







目录
1 引言
1.1 MODNet 原理
基于卷积神经网络擅长处理单一任务的特性,MODNet 将人像抠图分解成了三个相关的子任务:语义估计(Semantic Estimation)、细节预测(Detail Prediction)、语义-细节融合(Semantic-Detail Fusion),分别对应着模型结构中 Low-Resolution Branch(LR-Branch)、High-Resolution Branch(HR-Branch)、Fusion Branch(F-Branch) 三个分支。其中,LR-Branch 用于人像整体轮廓的预测,HR-Branch 用于前景人像与背景过渡区域的细节预测, Fusion Branch 负责将前两部分预测得到的轮廓与边缘细节融合。语义估计部分是独立的分支,依赖于细节预测、语义-细节融合两个分支。
MODNet论文地址:https://arxiv.org/pdf/2011.11961.pdf
1.2 MODNet 模型分析
作为轻量化模型,MODNet 参数量仅6.45MB,但作为底层视觉任务,MODNet输入、输出分辨率一致,计算复杂度较高。笔者利用 NNI 分析了 MODNet 三个分支的参数量与计算量:
| MODNet分支 | 参数量(MB) | 计算量(GFLOPs) |
|---|---|---|
| LR-Branch | 6.16 | 5.03 |
| HR-Branch | 0.24 | 10.58 |
| F-Branch | 0.05 | 2.71 |
从计算量来看,MODNet 三个分支 LR-Branch、HR-Branch、F-Branch 分别占整个网络的27.7%、58.2%、14.1%。HR-Branch 作为高分辨率分支,相比其它两个分支的计算量较高,是剪枝重点关注的部分。
在实际剪枝时,由于 MODNet 内部包含了三个分支,直接剪枝较为复杂,因此对结构进行拆分。
接下来,是笔者对主干网络 MobileNetV2 部分的探索实验。
2 MobileNetV2 剪枝
2.1 剪枝过程
确定待剪枝的对象:
- Cov2d layer
