






目录
1.Function with Unknown Parameters
2.Define Loss from Training Data
3.Function with Unknown Parameters
4.Define Loss from Training Data
摘要
本周主要学习了机器学习的基本概念,对机器学习是什么和用于什么有了一定的初步了解,理解了简单以及复杂的linear models的 Training过程,学习了深度学习的相关概念,知道了什么是神经网络和Deep learning的正向传播和反向传播的计算过程。
一、机器学习基本概念
机器学习赋予机器从数据中学习并做出预测或决策的能力,而无需明确编程。其本质就是让机器具备寻找一个正确函数的能力,该函数能够让输入转换为我们想要的输出。
函数的类别:
- regression:函数的输出为一个数值。
例如,通过当天的天气情况预测明天的PM2.5的数值。

- classification:提供若干选项,函数在其中选择一个最优选项输出。
例如让机器下围棋就是让其在棋盘选择最合适的位置落子。
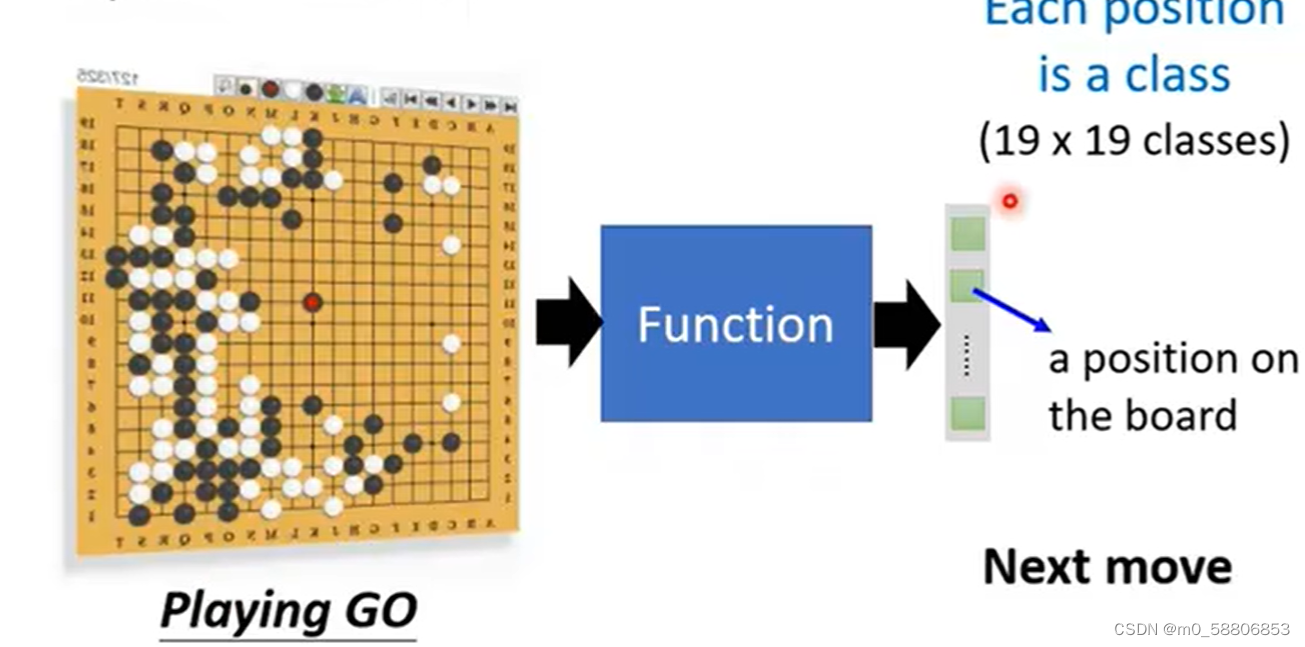
- structure learning:让机器学会创造有结构的事物,例如:图片和文章。
二、Training
