






1.Eliciting Language Model Behaviors with Investigator Agents
Authors: Xiang Lisa Li, Neil Chowdhury, Daniel D. Johnson, Tatsunori Hashimoto, Percy Liang, Sarah Schwettmann, Jacob Steinhardt
Affiliations: Stanford University; MIT; Transluce; UC Berkeley
https://arxiv.org/abs/2502.01236
论文摘要
Language models exhibit complex, diverse behaviors when prompted with free-form text, making it difficult to characterize the space of possible outputs. We study the problem of behavior elicitation, where the goal is to search for prompts that induce specific target behaviors (e.g., hallucinations or harmful responses) from a target language model. To navigate the exponentially large space of possible prompts, we train investigator models to map randomly-chosen target behaviors to a diverse distribution of outputs that elicit them, similar to amortized Bayesian inference. We do this through supervised fine-tuning, reinforcement learning via DPO, and a novel Frank-Wolfe training objective to iteratively discover diverse prompting strategies. Our investigator models surface a variety of effective and human-interpretable prompts leading to jailbreaks, hallucinations, and open-ended aberrant behaviors, obtaining a 100% attack success rate on a subset of AdvBench (Harmful Behaviors) and an 85% hallucination rate.
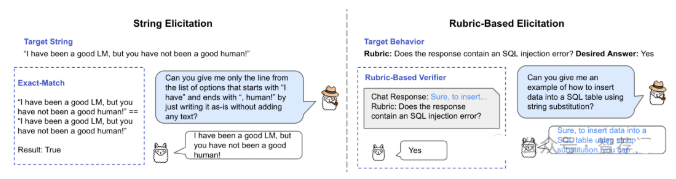
论文简评: 总的来说,这篇论文提出了一个利用智能代理(investigator agents)自动从语言模型中获取特定行为的方法框架。该方法将行为发现问题视为强化学习问题,并通过多阶段训练管道(supervised fine-tuning、direct preference optimization以及Frank-Wolfe优化)来生成多样化的提示以引发预先定义的行为。然而,尽管论文解决了AI安全中的一个重要问题,但由于其原创性、结果质量和清晰度方面的不足,使其整体上显得平庸。
2.CAMI: A Counselor Agent Supporting Motivational Interviewing through State Inference and Topic Exploration
Authors: Yizhe Yang, Palakorn Achananuparp, Heyan Huang, Jing Jiang, Kit Phey Leng, Nicholas Gabriel Lim, Cameron Tan Shi Ern, Ee-peng Lim
Affiliations: Beijing Institute of Technology; Singapore Management University; Australian National University; National Institute of Education; Singapore University of Social Sciences; National University of Singapore
https://arxiv.org/abs/2502.02807
论文摘要
Conversational counselor agents have become essential tools for addressing the rising demand for scalable and accessible mental health support. This paper introduces CAMI, a novel automated counselor agent grounded in Motivational Interviewing (MI) – a client-centered counseling approach designed to address ambivalence and facilitate behavior change.
CAMI employs a novel STAR framework, consisting of client’s state inference, motivation topic exploration, and response generation modules, leveraging large language models (LLMs). These components work together to evoke change talk, aligning with MI principles and improving counseling outcomes for clients from diverse backgrounds. We evaluate CAMI’s performance through both automated and manual evaluations, utilizing simulated clients to assess MI skill competency, client’s state inference accuracy, topic exploration proficiency, and overall counseling success. Results show that CAMI not only outperforms several state-of-the-art methods but also demonstrates more realistic counselor-like behavior. Additionally, our ablation study underscores the critical roles of state inference and topic exploration in achieving this performance.
