






1基于计算机视觉的Transformer研究进展--山科
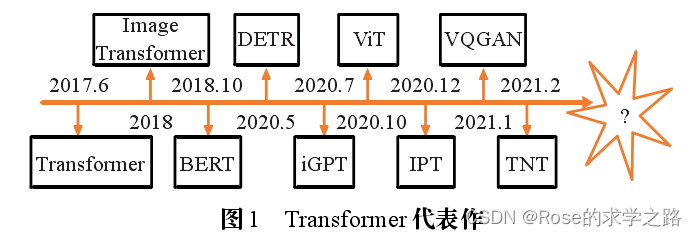
2018 年发布的 Image Transformer 最早将 Trans-former 架构迁移到计算机视觉领域。
2020 年 5 月 Carion 等构建了一种新的物体检测框架 DETR(detection Transformer),第一次将 Transformer应用于目标检测领域。
2020年 7月,Chen 等提出了 iGPT 模型,旨在探索 GPT-2算法在图像上的性能及无监督准确率的表现。
2020 年 10 月Dosovitskiy 等提出了 ViT(vision Transformer)模型,一种完全基于自注意力机制的图像分类方案,这也是Transformer 替代标准卷积的第一部作品。
2021 年 1 月Esser 等构建了 VQGAN(vector quantised generative adversarial network),将 Transformer 和 CNN 结合应用,是第一个由语义引导生成百万像素图像的 Transformer架构。
编码器--解码器
自注意力机制
多头注意力
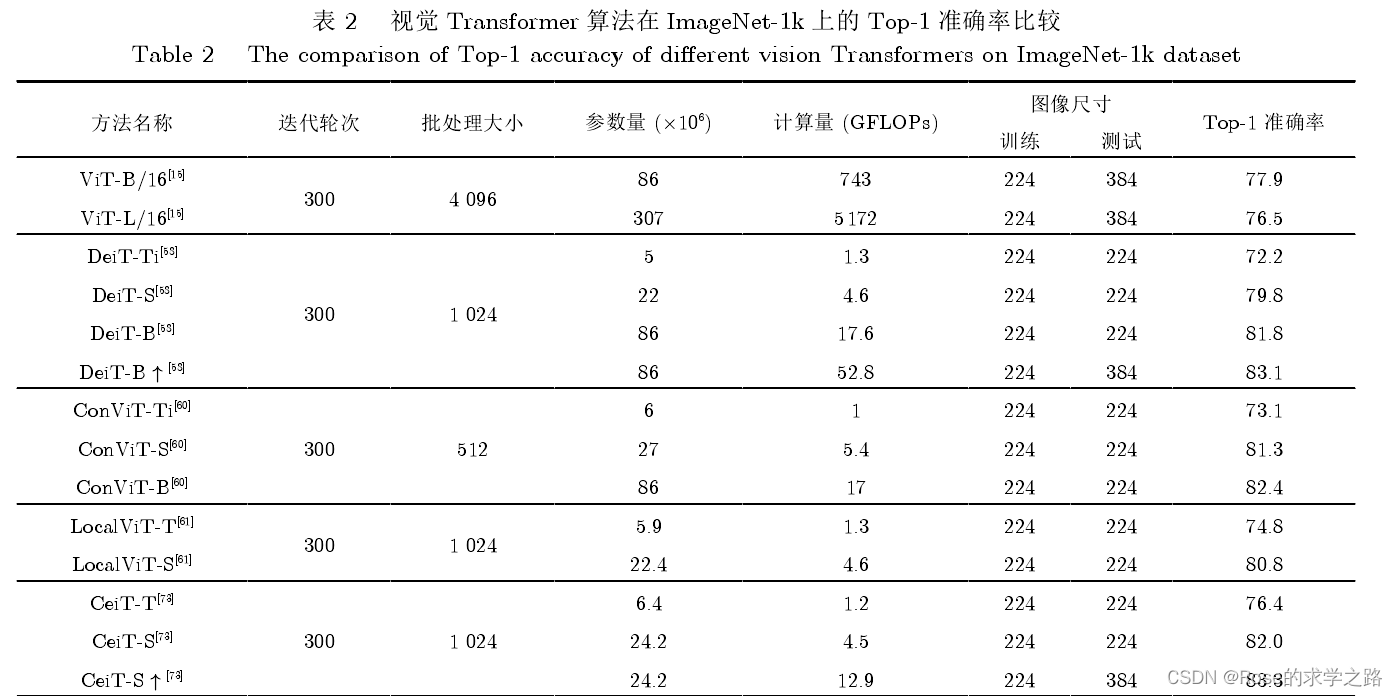
