










目录
第一关:极小极大归一化
任务描述:
本关任务:进行数据的极大极小归一化处理。
相关知识:
为了完成本关任务,你需要掌握:
- 极小极大归一化的介绍,
- 极小极大归一化的实现。
一、原理介绍:
通常情况下,在建模之前,都需要对数据进行标准化处理,以消除量纲的影响。如果对未标准化的数据直接进行建模,可能会导致模型对数值大的变量学习过多,而对数值小的变量训练不够充分,往往模型效果会不好。常用的数据标准化方法有最大最小归一化、均值方差标准化、小数定标法、定量特征二值化等。
最大最小归一化,顾名思义,就是利用数据列中的最大值和最小值进行标准化处理,标准化后的数值处于[0,1]之间,计算方式为数据与该列的最小值作差,再除以极差。

二、实现步骤:
引入库
用户使用 numpy 库进行基本的科学运算,pandas 库是一个强大的分析结构化数据的工具集,以 numpy 为基础。
import numpy
创建数据
利用随机数种子,每次生成的随机数相同方便进行数据检测。pd.DataFrame 类似多维数组,每列数据可以是不同类型。

三、归一化数据:
将数据的最大最小值记录下来,并通过Max-Min作为基数(即 Min = 0,Max = 1)进行数据的归一化处理。

四、数据归一化原因:
- 在机器学习中归一化后加快了梯度下降求最优解的速度。
- 在机器学习中归一化有可能提高精度。
- 消除变量间的量纲关系,从而使数据具有可比性。
编程要求:
根据提示,在右侧编译器中的 begin-end 代码块内完成极小极大归一化函数代码。
测试说明:
平台会对你编写的代码进行测试:
预期输出:
value1 value2 value1_n value2_n0 13.071792 20.708234 0.673810 0.1557081 2.300139 74.246953 0.081684 0.7619932 19.005657 39.215413 1.000000 0.3652883 9.643828 18.225652 0.485372 0.1275954 17.449491 74.353941 0.914456 0.763205
开始你的任务吧,祝你成功!
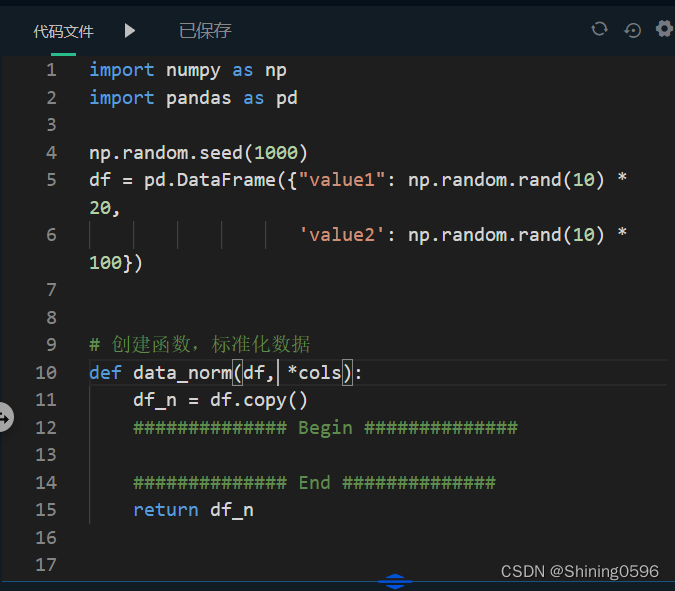

import numpy as np
import pandas as pd
np.random.seed(1000)
df = pd.DataFrame({"value1": np.random.rand(10) * 20,
'value2': np.random.rand(10) * 100})
# 创建函数,标准化数据
def data_norm(df, *cols):
df_n = df.copy()
############## Begin ##############
for col in cols:
ma = df_n[col].max()
mi = df_n[col].min()
df_n[col + '_n'] = (df_n[col] - mi) / (ma - mi)
############## End ##############
return df_n
df_n = data_norm(df, 'value1', 'value2')
print(df_n.head())
第二关:0均值标准化:
任务描述:
本关任务:进行数据的0均值标准化处理。
相关知识:
为了完成本关任务,你需要掌握:
- 0 值标准化的实现,
- 0 值标准化的优缺点。
一、原理介绍:
0 均值标准化处理方法处于整个框架中的数据准备阶段。也就是说,在源数据通过网络爬虫、接口或其他方式进入数据库中后,下一步就要进行的数据预处理阶段中的重要步骤。
数据分析与挖掘中,很多方法需要样本符合一定的标准,如果需要分析的诸多自变量不是同一个量级,就会给分析工作造成困难,甚至影响后期建模的精准度。
0 均值标准化是数据处理的一种常用方法。通过它能够将不同量级的数据转化为统一量度的 0 均值分值进行比较。也叫标准差标准化,这种方法给予原始数据的均值和标准差进行数据的标准化。
经过处理的数据符合标准正态分布,即均值为 0 ,标准差为 1 。

二、实现步骤:


三、0均值标准化的优缺点:
优点:
-
算法简单方便,结果方便比较;
-
可够应用与数值型的数据,并且不受数据量级的影响。
缺点
-
总体平均值与方差不一定可知;
-
在一定程度上要求数据分布;
-
0均值标准化的数据没有实际意义,只能用于比较。
编程要求:
根据提示,在右侧编译器的 begin-end 代码块内完成 0 均值标准化函数代码。
测试说明:
平台会对你编写的代码进行测试:
预期输出:
value1 value2 value1_Zn value2_Zn0 65.358959 20.708234 0.520694 -1.0245671 11.500694 74.246953 -1.093571 0.5650282 95.028286 39.215413 1.409956 -0.4750783 48.219140 18.225652 0.006971 -1.0982764 87.247454 74.353941 1.176746 0.5682045 21.233268 6.958208 -0.801862 -1.4328136 4.070962 88.533720 -1.316258 0.9892107 39.719446 95.264440 -0.247785 1.1890498 23.313220 93.114343 -0.739520 1.1252119 84.174072 41.543095 1.084629 -0.405968标准化后value1的均值为:-0.00, 标准差为:1.00
开始你的任务吧,祝你成功!

import numpy as np
import pandas as pd
np.random.seed(1000)
df = pd.DataFrame({"value1": np.random.rand(10) * 100,
'value2': np.random.rand(10) * 100})
# print(df.head())
# 创建函数,标准化数据
def data_Znorm(df, *cols):
df_n = df.copy()
############## Begin ##############
for col in cols:
u = df_n[col].mean()
std = df_n[col].std()
df_n[col + '_Zn'] = (df_n[col] - u) / std
############## End ##############
return (df_n)















 4960
4960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











