决特定的视觉任务和挑战。
四、最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 2758
2758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