机器通过现有数据Training从而找到到最优模型。
1.Function with Unknown Parameters
写出带有未知参数的函数是建立模型的基础。以y=b+w*x为例,其中y是预测值,x是特征,w是权重,b是偏差。这里的w和b就是位置参数。
2.Define Loss from Training Data
Loss(损失函数)用于衡量模型预测结果与真实结果的差异,并指导模型在训练过程中如何调整其参数以最小化这种差异,因此定义Loss是训练模型的关键步骤之一。以下通过对博主订阅人数的预测为例对定义损失函数进行分析。
(1)首先假定损失函数L(0.5k,1)。
(2)通过模型:y=b+w*x以及L(0.5k,1)计算出每天订阅数的预测值y,并记录计算值y与真实值之间的偏差e。
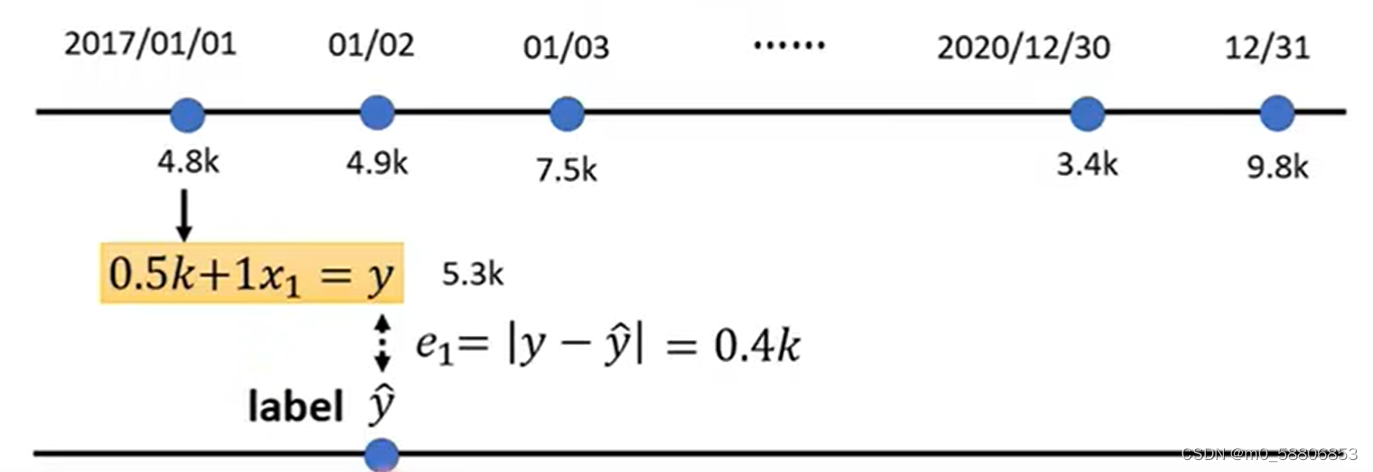
其中,偏差e的计算方式有MAE和MSE两种,MAE就是计算真实值与预测值两者差值的绝对值,上述就是使用的这种方式。MSE是计算两者之间的差值再取平方。

(3)通过对三年中每日订阅人数的预测偏差值计算Loss,Loss值越大则偏差越大,即选用的参数不好,Loss计算公式如下。
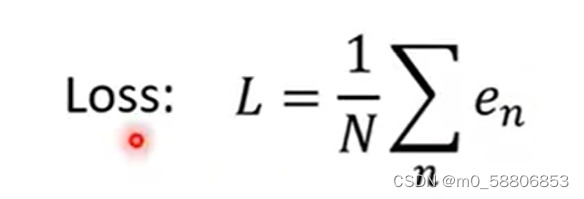
3.Optimization
