






在看论文或者用deepseek生成公式,可能遇到需要截图或者用,mathpix截图识别浪费时间又耗精力。接下来看看DOC2X 链接如下 :https://doc2x.noedgeai.com?inviteCode=D1IZ85
一 用deepseek生成数学公式
生成后直接复制
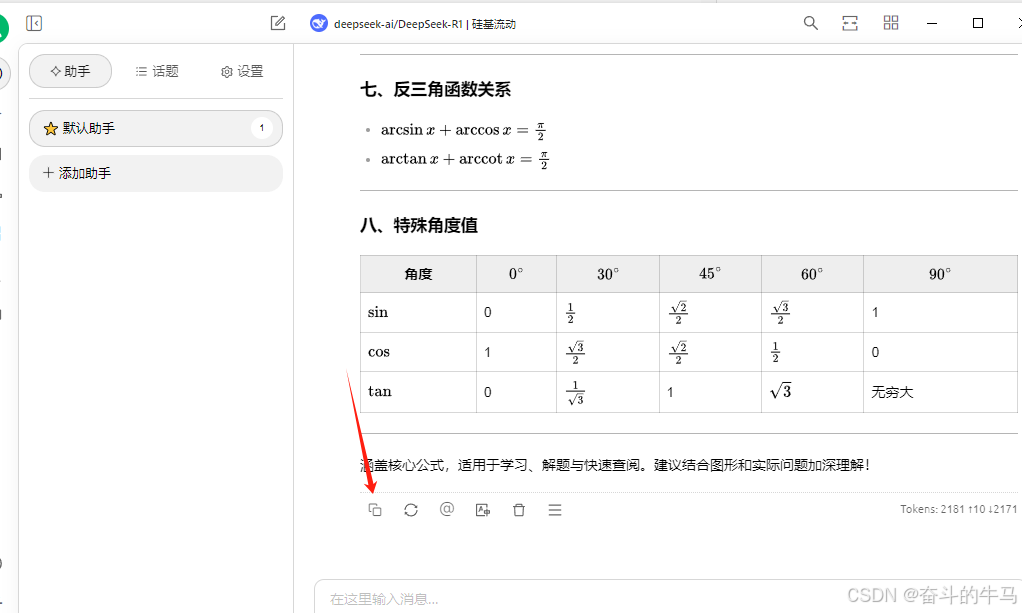
二 MD编辑转换格式
将复制的粘贴至左边,可以看到右边会出现公式。
三 导出转为word 文本模式
也可以pdf
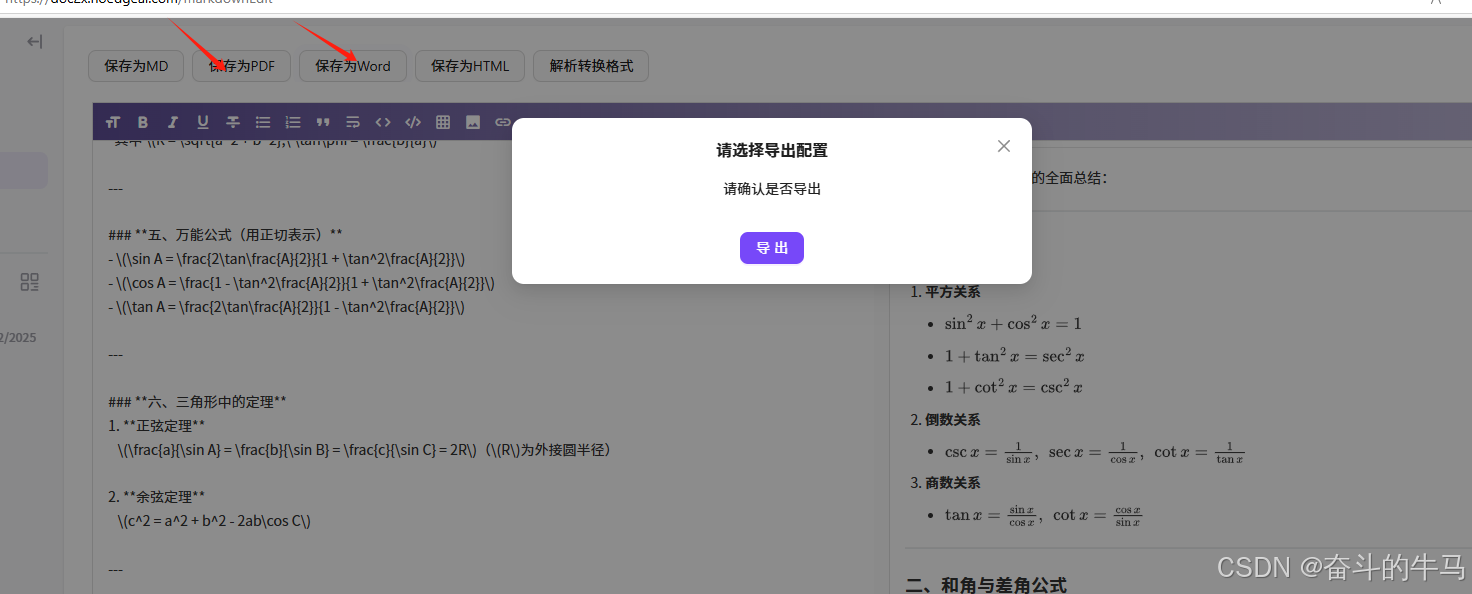
四 结果展示
