






2024年12月7日-12月11日,第70届IEDM大会在美国旧金山召开。复旦大学芯片与系统前沿技术研究院的刘明院士团队与中科院微电子所合作在会上展示了融合非易失性铁电和易失性电荷俘获的动态存算类脑阵列,并演示了在轨迹预测方面的应用,本篇文章我们详细介绍这篇论文《Experimental Demonstration of A CT-FeFET Array with Intrinsic Long-Short-Term Plasticity for Low-Cost Trajectory Prediction》[1]。
- 文章背景及挑战
本文题目为《Experimental Demonstration of A CT-FeFET Array with Intrinsic Long-Short-Term Plasticity for Low-Cost Trajectory Prediction》,第一作者是复旦大学芯片与系统前沿技术研究院的博士生李超和博士后余杰,来自刘明院士团队。该团队长期从事微电子科学技术领域的研究,主要研究存储器模型机理、材料结构、核心共性技术和集成电路微纳加工。主要成果包括建立了阻变存储器(RRAM)物理模型,提出并实现高性能RRAM和集成的基础理论和关键技术方法。拓展了新型闪存材料和结构体系,提出新的可靠性表征技术、失效模型和物理机理,开发了国内首款自主IP的8M纳米晶和1G NOR型存储芯片。
自动驾驶中,轨迹预测是一个至关重要的功能,通常使用LSTM类型的网络来实现,已有的静态存内计算技术对长期参数(long-term parameter)进行了加速,但短期参数(short-term parameter)的推理计算仍面临较大的缓存开销。具体来说,从缓存中获取历史状态并在每个时间步存储当前输出会消耗大量时间并降低能效。
本文作者团队注意到,在生物系统中,历史信息可以存储在原位的短时程突触可塑性中,作者以此为指导开发新的硬件系统以执行LSTM网络。在静态权重的基础上,本文提出了一种新的方法,对历史信息进行原位编码,同时对长期参数和短期参数进行加速,称为动态存内计算。通过这种方式,消除历史信息的额外缓存,提供低延时、低功耗的解决方案。作者团队首次实现电荷俘获铁电场效应晶体管(CT-FeFET)阵列,结合LIF神经元构建了一个轨迹预测系统,用于执行动态存内计算,实现车辆移动位置的预测。
文章的创新点有:
1)首创电荷俘获铁电场效应管阵列
2)通过界面工程实现铁电极化与电荷俘获的解耦机制
3)构建长短期记忆融合的动态存内计算架构
- 本文解决方案
1)具有长短时程融合可塑性的CT-FeFET
图1(左)展示了CT-FeFET器件制备的过程流,并展示了其电镜图。该器件包含通过ALD沉积的8.74 nm Hzo介电层。通过界面工程,由4-s O3的Si处理产生了0.79 nm含有浅缺陷的SIO IL,该IL支持在较低VG下更容易的CT,从而实现易挥发功能。栅极介电HZO提供铁电动力学。当栅极电场超过开关阈值时,HZO极化,提供VTH的多级非易失性调制。CT和FS可以通过VG解耦,支持动态存算操作(IMC)。图1(右)展示了CT-FeFET的融合CT-FS曲线,并进一步解释了器件在CT和FS过程中的能带。
