






Tushare ID:482621
Tushare是一个免费的大数据平台,你可以很方便地在上面获取各种各样的数据,包括但不限于股票数据(日度,月度,年度),公司财务数据(三大报表),新闻资讯等等。只需要简简单单的几行代码,就可以将数据导入到你所需要的编程软件当中去(支持各种编程环境)。
当然,如果你是编程小白,tushare也是一个很好的获取数据的社区,你可以通过鼠标点击操作,来获取数据并导出。非常的人性化。
实验题目6:根据你所查找的某一个股票或指数的近三年价格的日度数据,做如下运算:
导入相关库
library(zoo)
library(timeSeries)
library(Tushare) # 导入Tushare包
利用tushare获取数据
api <- Tushare::pro_api(token = '*********************************') # 需要注册自己的账号,便可获取属于自己的专属token
data0 <- api(api_name = 'daily', ts_code = "000333.SZ", start_date = "20190101", end_date = "20211231")
# 查看数据
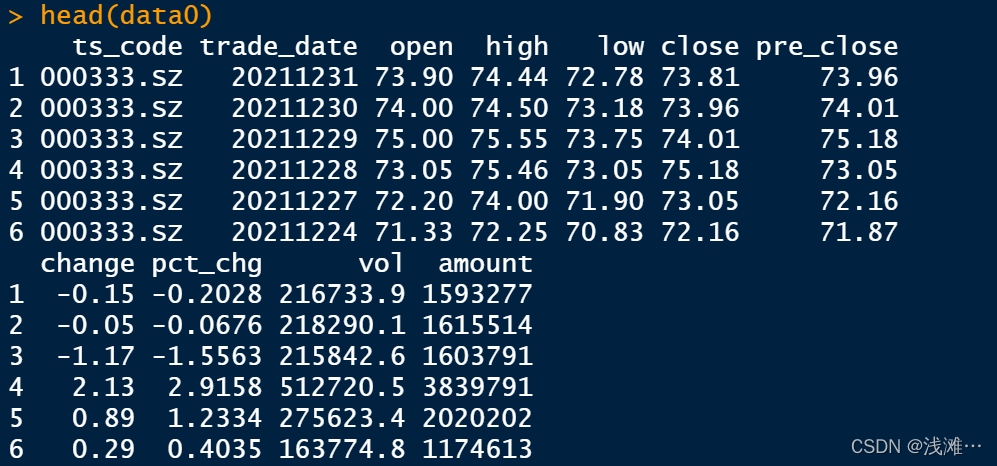
head(data0)
'*************************'这个是自己的token,大家只需要登录tushare的网站,经过简单的操作,并完善个人信息之后,就可以使用该社区,来获取你需要的数据啦,快去试试把!!!
