







✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,matlab项目合作可私信。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab完整代码及仿真定制内容点击👇
⛄ 内容介绍
在当今数据驱动的世界中,数据回归预测是一项重要的任务。它可以帮助我们预测未来的趋势和模式,为决策提供有力的支持。然而,由于数据的复杂性和噪声的存在,准确地进行回归预测并不容易。为了解决这个问题,研究人员提出了许多机器学习算法,并不断改进它们的性能。
极限学习机(ELM)是一种新兴的机器学习算法,它在回归预测任务中表现出色。ELM的核心思想是通过随机生成一组隐含层神经元的权重和偏置,将输入数据映射到隐含层。然后,通过线性回归方法将隐含层的输出与目标值进行拟合。ELM具有训练速度快、泛化能力强等优点,因此在实际应用中得到了广泛的应用。
然而,ELM算法在处理一些复杂的问题时仍然存在一些挑战。为了进一步提高ELM的性能,研究人员将其与优化算法相结合,以寻找最佳的权重和偏置。灰狼算法(GWO)是一种基于群体智能的优化算法,模拟了灰狼群体的行为。它通过模拟灰狼的捕食行为来寻找最优解。将GWO与ELM相结合,可以有效地优化ELM的性能,提高回归预测的准确性。
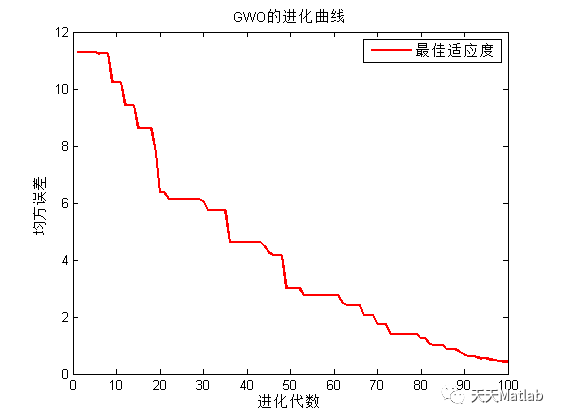
GWO-ELM算法的实现过程如下。首先,通过随机生成一组灰狼的位置和速度来初始化灰狼种群。然后,根据每个灰狼的适应度值,选择最优的灰狼作为领导者。接下来,通过模拟灰狼的捕食行为,更新灰狼的位置和速度。最后,使用更新后的灰狼位置和速度来优化ELM的权重和偏置。重复这个过程,直到达到预定的停止条件。
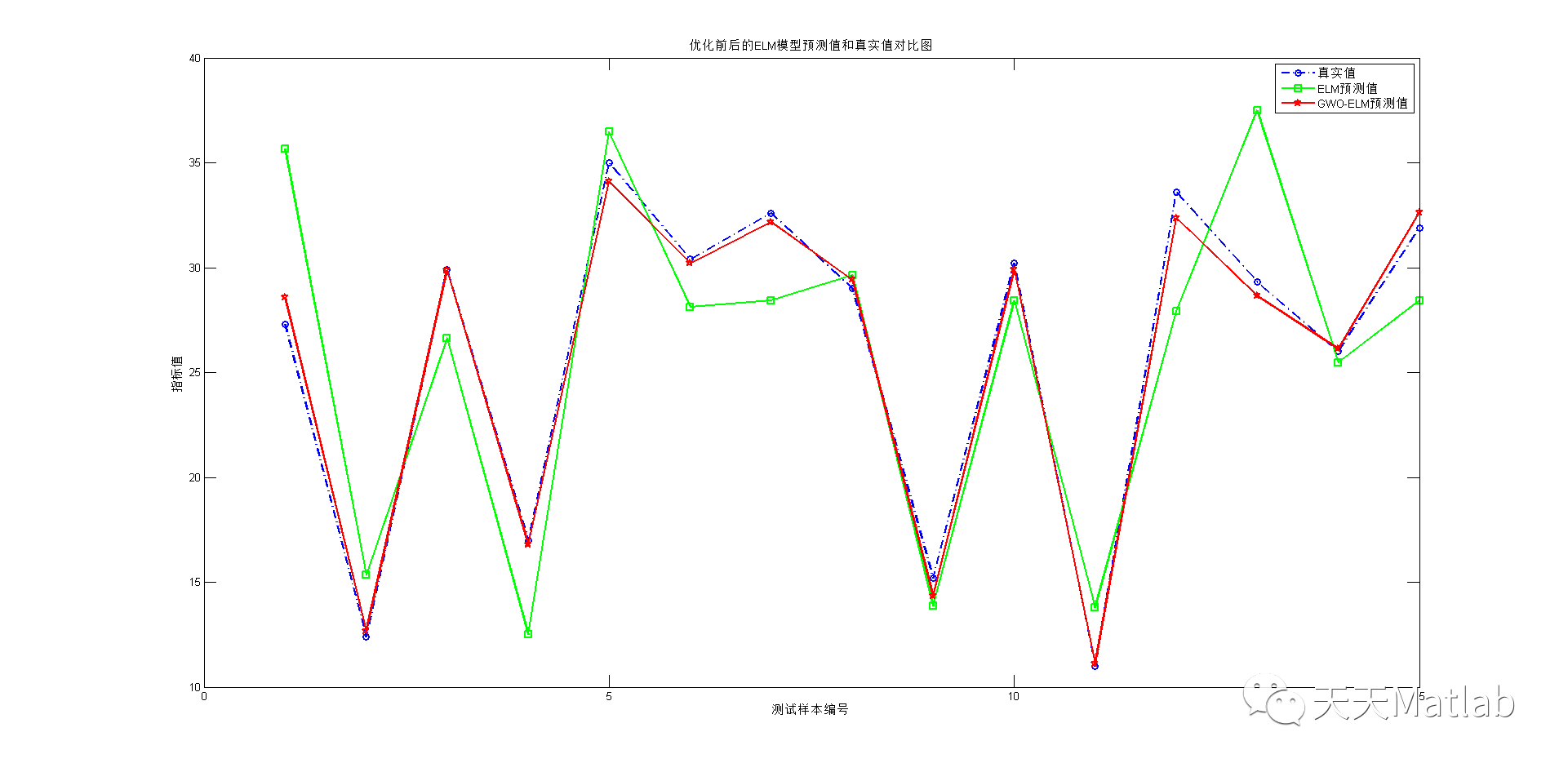
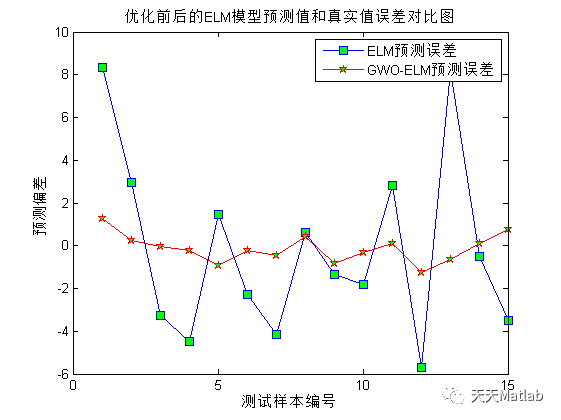
通过将GWO与ELM相结合,我们可以获得更好的回归预测结果。实验证明,GWO-ELM算法在多个数据集上的表现优于传统的ELM算法。它能够更好地适应复杂的数据模式,提高回归预测的准确性和稳定性。
总结起来,ELM回归预测是一项重要的任务,可以帮助我们预测未来的趋势和模式。为了提高ELM算法的性能,我们可以使用灰狼算法进行优化。GWO-ELM算法通过模拟灰狼的捕食行为,优化ELM的权重和偏置,从而提高回归预测的准确性。实验证明,GWO-ELM算法在多个数据集上表现优于传统的ELM算法。因此,GWO-ELM算法是一种值得尝试的方法,可以在实际应用中取得良好的效果。
希望通过本文的介绍,读者对于基于灰狼算法优化极限学习机GWO-ELM实现数据回归预测有了更深入的了解。在未来的研究和实践中,我们可以进一步探索和改进这个方法,以应对更加复杂的数据回归预测问题。
⛄ 部分代码