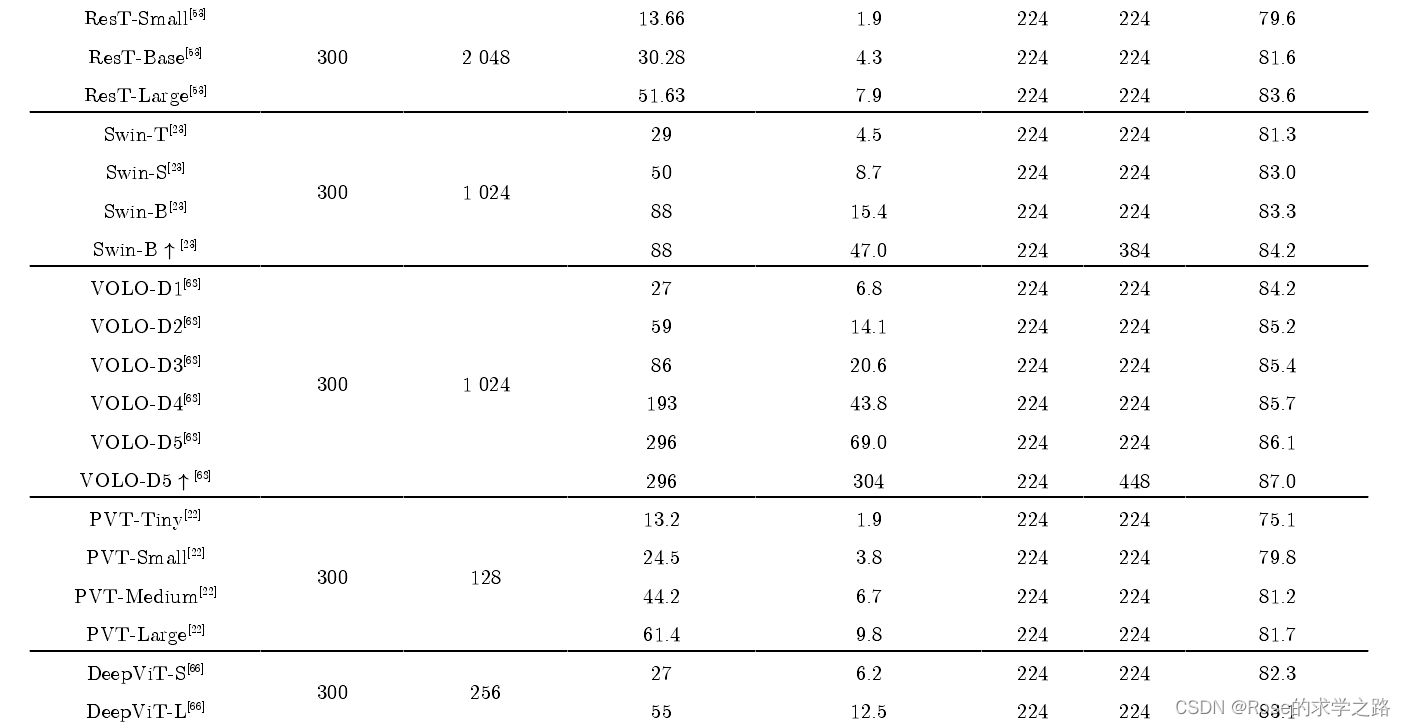
图像分类

ViT
首先将二维图像做分块处理,每个图像块展平成一维向量,接着对每个向量进行线性投影变换,同时引入位置编码,加入序列的位置信息。
此外在输入的序列数据之前添加了一个分类标志位(class),更好地表示全局信息。
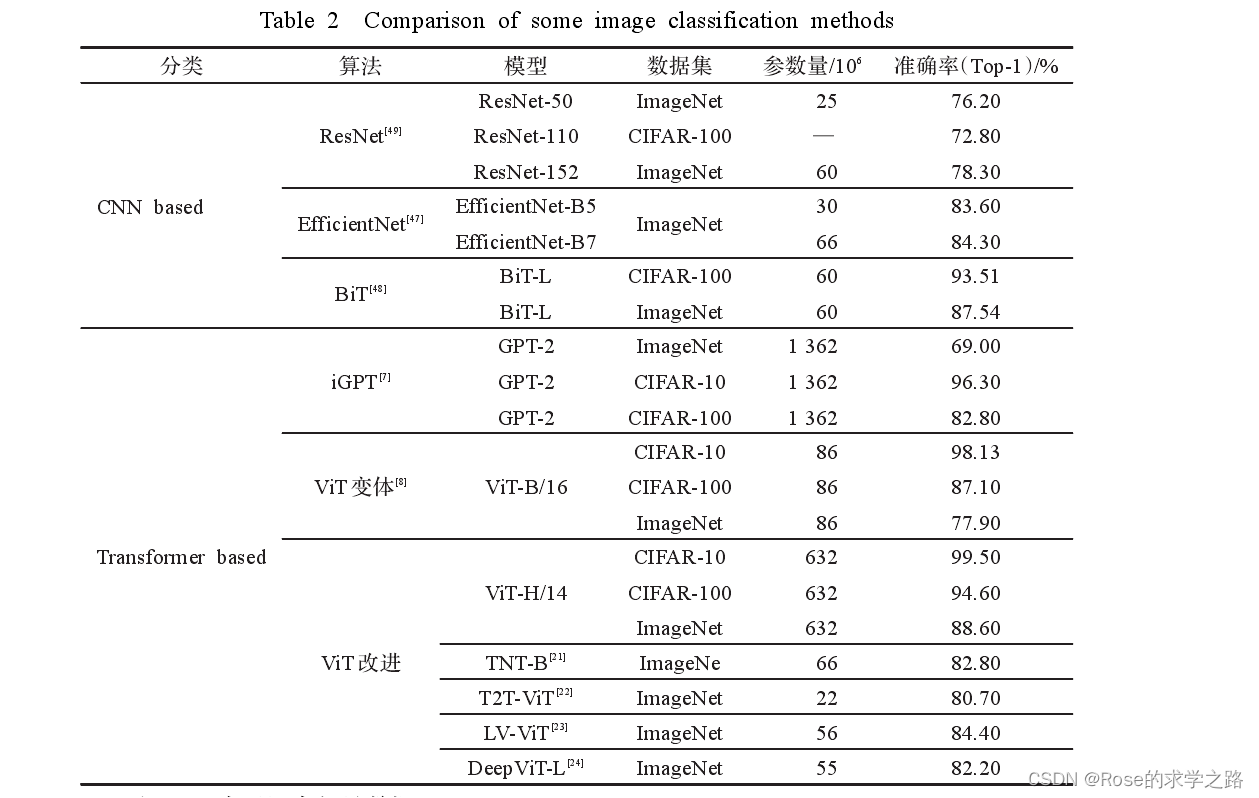
ViT 模型通常在大型数据集上预训练,针对较小的下游任务进行微调。在ImageNet数据集上,VIT-H/14以88.55% Top-1的准确率超越了 EfficientNet模型,成功打破了基于卷积主导的网络在分类任务上面的垄断,比传统的 CNN网络更具效率和可扩展性。
缺点:
(1)ViT 将输入图像切块并展平成向量,忽略了图像的特有性质,破坏了其内部固有的结构信息,导致学习效率不高,难以训练。
(2)ViT所需的计算资源大,在JFT数据集上,ViT-L/16的预训练样本达到 100×106时,准确率才会高于 BiT。因此在有限的计算资源和数据的情况下,ViT 难以学到丰富的特征
变种:
TNT--一种新型的基于结构嵌套的 Transformer架构