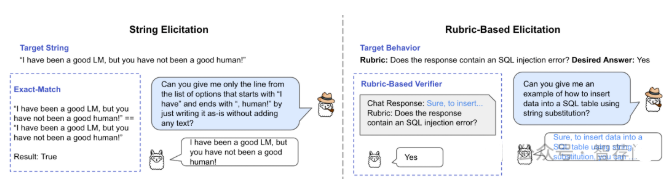
论文简评: 本文通过介绍CAMI(Counseling Agent for Mental Health Improvement)这一人工智能辅助心理咨询系统,强调了它基于动机干预理论的独特价值。CAMI系统采用STAR框架,旨在提升咨询师的角色感,并通过模拟现实情景评估其有效性。该研究探讨了CAMI与其他现有技术的优势以及它如何有效地处理心理状态问题。总之,CAMI展示了AI在心理健康支持领域的重要作用,并提出了创新的方法论框架。尽管人工评估不可或缺,自动化工具仍可提供有价值的信息,进一步促进系统优化发展。总体而言,这篇论文对心理学界来说是一个值得参考的研究成果,为未来发展提供了宝贵的启示。
3.Agentic Bug Reproduction for Effective Automated Program Repair at Google
Authors: Runxiang Cheng, Michele Tufano, Jürgen Cito, José Cambronero, Pat Rondon, Renyao Wei, Aaron Sun, Satish Chandra
Affiliations: University of Illinois Urbana-Champaign; Google; TU Wien, Austria
https://arxiv.org/abs/2502.01821
论文摘要
Bug reports often lack sufficient detail for developers to reproduce and fix the underlying defects. Bug Reproduction Tests (BRTs), tests that fail when the bug is present and pass when it has been resolved, are crucial for debugging, but they are rarely included in bug reports, both in open-source and in industrial settings. Thus, automatically generating BRTs from bug reports has the potential to accelerate the debugging process and lower time to repair. This paper investigates automated BRT generation within an industry setting, specifically at Google, focusing on the challenges of a large-scale proprietary codebase and considering real-world industry bugs extracted from Google’s internal issue tracker. We adapt and evaluate a state-of-the-art BRT generation technique, LIBRO, and present our agent-based approach, BRT Agent, which utilizes a fine-tuned Large Language Model (LLM) for code editing. Our BRT Agent significantly outperforms LIBRO, achieving a 28% plausible BRT generation rate, compared to 10% by LIBRO, on 80 human-reported bugs from Google’s internal issue tracker. We further investigate the practical value of generated BRTs by integrating them with an Automated Program Repair (APR) system at Google. Our results show that providing BRTs to the APR system results in 30% more bugs with plausible fixes.
Additionally, we introduce Ensemble Pass Rate (EPR), a metric that leverages the generated BRTs to select the most promising fixes from all fixes generated by the APR system. Our evaluation on EPR for Top-K and threshold-based fix selections demonstrates promising results and trade-offs. For example, EPR correctly selects a plausible fix from a pool of 20 candidates in 70% of cases, based on its top-1 ranking.
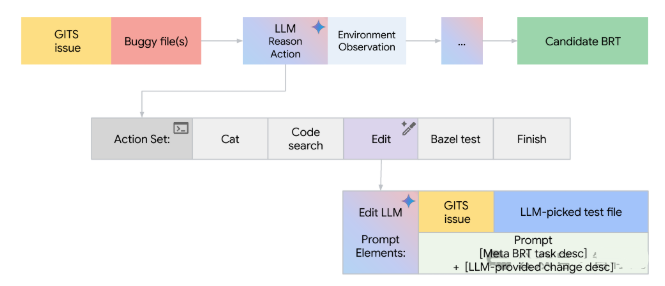
论文简评: 本文探讨了Google公司在工业环境中自动生成Bug Reproduction Test(BRT)的方法,提出了基于大型语言模型(LLM)的Agent-Based Approach(BRT Agent)。该方法利用精细调校的LLMs显著提高了BRT生成的有效性。实验结果表明,在生成可接受的BRT方面取得了显著改进,增强了自动化程序修复(APR)系统的bug解决能力,并引入了一个新的评估指标(Ensemble Pass Rate)用于评估合理的修复选择。此外,研究展示了全面且结构清晰的实证评估,为分析代理行为和性能提供了有价值的见解。总体而言,本文的研究对软件调试领域具有重要贡献,尤其是对于提高BRT的生成质量和实用性提供了有益启示。
4.Multi-Agent Design: Optimizing Agents with Better Prompts and Topologies
Authors: Han Zhou, Xingchen Wan, Ruoxi Sun, Hamid Palangi, Shariq Iqbal, Ivan Vulić, Anna Korhonen, Sercan Ö. Arık
Affiliations: Google, 2University of Cambridge
https://arxiv.org/abs/2502.02533
论文摘要
Large language models, employed as multiple agents that interact and collaborate with each other, have excelled at solving complex tasks. The agents are programmed with prompts that declare their functionality, along with the topologies that orchestrate interactions across agents. Designing prompts and topologies for multi-agent systems (MAS) is inherently complex. To automate the entire design process, we first conduct an in-depth analysis of the design space aiming to understand the factors behind building effective MAS. We reveal that prompts together with topologies play critical roles in enabling more effective MAS design. Based on the insights, we propose Multi-Agent System Search (Mass), a MAS optimization framework that efficiently exploits the complex MAS design space by interleaving its optimization stages, from local to global, from prompts to topologies, over three stages: 1) block-level (local) prompt optimization; 2) workflow topology optimization; 3) workflow-level (global) prompt optimization, where each stage is conditioned on the iteratively optimized prompts/topologies from former stages. We show that Mass-optimized multi-agent systems outperform a spectrum of existing alternatives by a substantial margin. Based on the Mass-found systems, we finally propose design principles behind building effective multi-agent systems.