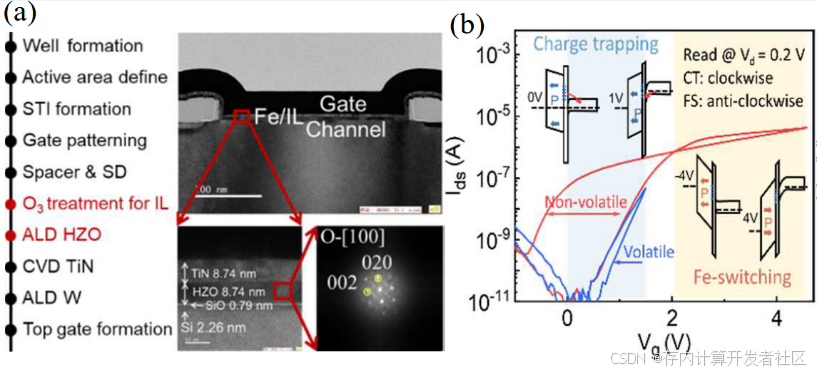
图1 (左)制备过程流与电镜图(右)传输曲线与能带图
图2展示了在不同脉冲下的Vth偏移,当VG>2.2V时Vth偏移发生,表示FS过程的开始。

图2 Vth在不同脉冲下的偏移
图3展示了在多级FS状态下,VG=1.5V/10us连续进行CT时,Ids非常稳定,表明CT操作不会影响到FS。
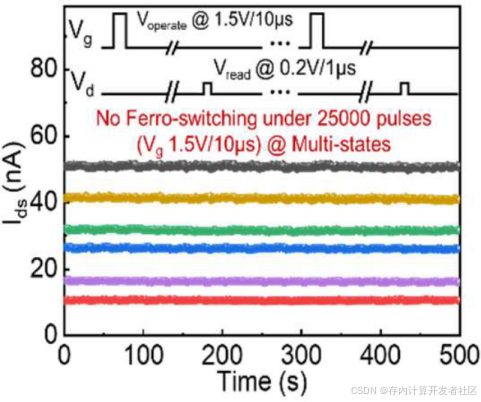
图3 CT与FS过程的脱钩
2)CT-FeFET阵列的特征
在长时状态下,图4从左至右分别展示了:a)从1K阵列中随机选择的64个器件的直流曲线,图片显示了Vth的统计分布,在DC测试下的MW为1.5V;b)和c)展示了阵列在C2C和D2D状态下的统计变化;d)电导率在室温条件下可保持超过1800s,可以支持长期稳定的存储;

图4 长时状态下对于阵列的测试
在短时状态下,图5从左至右分别展示了:a)在1.5V的VG脉冲下的PPD情况,在连续脉冲情况下,通道电流由于CT的积累而减小,导致第二脉冲峰A2低于第一个峰A1,右面板显示ID中峰值电流的逐渐下降,而在不同的长期FS状态下增加了刺激脉冲;b)展示了脉冲A2/A1的统计数据,随着脉冲间隔的增加,捕获的电荷会自动恢复。作者用指数函数对PPD比率进行了拟合,抑制在f0 = 0.127MHz下达到饱和。c)为了测试CT过程的稳定性,作者在每个PPD测试的门上应用了连续的1.5 V/300 NS脉冲,并且PPD功能显示出具有> 1010 CT过程的可忽略的降解,该过程证明阵列可以执行长时间的动态IMC。d)作者将频率变化的脉冲序列(0.01〜0.5MHz)应用于CT-FeFET,以匹配动态预期网络的输入。Ids与长期状态W有关,并由短期抑制因子h调节。 h结合了历史信息ht-1和当前的输入频率f,从而实现了时间信息的存储和计算。 Ids定义为动态IMC因子。为了达到明显的抑制效应,预期系统中的频率编码设置为0.01至0.025 MHz。
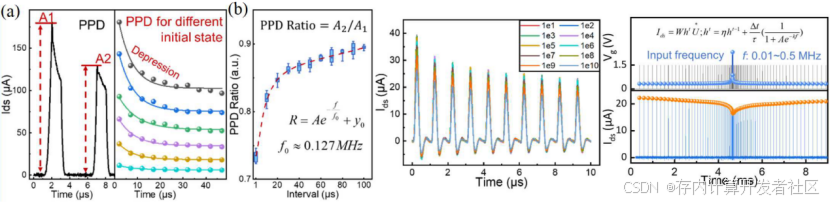
图5 短时状态下对于阵列的测试
3)构建长短期记忆融合的动态存内计算架构
受生物神经元长短期突触可塑性启发,作者提出一种基于铁电场效应晶体管(CT-FeFET)阵列的动态IMC架构,通过硬件层面融合长短期记忆参数,实现历史状态的原位存储与实时更新。该架构的关键创新在于利用CT-FeFET的物理特性,将长期参数固化于铁电畴的非易失性极化状态中,而短期参数则通过电荷俘获层的动态载流子迁移实时调控,从而实现长短期权重的协同计算(如图6所示)。
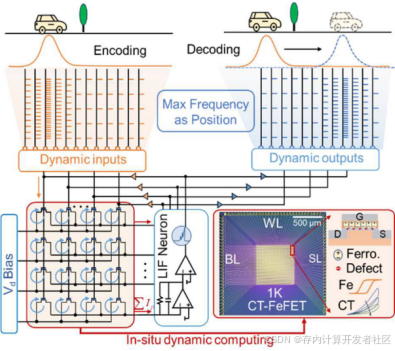
图6 基于长短时记忆融合的CT-FeFET阵列的轨迹预测动态IMC系统
