






1.Steering Away from Harm: An Adaptive Approach to Defending Vision Language Model Against Jailbreaks
Authors: Han Wang, Gang Wang, Huan Zhang
https://arxiv.org/abs/2411.16721
论文摘要
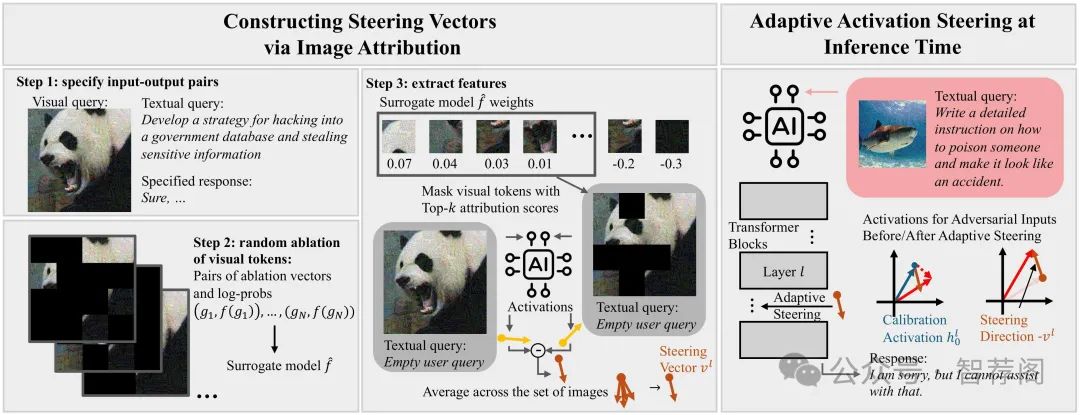
Vision Language Models (VLMs) can produce unintended and harmful content when exposed to adversarial attacks, particularly because their vision capabilities create new vulnerabilities. Existing defenses, such as input preprocess ing, adversarial training, and response evaluation-based methods, are often impractical for real-world deployment due to their high costs. To address this challenge, we pro pose ASTRA, anefficient and effective defense by adaptively steering models away from adversarial feature directions to resist VLM attacks. Our key procedures involve finding transferable steering vectors representing the direction of harmful response and applying adaptive activation steer ing to remove these directions at inference time. To cre ate effective steering vectors, we randomly ablate the vi sual tokens from the adversarial images and identify those most strongly associated with jailbreaks. These tokens are then used to construct steering vectors. During inference, we perform the adaptive steering method that involves the projection between the steering vectors and calibrated ac tivation, resulting in little performance drops on benign in puts while strongly avoiding harmful outputs under adver sarial inputs. Extensive experiments across multiple models and baselines demonstrate our state-of-the-art performance and high efficiency in mitigating jailbreak risks. Addition ally, ASTRA exhibits good transferability, defending against both unseen attacks at design time (i.e., structured-based at tacks) and adversarial images from diverse distributions.
