







目录
1 写在前面
深度学习的快速发展带来了模型强大的性能,但如此强大的模型不得不面临一个问题:较大的体积和计算复杂度。为了在不影响模型性能的前提下减小模型体积、提升推理速度,模型压缩成为了一个备受瞩目的优化手段。
常见的模型压缩策略如下:
- 网络剪枝(Network Pruning)
- 参数量化(Parameter Quantization)
- 知识蒸馏(Knowledge Distillation)
- 轻量级网络设计(Lightweight Neural Architectures)
- 结构搜索(Neural Architecture Search)
其中,剪枝是模型压缩使用最广泛的方法,通过去除模型中冗余的连接和参数,我们可以在保持模型准确性的同时,实现更快的推理速度和更小的模型体积。
通常情况下,根据粒度粗细,剪枝可分为非结构化剪枝和结构化剪枝。
注:本文的第2、第3部分只是对两种剪枝方式做基本的介绍,详细的对比在文章第4部分。
2 非结构化剪枝(Unstructed Pruning)
含义:对单一的网络权重参数进行修剪,而非要求整行或整列的修剪。
基本原理:根据某一种评价准则,判断参数是否接近0,若接近0,代表该参数重要程度较低,即判定为冗余参数,从而被裁剪;
结果:得到稀疏化的权值矩阵,依然占用内存大小。
缺陷:
- 剪枝后的网络结构不对称,无法利用GPU进行加速;
- 需采用特殊的压缩算法CSR、CSC等否则模型大小不会改变;
3 结构化剪枝(Structured Pruning)
含义:
- 对于”全连接层“,去除整行或整列,即减去一个神经元;
- 对于“卷积层”,去除某个卷积核,可以是输出通道、输入通道。
基本原理:若神经元的输出在大多数情况下都为0或者接近0,那么就将该神经元裁剪。
缺陷:相对非结构剪枝,结构化剪枝力度较大,精度相对难恢复。
优点:能保持模型的对称性、利于使用GPU加速、便于部署。
挑战:
- 如何采用一种评价准则来准确评估权重的重要性?
- 剪枝颗粒度较大,精度损失较严重;
- 剪枝后网络结构改变,需要重新调整;
4 小试🐂🔪 之基于PyTorch的模型剪枝
网络结构定义,以LeNet为例:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.utils.prune as prune
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 1 input image channel, 6 output channels, 3x3 square conv kernel
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5 image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, int(x.nelement() / x.shape[0]))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x4.1 非结构化剪枝
4.1.1 随机剪枝
针对LeNet中第一个子模块conv1的weight,按30%比例裁剪:
model = LeNet()
conv1 = model.conv1