真的太好用啦
在看论文或者用deepseek生成公式,可能遇到需要截图或者用,mathpix截图识别浪费时间又耗精力。接下来看看DOC2X 链接如下 :https://doc2x.noedgeai.com?inviteCode=D1IZ85
生成后直接复制
将复制的粘贴至左边,可以看到右边会出现公式。
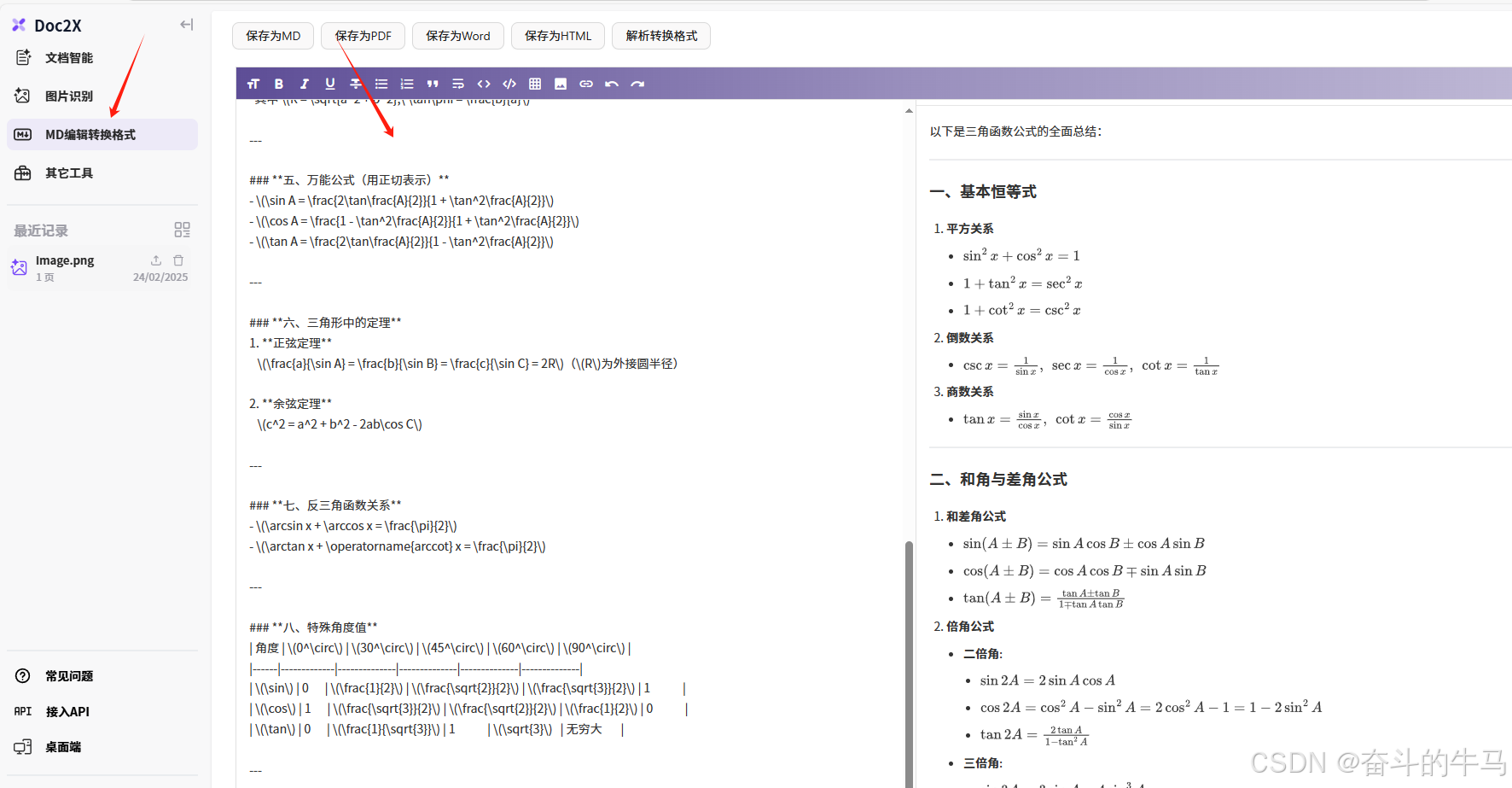
也可以pdf
真的太好用啦
 2263
2263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























