







 本文档展示了使用 Python 和正则表达式从文本小说中提取章回目录和内容的过程。作者通过练习改善了代码,解决了章回内容错位的问题,并提供了多种输出方式。代码中定义了一个名为 `text_extract` 的函数,该函数接收正则表达式和小说文本,返回一个以章回为键、内容为值的字典。示例代码分别用于演示《稻草人》和《骆驼祥子》的章节提取。
本文档展示了使用 Python 和正则表达式从文本小说中提取章回目录和内容的过程。作者通过练习改善了代码,解决了章回内容错位的问题,并提供了多种输出方式。代码中定义了一个名为 `text_extract` 的函数,该函数接收正则表达式和小说文本,返回一个以章回为键、内容为值的字典。示例代码分别用于演示《稻草人》和《骆驼祥子》的章节提取。
Python 官网:https://www.python.org/
-
Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么简单……
自学并不是什么神秘的东西,一个人一辈子自学的时间总是比在学校学习的时间长,没有老师的时候总是比有老师的时候多。
—— 华罗庚

想法倒是简单:
先从小说文本提取章回目录,再依章回目录提取章回内容。前面我有做过 re 提取章回的练习:《re提取小说文本章回目录》 。
但学“艺”不精的我,代码实现起来就难了。反反复复尝试用列表和字符串方法,最终用字符串拆分方法str.split()以章回目录为阈值拆分小说文本,达到目的。👀👀

CSDN博文审核机制判定因涉及“版权不明”,有bug的运行效果截图,就只好撤下去咯。


非但是第一章没有写入,而且还张冠李戴,章回目录和内容“错位”。😭😭
被几行代码困久,“得意忘形”得错漏都被“无视”😛😛
更改代码,缩略试炼文本小说字符串,让代码理“简洁”。😜😜用了两种不同的输出调用工具模块函数。
运行效果

CSDN博文审核机制判定因涉及“版权不明”,运行效果截图,这张撤下去,修改试炼文本后重run效果图。
提取工具函数调用方式一——直接打印字典
# 稻草人试码
re_s = r'第\w*章\s?\w*' # re小说章回目录提取表达式。
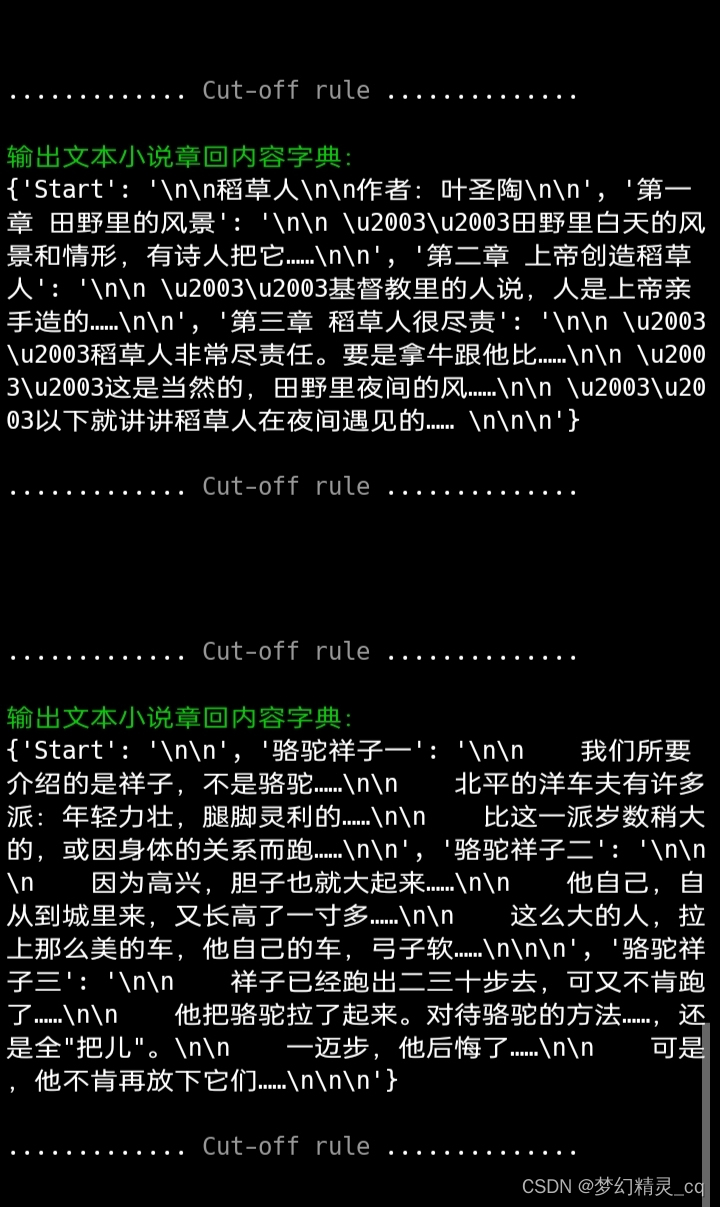
print(f"{cut_line()}{color(1, 'f_green')}输出文本小说章回内容字典:{color(0)}\n{text_extract(re_s, scarecrow)}{cut_line()}")
# 骆驼祥子试码
re_s = r'骆驼祥子\w?' # re小说章回目录提取表达式。
print(f"{cut_line()}{color(1, 'f_green')}输出文本小说章回内容字典:{color(0)}\n{text_extract(re_s, rickshaw_boy)}{cut_line()}")
提取工具函数调用方式二——打印字典keys
# 稻草人试码
re_s = r'第\w*章\s?\w*' # re小说章回目录提取表达式。
print(f"{cut_line()}{color(1, 'f_green')}输出文本小说章回内容字典keys:{color(0)}\n{list(text_extract(re_s, scarecrow).keys())}{cut_line()}")
# 骆驼祥子试码
re_s = r'骆驼祥子\w?' # re小说章回目录提取表达式。
print(f"{cut_line()}{color(1, 'f_green')}输出文本小说章回内容字典keys:{color(0)}\n{list(text_extract(re_s, rickshaw_boy).keys())}{cut_line()}")

