







1.模型剪枝
1.1什么是模型剪枝?
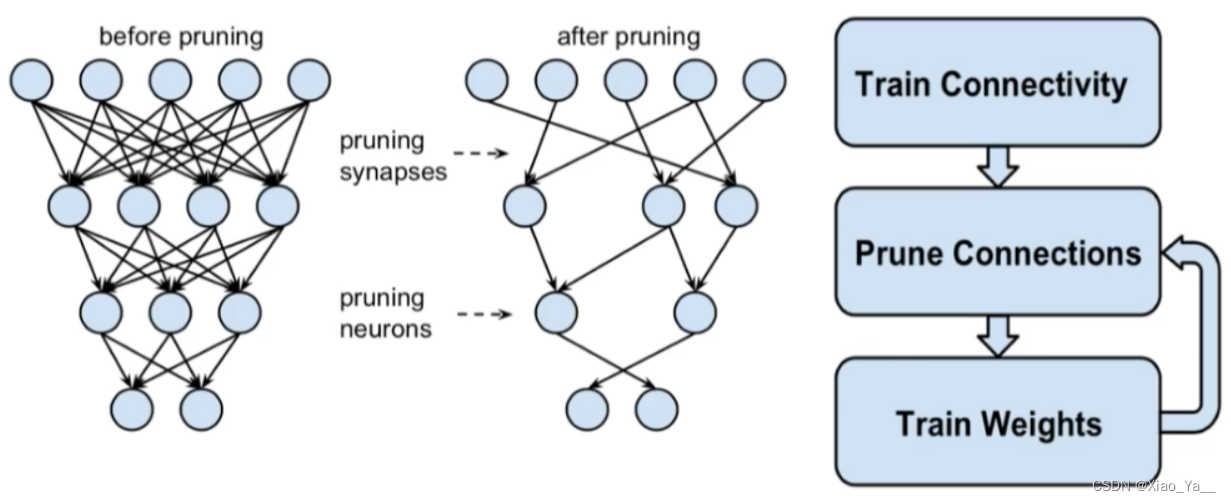
深度学习网络模型从卷积层到全连接层存在着大量冗余的参数,大量神经元激活值趋近于0,将这些神经元去除后可以表现出同样的模型表达能力,这种情况被称为过参数化,而对应的技术则被称为模型剪枝。(删除权重小于一定阈值的连接或者神经元节点得到更加稀疏的网络。)
1.2Dropout和DropConnect
模型剪枝主要分为结构化剪枝和非结构化剪枝,非结构化剪枝去除不重要的神经元,相应地,被剪除的神经元和其他神经元之间的连接在计算时会被忽略。由于剪枝后的模型通常很稀疏,并且破坏了原有模型的结构,所以这类方法被称为非结构化剪枝。非结构化剪枝能极大降低模型的参数量和理论计算量,但是现有硬件架构的计 算方式无法对其进行加速,所以在实际运行速度上得不到提升,需要设计特定的硬件才可能加速。与非结构化剪枝相对应的是结构化剪枝,结构化剪枝通常以滤波器或者整个网络层为基本单位进行剪枝。一个滤波器被剪枝,那么其前一个特征图和下一个特征图都会发生相应的变化,但是模型的结构却没有被破坏,仍然能够通过 GPU 或其他硬件来加速,因此这类方法被称之为结构化剪枝。
其实我们从学习深度学习的第一天起就接触过,Dropout和DropConnect代表着非常经典的模型剪枝技术,看下图:
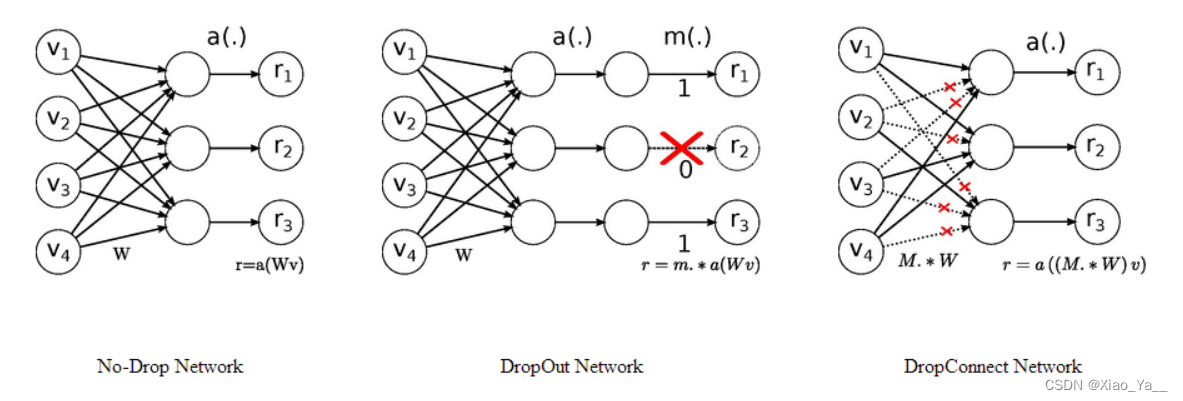
- Dropout 类似非结构化剪枝 剪去神经元
- DropConnect 类似结构化剪枝 (剪去连接)
1.2.1权重的冗余性
我们之所以能够对模型进行剪枝,本质上还是网络中的一些参数是冗余的,我们删除一些并不会对网络造成很大的影响,所以才可以去剪枝。
1.3 剪枝的不同粒度
模型剪枝不仅仅只有对神经元的剪枝和对权重连接的剪枝,根据粒度的不同,至少可以粗分为4个粒度。

细粒度剪枝(fine-grained):即对连接或者神经元进行剪枝,它是粒度最小的剪枝。
向量剪枝(vector-level):它相对于细粒度剪枝粒度更大,属于对卷积核内部(intra-kernel)的剪枝。
核剪枝(kernel-level):即去除某个卷积核,它将丢弃对输入通道中对应计算通道的响应。
滤波器剪枝(Filter-level):对整个卷积核组进行剪枝,会造成推理过程中输出特征通道数的改变。
细粒度剪枝(fine-grained),向量剪枝(vector-level),核剪枝(kernel-level)方法在参数量与模型性能之间取得了一定的平衡,但是网络的拓扑结构本身发生了变化,需要专门的算法设计来支持这种稀疏的运算,被称之为非结构化剪枝。
而滤波器剪枝(Filter-level)只改变了网络中的滤波器组和特征通道数目,所获得的模型不需要专门的算法设计就能够运行,被称为结构化剪枝。除此之外还有对整个网络层的剪枝,它可以被看作是滤波器剪枝(Filter-level)的变种,即所有的滤波器都丢弃。