- BatchNorm2d
- Linear
✨剪枝策略:基于L1范数结构化剪枝
model = MobileNetV2(3)
config_list = [{'sparsity': 0.8, 'op_types': ['Conv2d']}]
pruner = L1NormPruner(model, config_list)
_, masks = pruner.compress()
pruner._unwrap_model()
ModelSpeedup(model, torch.rand(1, 3, 512, 512), masks).speedup_model()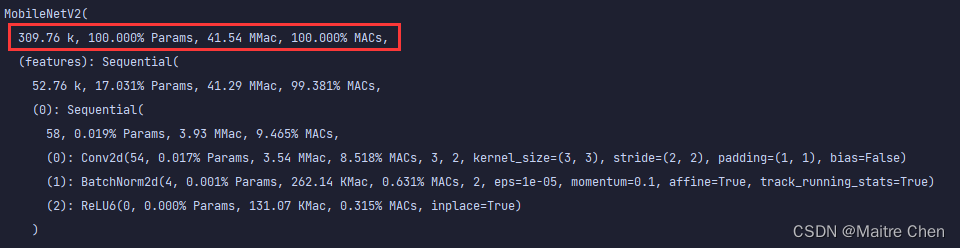
2.2 剪枝结果
参数量:3.5M → 309.76k
复杂度:1.67 GMac → 41.54 MMac
从参数量和计算复杂度来看,对MobileNetV2的剪枝可以明显压缩模型,下面具体来看网络结构、推理时延与精度。
2.2.1 网络结构
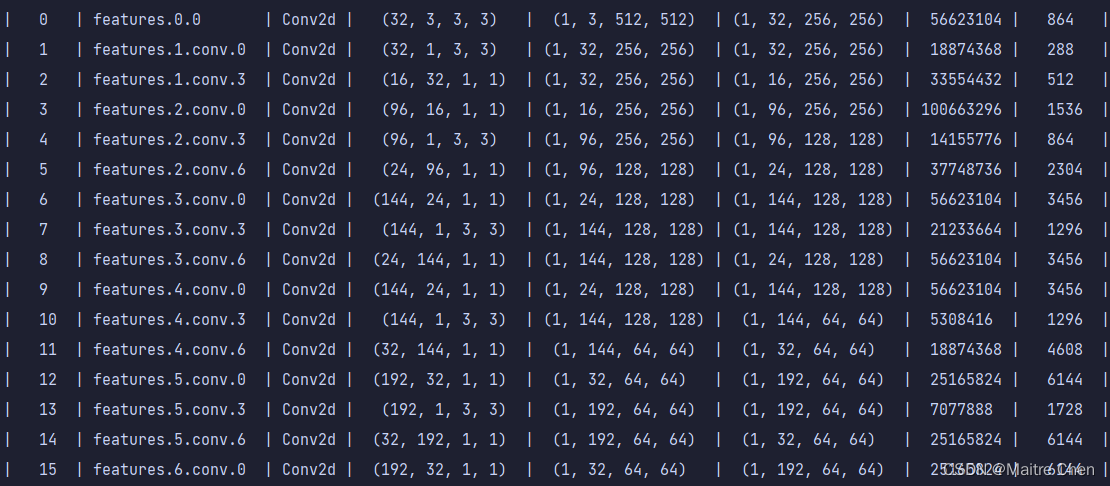
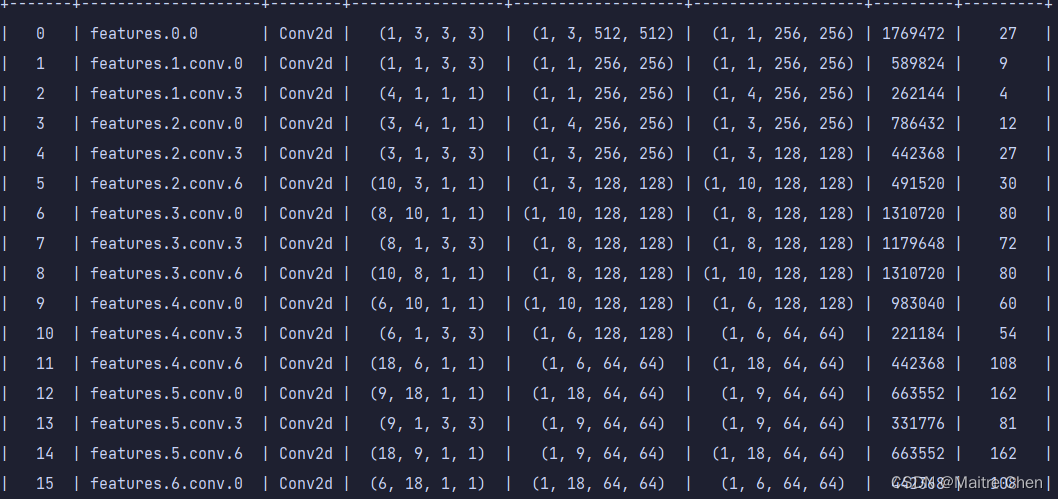
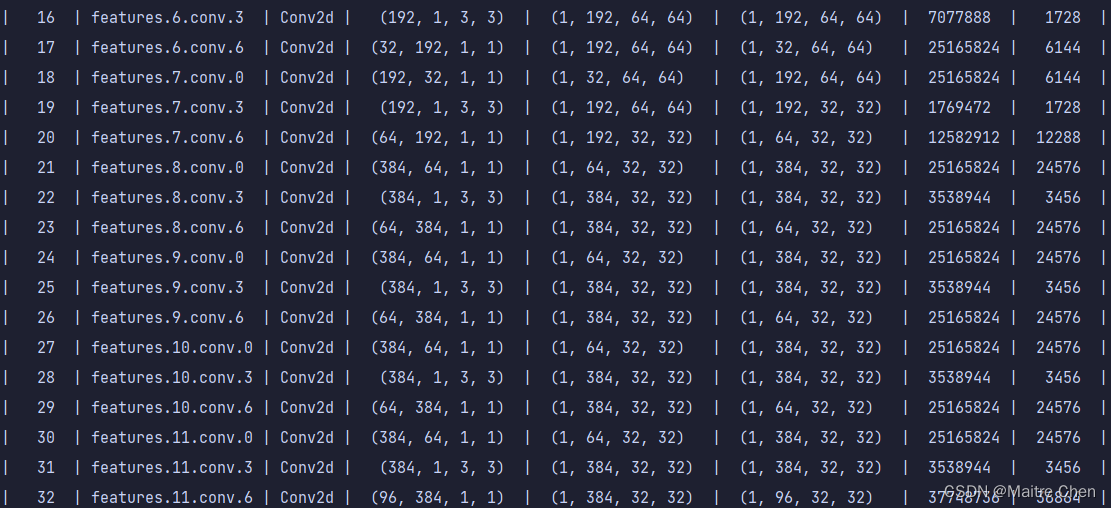
分别展示三组,A组、B组、C组分别代表MobileNetV2第0~15层、第16~32层、第33~52层。
A组剪枝前:
A组剪枝后:
B组剪枝前:
B组剪枝后:
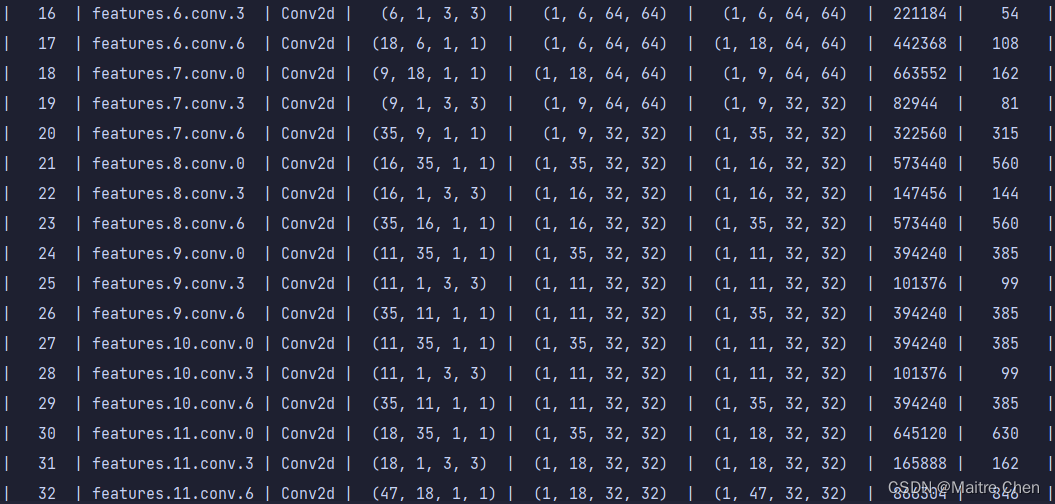
C组剪枝前:
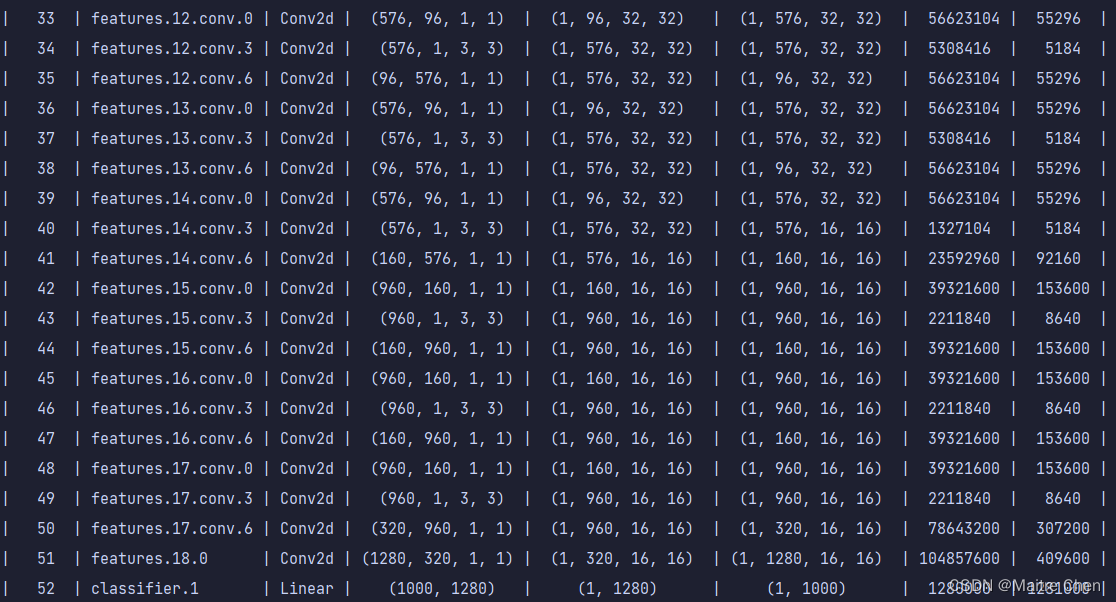
C组剪枝后:
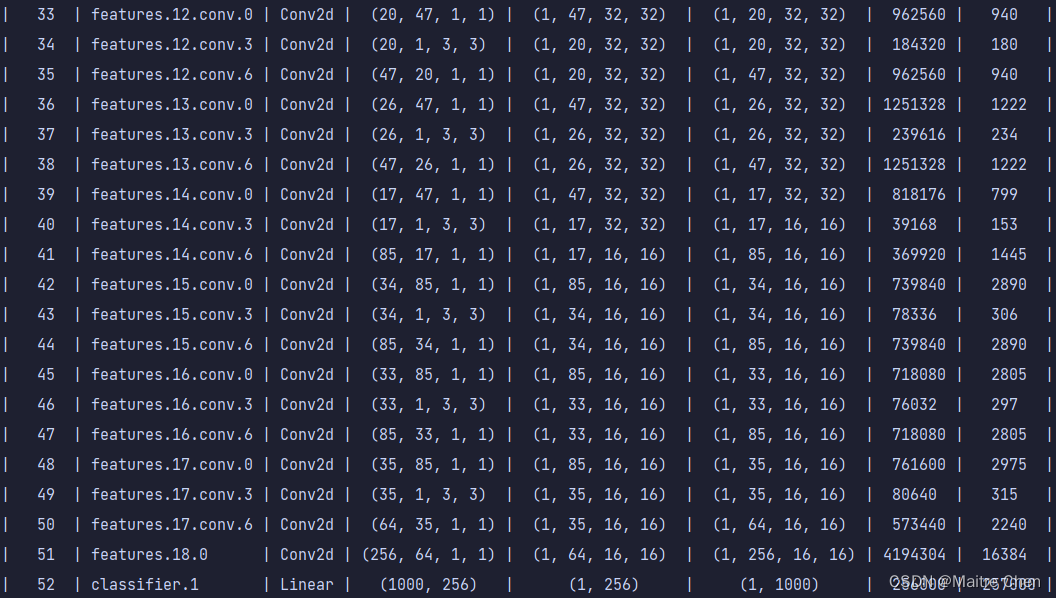
可以发现,不论是靠近模型输入端,还是输出端,卷积层都有大幅度的裁剪。
2.2.2 推理时延
使用PyTorch框架,分别在GPU与CPU上测试,结果如下。
GPU上
| 剪枝前 | 剪枝后 | |
|---|---|---|
| 1 | 0.9339 | 0.8370 |