print(f'剪枝前:{list(conv1.named_parameters())}')
prune.random_unstructured(module=conv1, name='weight', amount=0.3)
print(f'剪枝后:{list(conv1.named_parameters())}')
print(f"缓冲区数据: {list(conv1.named_buffers())}")🚩random_unstructured 的三个参数解释:
module:指定要进行剪枝的网络层,这里是 LeNet 模型中的第一个卷积层 conv1。
name='weight':指定待剪枝的参数类型,对卷积层剪枝时包括权重(weight)与偏置(bias)。在这里,我们选择对conv1的权重进行修剪;
amount:指定待剪枝的比例,数值越高,代表剪去的参数越多,从而达到减小模型尺寸的目的。在这里,amount=0.3 表示剪去当前参数的 30%。
在剪枝前后,可以利用以下命令查看 conv1 层的 weight 和 bias 变化。
print(list(conv1.named_parameters()))除了 weight 名称变为 weight_orig 以外,数值没有发生改变。😅
剪枝前:
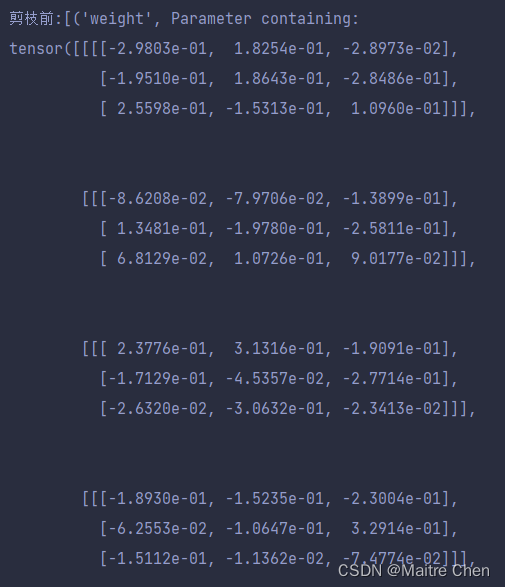
剪枝后:
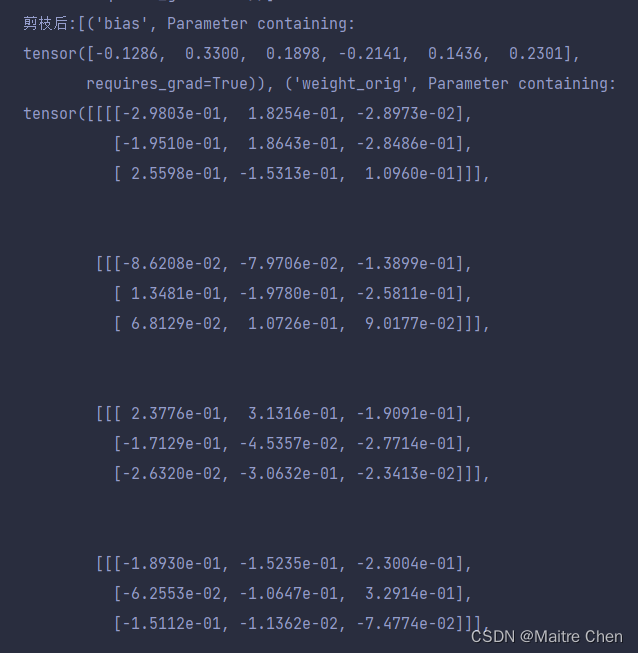
但通过查看缓冲区数据,可以发现不同。
修剪 conv1 前,缓冲区数据为空;修剪后,出现了 weight_mask 掩模矩阵,如下:

其中,0代表修剪,1代表不修剪;或者说,0代表冗余参数,1代表保留的重要参数;
实际上,剪枝 = 掩模矩阵(weight_mask) + 原矩阵(weight_orig)
准确地说是“按位与”,我们可以通过weight属性来查看修剪后的数值变化,这样就可以体会到weight_mask存在的意义。🌝
修剪完 conv1 层的 weight 以后,我们尝试一下修卷积层的 bias 参数:
prune.random_unstructured(module=conv1, name='bias', amount=0.3)同样,在 conv1 层中的 bias 被替换为了 bias_orig,仅仅只是名称发生了改变,数值没有变化。但通过查看缓冲区,可以得到 bias_mask 矩阵,代表第3和第5个位置的参数被判定为冗余参数,需要修剪。
# 剪枝前:
('bias', Parameter containing:
tensor([ 0.0007, -0.1844, -0.2432, -0.3038, -0.2903, -0.3091],
requires_grad=True))]
# 剪枝后:
('bias_orig', Parameter containing:
tensor([ 0.0007, -0.1844, -0.2432, -0.3038, -0.2903, -0.3091],
requires_grad=True))]
# 缓冲区:
[('bias_mask', tensor([1., 1., 0., 1., 1., 0.]))]但这样剪枝前后仅仅只是产生了对应的 mask 掩模矩阵,我们实际上希望的weight与bias并没有发生变化,那应该怎么办?
