







 本文介绍了使用MobileNet构建的垃圾识别模型,包括数据预处理、模型结构设计(关注全连接层调整)、训练策略(交叉熵损失函数和可训练层设置)、高精度94.1%的性能以及搭建的GUI界面。代码提供下载,详阅附带的文档以获取完整流程。
本文介绍了使用MobileNet构建的垃圾识别模型,包括数据预处理、模型结构设计(关注全连接层调整)、训练策略(交叉熵损失函数和可训练层设置)、高精度94.1%的性能以及搭建的GUI界面。代码提供下载,详阅附带的文档以获取完整流程。
第一步:准备数据
三种垃圾数据:厨房垃圾,危害性垃圾,可回收垃圾,总共10162张图片

第二步:搭建模型
本文选择MobileNe,其网络结构如下:
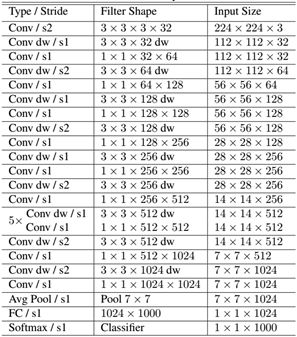
由于是三分类问题,直接套用网络肯定是不行,因此会在全连接部分做手脚,参考代码如下:
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(256)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Dense(64)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Dense(class_num)(x)
predictions = Activation('softmax')(x)
# for layer in base_model.layers:
# layer.trainable = True
model = Model(inputs=base_model.input, outputs=predictions)
return model第三步:训练代码
1)损失函数为:交叉熵损失函数
2)MobileNet可以从头训练或者利用预训练模型进行训练:
def MobileNet_model(width, height, class_num):
w = 1
if w:
base_model = MobileNet(weights='imagenet', include_top=False, input_shape=(width, height, 3))
else:
base_model = MobileNet(weights=None, include_top=False, input_shape=(width, height, 3))
for layer in base_model.layers:
layer.trainable = True第四步:统计正确率
|
|
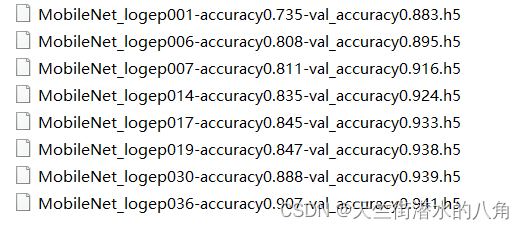
正确率高达94.1%
第五步:搭建GUI界面

第六步:整个工程的内容
有训练代码和训练好的模型以及训练过程,提供数据,提供GUI界面代码,主要使用方法可以参考里面的“文档说明_必看.docx”
代码的下载路径(新窗口打开链接):基于keras框架的MobileNet神经网络垃圾识别分类系统源码

有问题可以私信或者留言,有问必答















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