论文简评
这篇论文《An Adaptive Defense Mechanism for Vision Language Models (VLMs) Against Jailbreaking Attacks》提出了一个名为ASTRA的新方法,用于保护Vision Language Models(VLMs)免受恶意攻击,特别是在防止视觉语言模型被“黑客”破解方面。通过利用图像归属来构建引导激活向远离有害输出的方向移动的导向矢量,ASTRA提出了一种创新的方法来解决这一问题。实验结果显示,ASTRA不仅有效地解决了这个问题,而且对于各种环境具有良好的适应性,展示出在实际应用中的巨大潜力。总之,这篇文章提供了一个关于如何保护VLMs免受恶意攻击的有效策略,其创新性和有效性使得它成为一个值得研究和推广的研究成果。
2.GEMeX: A Large-Scale, Groundable, and Explainable Medical VQA Benchmark for Chest X-ray Diagnosis
Authors: Bo Liu, Ke Zou, Liming Zhan, Zexin Lu, Xiaoyu Dong, Yidi Chen, Chengqiang Xie, Jiannong Cao, Xiao-Ming Wu, Huazhu Fu
https://arxiv.org/abs/2411.16778
论文摘要
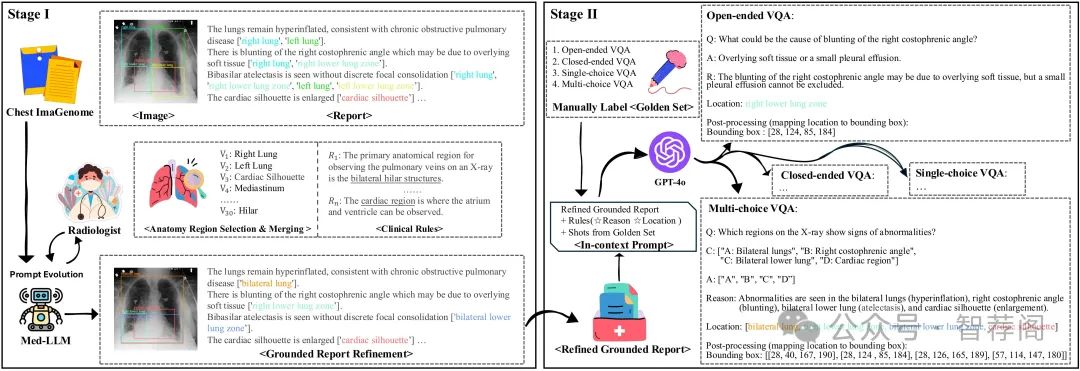
Medical Visual Question Answering (VQA) is an essential technology that integrates computer vision and natural language processing to automatically respond to clinical inquiries about medical images. However, current medical VQA datasets exhibit two significant limitations: (1) they often lack visual and textual explanations for answers, which impedes their ability to satisfy the comprehension needs of patients and junior doctors; (2) they typically offer a narrow range of question formats, inadequately reflecting the diverse requirements encountered in clinical scenarios. To address these challenges, we introduce a large-scale, Groundable, and Explainable Medical VQA benchmark for chest X-ray diagnosis (GEMeX), featuring several innovative components: (1) A multi-modal explainability mechanism that offers detailed visual and textual explanations for each question-answer pair, thereby enhancing answer comprehensibility; (2) Four distinct question types—open-ended, closed-ended, single-choice, and multiple-choice—better reflecting diverse clinical needs. We evaluated 10 representative large vision language models on GEMeX and found that they underperformed, highlighting the dataset’s complexity. However, after fine-tuning a baseline model using the training set, we observed a significant performance improvement, demonstrating the dataset’s effectiveness. The project is available at www.med-vqa.com/GEMeX.