寻找一组最优值使得偏差值L最小。
以单参数Loss寻找最优值的过程为例:
(1)随机选取一个值。
(2)计算该点斜率k。
(3)根据斜率重新取值。k<0前移,k>0后移,在重新取值的过程中我们可以通过设定n为学习速率以此控制移动步长的大小。
重复步骤(3)直至取值点斜率为0时停止。
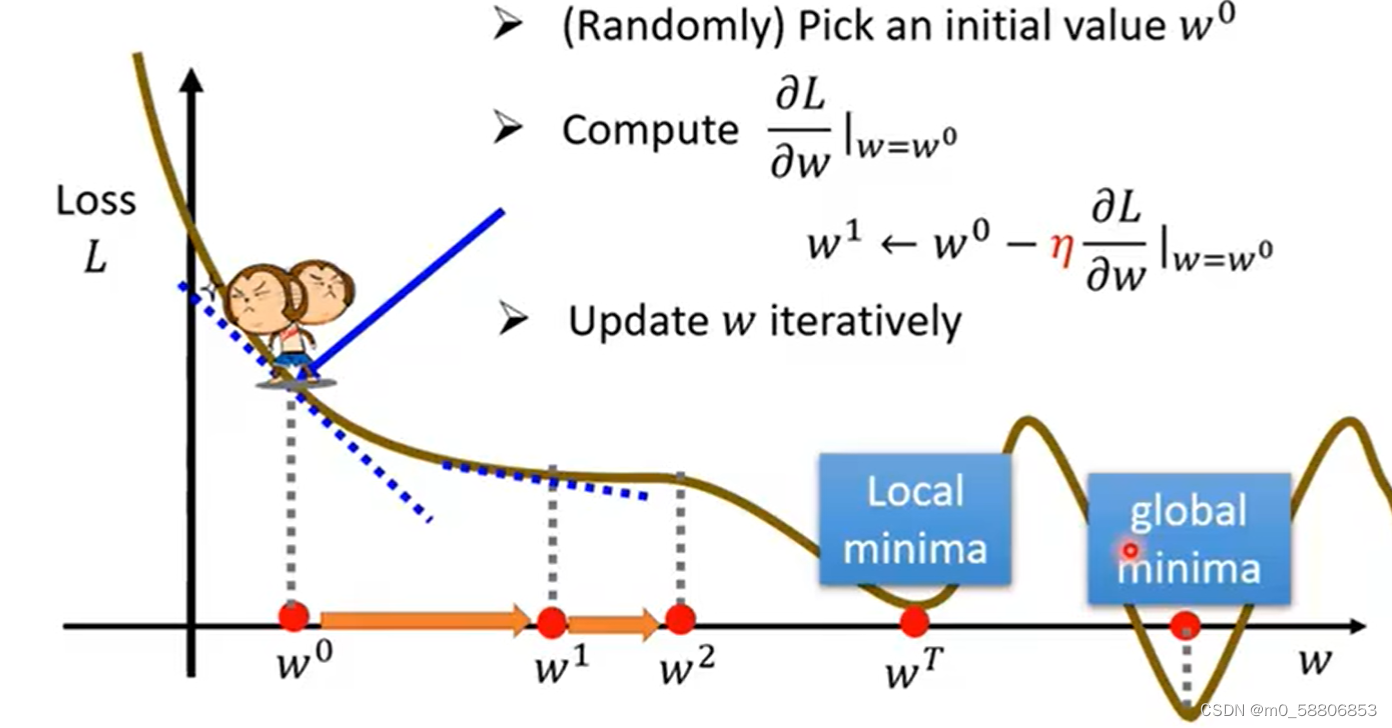
该方法存在一问题:只能获得局部误差最小值,无法确定全局误差最小值。
此外,可以根据实际情况对模型进行修改从而提高预测的准确性,依旧以订阅量为例。
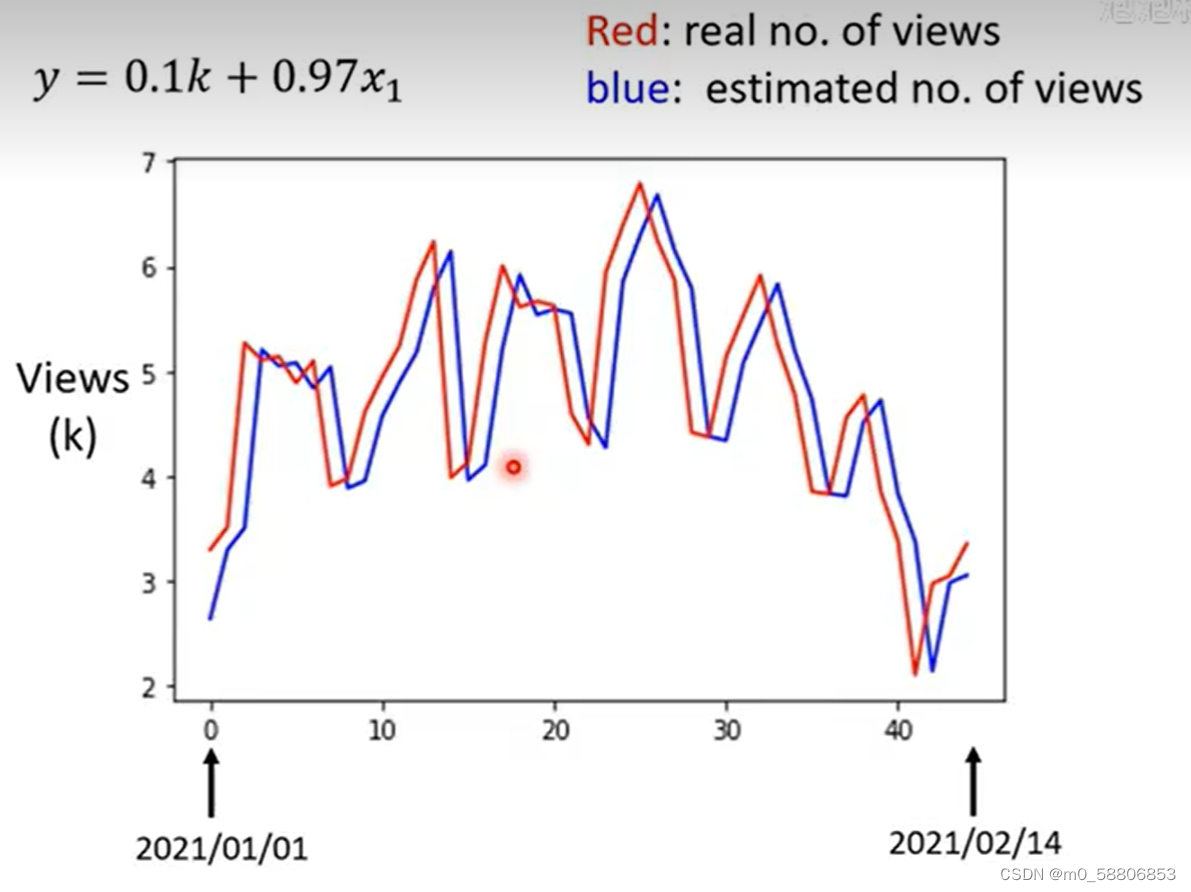
根据上图可以观察出订阅量存在周期性变化情况,如对模型进行对应修改,考虑天数越多,误差值会越小,但当考虑天数到达某一极限时,误差变化不大。
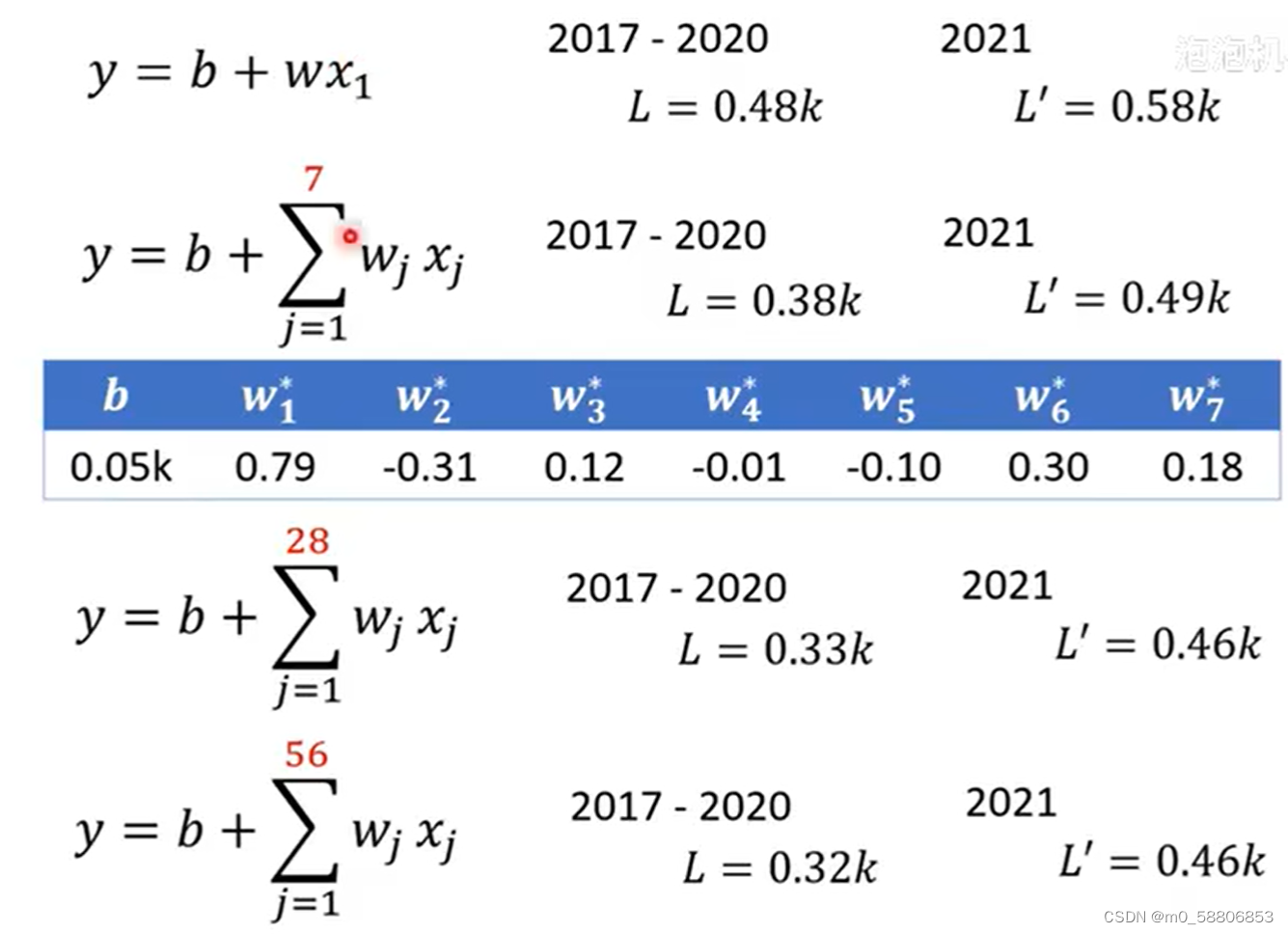
三、复杂Linear models
1.复杂Linear models的构建
上述这种x和y关系为一条直线的函数称为Linear models,这类模型太过简单,我们需要一类更巧妙和更灵活的模型。
如何构建一个更为复杂的function呢?以下图为例我们更为复杂的红线可以由常数加上若干条蓝色类型的线组合构建而成。
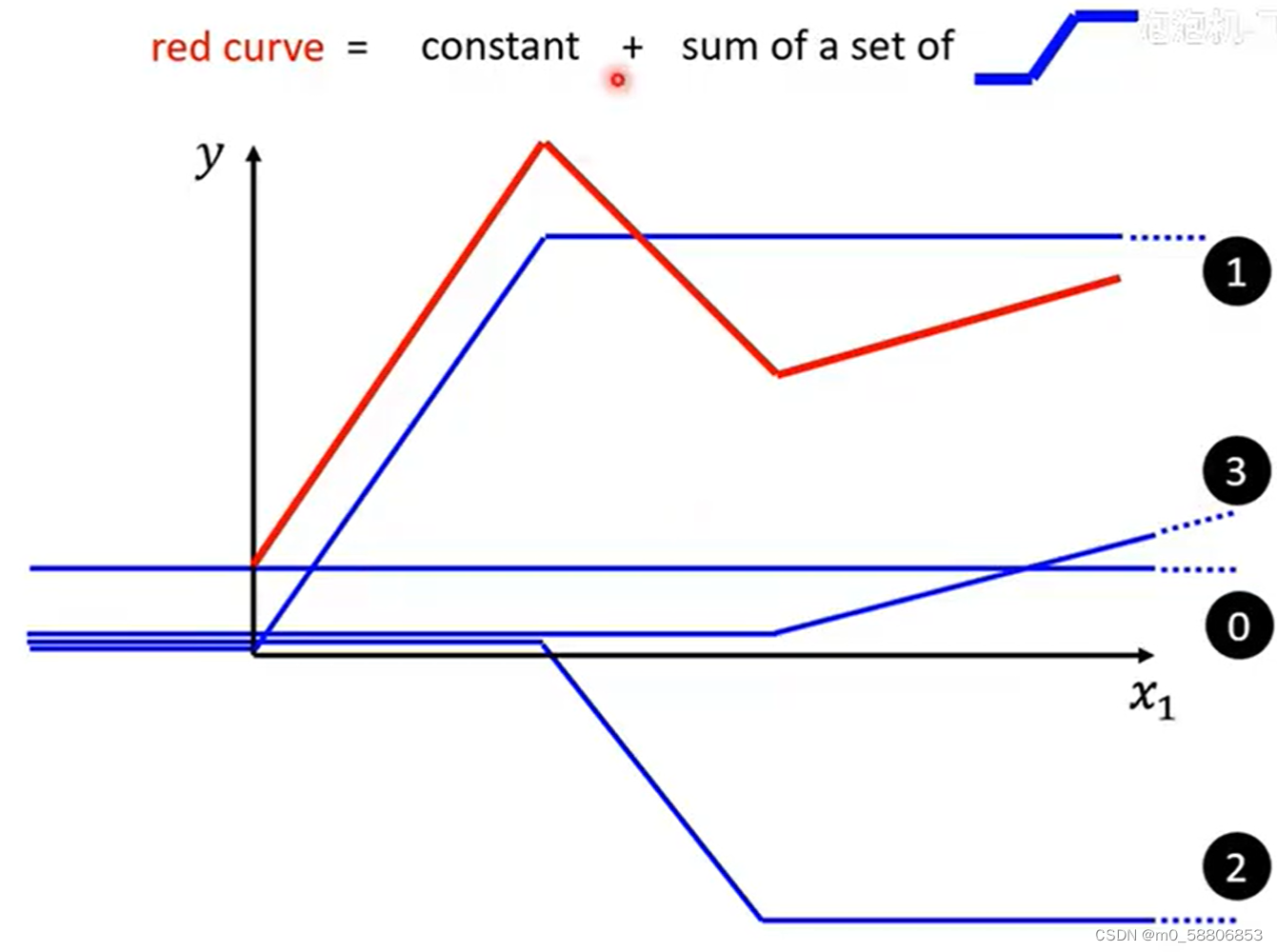