1.4 模型剪枝的必要性
既然冗余性是存在的,那么剪枝自然有它的必要性,下面以Google的研究来说明这个问题。
Google在《To prune, or not to prune: exploring the efficacy of pruning for model compression》[1]中探讨了具有同等参数量的稀疏大模型和稠密小模型的性能对比,在图像和语音任务上表明稀疏大模型普遍有更好的性能。
它们对Inception V3模型进行了实验,在参数的稀疏性分别为0%,50%,75%,87.5%时,模型中非零参数分别是原始模型的1,0.5,0.25,0.128倍进行了实验。实验结果表明在稀疏性为50%时,Inception V3模型的性能几乎不变。稀疏性为87.5%时,在ImageNet上的分类指标下降为2%。
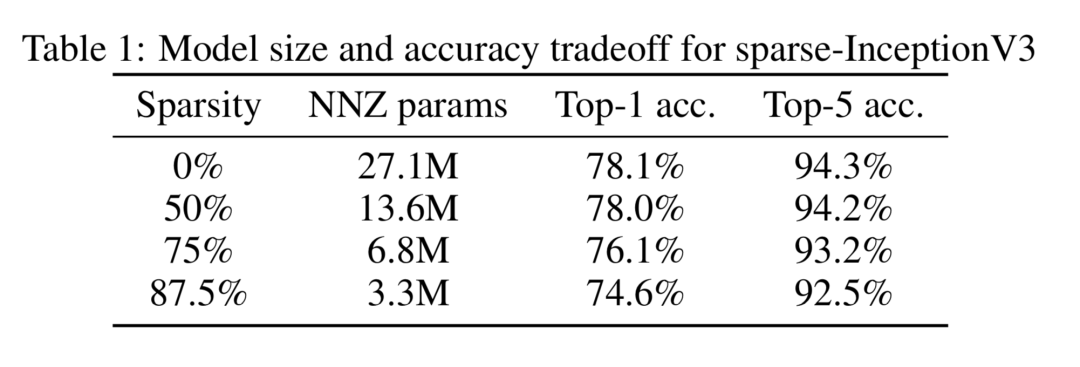
因此,我们完全可以相信,模型剪枝是有效的而且是必要的,剩下的问题就是怎么去找到冗余的参数进行剪枝。
1.5非结构化剪枝
1.5.1基本方法
根据连接的重要性判断是否裁剪掉连接
- 1.神经元重要性判别
- 2.去除神经元
- 3.微调
- 4.继续剪枝(判断是否回到1)
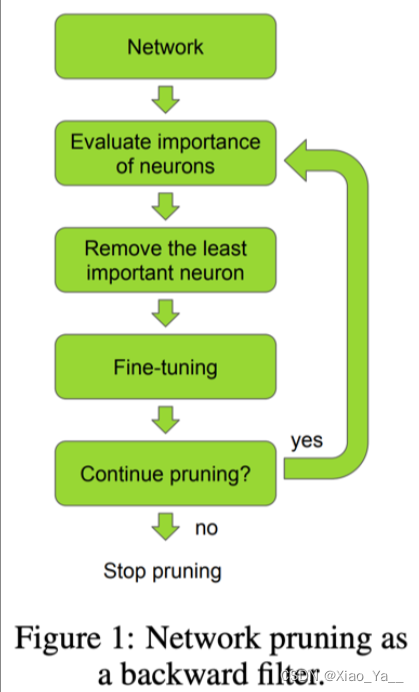
重要性程度就是其 L1或者L2 范数。
1.6结构化剪枝(幅度)
1.6.1基于权重大小的通道裁剪
基于权重的范数剪掉卷积核
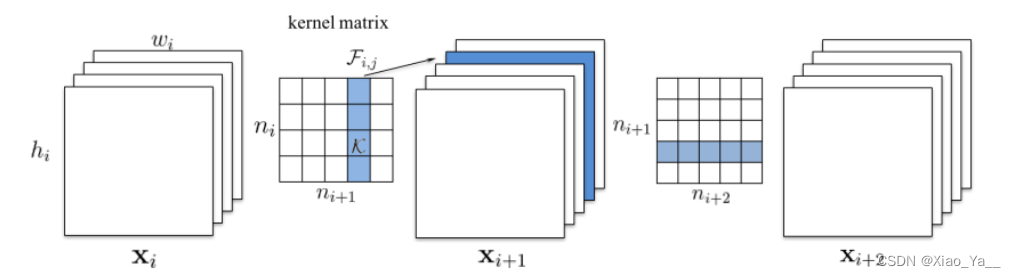
计算卷积核的绝对值和,进行排序,剪掉和最小的kernel以及对应的特征图Xi, Xi +1 和Xi+2 都是特征图。Kernel matrix 的共有n i ∗ n i + 1 个元素,每个元素是一个卷积核,Xi通道数是n i ,X i + 1 通道数是ni+1。
同时裁剪多个卷积核与通道
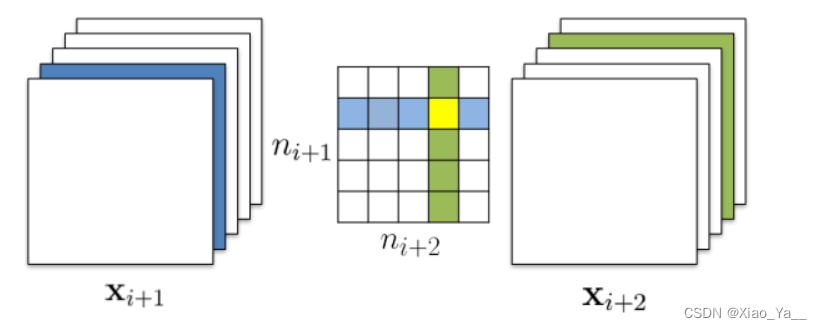
重叠部分分别考虑即可
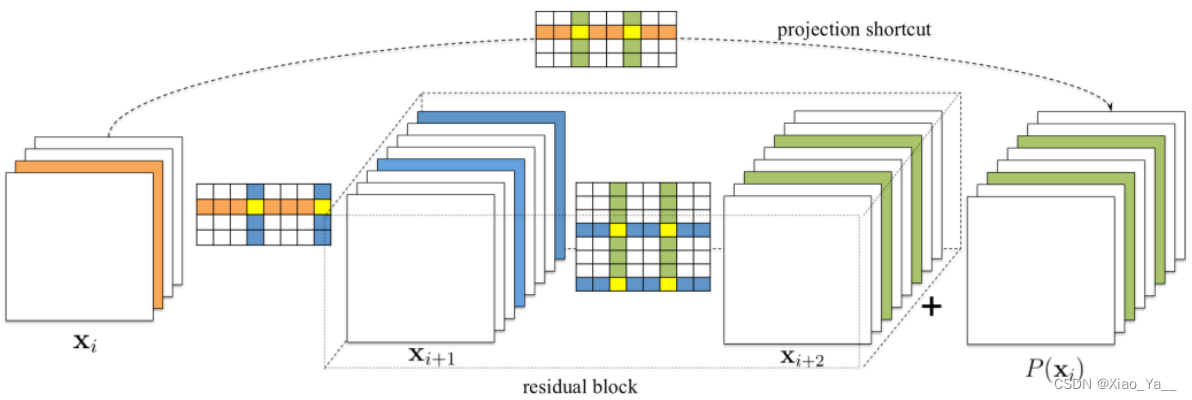 裁剪残差模块的通道,对应裁剪相同序号的恒等映射模块儿通道
裁剪残差模块的通道,对应裁剪相同序号的恒等映射模块儿通道
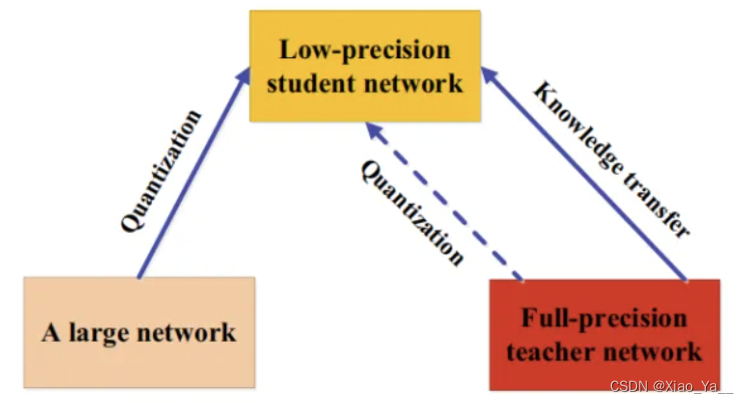
2.模型量化
2.1什么是模型量化
为了保证较高的精度,大部分的科学运算都是采用浮点型进行计算,常见的是32位浮点型和64位浮点型,即float32和double64。
对于深度学习模型来说,乘加计算量是非常大的,往往需要GPU等专用的计算平台才能实现实时运算,这对于端上产品来说是不可接受的,而模型量化是一个有效降低计算量的方法。