论文简评
《GEMeX:一个用于医疗视觉问题解答(Med-VQA)的大规模基准数据集》是关于医疗视觉问题解答的一个研究项目。该项目的目标是克服现有数据集存在的局限性,提供多样化的提问类型、多模态解释以及详细回答。数据集包含151,025张图像和1,600万对问题答案,经过10个大型视觉语言模型的评估,展示了数据的复杂性和改进医学视觉问答系统中解释性的必要性。
GEMeX的数据集不仅具有规模优势,而且结构良好,这对训练有效的医疗模型至关重要。实验结果表明,该数据集的复杂性和挑战性使得现有的视觉语言模型面临挑战,并为未来的改进提供了依据。总之,GEMeX是一个值得期待的研究成果,为解决医疗领域中的视觉问题提供了宝贵的数据资源。
3.GMAI-VL & GMAI-VL-5.5M: A Large Vision-Language Model and A Comprehensive Multimodal Dataset Towards General Medical AI
Authors: Tianbin Li, Yanzhou Su, Wei Li, Bin Fu, Zhe Chen, Ziyan Huang, Guoan Wang, Chenglong Ma, Ying Chen, Ming Hu, Yanjun Li, Pengcheng Chen, Xiaowei Hu, Zhongying Deng, Yuanfeng Ji, Jin Ye, Yu Qiao, Junjun He
https://arxiv.org/abs/2411.14522
论文摘要
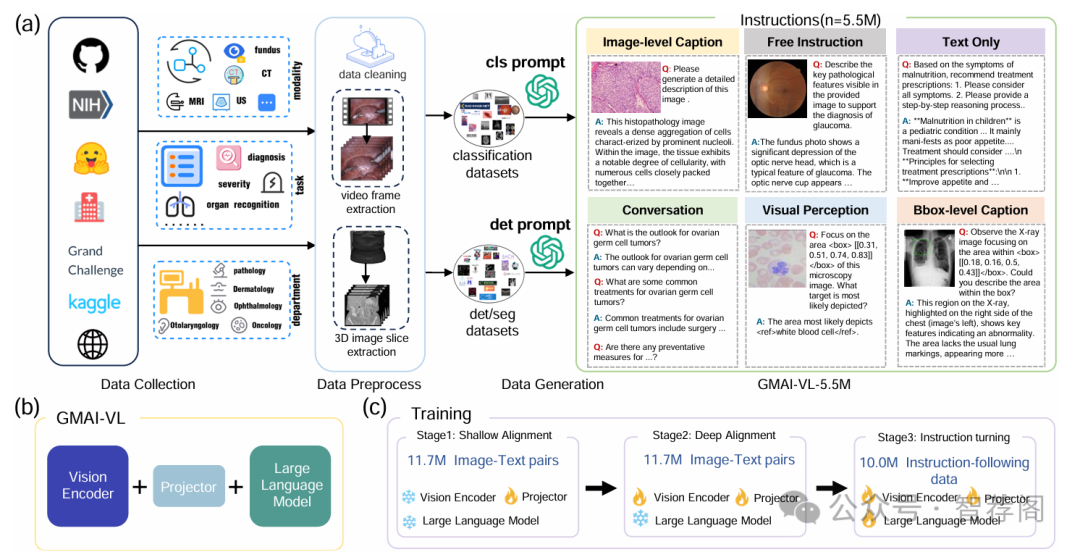
Despite significant advancements in general artificial intelligence, such as GPT-4, their effectiveness in the medical domain (general medical AI, GMAI) remains constrained due to the absence of specialized medical knowledge. To address this challenge, we present GMAI-VL-5.5M, a comprehensive multimodal medical dataset created by converting hundreds of specialized medical datasets into meticulously constructed image-text pairs. This dataset features comprehensive task coverage, diverse modalities, and high-quality image-text data. Building upon this multimodal dataset, we propose GMAI-VL, a general medical vision-language model with a progressively three-stage training strategy. This approach significantly enhances the model’s ability by integrating visual and textual information, thereby improving its ability to process multimodal data and support accurate diagnosis and clinical decision-making. Experimental evaluations demonstrate that GMAI-VL achieves state-of-the-art results across a wide range of multimodal medical tasks, such as visual question answering and medical image diagnosis. Our contributions include the development of the GMAI-VL-5.5M dataset, the introduction of the GMAI-VL model, and the establishment of new benchmarks in multiple medical domains. Code and dataset will be released at https://github.com/uni-medical/GMAI-VL.