提取工具函数调用方式三——按章回打印key -> value
# 稻草人试码
re_s = r'第\w*章\s?\w*' # re小说章回目录提取表达式。
print(f"{cut_line()}{color(1, 'f_green')}输出文本小说章回及内容:{color(0)}\n\n")
for key,value in text_extract(re_s, scarecrow).items():
print(f"§ {key} §\n{value}\n{'-'*50}\n\n")
print(cut_line())
# 骆驼祥子试码
re_s = r'骆驼祥子\w?' # re小说章回目录提取表达式。
print(f"{cut_line()}{color(1, 'f_green')}输出文本小说章回及内容:{color(0)}\n\n")
for key,value in text_extract(re_s, rickshaw_boy).items():
print(f"§ {key} §\n{value}\n{'-'*50}\n\n")
print(cut_line())

CSDN:此运行效果截图涉嫌“版权不明”违规,不宜展示。修改试炼文本,再上图。🤠

== 工具函数代码 ==
def text_extract(re_s, texts):
'''
提取.txt文本小说章回目录和章回内容,
返回以章回目录为key,章回内容为value的字典。
位置参数:
re_s -> 章回目录提取re表达式字符串
texts -> 待处理文本小说字符串
'''
texts_dict = {} # 初始化小说章回字典。
from re import findall # 从re模块加载findall方法。
contents = findall(re_s, texts) # 提取小说章回目录。
for k,content in enumerate(contents): # 枚举遍历提取章回目录列表。
tem = texts.split(content) # 以当前章回目录字符串拆分小说文本。
if k == 0: # 首章写入字典。
texts_dict['Start'] = tem[0] # 第一章回前面的内容写入字典。
texts = tem[1] # 待继续拆分文本赋值。
else: # 其她章回写入字典。
texts_dict[contents[k-1]] = tem[0]
texts = tem[1] # 待继续拆分文本赋值。
texts_dict[content] = texts # 最后一章写入字典。
return texts_dict # 返回小说章回内容字典。
一、《稻草人》
(此“稻草人”章回目录是我随意添加,为炼码成为,非原作者叶老先生原文,望阅者和叶老勿怪。) 稻草人 作者:叶圣陶 第一章 田野里的风景 第一自然段……… 第二章 上帝创造稻草人 第一自然段……… 第三章 稻草人很尽责 第一自然段……… 第二自然段……… 第三自然段………
二、《骆驼祥子》
骆驼祥子一
第一章回第一自然段……
第一章回第二自然段………
第一章回第三自然段………
骆驼祥子二
第二章回第一自然段………
第二章回第二自然段………
第二章回第三自然段………
骆驼祥子三
第三章回第一自然段………
他第三章回第二自然段。
第三章回第三自然段………
第三章回第四自然段………
CSDN博文审核机制判定因涉及“版权不明”,试码文本修改为每段落前面数字,以证“码”之功效。连这样子都仍“版权不明”,只好再改了。😭😭如来“真的”,请自行准备版权文本。
完整 Python 代码(完整代码为最后完成调试后的最终代码,前面贴出的代码是调试出功能就上传的,可能后来已作优化。完整代码中的对应部分,可能比前面贴出的“高级”哦。这是个人记笔记定CSDN博文的习惯所致,敬请谅解。)
我的解题思路,已融入代码注释,博文中就不再赘述。
(如果从语句注释不能清楚作用,请评论区留言指教和探讨。🤝)
#!/sur/bin/env python
# coding: utf-8
'''
filename: /sdcard/qpython/tem.py
梦幻精灵_cq的炼码场
'''
from mypythontools import TimeSpan, isprime,\
clear, wait, cut_line, color # 从自定,工具模块加载工具。
clear()
print(f"{cut_line()}{color(1, 'f_green')}{' 自制工具启动成功!':=^32}{color(0)}{cut_line()}")
def text_extract(re_s, texts):
'''
提取.txt文本小说章回目录和章回内容,
返回以章回目录为key,章回内容为value的字典。
位置参数:
re_s -> 章回目录提取re表达式字符串