% BS2RV.m - Binary string to real vector%% This function decodes binary chromosomes into vectors of reals. The% chromosomes are seen as the concatenation of binary strings of given% length, and decoded into real numbers in a specified interval using% either standard binary or Gray decoding.%% Syntax: Phen = bs2rv(Chrom,FieldD)%% Input parameters:%% Chrom - Matrix containing the chromosomes of the current% population. Each line corresponds to one% individual's concatenated binary string% representation. Leftmost bits are MSb and% rightmost are LSb.%% FieldD - Matrix describing the length and how to decode% each substring in the chromosome. It has the% following structure:%% [len; (num)% lb; (num)% ub; (num)% code; (0=binary | 1=gray)% scale; (0=arithmetic | 1=logarithmic)% lbin; (0=excluded | 1=included)% ubin]; (0=excluded | 1=included)%% where% len - row vector containing the length of% each substring in Chrom. sum(len)% should equal the individual length.% lb,% ub - Lower and upper bounds for each% variable.% code - binary row vector indicating how each% substring is to be decoded.% scale - binary row vector indicating where to% use arithmetic and/or logarithmic% scaling.% lbin,% ubin - binary row vectors indicating whether% or not to include each bound in the% representation range%% Output parameter:%% Phen - Real matrix containing the population phenotypes.%% Author: Carlos Fonseca, Updated: Andrew Chipperfield% Date: 08/06/93, Date: 26-Jan-94function Phen = bs2rv(Chrom,FieldD)% Identify the population size (Nind)% and the chromosome length (Lind)[Nind,Lind] = size(Chrom);% Identify the number of decision variables (Nvar)[seven,Nvar] = size(FieldD);if seven ~= 7error('FieldD must have 7 rows.');end% Get substring propertieslen = FieldD(1,:);lb = FieldD(2,:);ub = FieldD(3,:);code = ~(~FieldD(4,:));scale = ~(~FieldD(5,:));lin = ~(~FieldD(6,:));uin = ~(~FieldD(7,:));% Check substring properties for consistencyif sum(len) ~= Lind,error('Data in FieldD must agree with chromosome length');endif ~all(lb(scale).*ub(scale)>0)error('Log-scaled variables must not include 0 in their range');end% Decode chromosomesPhen = zeros(Nind,Nvar);lf = cumsum(len);li = cumsum([1 len]);Prec = .5 .^ len;logsgn = sign(lb(scale));lb(scale) = log( abs(lb(scale)) );ub(scale) = log( abs(ub(scale)) );delta = ub - lb;Prec = .5 .^ len;num = (~lin) .* Prec;den = (lin + uin - 1) .* Prec;for i = 1:Nvar,idx = li(i):lf(i);if code(i) % Gray decodingChrom(:,idx)=rem(cumsum(Chrom(:,idx)')',2);endPhen(:,i) = Chrom(:,idx) * [ (.5).^(1:len(i))' ];Phen(:,i) = lb(i) + delta(i) * (Phen(:,i) + num(i)) ./ (1 - den(i));endexpand = ones(Nind,1);if any(scale)Phen(:,scale) = logsgn(expand,:) .* exp(Phen(:,scale));end
⛄ 运行结果
⛄ 参考文献
[1] 刘振男、杜尧、韩幸烨、和鹏飞、周正模、曾天山.基于遗传算法优化极限学习机模型的干旱预测——以云贵高原为例[J].人民长江, 2020, 51(8):6.DOI:CNKI:SUN:RIVE.0.2020-08-003.
[2] 郑小霞,蒋海生,刘静,等.基于变分模态分解与灰狼算法优化极限学习机的滚动轴承故障诊断[J].轴承, 2021(9):6.
[3] 王桥,魏孟,叶敏,等.基于灰狼算法优化极限学习机的锂离子电池SOC估计[J].储能科学与技术, 2021.DOI:10.19799/j.cnki.2095-4239.2020.0389.















 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