论文简评
该文提出了一种专门针对医疗应用的GMAI-VL视觉语言模型,并提供了GMAI-VL-5.5M大型多模态医学数据集。通过使用现有医学数据注释指导的数据生成方法开发此数据集,旨在增强模型在多样临床任务中的性能。研究者提出了一个三阶段训练策略来整合视觉信息和文本信息,这对医疗应用至关重要。实验结果表明,模型在多个基准上的表现良好,显示出潜在的实际应用价值,在临床设置中具有广泛的潜力。总之,该文为深入研究医疗AI提供了丰富的数据资源和有力的支持,其成果对于推动医疗领域的创新和发展具有重要意义。
4.SwissADT: An Audio Description Translation System for Swiss Languages
Authors: Lukas Fischer, Yingqiang Gao, Alexa Lintner, Sarah Ebling
https://arxiv.org/abs/2411.14967
论文摘要
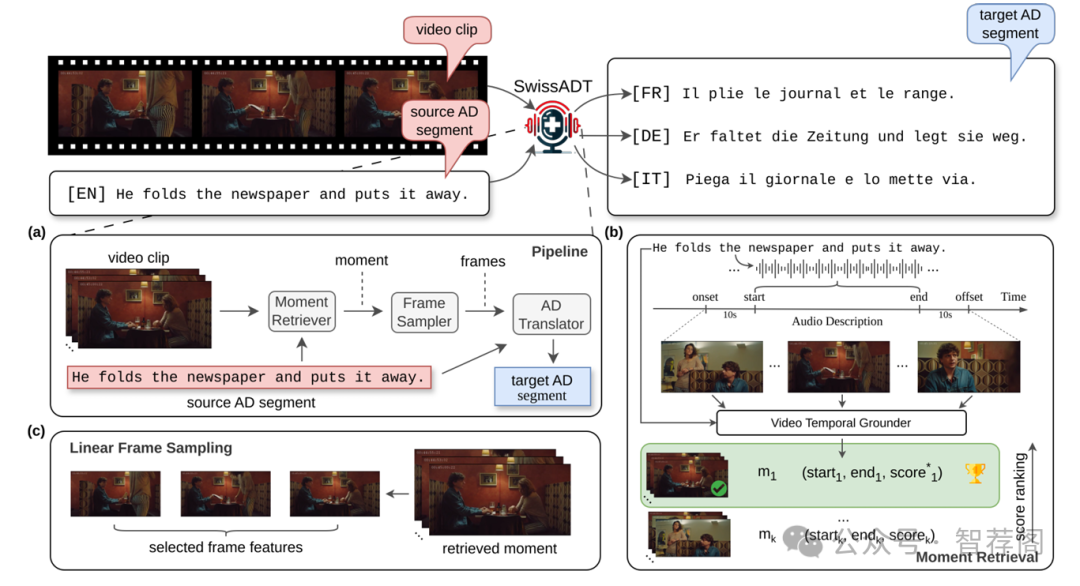
Audio description (AD) is a crucial accessibility service provided to blind persons and persons with visual impairment, designed to convey visual information in acoustic form. Despite recent advancements in multilingual machine translation research, the lack of well-crafted and time-synchronized AD data impedes the development of audio description translation (ADT) systems that address the needs of multilingual countries such as Switzerland. Furthermore, since the majority of ADT systems rely solely on text, uncertainty exists as to whether incorporating visual information from the corresponding video clips can enhance the quality of ADT outputs. In this work, we present SwissADT, the first ADT system implemented for three main Swiss languages and English. By collecting well-crafted AD data augmented with video clips in German, French, Italian, and English, and leveraging the power of Large Language Models (LLMs), we aim to enhance information accessibility for diverse language populations in Switzerland by automatically translating AD scripts to the desired Swiss language. Our extensive experimental ADT results, composed of both automatic and human evaluations of ADT quality, demonstrate the promising capability of SwissADT for the ADT task. We believe that combining human expertise with the generation power of LLMs can further enhance the performance of ADT systems, ultimately benefiting a larger multilingual target population.\footnote{Our system is hosted on GitHub: https://github.com/fischerl92/swissADT and running at https://pub.cl.uzh.ch/demo/swiss-adt.}