texts -> 待处理文本小说字符串
'''
texts_dict = {} # 初始化小说章回字典。
from re import findall # 从re模块加载findall方法。
contents = findall(re_s, texts) # 提取小说章回目录。
for k,content in enumerate(contents): # 枚举遍历提取章回目录列表。
tem = texts.split(content) # 以当前章回目录字符串拆分小说文本。
if k == 0: # 首章写入字典。
texts_dict['Start'] = tem[0] # 第一章回前面的内容写入字典。
texts = tem[1] # 待继续拆分文本赋值。
else: # 其她章回写入字典。
texts_dict[contents[k-1]] = tem[0]
texts = tem[1] # 待继续拆分文本赋值。
texts_dict[content] = texts # 最后一章写入字典。
return texts_dict # 返回小说章回内容字典。
if __name__ == '__main__':
scarecrow = '''
《稻草人》节选并撰改
''' # 为简洁笔记代码,略去试炼文本,run码请加文本,望君知悉。
rickshaw_boy = '''
《骆驼祥子》节选
''' # 为简洁笔记代码,略去试炼文本,run码请加文本,望君知悉。
# 稻草人试码
re_s = r'第\w*章\s?\w*' # re小说章回目录提取表达式。
print(f"{cut_line()}{color(1, 'f_green')}输出文本小说章回及内容:{color(0)}\n\n")
for key,value in text_extract(re_s, scarecrow).items():
print(f"§ {key} §\n{value}\n{'-'*50}\n\n")
print(cut_line())
# 骆驼祥子试码
re_s = r'骆驼祥子\w?' # re小说章回目录提取表达式。
print(f"{cut_line()}{color(1, 'f_green')}输出文本小说章回及内容:{color(0)}\n\n")
for key,value in text_extract(re_s, rickshaw_boy).items():
print(f"§ {key} §\n{value}\n{'-'*50}\n\n")
print(cut_line())
wait(' Test re txt ... ')
相关练习笔记:
My Up and Down:
__上一篇:__ 朴实无华的四则混合运算计算器__下一篇:__ 小炼二维数组
我的HOT博:
- 练习:银行复利计算(用 for 循环解一道初中小题)(1021阅读)
- pandas 数据类型之 DataFrame(1124阅读)
- 班里有人和我同生日难吗?(概率probability、蒙特卡洛随机模拟法)(2014阅读)
- Python字符串居中显示(1337阅读)
- 练习:求偶数和、阈值分割和求差( list 对象的两个基础小题)(1573阅读)
- 用 pandas 解一道小题(1950阅读)
- 可迭代对象和四个函数(1061阅读)
- “快乐数”判断(1221阅读)
- 罗马数字转换器(构造元素取模)(1918阅读)
- Hot:罗马数字(转换器|罗生成器)(3168阅读)
- Hot:让QQ群昵称色变的代码(23035阅读)
- Hot:斐波那契数列(递归| for )(3773阅读)
- 柱状图中最大矩形(1638阅读)
- 排序数组元素的重复起止(1230阅读)
- 电话拨号键盘字母组合(1332阅读)
- 密码强度检测器(1774阅读)
- 求列表平衡点(1801阅读)
- Hot: 字符串统计(4019阅读)
- Hot:尼姆游戏(聪明版首发)(3399阅读)尼姆游戏(优化版)(962阅读)
推荐条件
点阅破千

精品文章:
- 好文力荐:《python 完全自学教程》齐伟书稿免费连载
- OPP三大特性:封装中的property
- 通过内置对象理解python'
- 正则表达式
- python中“*”的作用
- Python 完全自学手册
- 海象运算符
- Python中的 `!=`与`is not`不同
- 学习编程的正确方法
来源:老齐教室
Python 入门指南【Python 3.6.3】
好文力荐:
-
全栈领域优质创作者——寒佬(还是国内某高校学生)好文:《非技术文—关于英语和如何正确的提问》,“英语”和“会提问”是学习的两大利器。


















 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