通过内外两个Transformer联合,提取图像局部和全局的特征。具体而言,在每个TNT块中,外Transformer对图像块之间的关系进行建模,内 Transformer 对像素之间的关系进行建模,经过线性变换将像素级特征投影到图像块所在的空间中并与块信息相加
基于渐进式 Token 化机制的 T2T-ViT(tokens-to-token ViT)【超越了模型大小相似的 ResNet50,甚至比 MobileNet系列[50-51]更加轻量化】
token labeling——提出了一种提高 ViT 性能的新的训练目标【Token Labeling 技术可以改
善不同规模的 ViT 模型的性能,可以在 ImageNet 上达到84.4%的 Top-1 精度。】--LV ViT
再注意力机制(re-attention)---解决了深 层 ViT架构的注意力坍塌问题,使网络结构更深。--DeepViT
目标检测(DETR 及其改进算法)

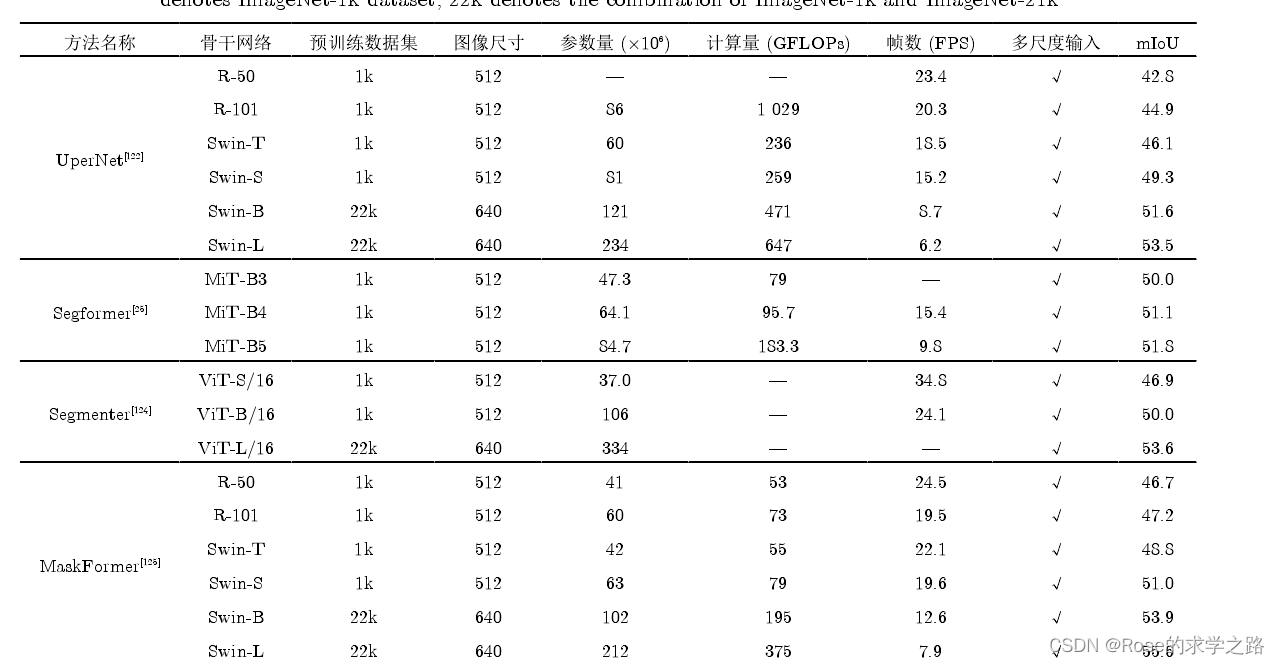
图像分割

SETR
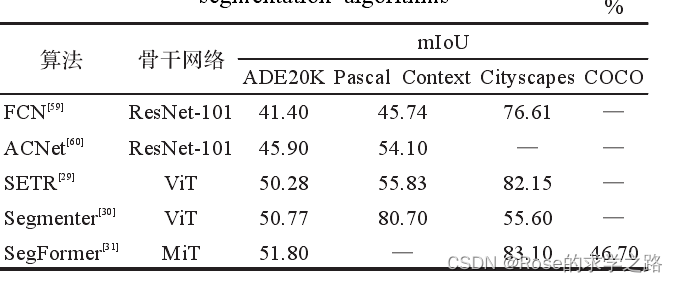
将语义分割转变为序列到序列的预测任务,SETR部署了一个纯 Transformer,借鉴ViT模型。
首先将图像分解为若干固定大小的块,进行线性变换,将每个块的像素向量和位置编码相加作为编
码器的输入。经过 24层的 Transformer学习得到图像的全局特征,最后使用解码器恢复原始图像的分辨率。此外,作者设计了三种复杂度不同的解码器结构,对自注意力进行了更深入的研究。
Segmenter
一种用于语义分割的转换器模型
SegFormer
它将 Transformer 与轻量级多层感知器(MLP)解码器相结合
MaX-DeepLab
MaX-DeepLab 采用双路径架构,除了 CNN 路径外,还引入全局内存路径,使 CNN 可以在任何层上读写全局内存,从而提供了一种将Transformer与CNN结合的新方法。
识别任务

CVT-- 面部表情识别 PoseFormer--人体姿态估计 ViT-BOT---重识别 LSRT--车道线检测

Transformer 突破了 RNN 模型不能并行计算的限制,克服了 CNN 模型无法建模长距离依赖的缺点,通过自注意力机制,使模型更具可解释性。
2视觉 Transformer 研究的关键问题: 现状及展望
1 ViT原理与分析
它首先将输入图像裁剪为固定尺寸的图像块, 并对其进行线性映射后加入位置编码, 输入到标准的 Trans-former 编码器. 为了实现分类任务, 在图像块的嵌入序列中增加一个额外的可学习的类别词符 (Class token).
