







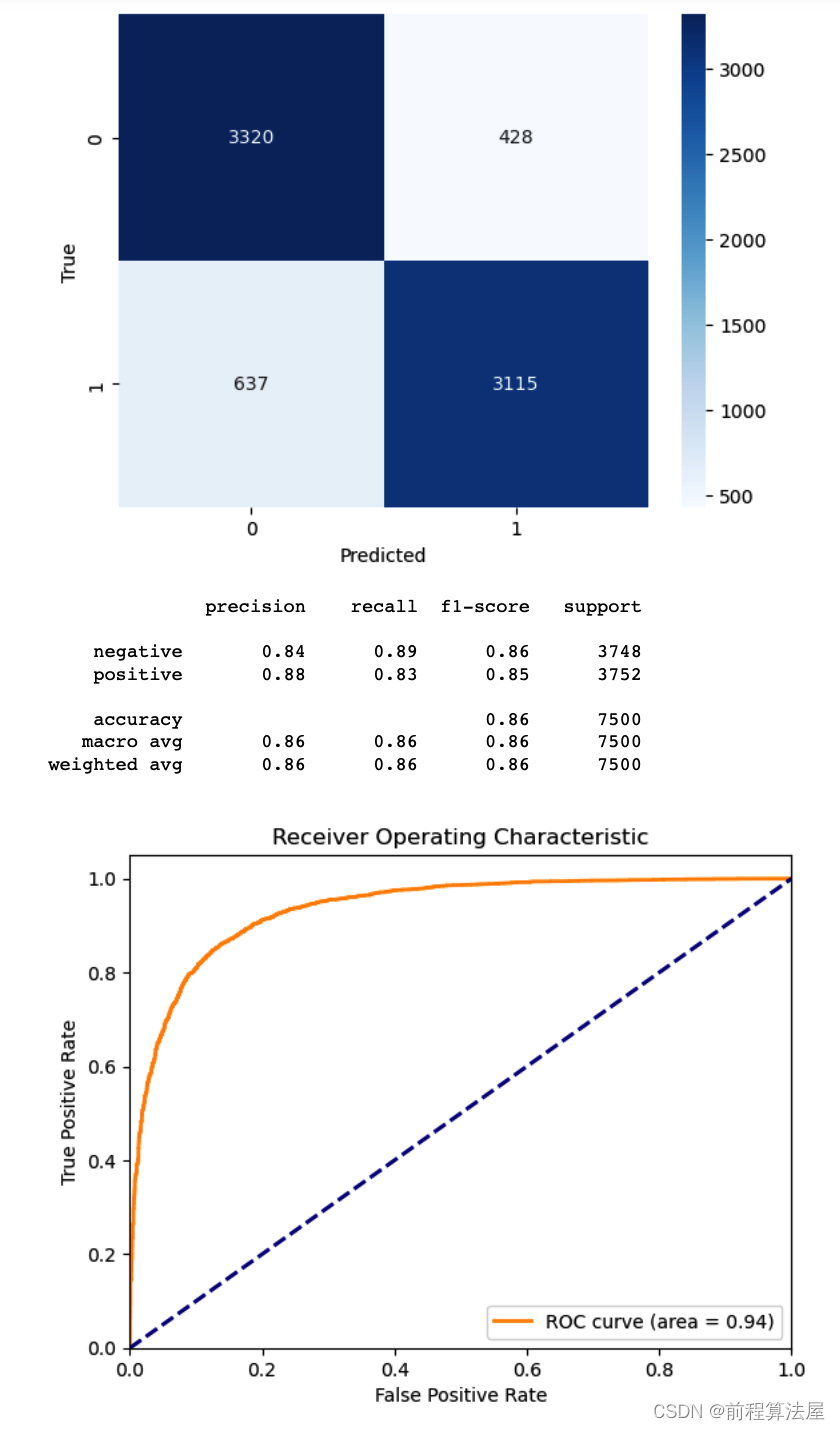
朴素贝叶斯算法是一种基于概率统计的分类算法。
它利用贝叶斯定理和特征条件独立假设来对样本进行分类。
该算法基于训练数据学习类别之间的概率分布,并根据新样本的特征计算其属于每个类别的概率,最终选择具有最高概率的类别作为预测结果。
朴素贝叶斯算法的基本原理可以简单地解释如下:
收集训练数据:首先,我们需要收集带有标签的训练数据集。这些数据应包含输入特征和对应的类别标签。
-
计算类别的先验概率:先验概率是指在未观测到任何特征信息时,每个类别出现的概率。通过计算每个类别在训练集中的出现频率,可以得到类别的先验概率。
-
计算特征的条件概率:对于每个输入特征,我们计算它在给定类别下的条件概率。这需要使用训练数据中某个类别下的特征值频率来估计概率分布。
-
根据贝叶斯定理计算后验概率:根据贝叶斯定理,我们可以计算给定输入特征情况下,样本属于每个类别的后验概率。这将用于最终的分类决策。
-
选择具有最高后验概率的类别:通过比较每个类别的后验概率,我们可以选择具有最高概率的类别作为最终的预测结果。
公式解释
朴素贝叶斯算法涉及到以下几个重要公式:
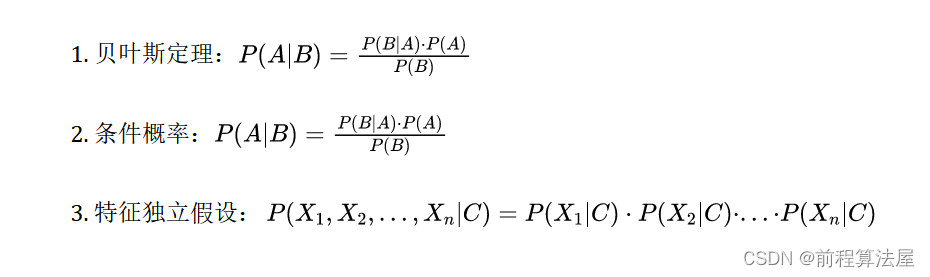
Python代码示例
假设我们有一个垃圾邮件分类的问题。我们收集了一个带有标签的训练数据集,其中包含垃圾邮件和非垃圾邮件的特征。

 订阅专栏 解锁全文
订阅专栏 解锁全文















 3977
3977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