量化,即将网络的权值,激活值等从高精度转化成低精度的操作过程,例如将32位浮点数转化成8位整型数int8,同时我们期望转换后的模型准确率与转化前相近。
2.2模型量化的优势
模型量化可以带来几方面的优势,如下。
(1) 更小的模型尺寸。以8bit量化为例,与32bit浮点数相比,我们可以将模型的体积降低为原来的四分之一,这对于模型的存储和更新来说都更有优势。
(2) 更低的功耗。移动8bit数据与移动32bit浮点型数据相比,前者比后者高4倍的效率,而在一定程度上内存的使用量与功耗是成正比的。
(3) 更快的计算速度。相对于浮点数,大多数处理器都支持8bit数据的更快处理,如果是二值量化,则更有优势。
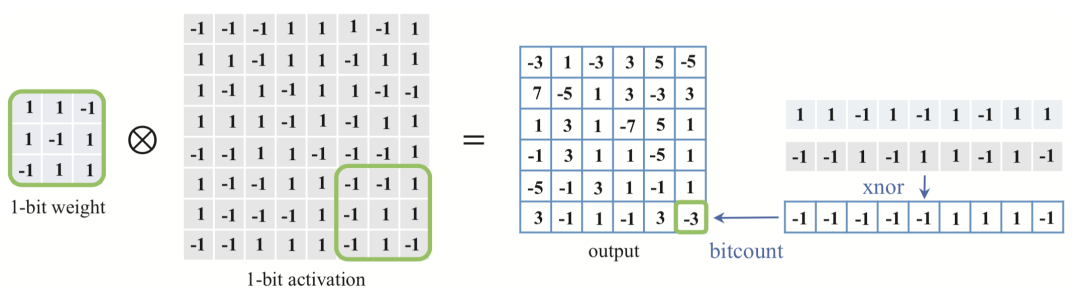
上图展示的是一个二值权重和激活值矩阵的运算,卷积过程中的乘加都可以转换为异或操作,并行程度更高,运算速度因此也更快。
3.知识蒸馏
3.1什么是知识蒸馏
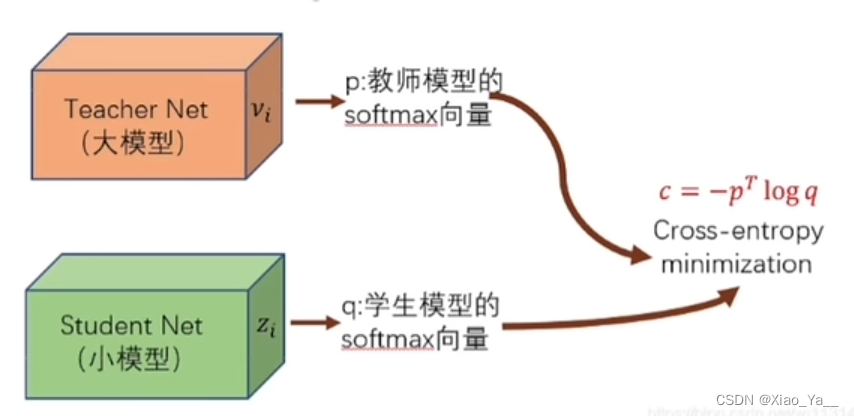
一般地,大模型往往是单个复杂网络或者是若干网络的集合,拥有良好的性能和泛化能力,而小模型因为网络规模较小,表达能力有限。利用大模型学习到的知识去指导小模型训练,使得小模型具有与大模型相当的性能,但是参数数量大幅降低,从而可以实现模型压缩与加速,就是知识蒸馏与迁移学习在模型优化中的应用。
Hinton等人最早在文章“Distilling the knowledge in a neural network”中提出了知识蒸馏这个概念,其核心思想是一旦复杂网络模型训练完成,便可以用另一种训练方法从复杂模型中提取出来更小的模型,因此知识蒸馏框架通常包含了一个大模型(被称为teacher模型),和一个小模型(被称为student模型)。
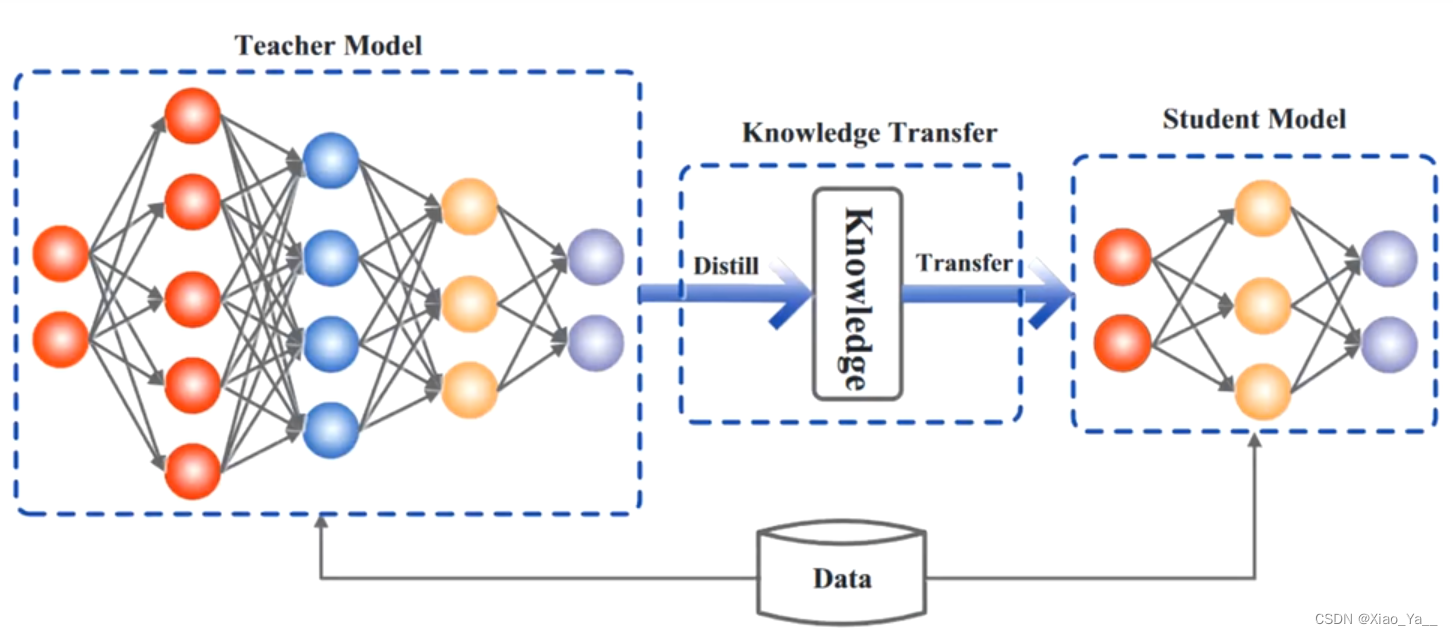
知识蒸馏(KD):该方法将知识从一个较大的深度神经网络中提取到一个较小的网络中
3.2知识(Knowledge)
在知识蒸馏中,知识类型、蒸馏策略和师生架构对学生模型的学习起着至关重要的作用。原始知识蒸馏使用大深度模型的对数作为教师知识(Hinton 2015),中间层的激活、神经元或特征也可以作为指导学生模型学习的知识,不同的激活、神经元或成对样本之间的关系包含了教师模型所学习到的丰富信息.此外,教师模型的参数(或层与层之间的联系)也包含了另一种知识,本节主要讨论以下几种类型的知识:基于响应的知识(response-based knowledge),基于特征的知识( feature-based knowledge), 基于关系的知识(relation-based knowledge),下图为教师模型中不同知识类别的直观示例。
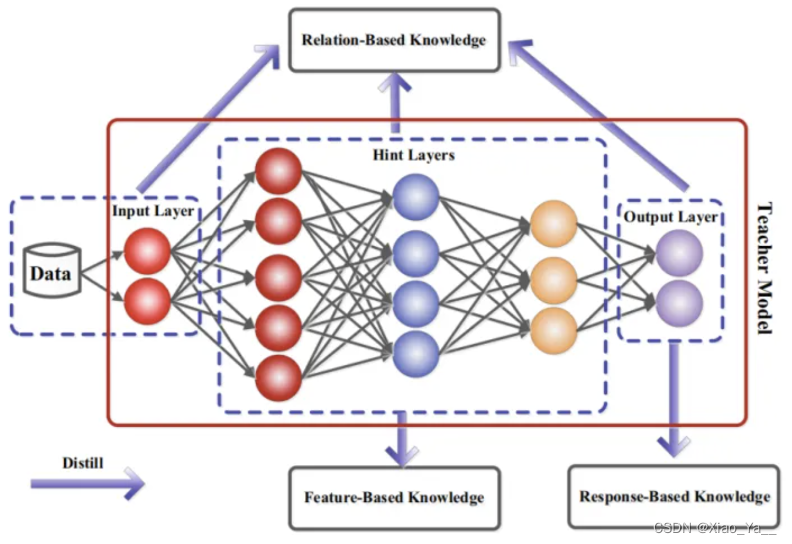