大家可以清晰地看到,只需要简简单单的两行,我就获取了美的公司近三年的股票的收盘价,最高价,最低价,日涨跌幅,总量等等。
整理数据
data = data0[,c(2,6)] # 获取我们需要的时间以及收盘价
head(data)
data <- na.omit(data)
date <- as.character(data[,1])
date <- as.Date(date,'%Y%m%d')
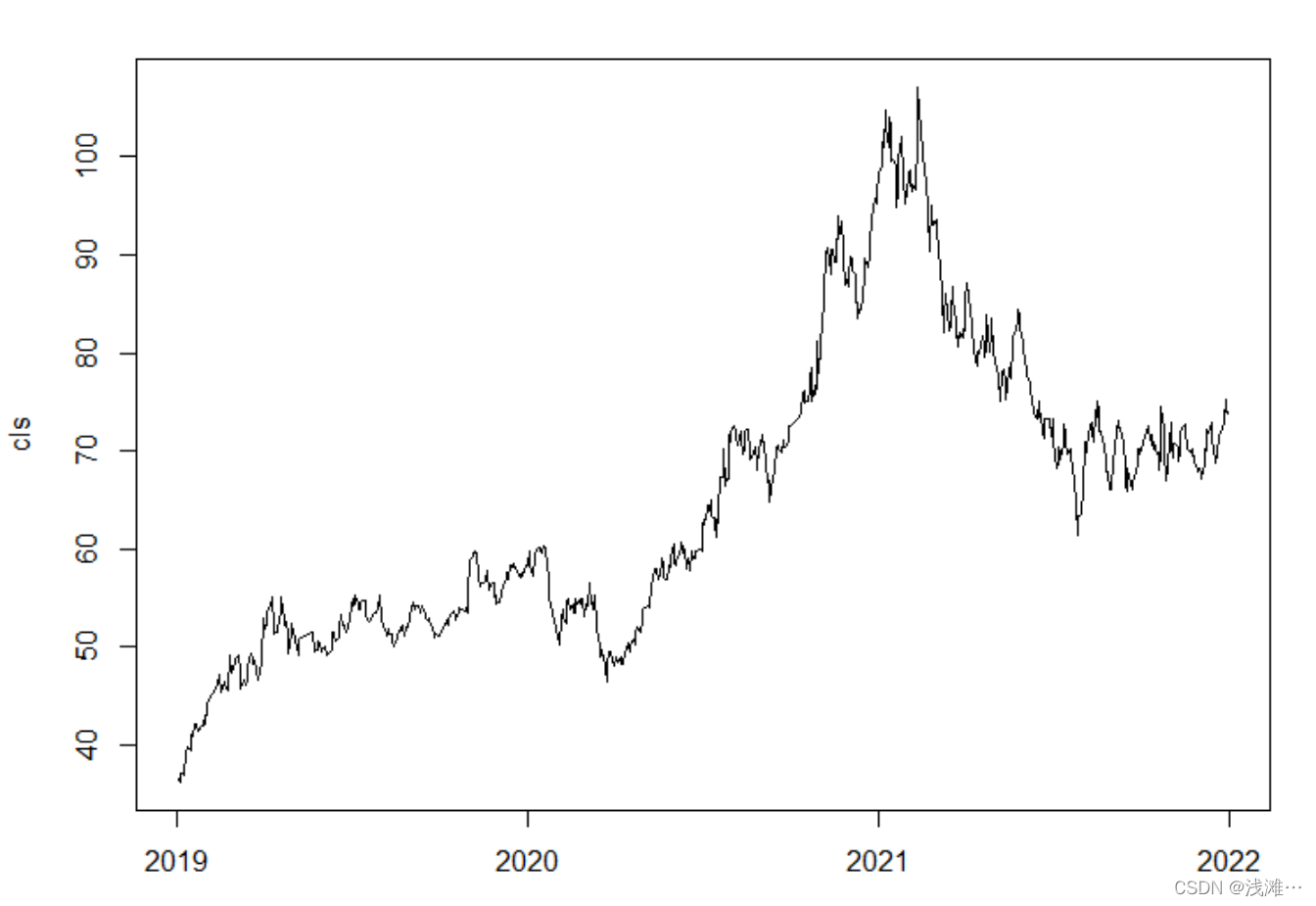
(1)绘制收盘价序列图
clsprc <- as.numeric(data[,2])
cls <- zoo(clsprc, date)
plot(cls)
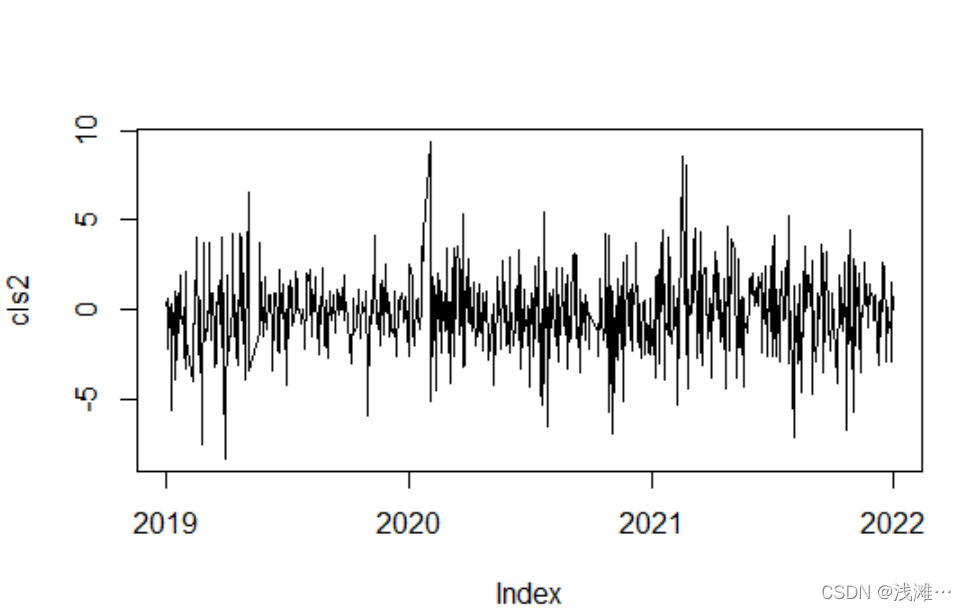
(2)计算其收益率,并绘制收益率的时序图
close = data$close
return <- 100 * diff(log(close))
cls2 <- zoo(return,date)
plot(cls2)
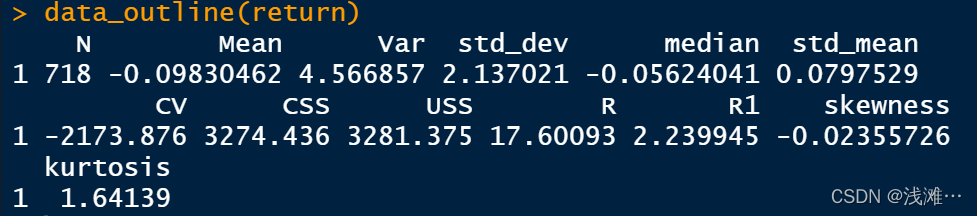
(3)对收益率数据进行描述性统计分析
data_outline <- function(x){
n <- length(x)
m <- mean(x)
v <- var(x)
s <- sd(x)
me <- median(x)
cv <- 100*s/m #变异系数
css <- sum((x-m)^2)
uss <- sum(x^2)
R <- max(x)-min(x)
R1 <- quantile(x,3/4)-quantile(x,1/4)