由上可知所有类型的piecewise linear curve都可以由常数加上若干条的蓝色函数组成,折的次数越多需要的蓝色函数个数也就更多。
对于曲线,我们可以在线上取点相连然后按照分段线性线段的做法去做就好了,只要取点个数足够多,我们可以就可以尽可能的去接近其原来的结果。
2.蓝色折线函数的表示
蓝色折线函数我们通常称之为hard sigmoid,我们可以用sigmoid function去逼近蓝色折线函数,sigmoid function的表示如下:
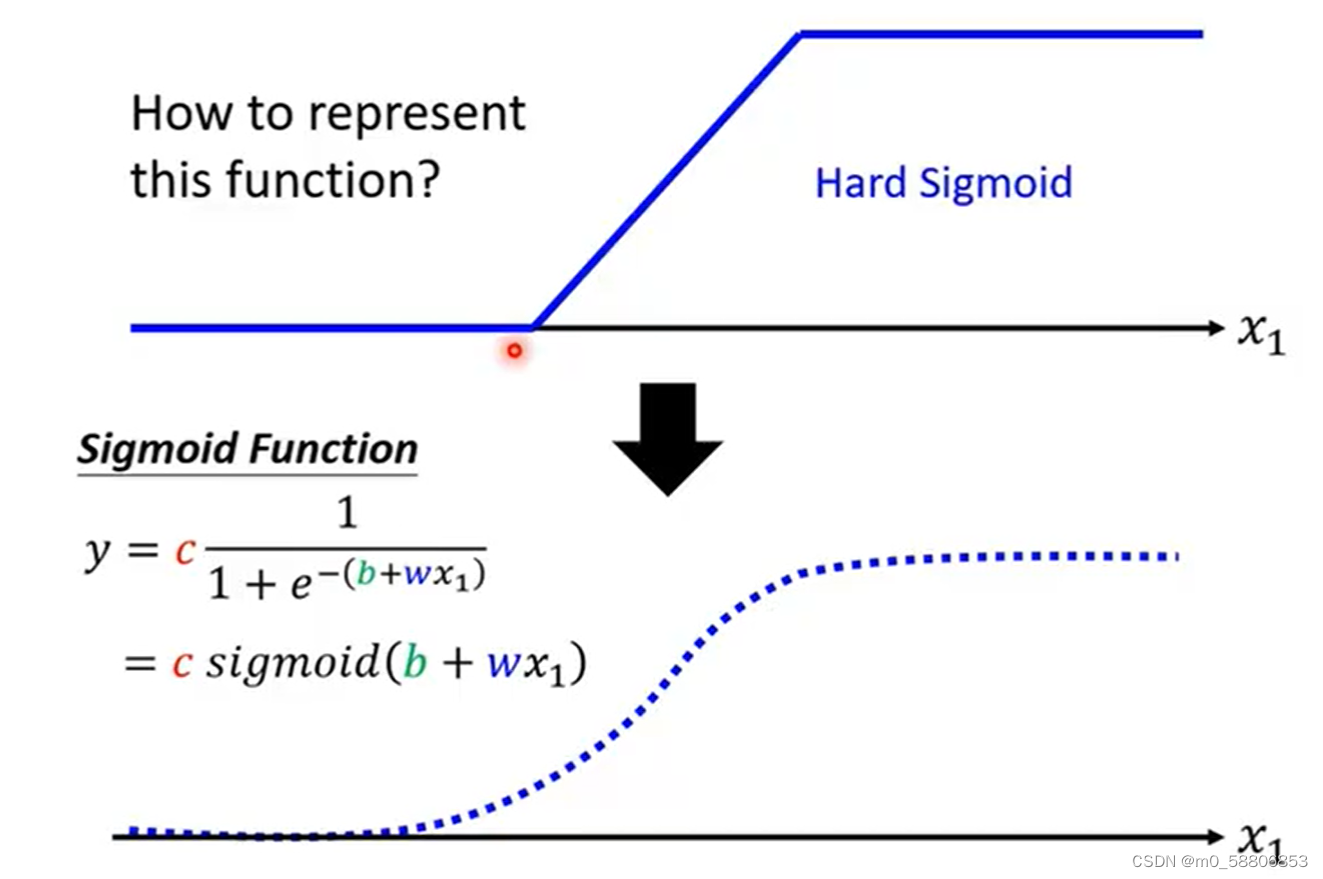
在复杂Linear models的构建过程中,我们需要各式各样的蓝色function,我们可以通过调整y=c*sigmoid(b+wx)中的c,b以及w来获得不同的蓝色function,改变w会改变函数的斜率,改变b会使得函数左右移动,改变c会改变函数的高度。
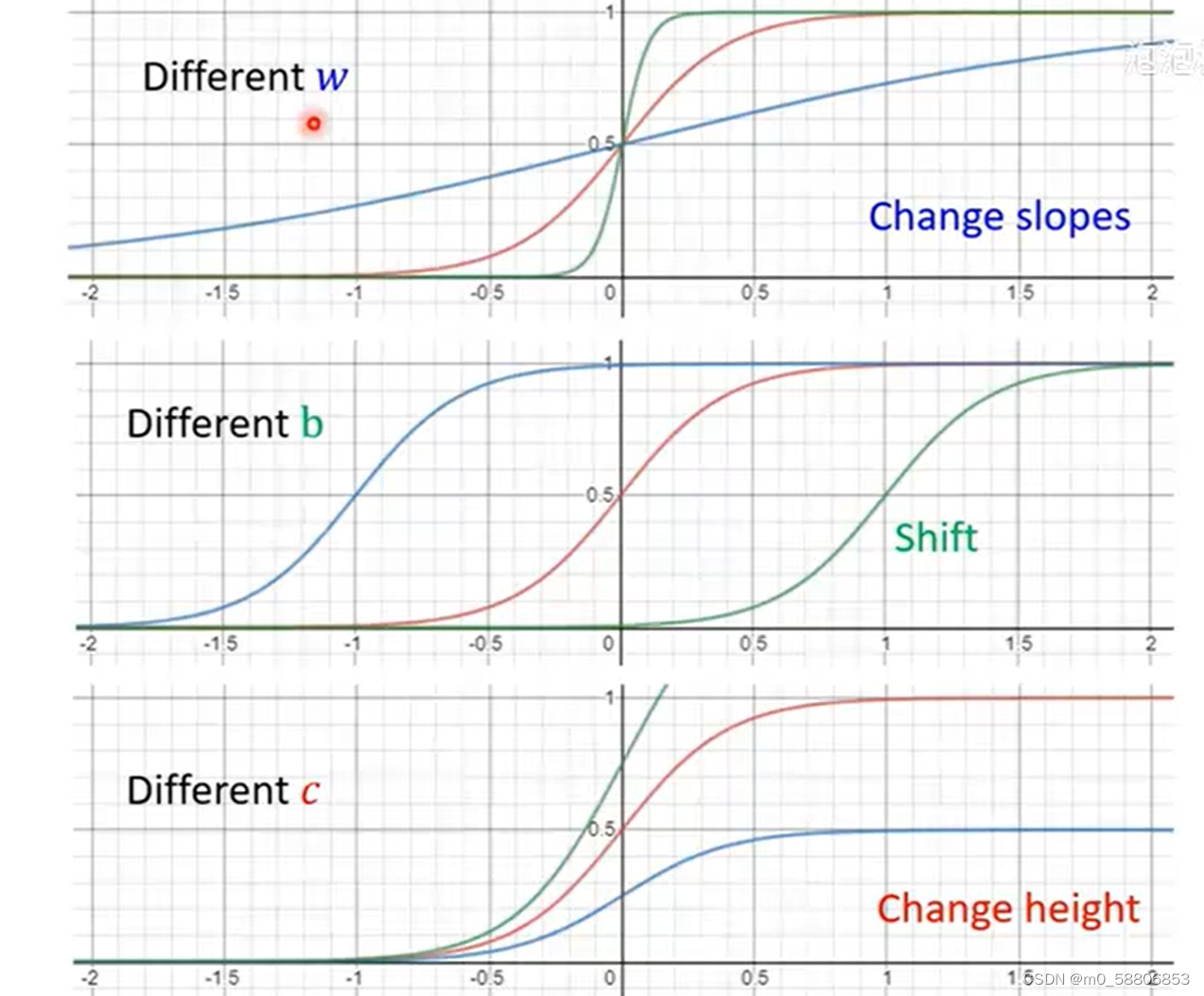
3.Function with Unknown Parameters
在此基础之上,我们也可以按照周期考虑以此获得More Features的New Models。
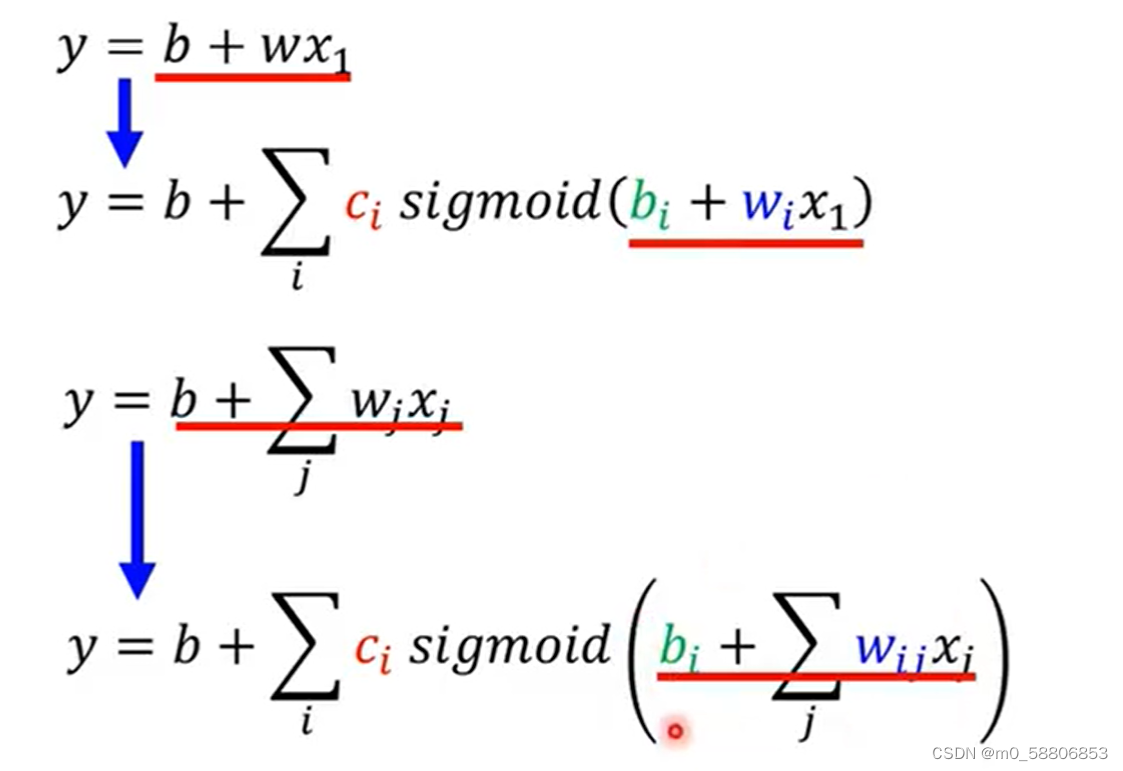