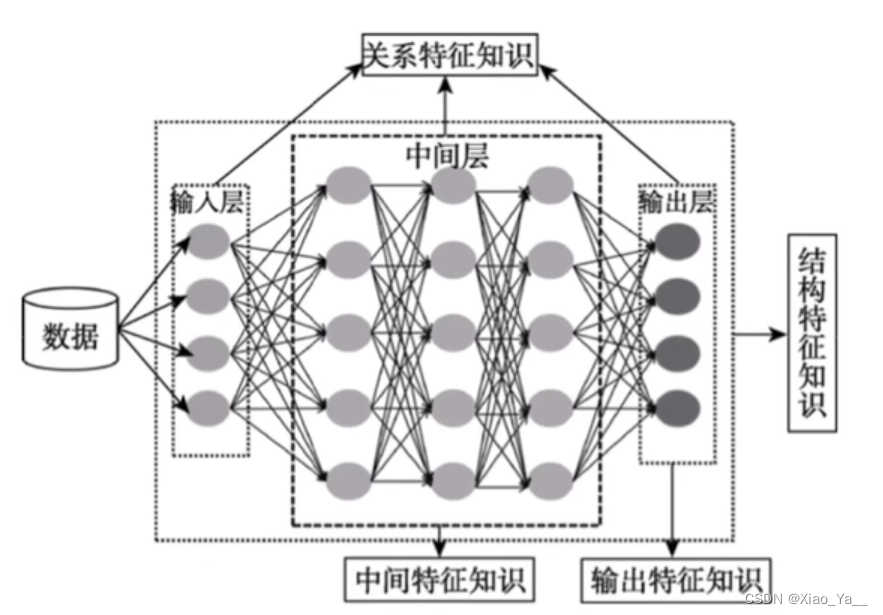
3.3蒸馏机制(Distillation Schemes)
根据教师模型是否与学生模型同时更新,知识蒸馏的学习方案可分为离线(offline distillation)蒸馏、在线(online distillation)蒸馏、自蒸馏(self-distillation)。
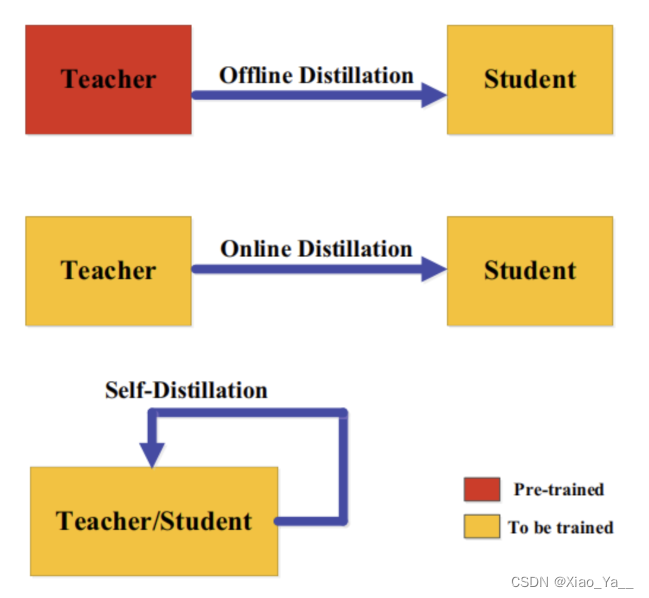
3.3.1离线蒸馏(offline distillation)
大多数之前的知识蒸馏方法都是离线的。最初的知识蒸馏中,知识从预训练的教师模型转移到学生模型中,整个训练过程包括两个阶段:
(1)大型教师模型蒸馏前在训练样本训练;
(2)教师模型以logits或中间特征的形式提取知识,将其在蒸馏过程中指导学生模型的训练。教师的结构是预定义的,很少关注教师模型的结构及其与学生模型的关系。因此,离线方法主要关注知识迁移的不同部分,包括知识设计、特征匹配或分布匹配的loss函数。离线方法的优点是简单、易于实现。
离线蒸馏方法通常采用单向的知识迁移和两阶段的训练程序。然而,训练时间长的、复杂的、高容量教师模型却无法避免,而在教师模型的指导下,离线蒸馏中的学生模型的训练通常是有效的。此外,教师与学生之间的能力差距始终存在,而且学生往往对教师有极大依赖。
3.3.2在线蒸馏(online distillation)
为了克服离线蒸馏的局限性,提出了在线蒸馏来进一步提高学生模型的性能,特别是在没有大容量高性能教师模型的情况下。在线蒸馏时,教师模型和学生模型同步更新,而整个知识蒸馏框架都是端到端可训练的。
在线蒸馏是一种具有高效并行计算的单阶段端到端训练方案。然而,现有的在线方法(如相互学习)通常无法解决在线环境中的高容量教师,这使进一步探索在线环境中教师和学生模式之间的关系成为一个有趣的话题。
3.3.3自蒸馏(self-distillation)
在自蒸馏中,教师和学生模型使用相同的网络,这可以看作是在线蒸馏的一个特例。例如论文(Zhang, L., Song, J., Gao, A., Chen, J., Bao, C. & Ma, K. (2019b).Be your own teacher: Improve the performance of convolutional eural networks via self distillation. In ICCV.)将网络深层的知识蒸馏到浅层部分。
从人类师生学习的角度也可以直观地理解离线、在线和自蒸馏。离线蒸馏是指知识渊博的教师教授学生知识;在线蒸馏是指教师和学生一起学习;自我蒸馏是指学生自己学习知识。而且,就像人类学习的方式一样,这三种蒸馏由于其自身的优点,可以相互补充。
3.4教师-学生结构(Teacher-Student Architecture)