| 2 | 0.9144 | 0.7980 |
| 3 | 0.9530 | 0.8759 |
CPU:
| 剪枝前 | 剪枝后 | |
|---|---|---|
| 1 | 0.3529 | 0.0609 |
| 2 | 0.3906 | 0.0549 |
| 3 | 0.3600 | 0.0520 |
第一次观察剪枝前、后的推理时延时,发现差距并不大。正在此时,笔者联想到前一秒的数据类型不一的报错:由于 dummy_input 转到了 CUDA 上,而 model 还是 CPU上 的 model,导致无法 run。于是笔者把 model 转到了cuda上。也正是在这个时候,笔者想到了推理硬件的问题:如果数据量本身就不大的时候,在 CUDA 上运行速度不一定比 CPU 快。数据如果要利用 GPU 计算,就需要从内存转移到显存上,数据传输具有很大开销,对于小规模数据来说,传输时间已经超过了 CPU 直接计算的时间。因此,规模小无法体现出 GPU 的优势,而大规模神经网络采用 GPU 加速意义较大,推理同样如此。
通过对MobileNetV2剪枝,我们可以发现:剪枝前、后的模型在 CPU 上的推理状况已经有了明显的差距,推理时延的降低达到了预期!!!
仔细看推理,dummy_input 初始化时涉及了batch,上述实验都是基于batch=1的情况。因此,接下来对剪枝前、后的模型,在不同的batch、在不同的硬件上推理进行对比。
CPU:
| batch | 剪枝前 | 剪枝后 |
|---|---|---|
| 1 | 0.30 | 0.07 |
| 2 | 0.64 | 0.07 |
| 4 | 1.14 | 0.18 |
| 8 | 2.22 | 0.25 |
| 16 | 4.33 | 0.39 |
| 32 | 11.76 | 0.78 |
| 64 | 66.45 | 1.49 |
GPU:
| batch | 剪枝前 | 剪枝后 |
|---|---|---|
| 1 | 0.81 | 0.77 |
| 2 | 0.90 | 0.79 |
| 4 | 0.95 | 0.76 |