以下可以通过由三个蓝色function,考虑周期为3的情况举例说明,其中i表示有三个蓝色function,j表示考虑前三次的情况。
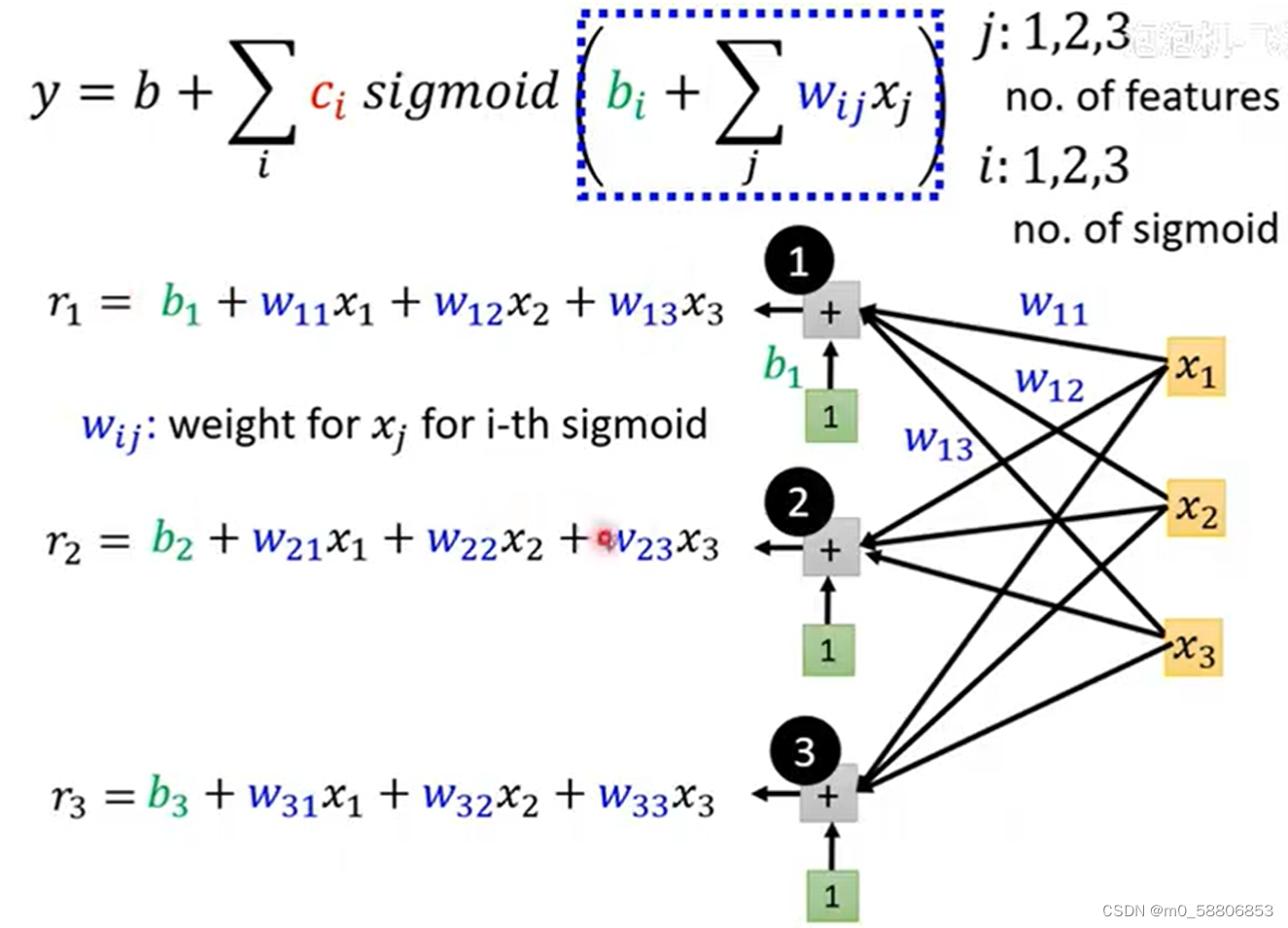
计算时我们可以把其看作矩阵的运算从而方便计算和理解。

将r1,r2,r3分别做sigmoid function从而得到a1,a2,a3,将得到的a分别与c相乘在加上对应的b则可以得到最终的y。
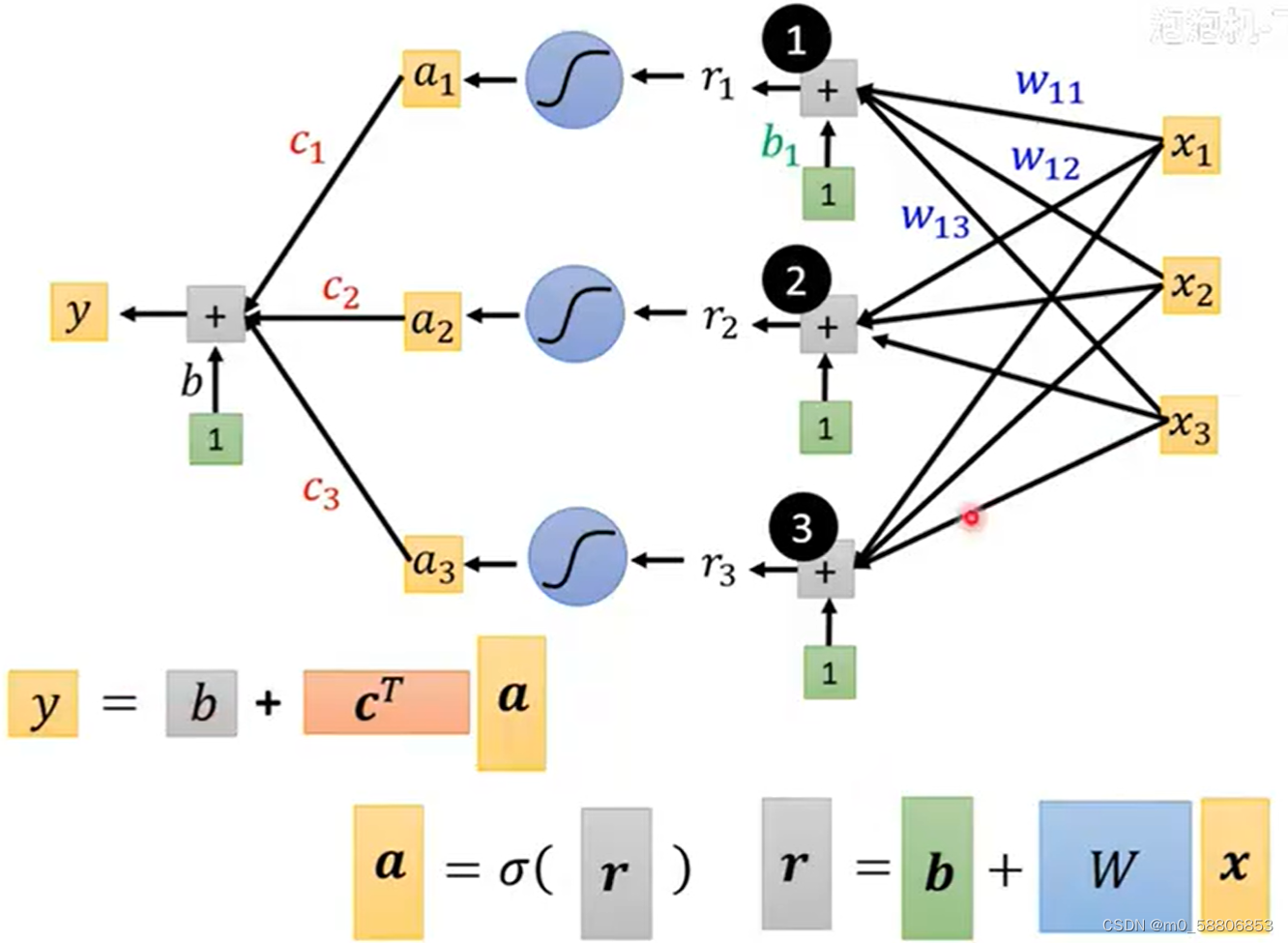
在这个function中,x为特征,所有的w,b,c都属于未知参量,可以将其列成一列统称为θ。至此重新定义了函数的未知参量。
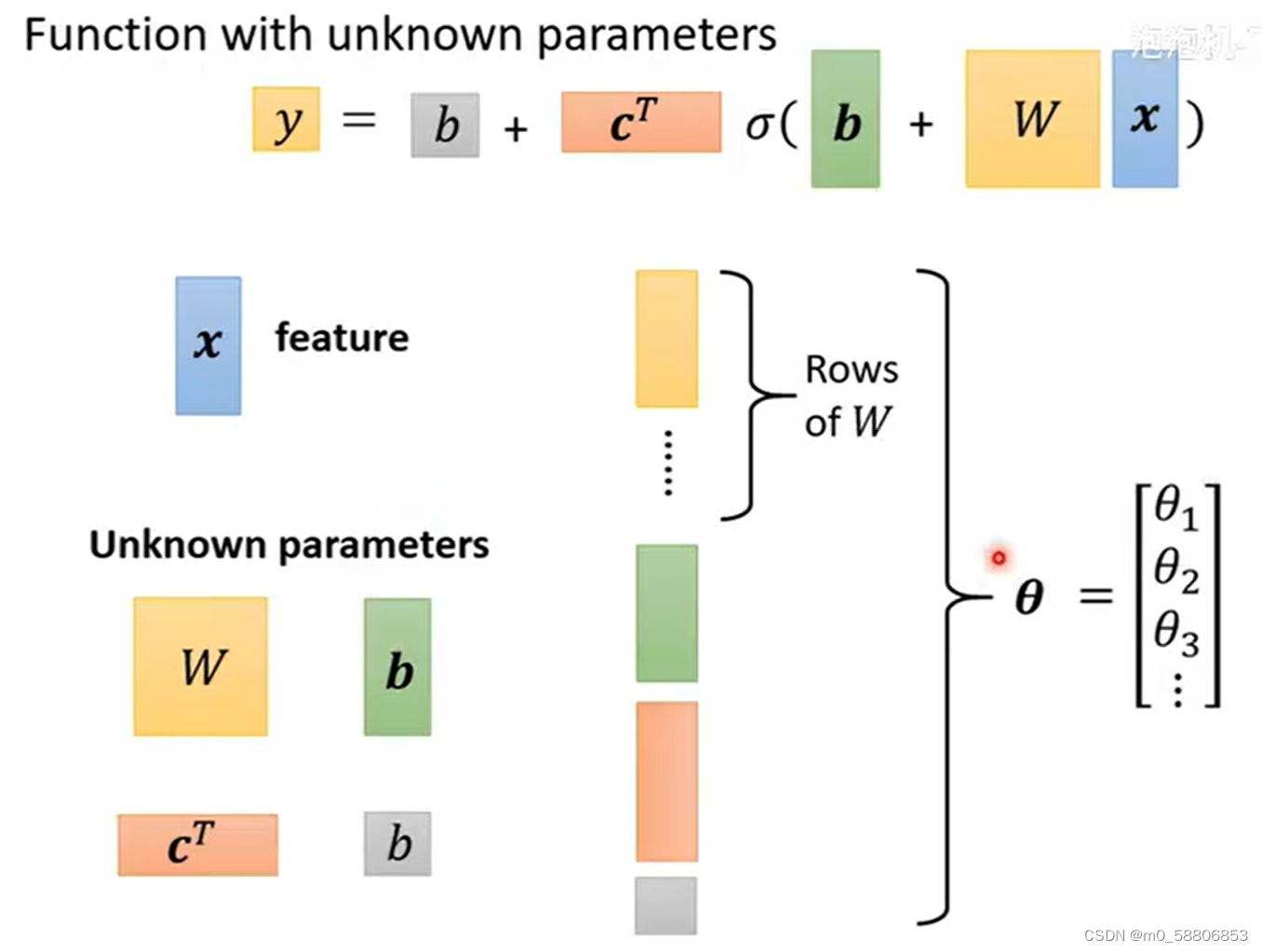
4.Define Loss from Training Data
在复杂Linear model中损失的定义并无不同,只是计算量更大。
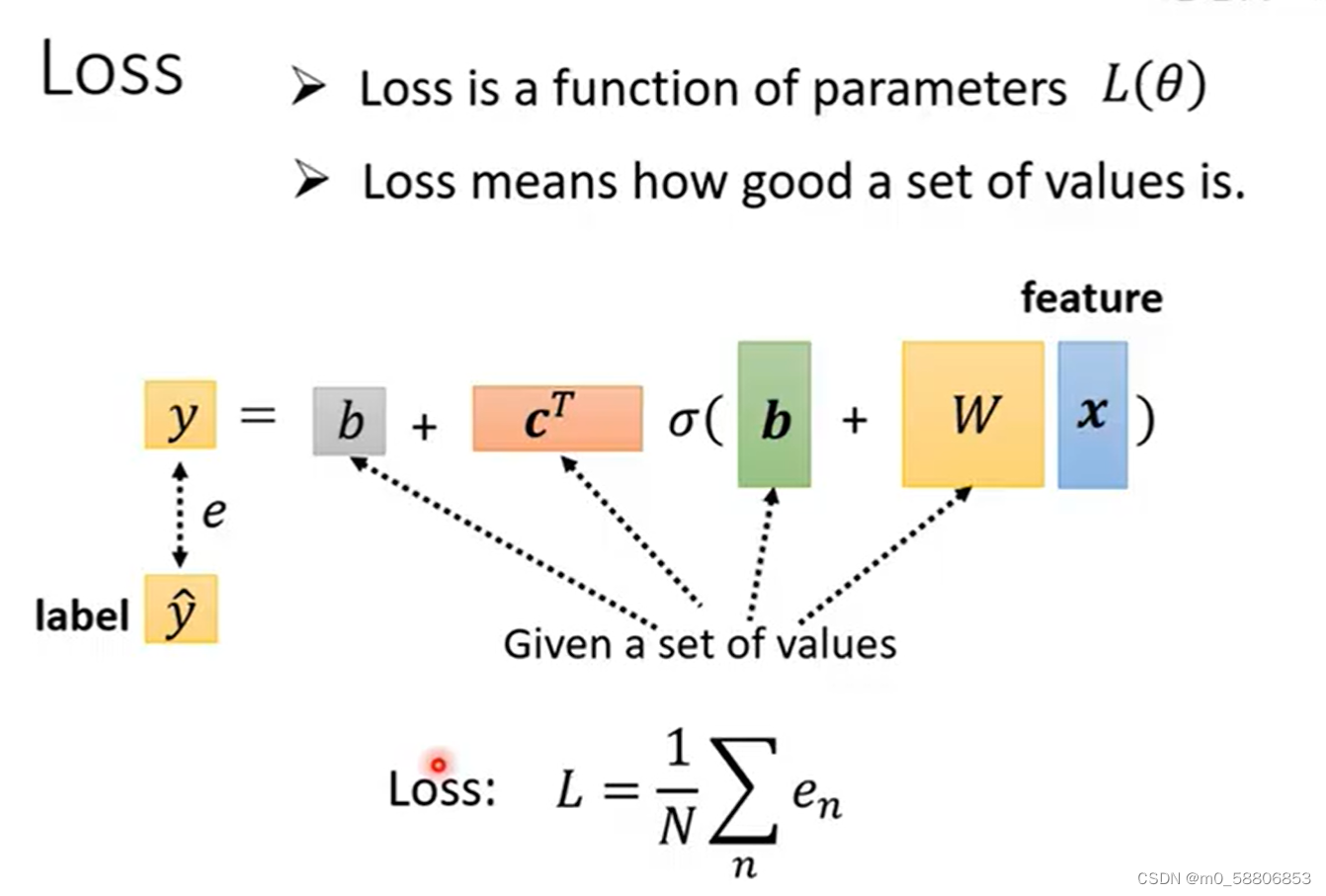
5.Optimization
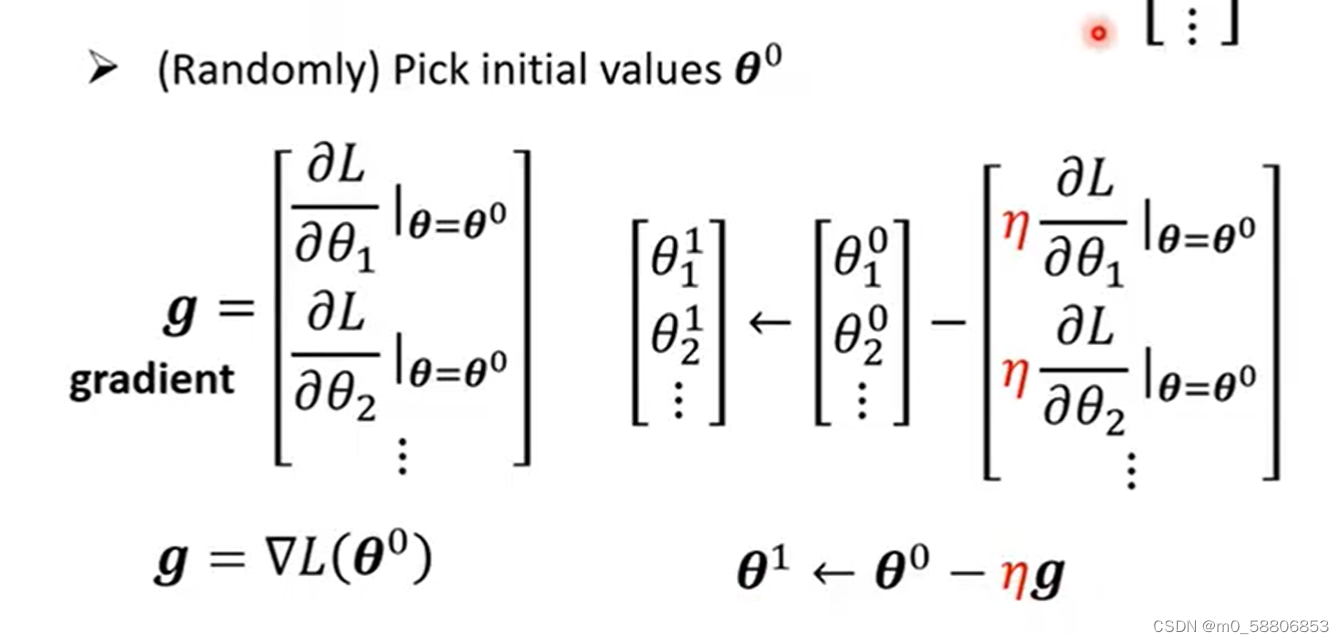
在复杂Linear model中的Optimization与Linear model也并无不同,也是寻找一组参量θ使得Loss最小,即寻找最优值。步骤如下:
(1)随机选取一个初始值。