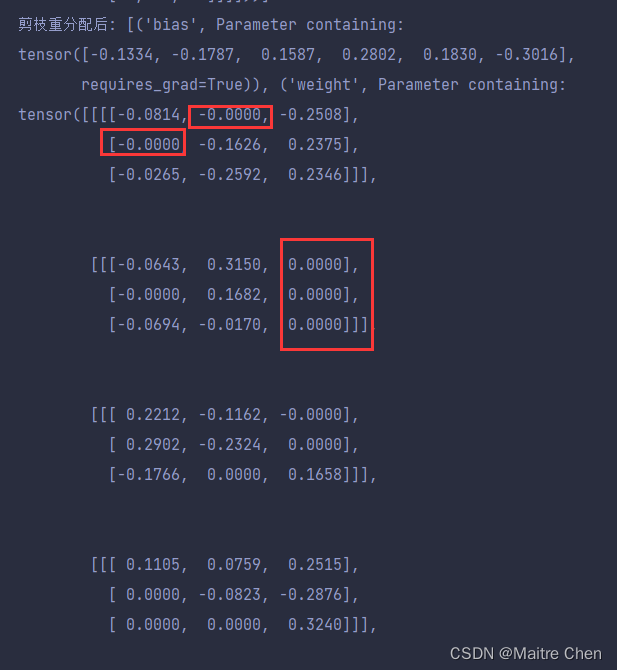
为了能够使剪枝永久化,可以采用remove将weight参数重新分配,这样就可以使得orig矩阵对应mask中为0的部分变成0。
接下来,我们通过打印输出观察一下:
参数化前:
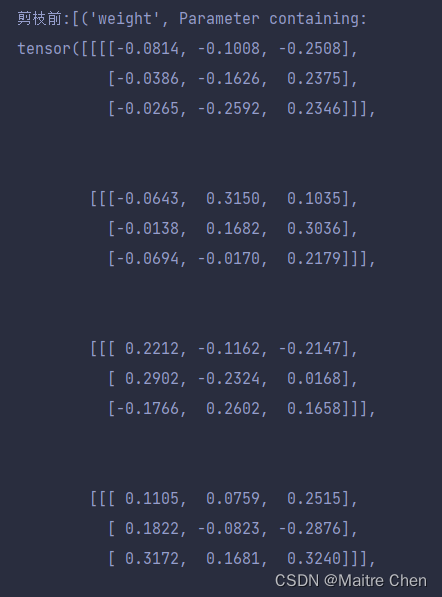
参数化后:
然而,就像在人生中随机偶遇一样,随机裁剪策略充满了不确定性。
有时候,这种策略可能无情地裁剪掉那些看似不重要但实际上非常关键的参数,就像误打误撞一样。所以说,这个策略在一般情况下的准确性并不是那么高。
我们需要更加可观的评价准则,就像在面试中被问到自己的优势一样,我们不能完全依赖运气。比如,我们可以利用L1/L2范数来对参数进行评价,毕竟它们才是“评价专家”(这里说一般情况是因为在有些数据集以及模型上,随机裁剪效果反而会更好,这是一个比较迷糊的问题,有待商榷!)
4.1.2 基于l1范数的剪枝
使用非常便捷,但我们需要简单了解L1范数。
prune.l1_unstructured(moodule, name='weight', amount=0.3)🚩下面讲L1范数:
L1范数,指矩阵或向量中元素的绝对值之和。
对于向量:
对矩阵 :
这个范数的名称来自于曼哈顿的城市规划,所以L1范数也是曼哈顿距离,即从一个区域到另一个区域的距离是沿着矩形的边缘行走,而不是直线穿越。
在非结构化剪枝中,使用L1范数作为剪枝的依据时,我们实际上是在尝试最小化模型参数的L1范数。这使得许多参数变为零,从而实现了对模型的稀疏化。
4.2 结构化剪枝
4.2.1 随机剪枝
prune.random_structured(module=conv1, name='weight', amount=0.3, dim=0)从函数调用来看,结构化剪枝与非结构随机剪枝的区别在于,需要指定维度dim,这是一个关键点!
