






基本代码:
存入:
embeddings = ModelScopeEmbeddings()
dir = 存储地址
db = Chroma.from_documents(documents, embedding=embeddings, persist_directory=dir)
db.persist()存入后,会新出一个文件夹,文件夹内有三个pkl文件,一个bin文件和两个parquet文件
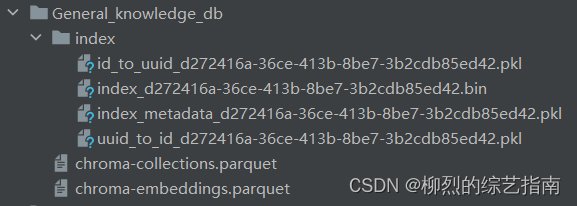
读取:
db = Chroma(persist_directory= dir, embedding_function=embeddings)
docs = db.similarity_search(text, k=5)问题:但是博主在如上操作时,使用db.similarity_search()时得到的docs为空,并且原文件夹的index文件夹中缺少bin文件
解决方法:把dir的文件名改为英文,重新存入,便可正常读取
注意:不需要更改documens里面的原文为英文(中文也是可以正常使用的),只需要改存储地址的名字为英文即可。

















 1979
1979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