(2)对每一个位置的参数求偏导,将所得值集合为一个向量。
(3)更新取值点直至梯度为0结束。
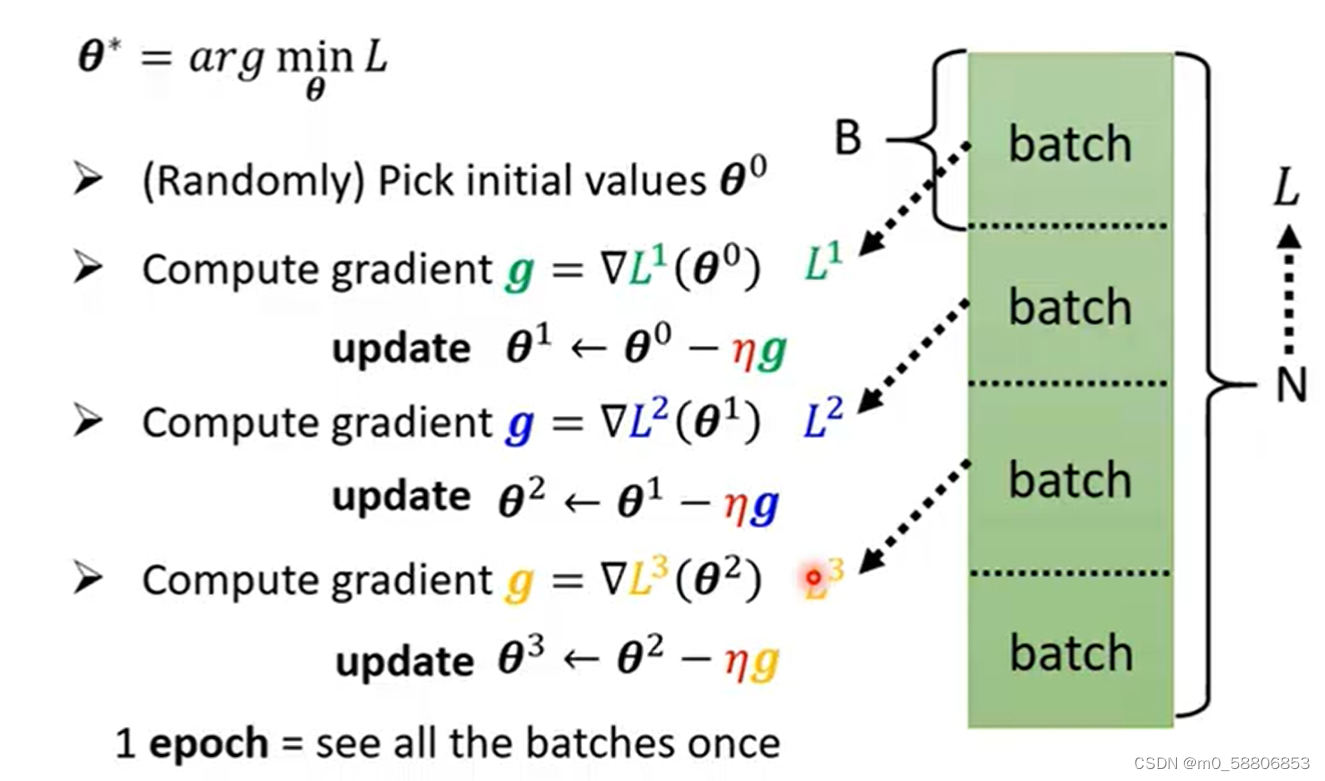
在实际操作中,通常会把现有数据随机分为若干个batch,分别计算每一个batch的Loss然后update参数,把所有数据都看过一遍后称为epoch,两者是有差别的。
6.Relu
Hard sigmoid函数可以由2个Relu函数组成,relu函数的表示如下所示。
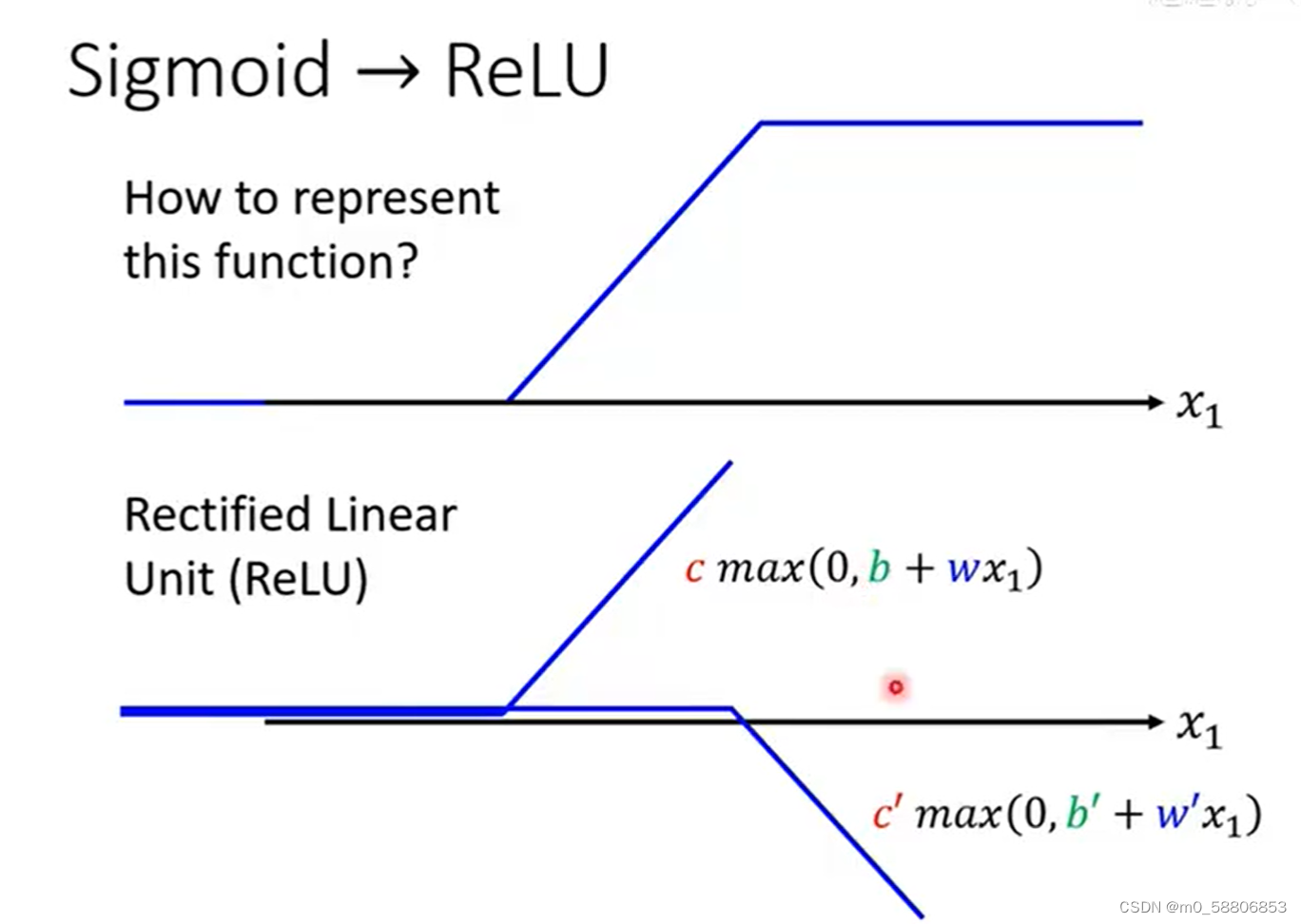
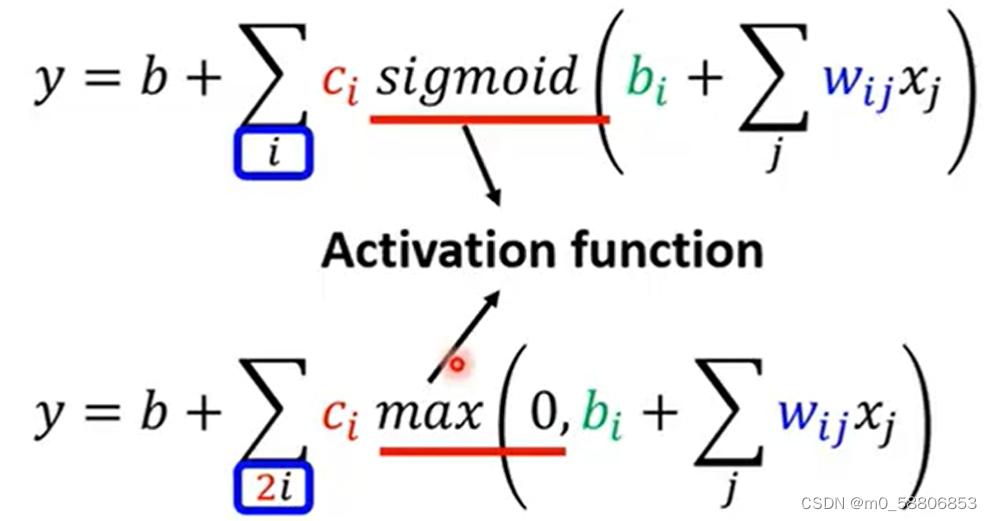
relu和sigmoid在机器学习中被称为Activatiom function。
四、深度学习
1.神经网络
神经网络是一种模拟人脑神经网络结构和功能的数学模型或计算模型,用于对函数进行估计或近似。在神经网络中,每一个sigmoid都可以称为一个神经元。神经网络由大量的Neuron联结进行计算,这些Neuron和它们之间的连接构成了一张网络。神经网络的学习过程是根据提供的样本数据来调整神经元之间的连接权值以及每个神经元的阈值,使网络的输出不断地接近期望的输出。
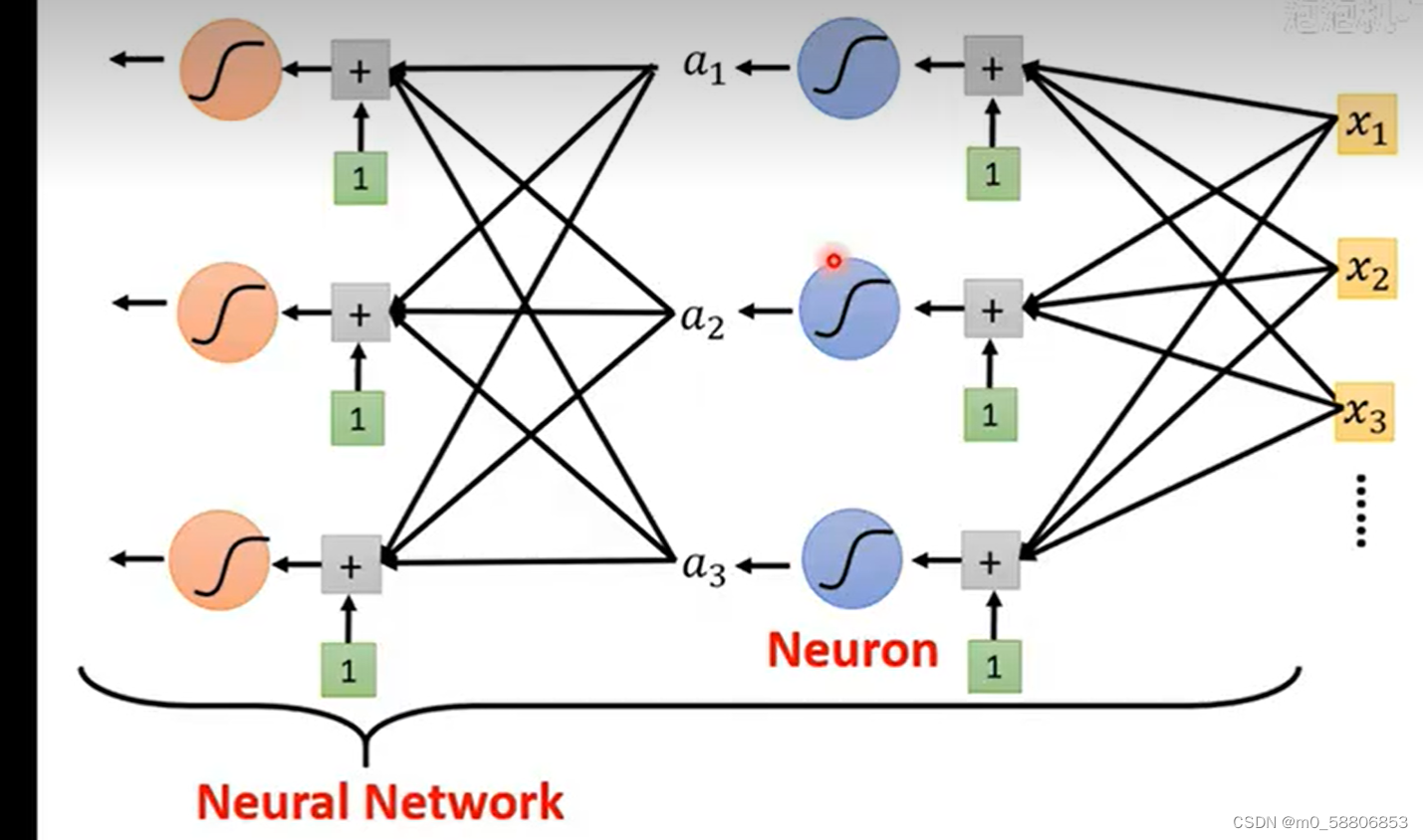
2.深度学习的基本概念