【解释】🪄
非结构化剪枝将权重矩阵视为一个扁平的向量,剪枝操作会在这个扁平向量上进行,即将其中一部分参数设置为零。而结构化剪枝是在特定维度剪枝,通常是输入通道、输出通道、过滤器等。
【举个栗子】🌰
我们将卷积层的权重矩阵视为立方体,假设该权重矩阵形状为(6, 1, 3, 3)。按照torch权重的形状格式
(out_channels, in_channels, kernel_height, kernel_width),分别代表输出通道、输入通道、卷积核高度、卷积核宽度,那么我们只有一个立方体,且长x宽x高为6x3x3。情况一:结构化剪枝
如果我们在
dim=0(即输出通道维度)上进行 50% 的结构化剪枝,那么每个输出通道将保留一半的卷积核。这意味着每个输出通道将减少一半的卷积核数量,形成一个更瘦长的立方体,尺寸变为:3x3x3;情况二:非结构化剪枝
如果我们使用非结构化剪枝进行 50% 的剪枝,那么整个权重矩阵被视为一个扁平的向量,其中有一半的参数将被剪枝,即被置为零。此时的权重矩阵形内部的一些参数被剪枝,形成了稀疏的区域,也就是我们的立方体内部雕去了一些块,变得空洞化了。
【总结】
结构化剪枝可以保持原来的形状与结构,只不过整体变小了;但非结构化剪枝从外观来看和原先是差不多的,但是内部结构改变了,也就是权重矩阵变得稀疏化了。
我们可以通过打印输出conv1剪枝后的参数做一个对比:
剪枝前:
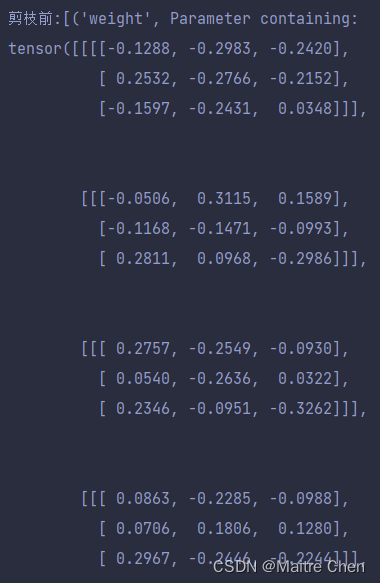
非结构化剪枝:
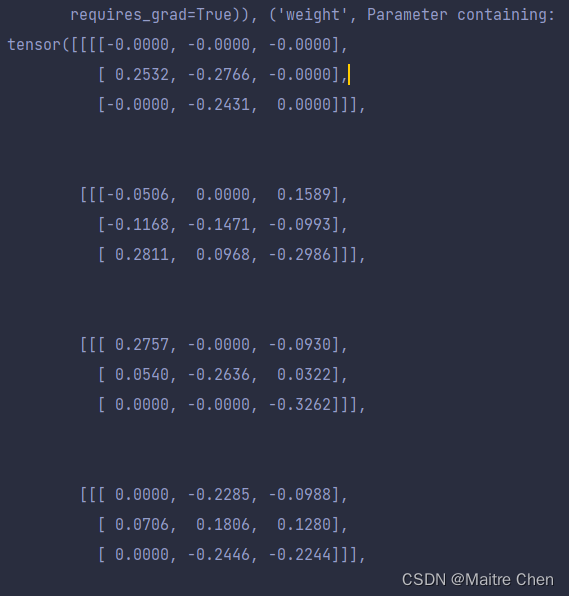
结构化剪枝:
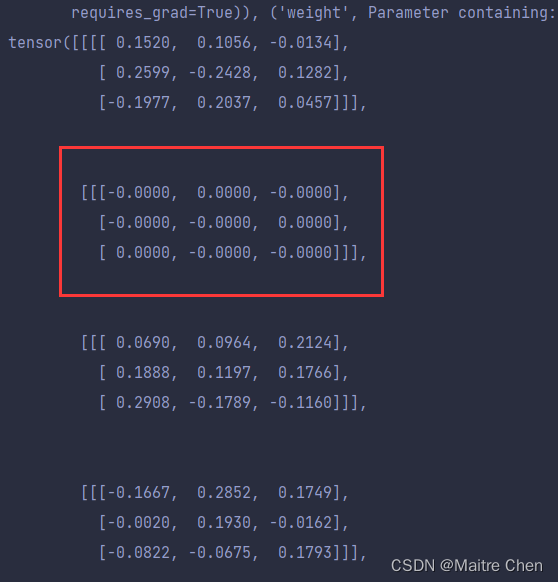
通过打印输出内部参数情况,我们可以清晰发现两者的区别:非结构化的确看上去是“东一处西一处”剪枝,而结构化体现出了整体性。
💥对非结构剪枝得到的模型不利于使用GPU加速的解释:
GPU中通常采用并行计算模式,在该模式下,GPU会同时对多个数据执行相同的指令,从而实现高度的并行性。当模型的权重矩阵是稠密的(即大部分元素都非零)时,GPU能够更有效地发挥作用,因为每个线程都在处理有意义的数据;当模型的权重矩阵被稀疏化,即大部分元素为零时,加速效果就会减弱。因为对于稀疏矩阵,许多线程会在处理零元素时浪费计算资源,这会导致计算效率的下降。
因此,结构化剪枝更有利于GPU加速计算,因为它保持了一定的稠密结构;非结构化剪枝导致权重矩阵的稀疏性,降低了GPU计算的效率。所以,在实际的模型剪枝中,我们一般会采用结构化剪枝。
4.2.2 基于Ln范数的剪枝
非结构化与结构化剪枝都有基于范数的剪枝,区别和上面随机剪枝中讲述的是一样的。
prune.ln_structured(module, name='weight', amount=0.5, n=2, dim=0) ln_structured参数解释:
module、name、amount在前面已经解释过;
n,指范数值,对于 L2 范数剪枝,n= 2;对于 L1 范数,n=1 ;
dim,指定剪枝维度,在这个例子中,代表对整个输出通道进行剪枝
对比L1范数与L2范数作出解释:
L1范数:定义为各个元素绝对值之和,即曼哈顿距离;
L2范数:定义为各个元素的平方和再开方,即欧氏距离;
L1和L2范数也常用于深度学习中的正则化,通过在损失函数中添加L1或L2范数项,惩罚模型的权重,使其趋向于较小的值,从而防止过拟合。而在剪枝中,L1范数和L2范数的概念被用于指导参数的稀疏化,即将一些参数变为零,以减少模型的复杂性。
4.3 其他剪枝策略
4.3.1 全局剪枝
局部剪枝仅仅修剪某一层的权重参数,而无法针对整个模型占比最低的权重参数进行修剪。
在全局剪枝时,我们可以将模型的每一层作为剪枝对象,让模型自动分析。
parameters_to_prune = (
(model.conv1, 'weight'),
(model.conv2, 'weight'),
(model.fc1, 'weight'),
(model.fc2, 'weight'),
(model.fc3, 'weight'),
)
prune.global_unstructured(parameters_to_prune, pruning_method=prune.L1Unstructured, amount=0.2)
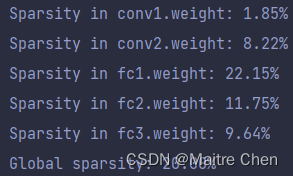
# 查看各层的剪枝情况
print("Sparsity in conv1.weight: {:.2f}%".format(