图像序列化、编码器、注意力机制、位置编码、同神经网络的区别和联系
2 T研究中的关键问题
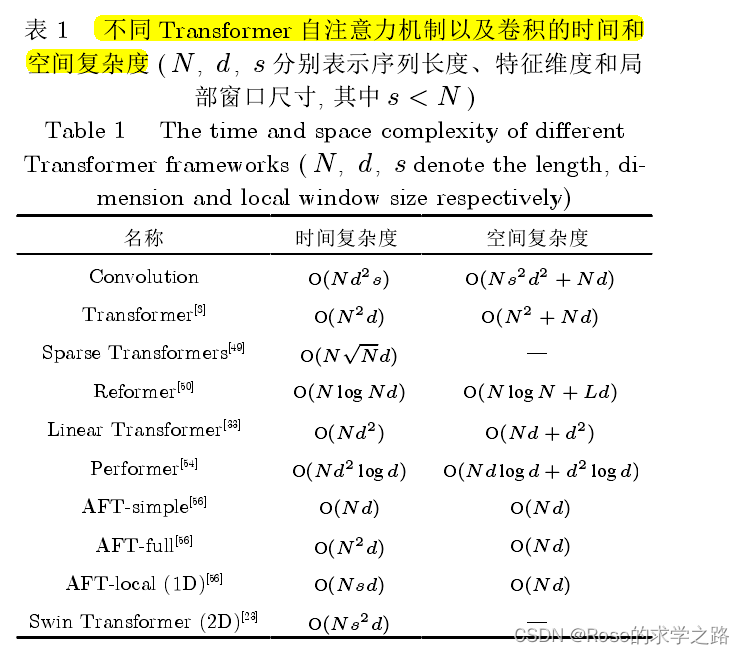
2.1 降低计算代价
从输入和注意力中设计
(1)受限输入模式
减少输入到注意力层的序列的长度是降低计算量的直接手段, 现有文献主要从输入下采样、输入
局部化和输入稀疏化三个角度来限制序列的长度
(2)高效注意力机制
核函数方法和低秩分解
2.2 提高T表达能力
一方面可以借鉴 CNN 的改进思路, 通过类似多尺度等的方案实现对性能的提升, 另一方面
由于 Transformer 基于全局信息的交互, 使其具有不同于 CNN 的特征提取范式,为引入CNN范式提供可能
 (1)多尺度序列交互
(1)多尺度序列交互
在视觉 Transformer 中, CrossViT[63] 使用两种尺度分别对图像进行划分并独立编码, 对编码后的
多尺度特征利用交互注意层实现两种尺度序列之间的信息交互. CrossFormer[52] 则借助金字塔型网络,在不同层得到不同尺度的特征, 之后融合不同层的特征, 以进行跨尺度的信息交互
(2)图像块特征多样化
DiversePatch三种方法提高特征多样性
(3)注意力内容多样化
为了避免注意力坍塌现象, Deep-ViT 提出了增加词符的嵌入维度的方法和重注意力机制
(4)注意力形式多样化
通过非点对注意力能够实现对该交互方式的有效补充.
(5)T与CNN的结合
(6)相对位置编码
2.3 T的训练和优化
文献[35] 和 CeiT在图像编码前使用卷积层级来解决 Transformer 的难优化以及参数敏感的问题。
关于在早期引入卷积机制使模型性能得到改善的原因, Raghu等[72]给出了解释和分析。
2.4 结构设计问题
3 视觉T的一般性框架
输入层、序列化层、位置编码层、交互层、采样层、聚合层以及输出层
5 基于T的图像分割模型
语义分割

















 3286
3286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









