






计划-解决提示:通过大型语言模型改进零射击思维链推理
主要内容:
论文介绍了如何通过改进零样本链式思维(Zero-shot chain-of-thought)推理模型来提高大型语言模型在多步推理任务中的表现。作者提出了“计划和解决问题”(Plan-and-Solve)提示策略,该策略由两个组件组成:首先,将整个任务分解为更小的子任务,并根据计划执行这些子任务;其次,为了消除计算错误并提高生成的推理步骤的质量,作者还扩展了PS提示策略,得到了PS+提示策略。实验结果表明,与Zero-shot-CoT相比,作者提出的提示策略在所有数据集上都取得了显著的性能提升,并且在数学推理问题上的表现甚至超过了8个训练示例的CoT提示策略。

Zero-shot-CoT存在的三个问题:
i)计算错误(7%的测试示例):这些是计算错误导致错误答案;
(ii)缺失步骤错误(占测试示例的12%):当一些中间推理步骤被遗漏时,特别是当涉及许多步骤时,这些错误就会发生;
(iii)语义误解(占测试示例的27%):在对问题的语义理解和推理步骤的连贯性方面存在其他错误,可能是llm能力不足造成的。
论文方法描述:
本文提出了PS(Plan-and-Solve)提示,这是一种新的Chain-of-Thought提示方法,它使LLMs能够明确地设计解决问题的计划,并在预测输入问题的答案之前生成中间推理过程。与以前的零样本CoT方法不同,它们需要包含一些逐步演示示例的提示,而零样本PS提示不需要示范例子,它的提示包括问题本身和一个简单的触发句子。类似于Zero-shot-CoT,Zero-shot PS提示分为两个步骤。
第一步中,提示首先使用提出的提示模板进行推断,以生成推理过程和答案。