100 * float(torch.sum(model.conv1.weight == 0)) / float(model.conv1.weight.nelement())))
print("Sparsity in conv2.weight: {:.2f}%".format(
100 * float(torch.sum(model.conv2.weight == 0)) / float(model.conv2.weight.nelement())))
print("Sparsity in fc1.weight: {:.2f}%".format(
100 * float(torch.sum(model.fc1.weight == 0)) / float(model.fc1.weight.nelement())))
print("Sparsity in fc2.weight: {:.2f}%".format(
100 * float(torch.sum(model.fc2.weight == 0)) / float(model.fc2.weight.nelement())))
print("Sparsity in fc3.weight: {:.2f}%".format(
100 * float(torch.sum(model.fc3.weight == 0)) / float(model.fc3.weight.nelement())))
print(
"Global sparsity: {:.2f}%".format(
100 * float(
torch.sum(model.conv1.weight == 0)
+ torch.sum(model.conv2.weight == 0)
+ torch.sum(model.fc1.weight == 0)
+ torch.sum(model.fc2.weight == 0)
+ torch.sum(model.fc3.weight == 0)
)
/ float(
model.conv1.weight.nelement()
+ model.conv2.weight.nelement()
+ model.fc1.weight.nelement()
+ model.fc2.weight.nelement()
+ model.fc3.weight.nelement()
)
)
)每一层的稀疏比例与全局稀疏比例:
4.3.2 修剪多个参数
利用循环遍历整个模型,而非采用取出子模块的方式处理。(其实只是一个方便的表达而已~~)
# 对网络中的卷积层随机裁剪30%,裁剪全连接层60%
for name, module in model.named_modules():
if isinstance(module, torch.nn.Conv2d):
prune.random_unstructured(module, name='weight', amount=0.3)
elif isinstance(module, torch.nn.Linear):
prune.random_unstructured(module, name='weight', amount=0.6)5 小试🐂🔪之基于NNI的模型剪枝
安装参考NNI官方doc,实际上已经有详细的sample了,这儿只是笔者的笔记,感兴趣的小伙伴可以看看;
5.1 LeNet 剪枝流程
①定义config_list,包括稀疏度、待修剪层等;
config_list = [{
'sparsity_per_layer': 0.3,
'op_types': ['Linear', 'Conv2d']
}]②调用pruning api,这里基于L1范数评估,对通道进行剪枝
pruner = L1NormPruner(model, config_list)③压缩并生成掩模
_, masks = pruner.compress()④利用掩模和原模型进行加速(input为未封装的model)
pruner._unwrap_model()
ModelSpeedup(model, torch.rand(1, 1, 28, 28).to(‘cpu’), masks).speedup_model()⑤查看mask的稀疏程度
# show the masks sparsity
for name, mask in masks.items():
print(name, ' sparsity : ', '{:.2}'.format(mask['weight'].sum() / mask['weight'].numel()))5.2 LeNet 剪枝结果
5.2.1 模型结构
剪枝前:

剪枝与加速后:

5.2.2 计算量以及参数量