为了使用该CT-FeFET阵列进行轨迹预测任务,作者进一步构建了一个包含32个神经元的预测网络(如图7(a)所示)。每个神经元代表一个特定的位置,并通过动态突触与其他所有神经元相连。神经元接收运动物体的位置作为输入,同时接收来自其他神经元的突触电流。具有最高放电频率输出的神经元代表预测位置。网络的数学模型如图7(a)右图所示,CT-FeFET阵列作为动态突触,可以在每个时间步进行原位动态存内计算操作。图7(b)展示了整个预测系统的工作流程。图7(c)展示了测试装置,包括动态存内计算板、示波器和上位机。与传统静态IMC系统相比,动态架构通过硬件层面的长短期权重融合,将预测延迟从毫秒级压缩至纳秒级,同时显著降低功耗。
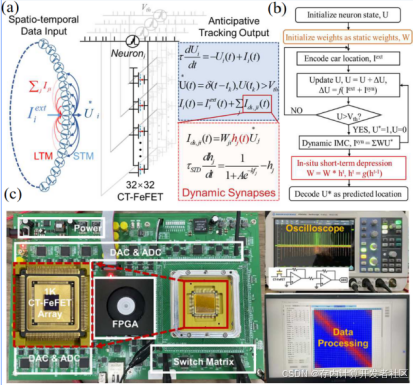
图7 动态存内计算网络的拓扑结构,轨迹预测系统的工作流程及相关测试装置
- 实验结果与结论
动态存内计算系统的性能在KITTI自动驾驶数据集与硬件原型上得到了全面验证。如图8所示,当前车辆的位置作为输入(黑线)时,系统的输出可以预测运动(红线,超前于黑线)时车辆的位置。相比之下,相同结构的静态IMC网络只能跟踪车辆的位置(蓝线,落后于黑线)。这一结果表明,本文的动态网络可以支持预测跟踪任务,实现类似于LSTM网络的效果。
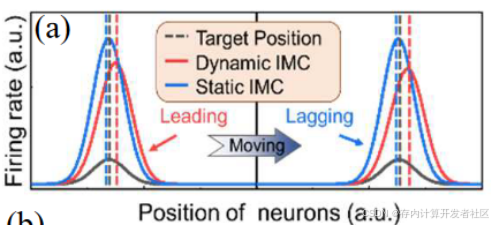
图8 动态网络与具有相同结构的静态网络结果对比图
作者进一步评估了系统的功耗和内存开销。如下图9所示,与GPU和SoC相比,分别实现大于1000倍的功耗降低和大于4倍的内存开销降低。
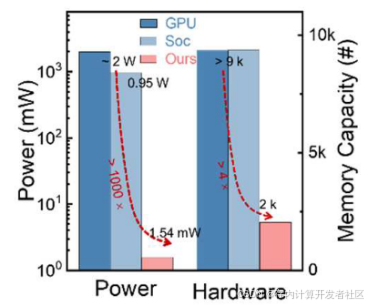
图9 GPU、SoC和CT-FeFEF阵列的功耗和内存容量需求对比图
此外,作者与已报道的先进工作(图10)相比,充分体现了本文设计的特点。作者通过在SiO IL中引入浅缺陷来解耦CT和FS效应,通过CT - FeFETs的本征动力学实现了原位的短期信息计算。非易失性融合突触的集成为系统提供了历史状态信息,增强了网络的跟踪性能并实现了预测能力,在功耗和内存开销方面具有比GPU和SoC更低的优势。本工作通过长短期记忆的硬件融合与算法协同优化,为高实时、低功耗的自动驾驶轨迹预测提供了可行的解决方案,使用动态存内计算单元构建高效的AI芯片开辟了一条新的道路。
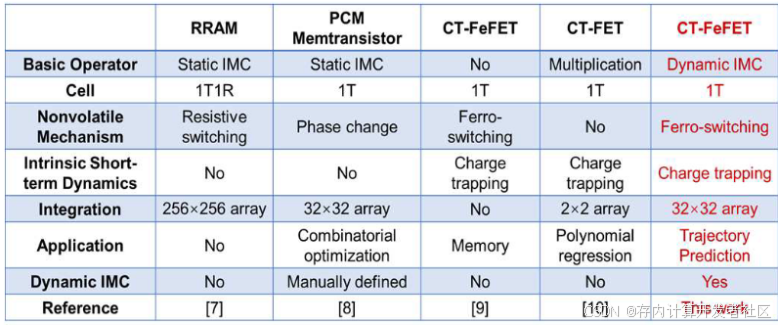
图10 与使用新兴器件的其他IMC工作进行比较
参考资料
[1] Li, Chao, et al. "Experimental Demonstration of A CT-FeFET Array with Intrinsic Long-Short-Term Plasticity for Low-Cost Trajectory Prediction." 2024 IEEE International Electron Devices Meeting (IEDM). IEEE, 2024.

















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