在知识蒸馏中,师生架构是形成知识转移的一般载体。换句话说,师生结构决定了学生模型提取教师模型中知识的质量,用人类学习过程来描述,就是我们希望学生获得一个不错的老师来获取知识。因此,在知识的提炼过程中,如何选择或设计合适的师生结构,是一个重要而又困难的问题。最近,在蒸馏过程中,教师和学生的模型设置几乎是固定不变的大小和结构,从而容易造成模型容量缺口。然而,如何特别设计教师和学生的体系结构,以及为什么他们的体系结构由这些模型设置决定,几乎是缺失的。两者之间模型的设置主要有以下关系:
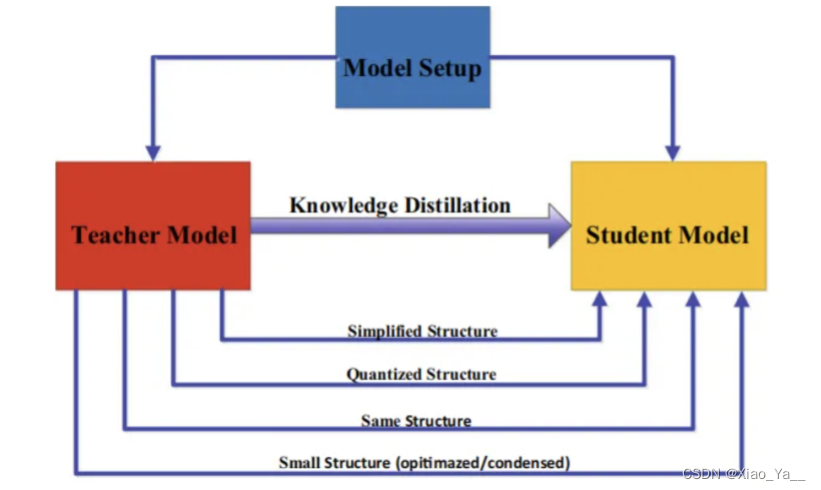
3.5蒸馏算法
一个简单但有效的知识迁移方法是直接匹配基于响应的、基于特征的或教师模型和学生模型之间的特征空间中的表示分布。许多不同的算法已经被提出,以改善在更复杂的环境中传递知识的过程。
3.5.1对抗性蒸馏(Adversarial Distillation)
在知识蒸馏中,教师模型很难学习到真实数据分布,同时,学生模型容量小,不能准确模仿教师模型。近年来,对抗训练在生成网络中取得了成功,生成对抗网络(GAN)中的鉴别器估计样本来自训练数据分布的概率,而生成器试图使用生成的数据样本欺骗鉴别器的概率预测。受此启发,许多对抗知识蒸馏方法被提出,以使教师和学生网络更好地了解真实的数据分布,如下图所示,对抗训练在知识蒸馏中的应用可以刚被分为三类。
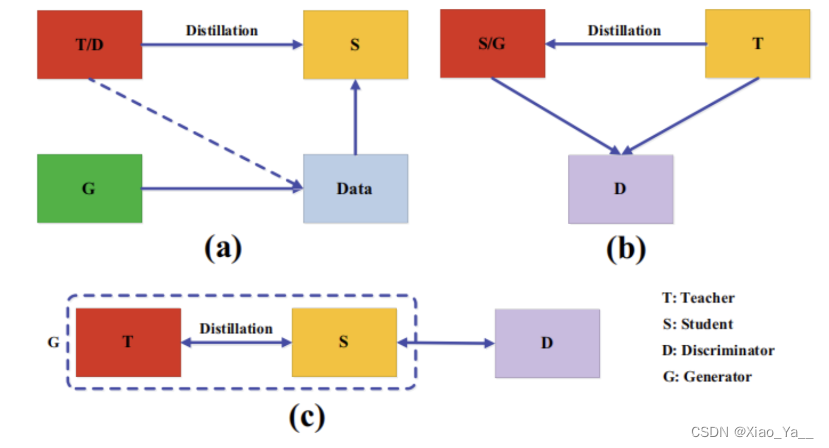
a)训练一个对抗性生成器生成合成的数据,将其直接作为训练集或用于增强训练集。
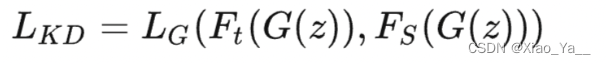
其中,Ft(.)和Fs(.)分别是教师模型和学生模型的输出;G(z)表示给定随机输入向量z的生成器G生成的训练样本;LG是蒸馏损失,以迫使预测的概率分布与真实概率分布之间匹配,蒸馏损失函数通常采用交叉熵或KL散度。
b)使用鉴别器,利用logits或特征来分辨样本来自教师或是学生模型。
代表性方法如论文(Wang, Y., Xu, C., Xu, C. & Tao, D. (2018f). Adversarial learning of portable student networks. In AAAI.),其loss可以表示为:
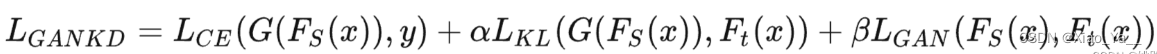
其中,G是一个学生网络,LGAN是生成对抗网络使用的损失函数,使学生和教师之间的输出尽可能相似。
c)在线方式进行,在每次迭代中,教师和学生共同进行优化。
利用知识蒸馏压缩GAN,小GAN学生网络通过知识迁移模仿大GAN教师网络。从上述对抗性蒸馏方法中,可以得出三个主要结论:
(1)GAN是通过教师知识迁移来提高学生学习能力的有效工具;