这里有多种方法可以查看,比如summary、summaryx、thop、ptflops,用法也比较容易。
# summary
from torchsummary import summary
summary(model,input_size=(1,28,28))
# pflops:
from ptflops import get_model_complexity_info
flops, params = get_model_complexity_info(model, dummy_input, as_strings=True, print_per_layer_stat=True)
print('flops: {:<8}'.format(flops))
print('parameters: {:<8}'.format(params))
# NNI自带的函数计算:
dummy_input = torch.randn([1, 1, 28, 28]).to(device)
flops, params, _ = count_flops_params(model, dummy_input, verbose=True)
print(f"Model FLOPs {flops / 1e6:.2f}M, Params {params / 1e6:.2f}M")剪枝前:
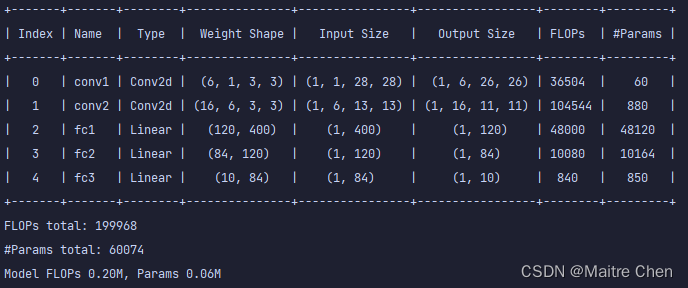
剪枝后:
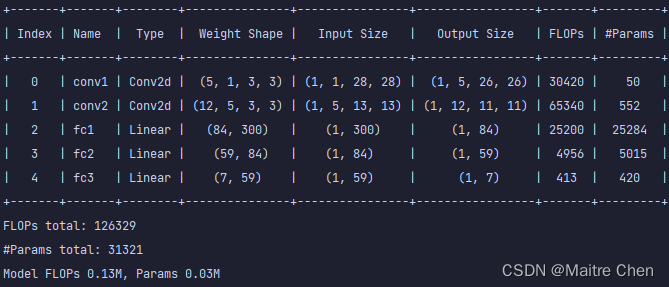
5.2.3 推理时延
创建输入实例、统计时延:
dummy_input = torch.randn([1, 1, 28, 28]).to(device)
t1 = time.time()
model(dummy_input)
t2 = time.time()
print('inference time: ', t2 - t1)下面指定不同的device进行测试:
GPU:
| 序号 | 剪枝前 | 剪枝后 |
|---|---|---|
| 1 | 0.8440 | 0.8439 |
| 2 | 0.8110 | 0.8380 |
| 3 | 0.8220 | 0.8890 |
CPU:
| 序号 | 剪枝前 | 剪枝后 |
|---|---|---|
| 1 | 0.0019 | 0.0009 |
| 2 | 0.0020 | 0.0019 |
| 3 | 0.0019 | 0.0020 |
由于模型本身较小,因此在GPU、CPU上的推理速度都没有明显的差异。
于是,增大batch,在CPU上进行推理测试,这里比较理想化,但为了对比明显,所以不成熟得疯狂增大batch~~
| batch | 剪枝前 | 剪枝后 |
|---|---|---|
| 1 | 0.009 | 0.009 |
| 2 | 0.009 | 0.010 |
| 2**3 | 0.009 | 0.009 |
| 2**4 | 0.009 | 0.009 |
| 2**6 | 0.020 | 0.009 |
| 2**7 | 0.014 | 0.009 |
| 2**10 | 0.049 | 0.019 |
| 2**14 | 0.775 | 0.331 |
| 2**18 | 69.536 | 7.031 |
为了获得在硬件上更加精确的效果,这里利用 openvino benchmark 进行测试。
测试插件:CPU
测试模型格式:FP32
python benchmark_app.py -m F:\AI\ML\workplace\model\result\ir_model\after\model_fp32.xml -api sync -nstreams 1 -i F:\AI\ML\workplace\MNIST\images\train231.jpg -b 32尝试不同batch
当batch = 1:
| 剪枝前 | 剪枝后 | |
|---|---|---|
| 1 | 0.09 | 0.08 |
| 2 | 0.09 | 0.09 |
| 3 | 0.09 | 0.09 |
当batch = 16:
| 剪枝前 | 剪枝后 | |
|---|---|---|
| 1 | 0.27 | 0.28 |
| 2 | 0.29 | 0.29 |
| 3 | 0.28 | 0.29 |
当batch = 32:
| 剪枝前 | 剪枝后 | |
|---|---|---|
| 1 | 0.37 | 0.39 |
| 2 | 0.41 | 0.37 |
| 3 | 0.40 | 0.40 |
| 4 | 0.45 | 0.46 |