第二步中,通过使用答案提取提示来提取答案,例如“因此,答案是阿拉伯数字”。这种方法的新颖之处在于,它引导LLMs制定详细的计划并执行该计划,以确保正确计算和执行中间结果。

方法改进
为了解决复杂推理任务中的错误,本文提出了一些详细指令,如“注意计算”,“提取相关变量及其对应的数值”,以及“计算中间结果”。这些指令可以帮助LLMs更准确地执行计算和中间结果,并避免遗漏重要信息。
解决的问题
本文的主要贡献是在CoT提示领域引入了一种新的方法,即PS提示,它允许LLMs在没有示范例子的情况下制定详细的计划并执行该计划,从而提高其在复杂推理任务上的性能。这种方法不仅可以帮助LLMs更好地理解问题和解决问题,还可以减少由于计算错误或遗漏关键信息而导致的错误。
实验部分
本文主要介绍了使用GPT-3作为语言模型的零/少量样本学习方法在不同类型的数学问题上的表现,并与现有的零/少量样本学习方法进行了比较。具体来说,本文进行了以下对比实验:
所用数据集:
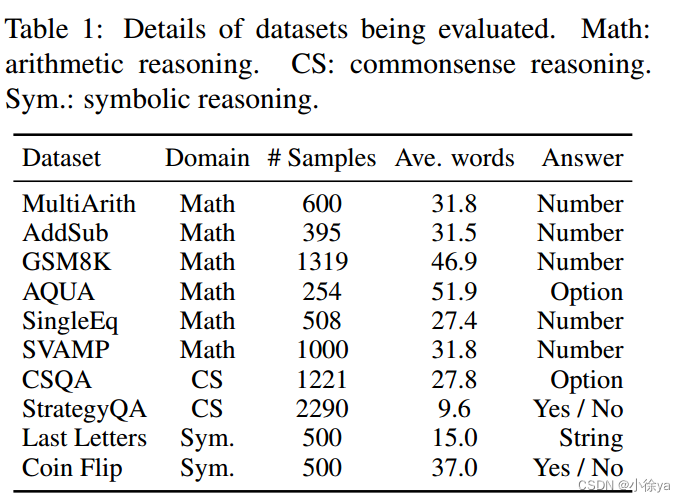
评估基准:
Zero-shot baselines
Few-shot with manual demonstrations
Few-shot with automatic demonstrations
实验结果:
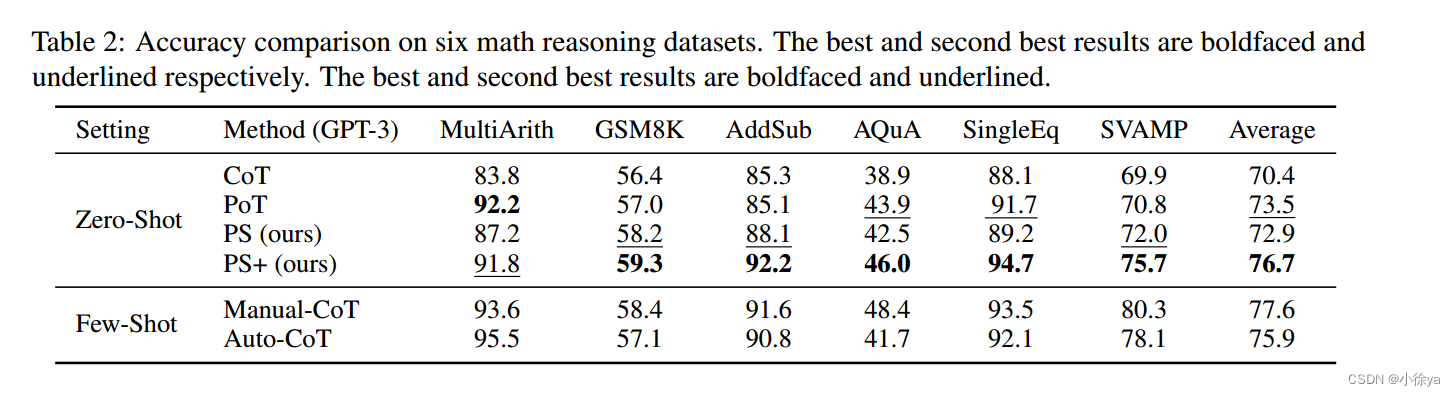
数学推理数据集:
零/少量样本学习方法在算术推理问题上的表现比较。作者使用了手动和自动生成的示例来训练模型,并使用准确率作为评估指标。结果表明,作者提出的零/少量样本学习方法在算术推理问题上表现优异,特别是在没有人工示例的情况下也能取得较好的效果。