sm <- s/sqrt(n)
g1 <- n/((n-1)*(n-2))*sum((x-m)^3)/s^3
g2 <- ((n*(n-1))/((n-1)*(n-2)*(n-3))*sum((x-m)^4)/s^4
-(3*(n-1)^2)/((n-2)*(n-3)))
data.frame(N=n,Mean=m,Var=v,std_dev=s,
median=me,std_mean=sm,CV=cv,CSS=css,USS=uss,
R=R,R1=R1,skewness=g1,kurtosis=g2,row.names=1)
}
data_outline(return)
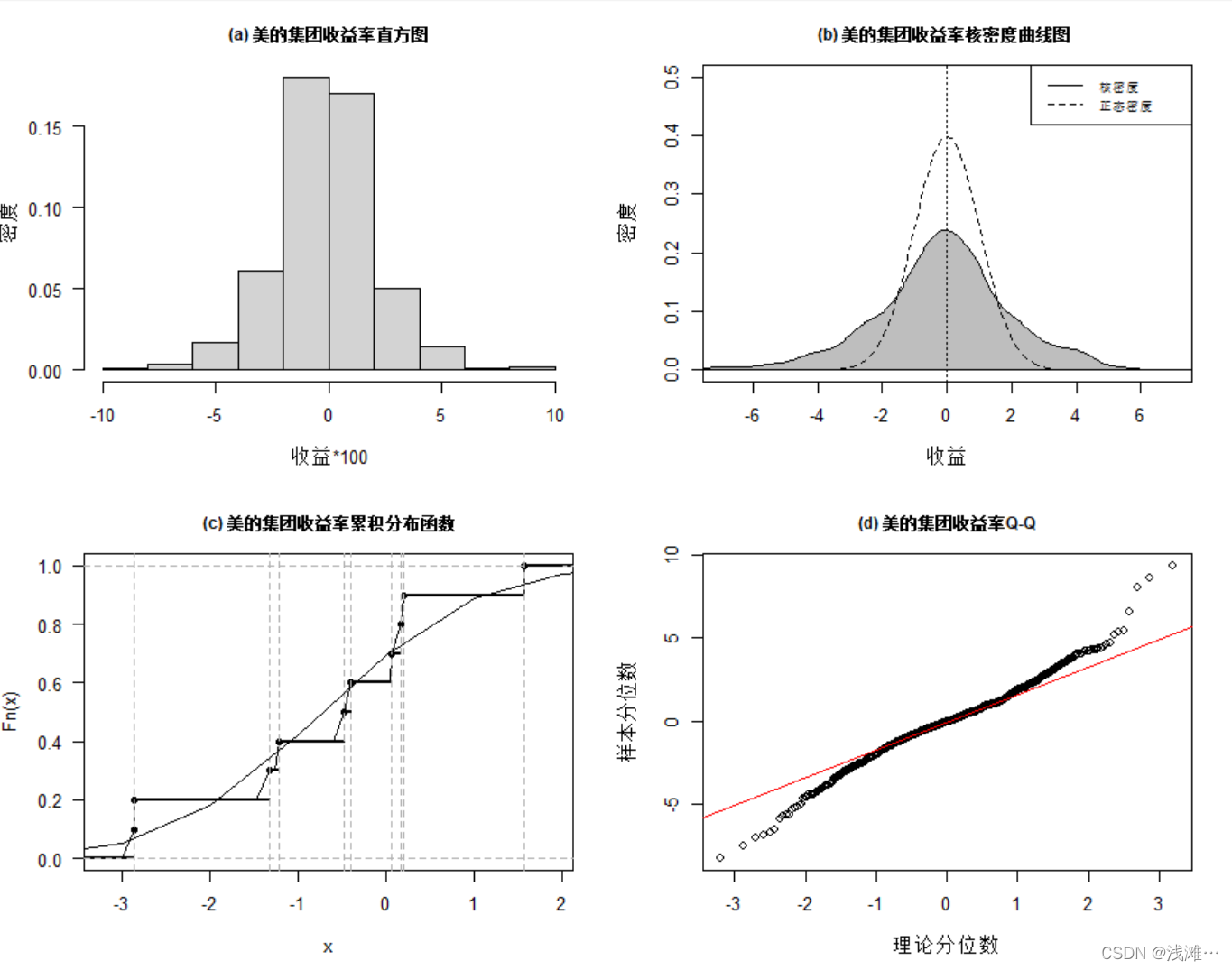
(4)在同一个画布里绘出收益率序列的直方图、核密度估计曲线、经验分布图和QQ图,并将后两个图与正态分布做比较。
#直方图
win.graph(width=7,height=6.5)
par(mfrow=c(2,2),mar=c(5,4,3,2))
hist(return,main='(a) 美的集团收益率直方图',
xlab='收益*100',ylab='密度', freq=F,cex.main=0.95,las=1)
#核密度估计图
plot(density(return), main="(b) 美的集团收益率核密度曲线图 ",xlab="收益", ylab='密度',
xlim = c(-7,7), ylim=c(0,0.5),cex.main=0.95)
polygon(density(return), col="gray", border="black")
curve(dnorm,lty = 2, add = TRUE)
abline(v=0,lty = 3)
legend("topright", legend=c("核密度","正态密度"),lty=c(1,2,3),cex=0.7)
#经验分布图
ECD.SSEC <- ecdf(return[1:10])
plot(ECD.SSEC,lwd = 2,main="(c) 美的集团收益率累积分布函数",cex.main=0.95,las=1)
xx <- unique(sort(c(seq(-3, 2, length=24), knots(ECD.SSEC))))
lines(xx, ECD.SSEC(xx))
abline(v=knots(ECD.SSEC),lty=2,col='gray70')
x1 <- c((-4):3)
lines(x1,pnorm(x1,mean(return[1:10]),sd(return[1:10])))
#QQ图
qqnorm(return,main="(d) 美的集团收益率Q-Q",cex.main=0.95,xlab='理论分位数',ylab='样本分位数')
qqline(return,col='red')
我会不定期的发一些关于金融数据分析的小实例,在学习编程的同时,分享自己的经历,希望大家多多交流和指点。
注:本代码均来自于课程学习以及网络,如有雷同,纯属巧合。如果侵犯到您的权益,请及时联系我。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