在每个神经网络中,同一排的Neuron可以称为一个layer,由多个layer组成的模型就可以被称为Deep Learning。深度学习的层数越多,预测值往往越准确。但层数过多可能会导致在数据训练时预测较为准确,而实际预测却偏差较大,这种现象被称为Overfitting。
Deep Learning的三大步骤:
(1)定义一个function,即定义一个神经网络。
(2)定义一个function的好坏。
(3)选择最好的一个function。
3.正向传播
正向传播是指对神经网络沿着从输入层到输出层的顺序,依次计算并存储模型的中间变量(包括输出)的过程。
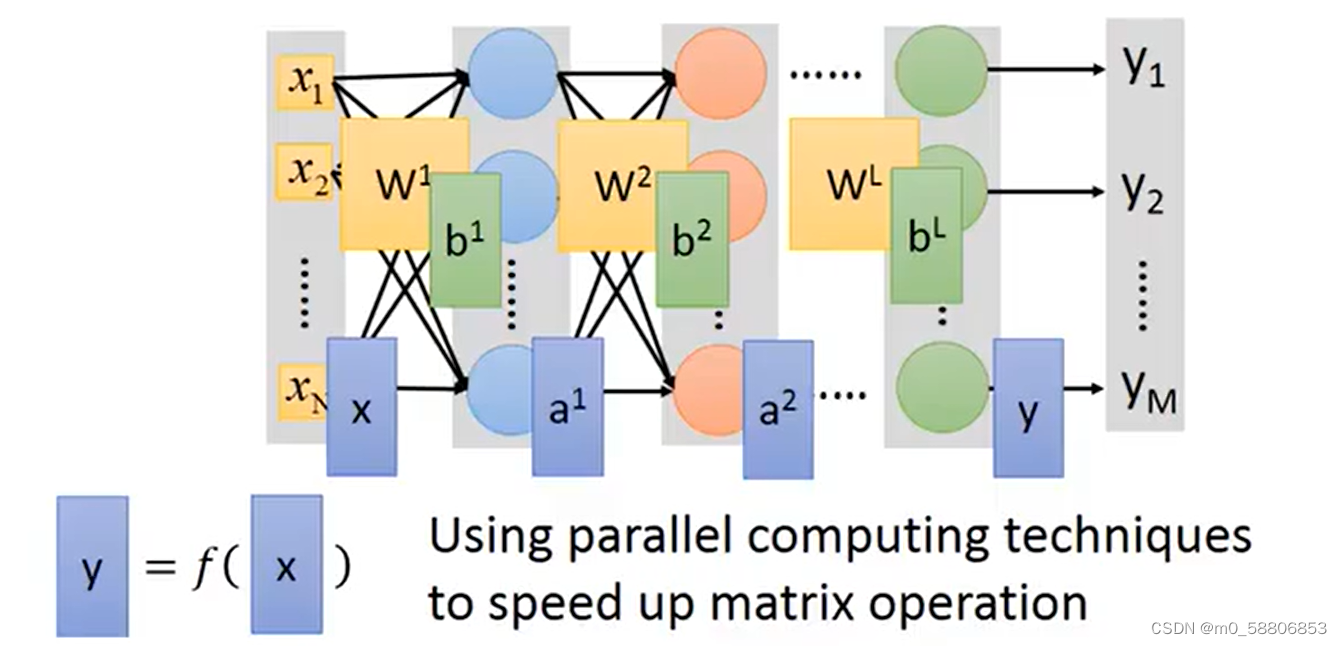
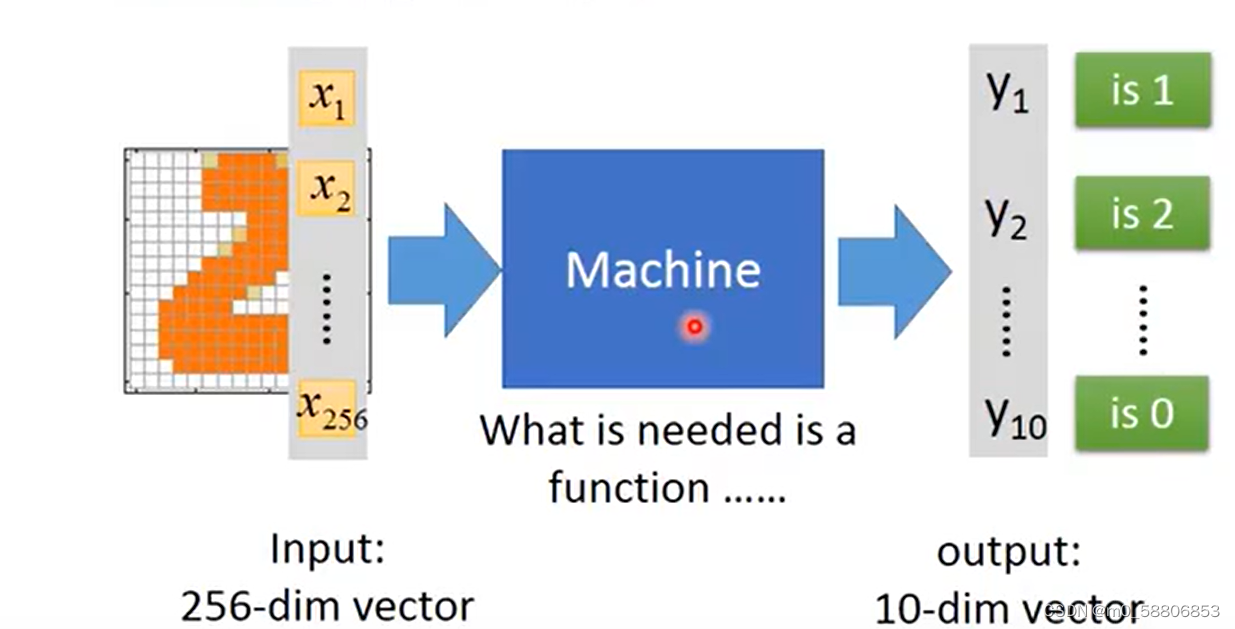
输入数据首先被传入神经网络的输入层。数据随后通过神经网络的各个层,包括隐藏层,进行逐层计算和变换。在每一层中,输入数据(或前一层的输出)与当前层的权重矩阵相乘,并加上偏置项,然后通过激活函数进行非线性变换,得到该层的输出。这个过程重复进行,直到数据通过所有隐藏层传递到输出层。输出层的输出即为神经网络的最终预测结果。例如:判断图片中是什么数字的问题过程。
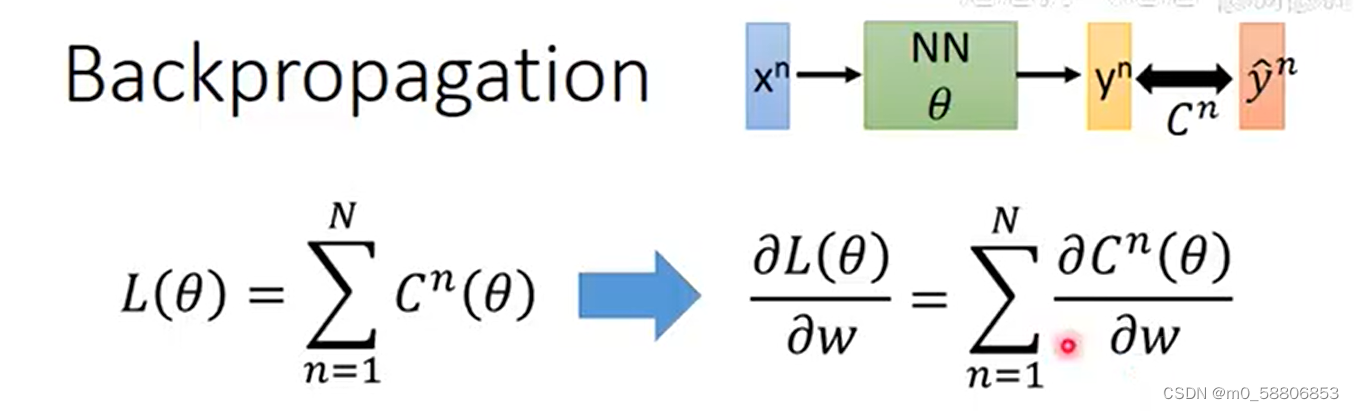
4.反向传播