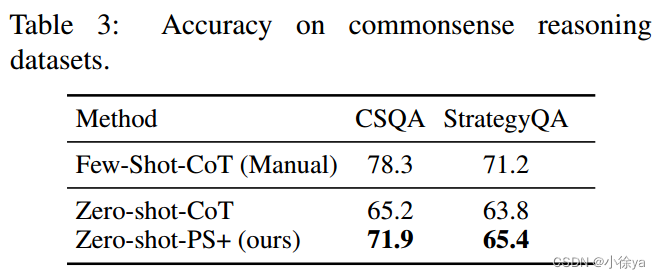
常识推理数据集:
零/少量样本学习方法在常识推理问题上的表现比较。作者只对作者提出的零/少量样本学习方法进行了比较,因为其他方法不适用于该类型的问题。结果表明,在常识推理问题上,作者的方法表现较好。
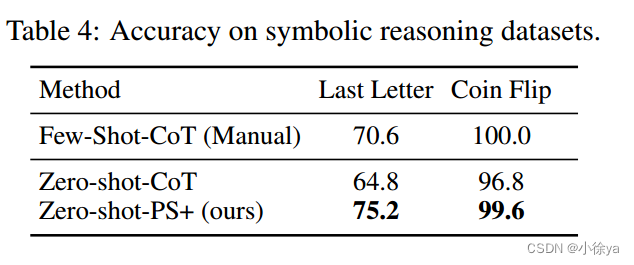
符号推理数据集:
零/少量样本学习方法在符号推理问题上的表现比较。作者只对作者提出的零/少量样本学习方法进行了比较,因为其他方法不适用于该类型的问题。结果表明,在符号推理问题上,作者的方法表现较好。
不同ps提示词在数据集上的得分表现:
不同提示方式对零/少量样本学习方法的影响比较。作者设计了多种不同的提示方式,并对其表现进行了比较。结果表明,添加更多的细节指令可以使模型产生更好的推理步骤。
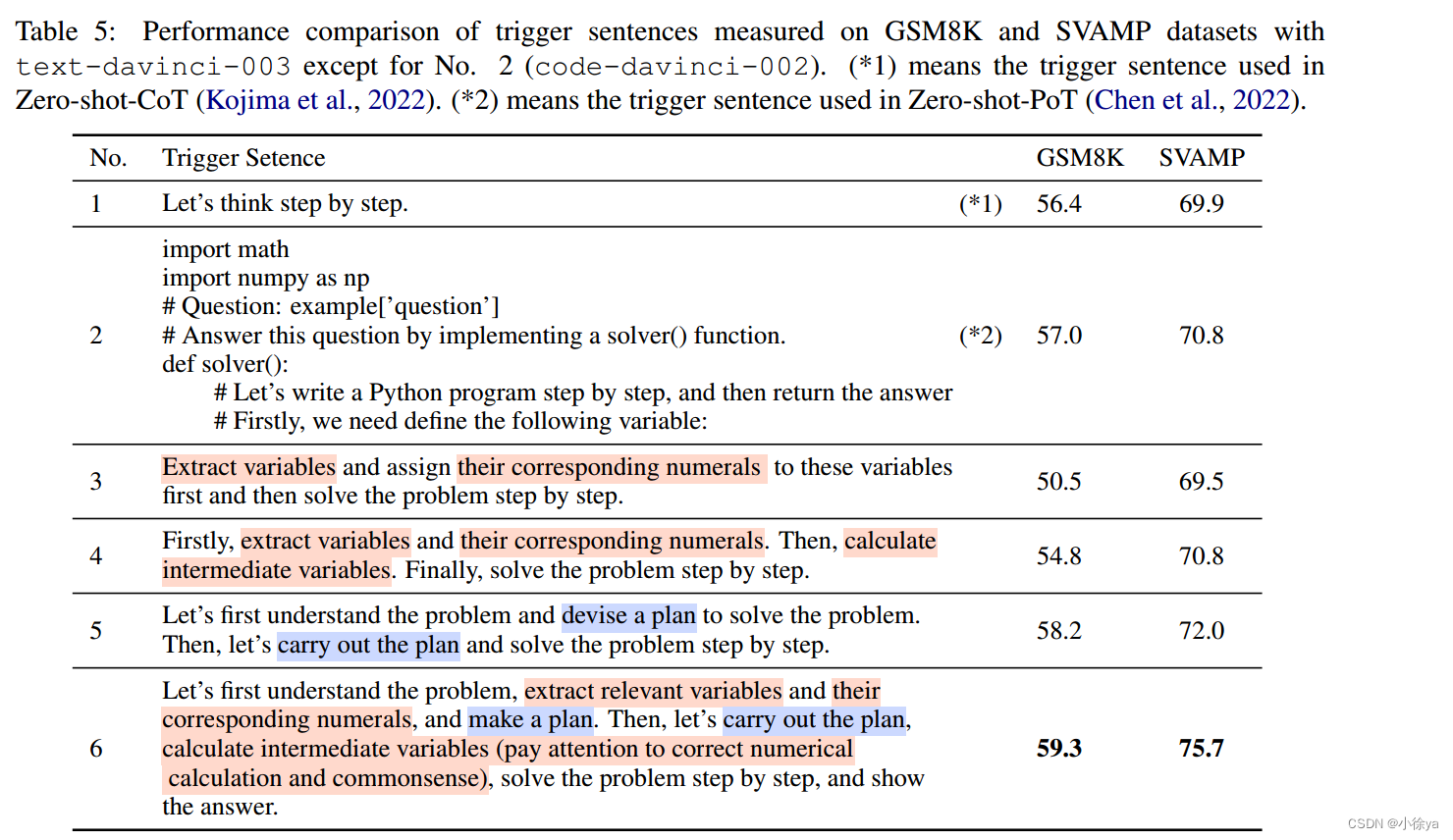
Zero-shot-ps/ps+与Zero-shot-CoT对比
计算错误-缺失步骤错误-语义误解
错误分析和计划存在的影响比较。作者通过对错误类型的分布进行分析,进一步探讨了零/少量样本学习方法的优势。结果表明,计划的存在可以减少计算错误和缺失推理步骤的错误,而零/少量样本学习方法可以在不依赖人工示例的情况下实现这一点。
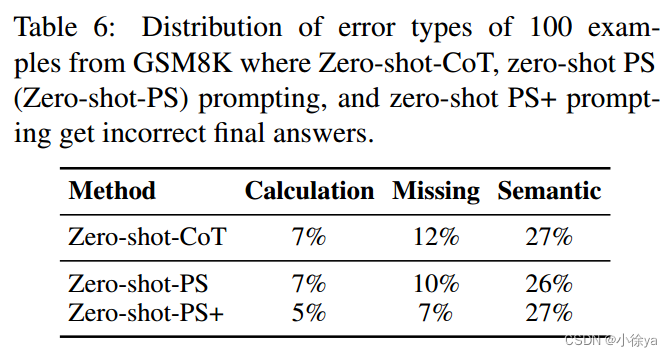
总的来说,本文展示了使用GPT-3作为语言模型的零/少量样本学习方法在不同类型数学问题上的表现,并与其他现有方法进行了比较。结果表明,该方法具有较高的准确性,并且可以通过添加更多细节指令和使用自一致性策略等方式进一步提高其性能。此外,该方法还可以有效地解决计算错误和缺失推理步骤等问题。
