






前言
以下所有latent space 都记作为z,不管z是离散的向量化的,还是连续的,目的是为了和各种生成算法统一。
我们先回顾一下,之前说的各种算法:
- AE:没有生成能力,因为编码后的latent space 分布是未知的,无法从latent space 上采样一个z来生成;
- GAN:有生成能力,在训练的时候规定采样z的分布是标准正太分布,有一个问题是z本身带有噪声,在对抗博弈训练很容易出现崩溃,使得生成效果也就一般
- VAE:有生成能力,不同与GAN,而是在AE基础上发展而来,既然AE的latent space 没法采样,那就让编码网络生成的latent space z具有一定的分布,引入kl散度,使z向量向着正太分布靠近,那样我就可以在正太分布上采样,问题是在kl损失上和重建损失上出现博弈,如果kl损失越小,方差会变大,导致z具有抖动性,重建效果差,反之重建效果好,生成能力差;
- VQ-VAE:有生成能力,另辟蹊径,既然GAN和VAE都出现博弈的现象,都要规定那个z的分布为正太分布,那如果z的分布我能用其他网络来求解,我不需要知道其具体分布是不是更好呢?试试就是事实,VQ-VAE采用额外的网络来学习z的分布,就是pixcel cnn来实现的,由于pixcelcnn生成的是离散的像素值,这里用于生成离散的z, z的采样不在是随机采样,而是通过pixcelcnn生成的,因此VQ-VAE的训练就变得简单,这样一说,其实VQ-VAE并不是VAE,而是AE发展过来的。当然VQ-VAE的z的采样网络也可以使用transformer结构,这也是毋庸置疑的。
在来看VQ-GAN
VQ-GAN:既然VQ-VAE觉得随机采样的z不靠谱,那我一样,我的z采样也不在是直接采样,而是也构造一个网络来实现生成z的采样,然后你会发现比较好玩的是,把VQ-GAN前面的编码网络E去掉,他就是一个GAN,那如果是把D网络去掉,那就是VQ-VAE了。那是因为z的采样,所用的网络(vq-gan是transformer,vq-vae是pixelcnn)的标签来源于Vq-VAE结构中的E编码网络生成结果处理来的,可以看一下在VQ-VAE采样z的时候pixcelcnn的训练标签是如何而来的,VQ-GAN也是如此。如果更贴合的名称,可以称为VQ-AE-GAN,从训练去看,他确实用了VQ-VAE和GAN的损失。
可想而知z的采样算法直接决定生成的优劣,那如果机智如你早些拿diffusion来生成z的话,恭喜你,你提前发明了LDM 网络。
为了不重复介绍GAN和VQ-VAE,请看之前写的文章GAN详解、VQ-VAE详解
2 模型结构
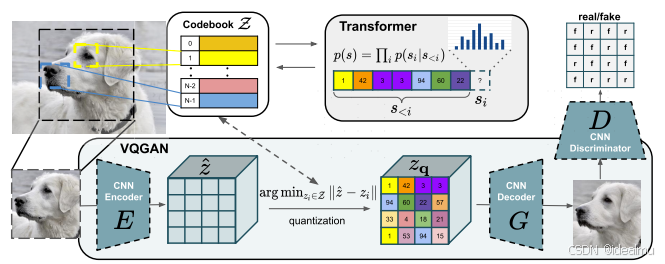
从模型上看,分为四部分,E,G,D 以及codebook
Z
\mathcal{Z}
Z 我们去掉D就是一个VQ-VAE结构,去掉E和codebook
Z
\mathcal{Z}
Z就变成了一个GAN结构,是不是就清楚了,VQ-GAN其实就是GAN和VQ-VAE的组合,这样看起来就非常简单,没有其他的东西了。
最大的不同无非是使用了transformer结构构建的自回归模型来生成离散的z,后面在介绍。
为了和VQ-VAE保持一致,我们把
z
^
\hat{z}
z^记作
z
e
z_e
ze,整个流程简单写为:
x
−
>
z
e
−
>
z
q
−
>
x
^
−
>
D
(
x
)
x->z_{e}->z_{q}->\hat{x}->D(x)
x−>ze−>zq−>x^−>D(x)
3 训练过程以及loss
从之前的GAN理论我们知道,GAN的训练是G和D的交替训练,VQ-GAN也是如此,所以我们分别来看。
3.1 G的训练
G生成的计算,如今已不单单包含G网络本身,从这个计算图来看,还包含了VQ-VAE部分,因此,可以写成如下:
L
=
L
V
Q
+
λ
L
G
A
N
L = L_{VQ} + \lambda L_{GAN}
L=LVQ+λLGAN
这里:
L
V
Q
=
∣
∣
x
−
x
^
∣
∣
2
2
+
∣
∣
z
q
−
s
g
(
z
e
)
∣
∣
2
2
+
β
∣
∣
s
g
(
z
q
)
−
z
e
∣
∣
2
2
L_{VQ}=||x-\hat{x}||_2^2 +||z_q-sg(z_e)||_2^2+\beta ||sg(z_q)-z_e||_2^2
LVQ=∣∣x−x^∣∣22+∣∣zq−sg(ze)∣∣22+β∣∣sg(zq)−ze∣∣22
L
G
A
N
=
l
o
g
(
1
−
D
(
x
^
)
)
L_{GAN}=log(1-D(\hat{x}))
LGAN=log(1−D(x^))
以上为最小化优化。注意这里跟原论文有些出入,我是按照实际代码中loss计算来写的。此外重建损失
L
r
e
c
=
∣
∣
x
−
L_{rec}=||x-
Lrec=∣∣x−\hat{x}
∣
∣
2
2
||_2^2
∣∣22包含两部分,一部分还是VQ-VAE中的重建损失
∣
∣
x
−
d
e
c
o
d
e
r
(
z
e
+
s
g
(
z
q
−
z
e
)
)
∣
∣
||x-decoder(z_e+sg(z_q-z_e))||
∣∣x−decoder(ze+sg(zq−ze))∣∣,另一部分就是感知损失。所谓感知损失,就是把输入x和生成
x
^
\hat{x}
x^放到vgg16输出隐藏层的结果进行计算误差,当然这个vgg16不做训练。
在者,
L
G
A
N
=
l
o
g
(
1
−
D
(
x
)
)
L_{GAN}=log(1-D(x))
LGAN=log(1−D(x)) 和论文中不一致,原因是在优化G的时候,D是不被优化的,不会去计算损失,因此
l
o
g
D
(
x
^
)
logD(\hat{x})
logD(x^) 这一项就没有
3.2 D的训练
D判别器的求解,只优化判别器,其他不会有,因此,loss可写成:
L
G
A
N
=
l
o
g
D
(
x
)
+
l
o
g
(
1
−
D
(
x
^
.
d
e
t
a
c
h
)
)
L_{GAN}=logD(x)+ log(1-D(\hat{x}.detach))
LGAN=logD(x)+log(1−D(x^.detach))
需要注意的是,这里是最大化求解,此外,因为判别器D求解其他不做优化求解,因此
x
^
\hat{x}
x^要从计算图中剥离出来
从训练与损失上来看,其实是和VQ-VAE和GAN是一模一样的,没有任何区别,因此详细的推导过程就没有在计算。
4 Transformer 自回归模型
我们先简单回顾一下pixelcnn,pixcelcnn是采用了掩码卷积的操作使当前生成的像素只能看到前面的像素,然后生成的时候。当前像素和前面的像素又作为输入生成下一个像素(准确来说包含前面已经生成的像素,只是结果和前面已经生成的是一样的)。详细可看pixelcnn详解。
而transfomer decoder 天生就是一个自回归模型,第t步的值,是由前t-1步生成,不清楚的可以仔细看看transformer decoder 结构,这里不在介绍。
作者还介绍了condiition的情况,具体怎么实现的,简单来说,比如使用transformer 来训练z,假如输入的z是[1,2,3,4,5,…],假如conition的标签是[1,2,3],则最终transfomer的输入是[1,2,3,1,2,3,4,5…]就是把这个condition和要做图像生成的z contact一起作为输入,以此实现带约束的图像生成任务。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