(2)联合GAN和知识蒸馏可以为知识蒸馏的性能生成有价值的数据,克服了不可用和不可访问的数据的限制;
(3)知识蒸馏可以用来压缩GAN。
3.5.2多教师蒸馏(Multi-teacher Distillation)
不同的教师架构可以为学生网络提供他们自己有用的知识。在训练一个教师网络期间,多个教师网络可以单独或整体地用于蒸馏。在一个典型的师生框架中,教师通常是一个大的模型或一个大的模型的集合。要迁移来自多个教师的知识,最简单的方法是使用来自所有教师的平均响应作为监督信息。多教师蒸馏的一般框架如下图所示:
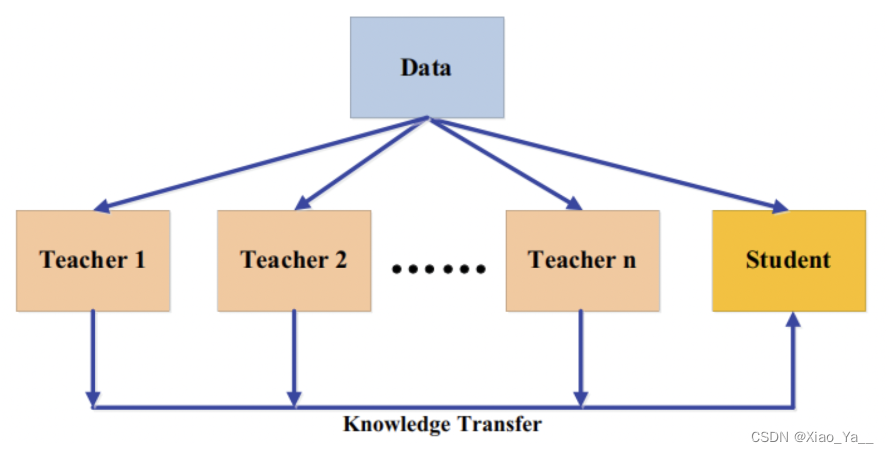 多个教师网络通常使用logits和特征表示作为知识。除了来自所有教师的平均logits,还有其他的变体。文献(Chen, X., Su, J., & Zhang, J. (2019b). A two-teacher tramework for knowledge distillation. In ISNN.)使用了两个教师网络,其中一名教师将基于响应的知识迁移给学生,另一名将基于特征的知识迁移给学生。文献(Fukuda, T., Suzuki, M., Kurata, G., Thomas, S., Cui, J. & Ramabhadran,B. (2017). Effificient knowledge distillation from an ensemble of teachers. In Interspeech.))在每次迭代中从教师网络池中随机选择一名教师。一般来说,多教师知识蒸馏可以提供丰富的知识,并能针对不同教师知识的多样性量身定制一个全方位的学生模型。然而,如何有效地整合来自多名教师的不同类型的知识,还需要进一步研究。
多个教师网络通常使用logits和特征表示作为知识。除了来自所有教师的平均logits,还有其他的变体。文献(Chen, X., Su, J., & Zhang, J. (2019b). A two-teacher tramework for knowledge distillation. In ISNN.)使用了两个教师网络,其中一名教师将基于响应的知识迁移给学生,另一名将基于特征的知识迁移给学生。文献(Fukuda, T., Suzuki, M., Kurata, G., Thomas, S., Cui, J. & Ramabhadran,B. (2017). Effificient knowledge distillation from an ensemble of teachers. In Interspeech.))在每次迭代中从教师网络池中随机选择一名教师。一般来说,多教师知识蒸馏可以提供丰富的知识,并能针对不同教师知识的多样性量身定制一个全方位的学生模型。然而,如何有效地整合来自多名教师的不同类型的知识,还需要进一步研究。