论文总结
文章优点
本文提出了一种新的Zero-shot-CoT方法——计划和解决策略(PS)和PS+提示。这些方法引导大型语言模型通过将整个任务分解为更小的子任务来实现正确的推理,并根据计划执行子任务。实验结果表明,与先前的Zero-shot-CoT相比,PS+在多个算术推理数据集上表现更好或相当好,并且可以与少数shot-CoT方法相媲美。此外,作者还提出了计划和解决策略的概念,该概念可用于非推理任务,这为未来的进一步研究提供了方向。
方法创新点
本文的主要贡献是提出了一种新的Zero-shot-CoT方法——计划和解决策略(PS)和PS+提示,以及计划和解决策略的概念。这种方法能够引导大型语言模型实现正确的推理,而不是仅仅基于语言模型本身的能力。这种创新的方法对于提高语言模型在推理任务中的性能具有重要意义。
未来展望
未来的研究可以从以下几个方面展开:首先,可以探索如何改进计划和解决策略以更好地指导大型语言模型实现正确的推理;其次,可以考虑如何将计划和解决策略应用于其他类型的自然语言处理任务中,例如对话系统和机器翻译等;最后,可以尝试将计划和解决策略与其他技术相结合,如动态提示学习和半监督学习等,以进一步提高语言模型在各种任务上的性能。
个人总结
其实仔细观察下来,与关于Agent设计的提示策略底层的原理差别不大,均是对ReAct或CoT的改进,都是基于大模型强大的能力而又不能充分且良好调用的基础上,让大模型能够像人一样初步思考,计划,执行,反思,总结...


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