反向传播(Backpropagation)是神经网络中一种重要的训练算法,用于调整网络的参数(如权重和偏置),使得网络能够更好地拟合训练数据并提高在未见过的数据上的泛化能力,从损失函数开始,通过链式法则(Chain Rule)计算每个参数(权重和偏置)对损失函数的影响(即梯度)。
首先计算出每一个预测值和实际值之间的差值C,将所有的差值相加即可获得全部的Loss。
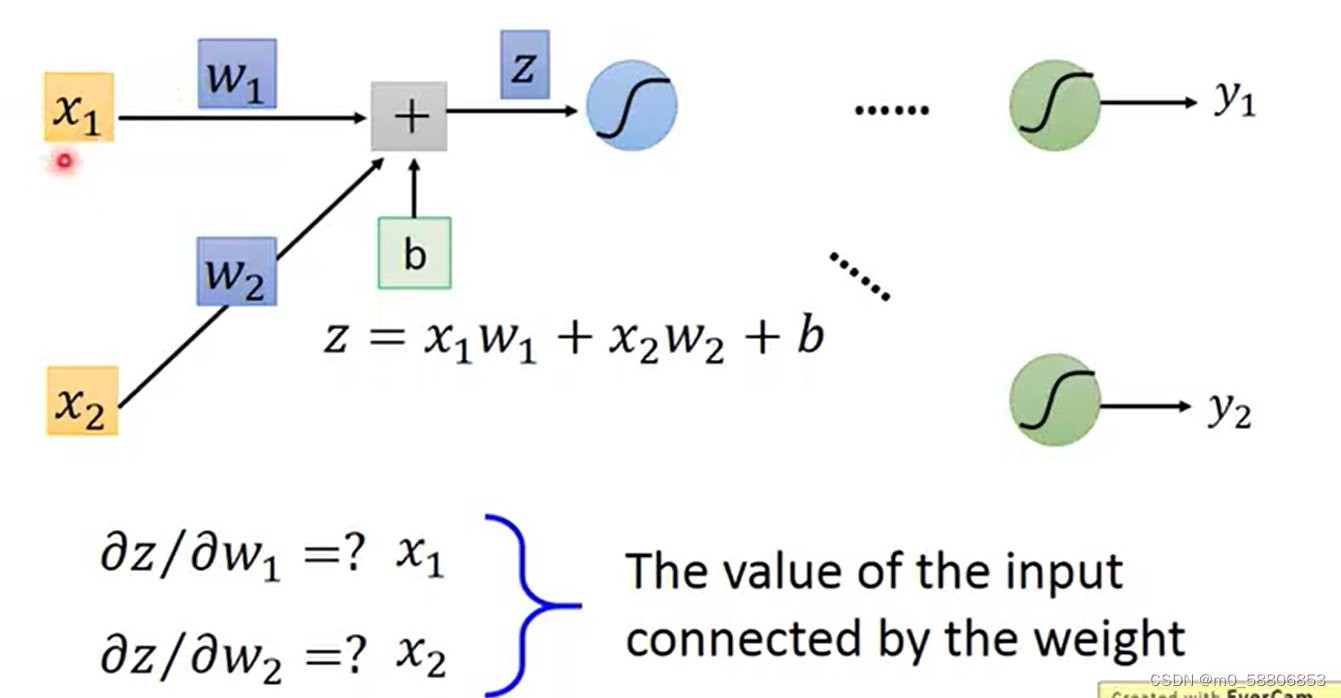
以对w求偏导为例,将模型局部放大。由链式法则可得c对w求偏导即为c对z求偏导乘以z对w求偏导,计算z对w求偏导的过程称为forword pass,计算C对z求偏导的过程称为Backward pass。
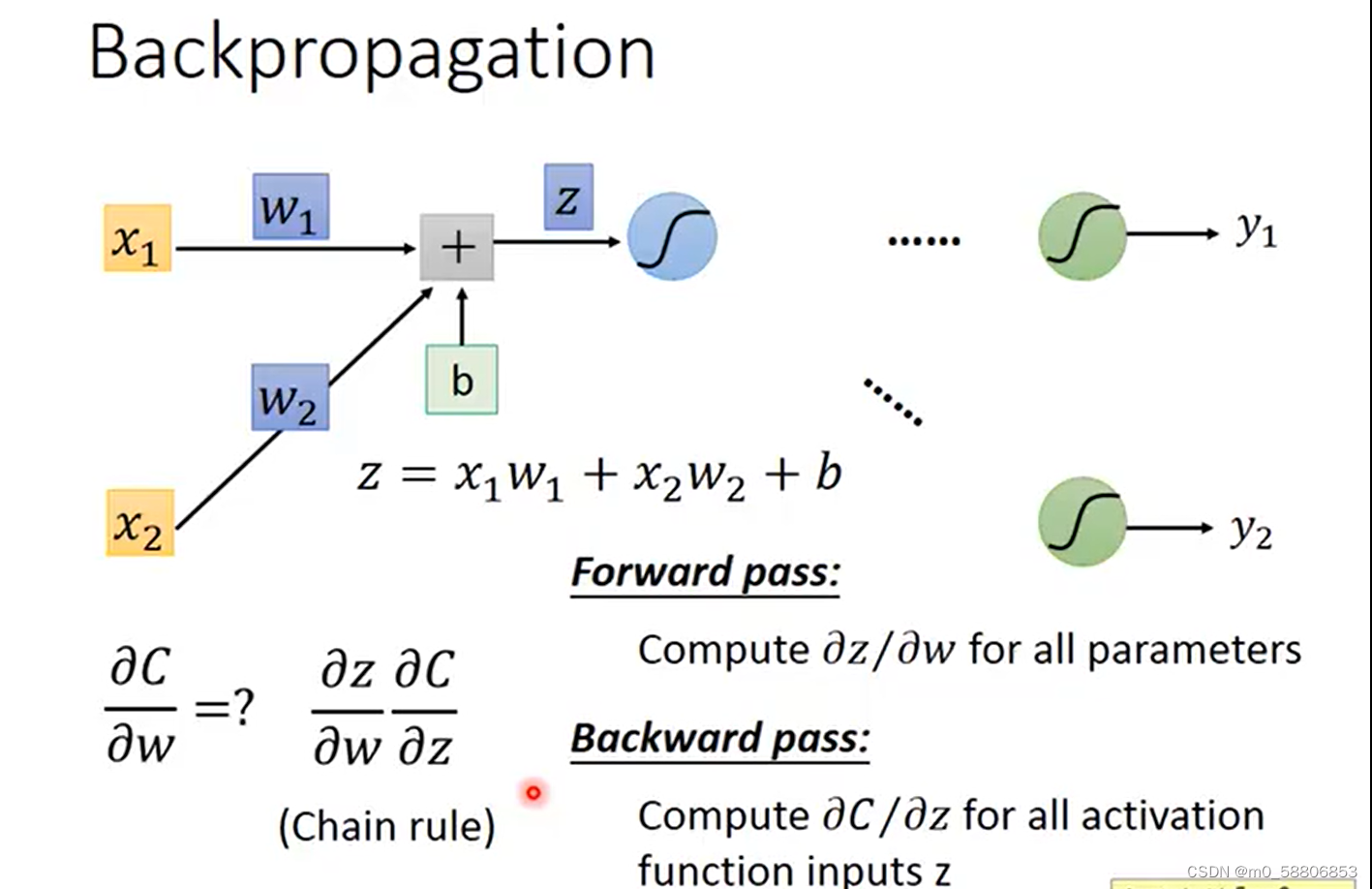
forword pass的过程中我们可以得出一个规律,z对w的偏导为与w相连接的input值。
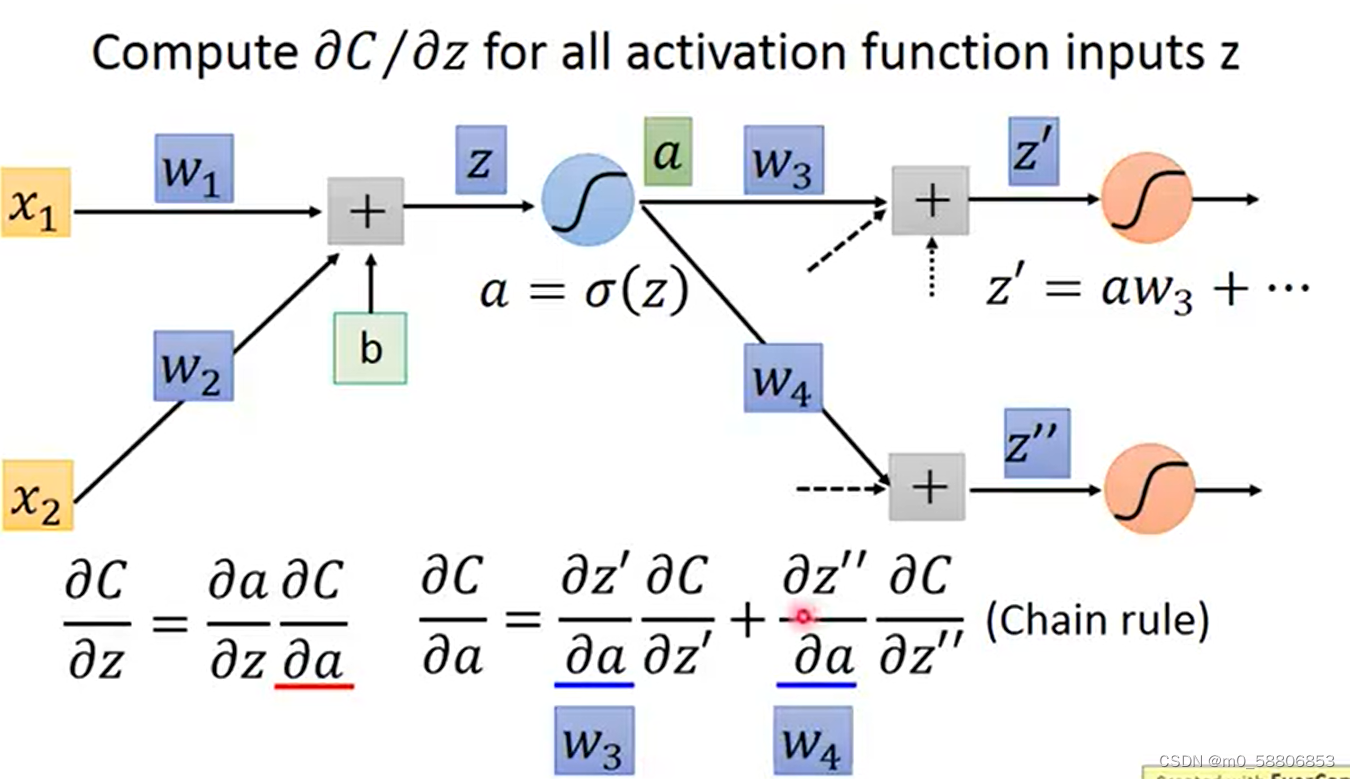
求C对z偏导的过程可拆分为C对a求偏导乘以a对z求偏导,其中C对a求偏导为后续所有与a有函数关系项的偏导值相加得出。















 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









