






简述
上一篇的单价函数用画图的方式来找到代价函数的最低点,在实际的应用中我们不可能用画图来去求取参数值。那么我们有没有一种系统的方法来求取最小的代价函数的中的w,b值呢,没错,就是梯度下降,梯度下降是一种用来最小化任何函数的算法,它不仅仅用于线性回归,还用于训练,例如,最先进的神经网络模型,也就是深度学习模型。
那么梯度是如何下降的呢?

上面是一副3d图,将这幅图,看作一个山,人站在山峰之上,那么人要最快的下来该怎么走呢,如上图所示,站在不同的点有不同的下山路线,但无一例外的都是朝着最陡峭的方向走去,到达某一条路线的最低点,那个最低点叫做局部最低点
梯度下降的数学表达式
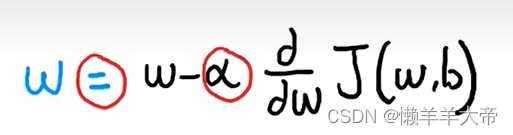
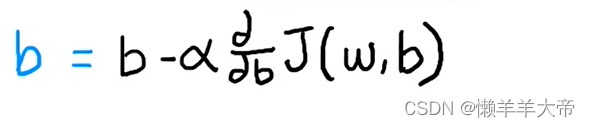
a是学习率,范围在0-1之间,控制着更新模型的w参数和b的步长,当a小的时候,代表从山上迈出的步子比较小,a较大的时候,则代表比较激进。后面的导数是代价函数导数项。
重复w,b步骤,直到算法内敛,通过收敛,我们可以得到一个局部最小值点,wb不在跟随以上步骤发生大的变化
理解梯度下降数学公式
导数项
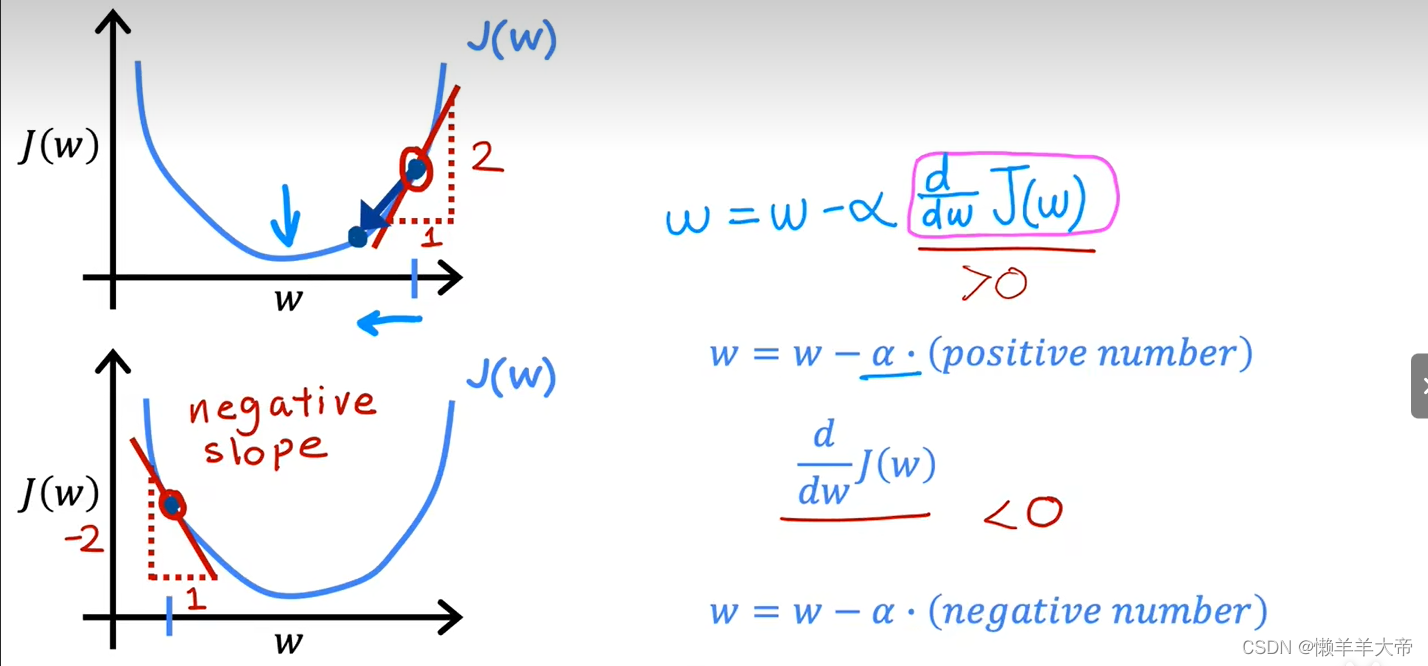
以b=0举例
f(x)=wx
代价函数如上图所示,是一个二位的函数。
第一种,当w的初始点在代价函数的最小值的右边时,a是正数,在w点偏导数也是正数,所以代价函数的值是逐渐减小的,他会逐渐接近最小值,从而达到我们的目的。
第二种情况,当w的初始点在代价函数的最小值的左边时,a是正数,在w点偏导数是负数,所以代价函数的值也是逐渐减小的,他会逐渐接近最小值,从而达到我们的目的。
学习率
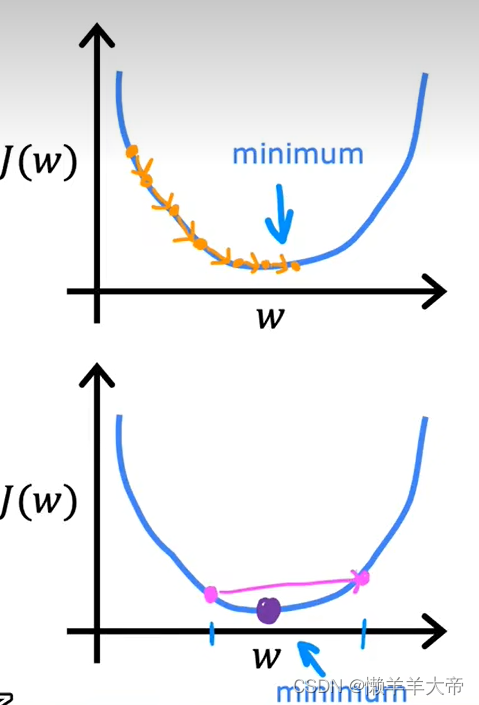
学习率的选择会对梯度下降的效率产生巨大影响,学习率选择的不好,下降率可能会根本不起作用。
当学习率太小的时候,虽然也能降低代价函数,但是速度会非常的慢。
当学习率太大的时候,很可能不会得到代价函数的最小值。















 1638
1638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









