







载入数据集
首先我们载入kaggle的数据集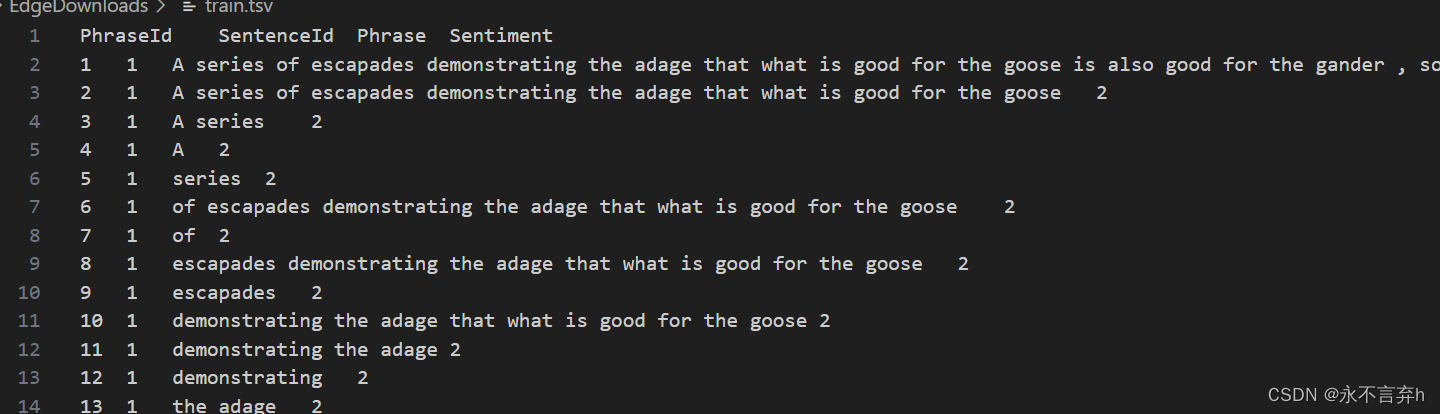
PhraseId为一个id,SentenceId为句子ID ,这里数据集,将一个句子分解开了,第一个为句子,后面的均是他的分解。
# 解压数据集
import zipfile
def extract_file(path):
with zipfile.ZipFile(path,'r') as zipref:
zipref.extractall('./data')
paths = [
'/kaggle/input/sentiment-analysis-on-movie-reviews/train.tsv.zip',
'/kaggle/input/sentiment-analysis-on-movie-reviews/test.tsv.zip',
]
_ = [extract_file(path) for path in paths]
然后我们只需要读入句子和情感标签即可
train_tsv =pd.read_csv('./data/train.tsv', sep='\t', header=0)
# train_tsv = pd.read_csv("/kaggle/working/data/train.tsv")
phrase = np.array(train_tsv["Phrase"])
sentiment = np.array(train_tsv["Sentiment"])
BOW特征工程
这里使用sklearn的CountVectorizer模型,将模型转换成一个np的矩阵。
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(stop_words='english', max_features=1000)
docs = phrase
# bag是一个稀疏的矩阵。因为词袋模型就是一种稀疏的表示。
bag = vectorizer .fit_transform(docs)
vocabulary = vectorizer.get_feature_names_out()
word_counts = bag.toarray()
划分数据集
这里将数据划分80%的训练集,20%测试集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(word_counts,sentiment, random_state=22,test_size=0.2)
训练
导入sklarn的LogisticRegression模型
# 损失函数: liblinear lbfgs newton-cg sag
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
classifier = LogisticRegression(solver="lbfgs",max_iter=500 )
classifier.fit(x_train, y_train)
y_pred = classifier.predict(x_test)
print(accuracy_score(y_pred,y_test))
结果精度只有0.58

提交
def submission(model,vectorizer):
test_csv =pd.read_csv('./data/test.tsv', sep='\t', header=0)
# phrase = np.array(test_csv["Phrase"])
X = vectorizer.fit_transform(test_csv["Phrase"].values.astype('U'))
y_pred = model.predict(X)
test_csv['Sentiment'] = pd.Series(y_pred)
submission = pd.concat([test_csv["Phrase"], test_csv['Sentiment']], axis=1)
submission.to_csv("submission.csv", index=False)
print("Done!!!!!!!!!!!!!!!!!!!!!!!!!!!")
submission(classifier,vectorizer)
只有0.488,太低了,接下来尝试深度学习词嵌入的方法。















 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