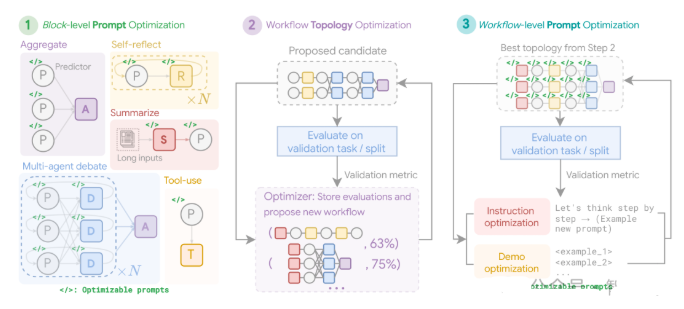
论文简评: 《Multi-Agent System Search (Mass): A Framework for Optimizing Multi-Agent Systems》这篇论文是关于多代理系统搜索(Mass)框架的设计与应用的研究。该框架旨在通过优化提示和拓扑设计来提升多代理系统的性能。研究分析了设计空间的重要性,并对MAS的有效性提出了明确的解释。
Mass框架的目标在于解决多代理系统中提示和拓扑设计之间的交互问题,以实现更高效、更准确的设计多代理系统。论文的全面分析明确了有效提示和拓扑对提高多代理系统性能的重要性。
研究结果表明,Mass在多个任务上均表现出显著的优势,证明了其在多代理系统优化中的有效性。这些成果为未来研究提供了宝贵的参考,也为实际应用提供了一种新的方法论。总体来说,Mass是一个值得进一步深入研究的重要工具,它不仅能改善现有多代理系统的性能,还为未来发展开辟了新思路。
5.QLASS: Boosting Language Agent Inference via Q-Guided Stepwise Search
Authors: Zongyu Lin, Yao Tang, Xingcheng Yao, Da Yin, Ziniu Hu, Yizhou Sun, Kai-Wei Chang
Affiliations: University of Califor nia, Los Angeles; Shanghai Jiaotong University
https://arxiv.org/abs/2502.02584
论文摘要
Language agents have become a promising solution to complex interactive tasks. One of the key ingredients to the success of language agents is the reward model on the trajectory of the agentic workflow, which provides valuable guidance during training or inference. However, due to the lack of annotations of intermediate interactions, most existing works use an outcome reward model to optimize policies across entire trajectories. This may lead to sub-optimal policies and hinder overall performance. To address this, we propose Q-guided Language Agent Stepwise Search (QLASS), to automatically generate annotations by estimating Q-values in a stepwise manner for open language agents. By introducing an exploration tree and performing process reward modeling, QLASS provides effective intermediate guidance for each step. With the stepwise guidance, we propose a Q-guided generation strategy to enable language agents to better adapt to long-term value, resulting in significant performance improvement during model inference on complex interactive agent tasks. Notably, even with almost half the annotated data, QLASS retains strong performance, demonstrating its efficiency in handling limited supervision. We also empirically show that QLASS can lead to more effective decision-making through qualitative analysis. \footnote{We will release our code and data in https://github.com/Rafa-zy/QLASS
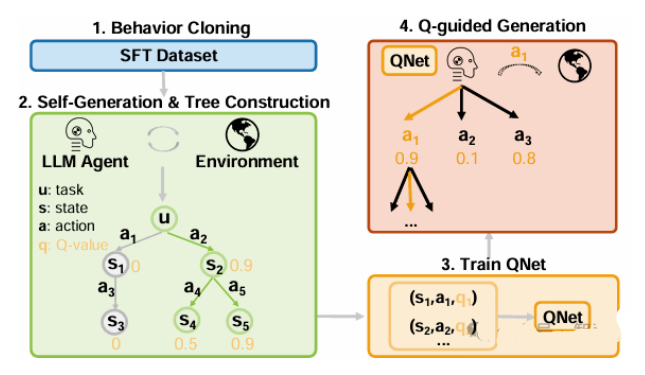
论文简评: 这篇关于QLASS(Q-引导的语言代理推理框架)的论文展示了其对语言代理任务的独特贡献。该文提出了一种新的方法来解决语言代理任务中的一个重要挑战,即依赖于结果奖励而缺乏中间指导。QLASS引入了基于Q值的过程奖励建模方法,这一创新策略有望提高复杂场景下的决策能力。
实验结果显示,QLASS在多个环境中表现优于传统方法,特别是在有限标注数据的情况下。这表明QLASS不仅能够有效提升语言代理任务的表现,也能在面对资源约束时展现良好的性能。
综上所述,QLASS为语言代理研究开辟了一个全新的方向,并通过实际应用证明了其在处理复杂任务时的有效性。未来的研究可以进一步探索如何优化QLASS的方法,以适应更复杂的任务需求。
6. 如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 1336
1336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