综上实验:
-
在使用python推理一个输入实例时(四维张量),剪枝前后的时延明显减少;
-
使用openvino benchmark在不同的batch下,对剪枝前后的模型进行测试,时延几乎没有差异。
所以,openvino benchmark评估机制是什么?模型由pth→onnx→IR(xml & bin),是否在转换途中发生了变化?
首先利用IR文件,测试基于openvino进行实际推理的效果。
在使用Python进行推理时,同一模型的推理时延不稳定,变化较大(在0-10ms之间不断变化),这对比较剪枝前后的模型情况造成了困扰;而使用c++进行推理时,同一模型时延没有大幅变化,但剪枝前后的模型推理时延都在1、2ms之间徘徊,也没有明显的差异。所以IR模型推理失败!
再回首,基于大batch推理小模型推理时延下降才明显的假设,再一次测试python openvino推理效果。
| batch | 剪枝前 | 剪枝后 |
|---|---|---|
| 1 | 1.73 | 1.81 |
| 4 | 16.41 | 18.97 |
| 8 | 16.81 | 16.63 |
| 16 | 17.28 | 18.34 |
| 32 | 16.03 | 14.15 |
| 64 | 24.21 | 16.63 |
| 128 | 18.74 | 17.03 |
| 512 | 26.91 | 21.96 |
假设成立!因此,下方针对原模型pth格式以及onnx格式的推理也有了很好的解释,不再进行实验验证。
然后,对上一级格式onnx进行推理,使用 onnxruntime。
import onnxruntime
import cv2 as cv
import numpy as np
from torchvision import transforms as transforms
from time import time
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
def get_test_transform():
return transforms.ToTensor()
path1 = 'model.onnx'
path2 = 'pruned_model.onnx'
session = onnxruntime.InferenceSession(path1)
img_path = 'dataset/train28.jpg'
image = cv.imread(img_path, 0)
img = get_test_transform()(image)
img = img.unsqueeze_(0)
inputs = {session.get_inputs()[0].name: to_numpy(img)}
t1 = time()
outs = session.run(None, inputs)
t2 = time()
print("Inference time: ", t2 - t1)
max_num = np.max(outs)
class_idx = np.squeeze(np.argwhere(outs == max_num))[2]
print("The prediction number is:", class_idx)通过多次run,绝大多数情况下,剪枝前后的推理时延都为0ms,依然无果。
接下来,直接对纯天然pth模型进行实际推理。
import torch
import cv2 as cv
import numpy as np
from time import time
from torchvision import transforms as transforms
model = torch.load('./model/result/model.pth')
model.eval()
img_path = 'dataset/train28.jpg'
image = cv.imread(img_path, 0)
img = transforms.ToTensor()(image).to('cuda')
img = img.unsqueeze_(0)
# 取消backpropagation时的自动求导(不论requires_grad是否为true)
with torch.no_grad():
t1 = time()
output = model.forward(img)
t2 = time()
print("Inference time: ", t2 - t1)
outs = output.cpu().numpy()[0]