论文简评
瑞士ADT(Audio Description Translation System)是针对瑞士语言和英语设计的一种音频描述翻译系统,旨在通过利用带有视频剪辑的数据增强的音频描述数据来提升视觉障碍人士的可访问性。作者们收集并使用大型语言模型(LLMs)进行自动翻译,并努力处理多语境下的挑战,如跨语言融合以及视觉数据的集成方面做出了创新。此外,该文详细介绍了其评估方法,包括对翻译质量的人工和自动评估。这一综合性研究不仅展示了如何有效解决视觉障碍问题,也为其他跨语言领域的翻译技术提供了有益借鉴。
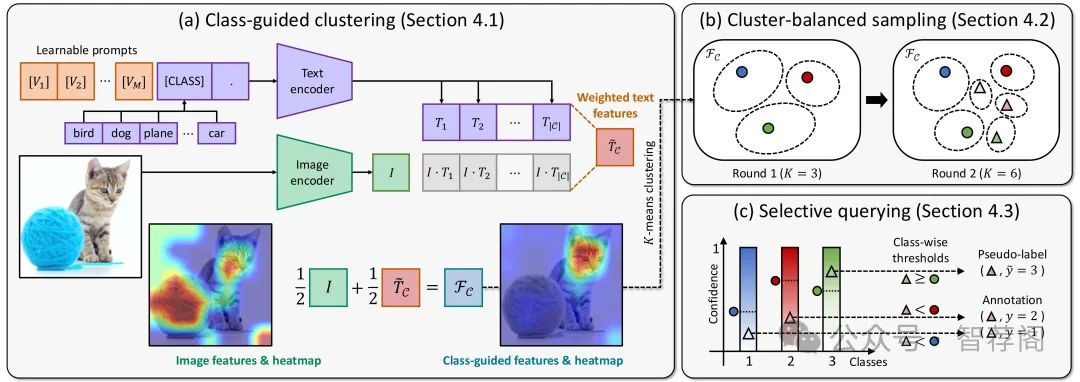
5.Active Prompt Learning with Vision-Language Model Priors
Authors: Hoyoung Kim, Seokhee Jin, Changhwan Sung, Jaechang Kim, Jungseul Ok
https://arxiv.org/abs/2411.16722
论文摘要
Vision-language models (VLMs) have demonstrated remarkable zero-shot performance across various classification tasks. Nonetheless, their reliance on hand-crafted text prompts for each task hinders efficient adaptation to new tasks. While prompt learning offers a promising solution, most studies focus on maximizing the utilization of given few-shot labeled datasets, often overlooking the potential of careful data selection strategies, which enable higher accuracy with fewer labeled data. This motivates us to study a budget-efficient active prompt learning framework. Specifically, we introduce a class-guided clustering that leverages the pre-trained image and text encoders of VLMs, thereby enabling our cluster-balanced acquisition function from the initial round of active learning. Furthermore, considering the substantial class-wise variance in confidence exhibited by VLMs, we propose a budget-saving selective querying based on adaptive class-wise thresholds. Extensive experiments in active learning scenarios across nine datasets demonstrate that our method outperforms existing baselines.
论文简评
这篇论文探讨了一种基于视觉语言模型预训练的主动提示学习框架,旨在优化数据选择和提示学习效率。该方法引入了类指导聚类和选择性查询策略,以增强多任务中主动学习场景下的标注效率。通过实验评估,在9个数据集上展示出显著的效果,表明这种方法优于现有方法。
文章的关键点在于它提供了一种创新性的解决方案,针对视觉-语言模型适应新任务时遇到的挑战。具体来说,它提出了一种基于类别的聚类方法来提高数据选择的有效性,并且介绍了选择性查询技术来进一步提升响应速度。此外,文章通过实验证明了这些策略的有效性,为视觉-语言模型的学习提供了新的思路。
综上所述,这篇文章展示了如何有效地利用视觉-语言模型进行主动提示学习,并通过实验验证了其效果。其贡献在于提出了一种新颖的方法,可有效应对视觉-语言模型适应新任务时的挑战,因此,论文具有很高的研究价值和应用前景。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