| 8 | xxx | 0.83 |
| 16 | xxx | 0.91 |
| 32 | xxx | 0.97 |
| 64 | xxx | xxx |
2.3 实验结论
回首LeNet,不论是pth格式的PyTorch模拟推理还是实际推理,以及 ONNX、OpenVINO 推理,剪枝前、后的模型在 CPU 上的推理速度差异不明显就可以解释了,同时也验证了先前的猜想:LeNet 本身属于小规模网络,结构简单,推理速度已经很快了。因此,不论如何压缩模型,在batch较小的时候都无法有效降低推理时延。
另外,笔者总结了下列结论🎉:
当网络规模并非很大时,在CPU上推理比GPU更适合;(规模的阈值没有明确界限,需要尝试)
当 batch 逐渐增大时,剪枝后的模型推理速度占有绝对优势,且大模型优于小模型;
若要进行实时推理,保证较低的推理时延,batch 可以考虑设置为1;
相较于小模型,大模型剪枝在实际推理中更有意义;(LeNet剪枝前后batch为1时延不变,而mobilenetv2差异较大)
不仅仅是模型大小,数据本身也会影响推理速度;(推理小数据负担较小,所以在做模型压缩时,是否可以考虑前处理,例如图像压缩)
3 模型嵌入
3.1 模型保存与加载
PyTorch 模型的保存与读取方式有两种,接下来还是以 LeNet 为例,结构定义如下:
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, int(x.nelement() / x.shape[0]))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x法一:保存整个模型
model = LeNet()
torch.save(model,PATH)
# 直接加载,得到网络结构:
model = torch.load(PATH) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1972
1972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











