







一、概述
人体姿态估计是计算机视觉领域的一项技术,它指的是通过图像或视频数据来识别和追踪人体关键部位(如头部、四肢关节等)的位置,并利用这些信息重建出人体的姿态。简单来说,就是让计算机“看”到人体,并理解人体的各种姿势。姿态估计效果如下:
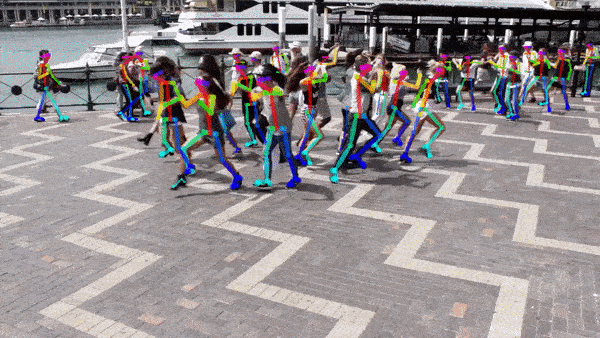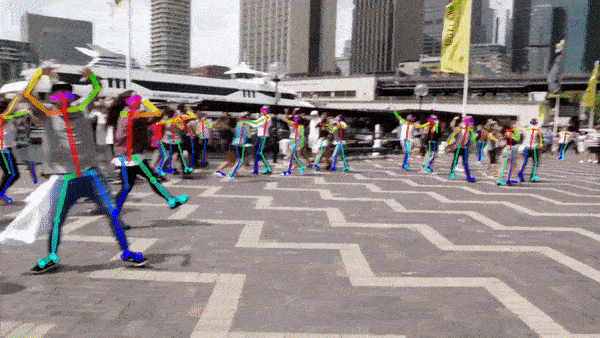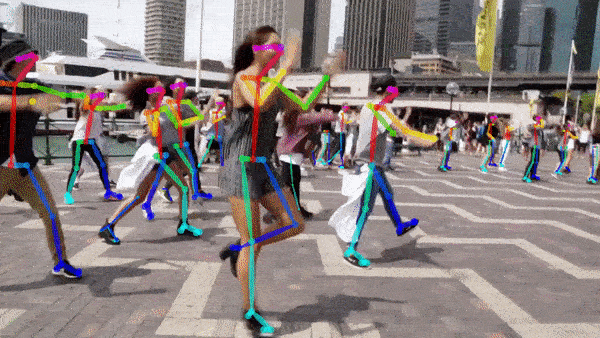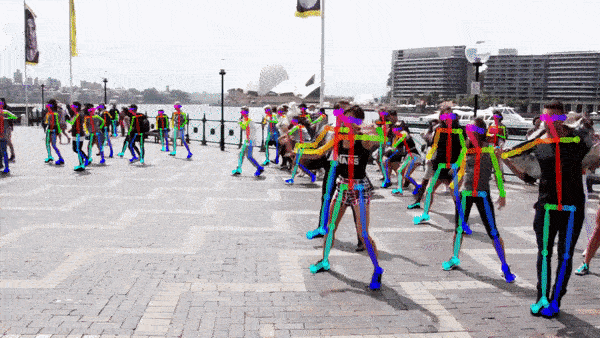
一般情况下的标注信息如下:COCO提供一共17个关键点(不同的数据集可能不一样),如下图。但是我决定用18个,多出一个是脖子,脖子可以用两侧肩膀的平均值做替代,所以可能相对于实际脖子,位置会偏下。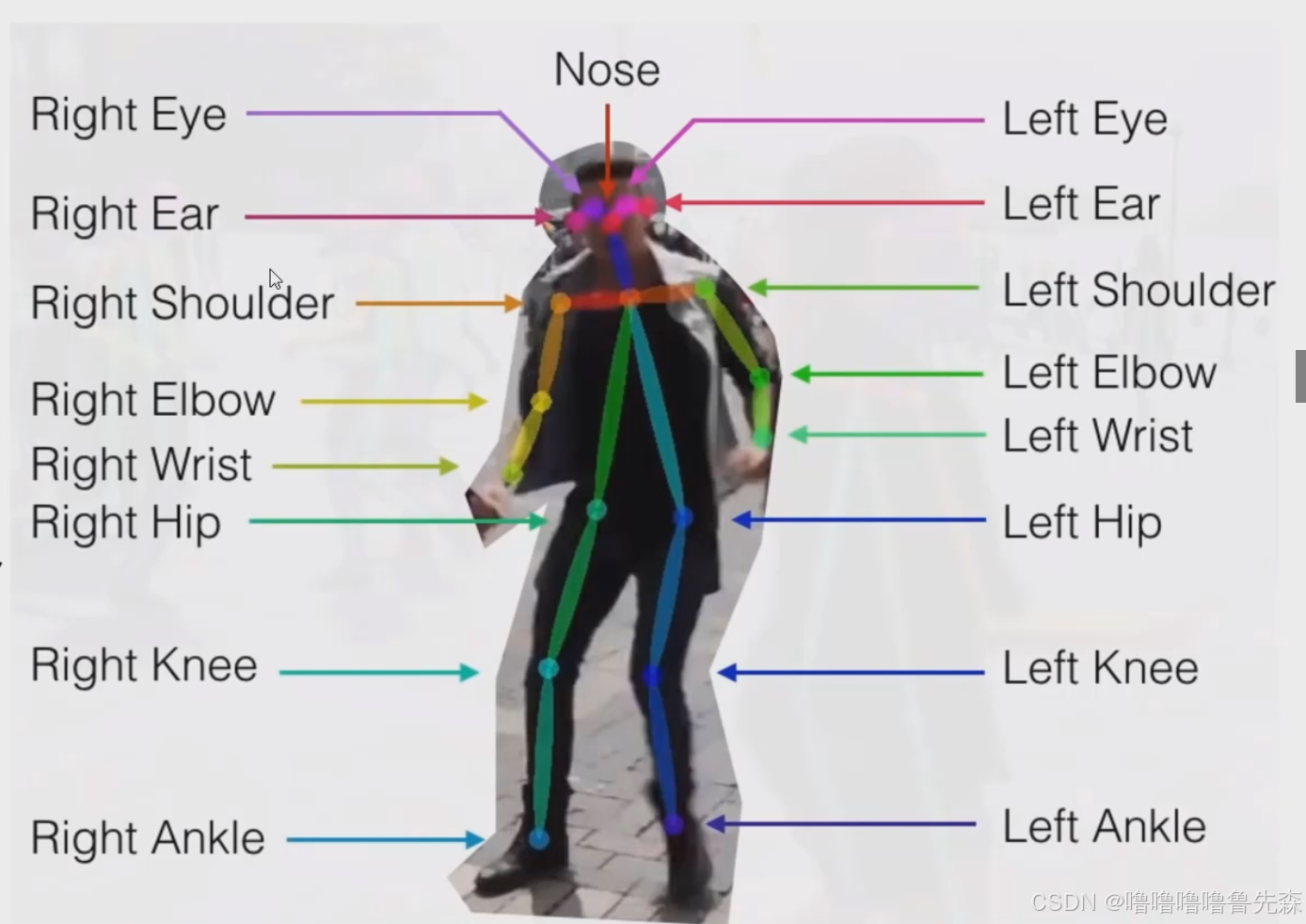
基于深度学习的方法,尤其是卷积神经网络(CNN)和相关变体,在人体姿态估计领域取得了显著进展。这些方法能够学习到复杂的特征,从而在处理多样化和复杂的人体姿态时表现出色。
二、主要方法
2.1 TopDown方法
两步走:①检测到所有人的框②对每个框进行姿态估计输出结果
这样保证了准确率,因为每个框中只有一个人,再对每个框单独做一个回归,每个框去预测实际的关键点位置。

但是缺点也存在,如姿态估计主要是由目标检测所决定,假如两个人出现重叠,只能检测到一个人,那肯定会丢失一个目标;
且计算效率较低,假如一张图像存在多个人,要先进行目标检测(如Yolo),那么姿态估计就相当慢了,这也是这个方法的最大问题,很难做到实时的姿态估计。所有该方法一般用于离线时,想要检测姿态估计做的准确,那么就使用这种方法。
2.2 OpenPose的方法
思路:首先得到所有关键点的位置(头、肩膀、胳膊、腿、脚等等)&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1677
1677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