max_num = np.max(outs)
class_idx = np.squeeze(np.argwhere(outs == max_num))
print("The prediction number is:", class_idx)GPU:
| 剪枝前 | 剪枝后 | |
|---|---|---|
| 1 | 0.8600 | 0.8480 |
| 2 | 0.8189 | 0.9059 |
| 3 | 0.8249 | 0.9190 |
CPU:
| 剪枝前 | 剪枝后 | |
|---|---|---|
| 1 | 0.0020 | 0.0019 |
| 2 | 0.0010 | 0.0009 |
| 3 | 0.0009 | 0.0009 |
不论是哪一个模型,采用各自的推理框架进行实际推理时,时延几乎没有差异,于是我又回到了openvino的IR文件。
在使用netron时,发现剪枝前后模型结构相同,仔细一想,模型结构一致是必然的,这里的剪枝仅仅是对channel 进行了裁剪,所以只有权重文件不同。可当我回头去看权重文件的时候,发现剪枝前后的size居然是一样的。用model optimizer再一次转换 onnx model后,我意识到了problem😅(剪枝后的模型大小没有变化,估计操作不当导致的~)
原先的模型:


隔多日再一次转换后:


重新测试,基于openvino的python与c++推理,剪枝前后推理时延依然不明显。
openvino benchmark测试:
batch = 1:
| 剪枝前 | 剪枝后 | |
|---|---|---|
| 1 | 0.05 | 0.05 |
| 2 | 0.05 | 0.06 |
| 3 | 0.05 | 0.06 |
batch = 8:
| 剪枝前 | 剪枝后 | |
|---|---|---|
| 1 | 0.16 | 0.15 |
| 2 | 0.16 | 0.16 |
| 3 | 0.17 | 0.15 |
batch =16:
| 剪枝前 | 剪枝后 | |
|---|---|---|
| 1 | 0.25 | 0.24 |
| 2 | 0.25 | 0.24 |
| 3 | 0.25 | 0.25 |
结论:只有对一个初始化输入实例进行模拟推理时,剪枝后的推理时延才有明显降低;而进行实际推理时,效果几乎不变。
思考:通道剪枝的优点就在于能对网络结构的一部分做剪枝,而不如非结构化剪枝,仅仅只是个别权重的裁剪,需要特殊库进行推理加速。通道剪枝以后,在不需要特殊库的情况下能够加速推理,而本次实验在使用原生态模型进行推理以及使用onnxruntime、openvino推理时,加速效果都不明显,一方面排除了模型格式转换中发生的错误,另一方面也证明了推理工具(onnxruntime、openvino)不存在问题。
而问题很有可能出在LeNet模型本身,由于模型较小,实际推理中的时延较低,接近0ms。因此,尽管剪枝前后模型大小减少为原来的一半,但实际推理性能并未有明显的改善。当然,LeNet只是一个非常简单的模型,在实际需要剪枝的时候,模型往往遇到了内存占用较大、推理时延缓慢的问题,那么剪枝的意义就可以更好得体现了~~
5.2.4 精度
在剪枝过后,需要利用test评估模型精度。一旦精度下降较多,需要进行微调或重新训练。
微调,指在预训练模型的基础上加载参数再次训练,可以节省大量时间与内存消耗。
在执行test脚本时遇到了一个bug:
![]()
原因在于剪枝后的LeNet通道数发生了变化,在最后一层全连接层中,原本为10分类问题输出通道数为10,却被裁剪成了7,导致数值越界。所以剪枝后我们要注意模型结构的通道匹配问题,需要做调整或者对最后一层不做剪枝,都可以尝试。
因此,重新剪枝,这里只针对卷积层,按80%的比例基于L1范数裁剪:

剪枝后模型:

剪枝前精度:91%
![]()
剪枝后精度:77%
![]()
微调后精度:93%
![]()
可以看到,剪枝后的效果是很差的,但我们可以通过微调弥补精度损失,甚至比原先更好!或许,这就是剪枝的魅力~~
5 写在最后
我们可以把网络剪枝看成神经系统的减肥计划,去掉那些多余的神经元,让整个系统更精瘦、更灵活、表现更好!
对我们而言,剪枝相当于做减法,去掉那些多余的烦恼、复杂性,这样,我们的生活就会像一杯清爽的果汁,简单而美好!
因此,无论是神经网络,还是我们人类,减法都是提升性能的秘诀!让我们一同去寻找属于自己的减法,携手共创美好未来!

















 1464
1464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