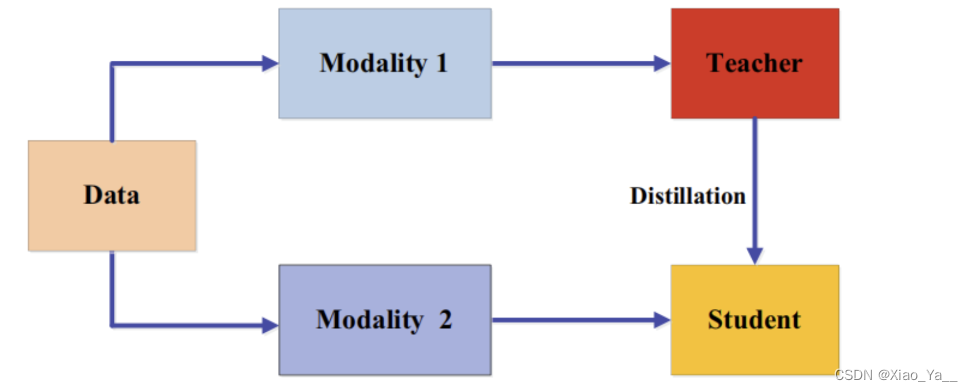
3.5.3跨模态蒸馏(Cross-Modal Distillation)
在训练或测试时一些模态的数据或标签可能不可用,因此需要在不同模态间知识迁移。在教师模型预先训练的一种模态(如RGB图像)上,有大量注释良好的数据样本,(Gupta, S., Hoffman, J. & Malik, J. (2016). Cross modal distillation for supervision transfer. In CVPR.)将知识从教师模型迁移到学生模型,使用新的未标记输入模态,如深度图像(depth image)和光流(optical flow)。具体来说,所提出的方法依赖于涉及两种模态的未标记成对样本,即RGB和深度图像。然后将教师从RGB图像中获得的特征用于对学生的监督训练。成对样本背后的思想是通过成对样本迁移标注(annotation)或标签信息,并已广泛应用于跨模态应用。成对样本的示例还有:
(1)在人类动作识别模型中,RGB视频和骨骼序列;
(2)在视觉问题回答方法中,将图像-问题-回答作为输入的三线性交互教师模型中的知识迁移到将图像-问题作为输入的双线性输入学生模型中。
跨模态蒸馏的框架如下:
3.5.4基于图的蒸馏(Graph-Based Distillation)
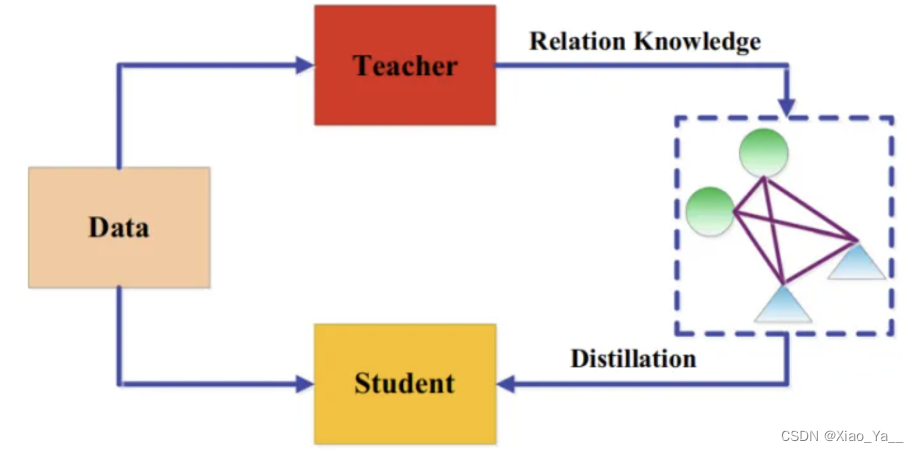
大多数知识蒸馏算法侧重于将个体实例知识从教师传递给学生,而最近提出了一些方法使用图来探索数据内关系。这些基于图的蒸馏方法的主要思想是:
(1)使用图作为教师知识的载体;
(2)使用图来控制教师知识的传递。基于图的知识可以归类为基于关系的知识。基于图的知识蒸馏如下图所示:
1)使用图作为教师知识的载体
文献(Zhang, C. & Peng, Y. (2018). Better and faster: knowledge transfer from multiple self-supervised learning tasks via graph distillation for video classifification. In IJCAI)中,每个顶点表示一个自监督的教师,利用logits和中间特征构造两个图,将多个自监督的教师的知识转移给学校。
2)使用图来控制知识迁移
文献(Luo, Z., Hsieh, J. T., Jiang, L., Carlos Niebles, J.& Fei-Fei, L. (2018).Graph distillation for action detection with privileged http://modalities.In ECCV.)将模态差异纳入来自源领域的特权信息,特权信息。引入了一种有向图来探讨不同模态之间的关系。每个顶点表示一个模态,边表示一个模态和另一个模态之间的连接强度。
3.5.5基于注意力的蒸馏(Attention-Based Distillation)
注意力机制能够很好地反映神经网络中神经元的激活情况,因此在知识蒸馏中引入了注意力机制,提高了学生模型的性能。基于注意力机制的知识迁移的核心是定义注意力图,将特征嵌入神经网络的各个层次。也就是说,利用注意力图函数转移特征嵌入知识。
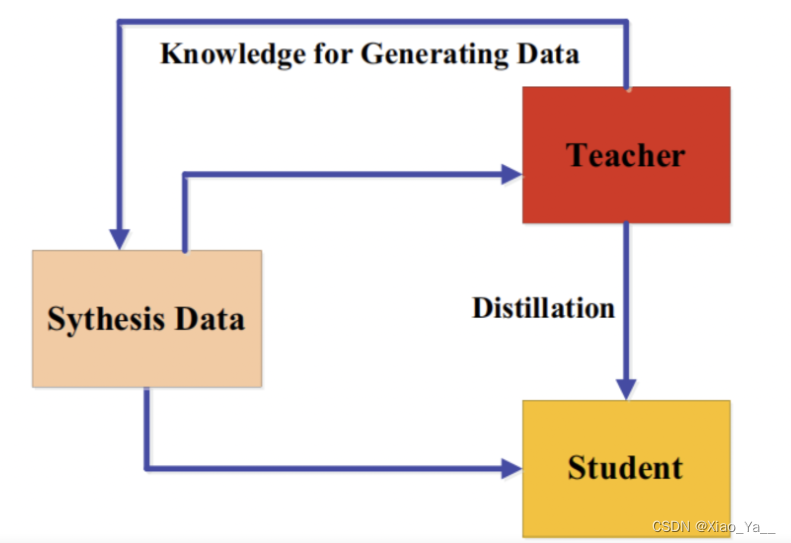
3.5.6无数据的蒸馏(Data-Free Distillation)
无数据蒸馏的方法提出的背景是克服由于隐私性、合法性、安全性和保密问题导致的数据缺失。“data free”表明并没有训练数据,数据是新生成或综合产生的。新生的数据可以利用GAN来产生。合成数据通常由预先训练过的教师模型的特征表示生成。
 3.5.7量化蒸馏(Quantized Distillation)
3.5.7量化蒸馏(Quantized Distillation)
网络量化通过将高精度网络(如32位浮点)转换为低精度网络(如2位和8位),降低了神经网络的计算复杂度。同时,知识蒸馏的目标是训练小模型,使其具有与复杂模型相当的性能。在师生框架下,利用量化过程提出了一些KD方法,如下图所示:
 3.5.8终身蒸馏(Lifelong Distillation)
3.5.8终身蒸馏(Lifelong Distillation)
终身学习包括持续学习、持续学习和元学习,旨在以与人相似的方式学习。它积累了以前学到的知识,并将所学到的知识转化为未来的学习,知识蒸馏提供了一种有效的方法来保存和转移学习到的知识,而不会造成灾难性的遗忘。最近,越来越多的KD变体被开发出来,它们是基于终身学习的。
3.5.9基于神经架构搜索的蒸馏(NAS-Based Distillation)
神经架构搜索(NAS),它是最流行的自动机器学习(或AutoML)之一,旨在自动识别深度神经模型和自适应学习合适的深度神经结构。在知识蒸馏中,知识转移的成功不仅取决于教师的知识,还取决于学生的架构。然而,大教师模式和小学生模式之间可能存在能力差距,使得学生很难从老师那里学得好。为了解决这一问题,采用神经结构搜索寻找合适的学生结构。
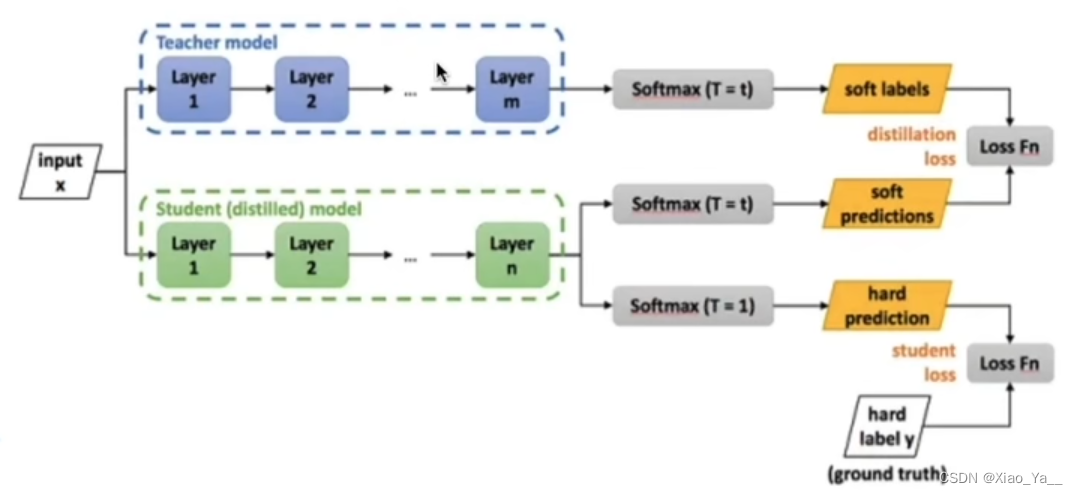
3.6蒸馏流程
step1:训练Teacher模型。
step2:利用高温T产生Soft-target,.用T=1产生Hard-target.
step3:利用{高温T,Soft-target}和T=1,Hard-target)同时训练Student模型。
step4:设置T=1,Student模型线上做推理。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









