







Attention is all you need 是一篇发表在NIPS 2017年会议上的论文,该论文犹如火星撞地球一般迅速横扫了整个自然语言处理学术界,并迅速取代了循环神经网络家族成为了之后的语言模型里的标配。如我们熟知的GPT(生成式预训练模型)系列模型和BERT(来自transformer的双向编码器表征)系列模型,都是受到了这篇文章的启发采用了部分transformer的架构。
Part 1 神经网络基础
神经网络基础



全连接
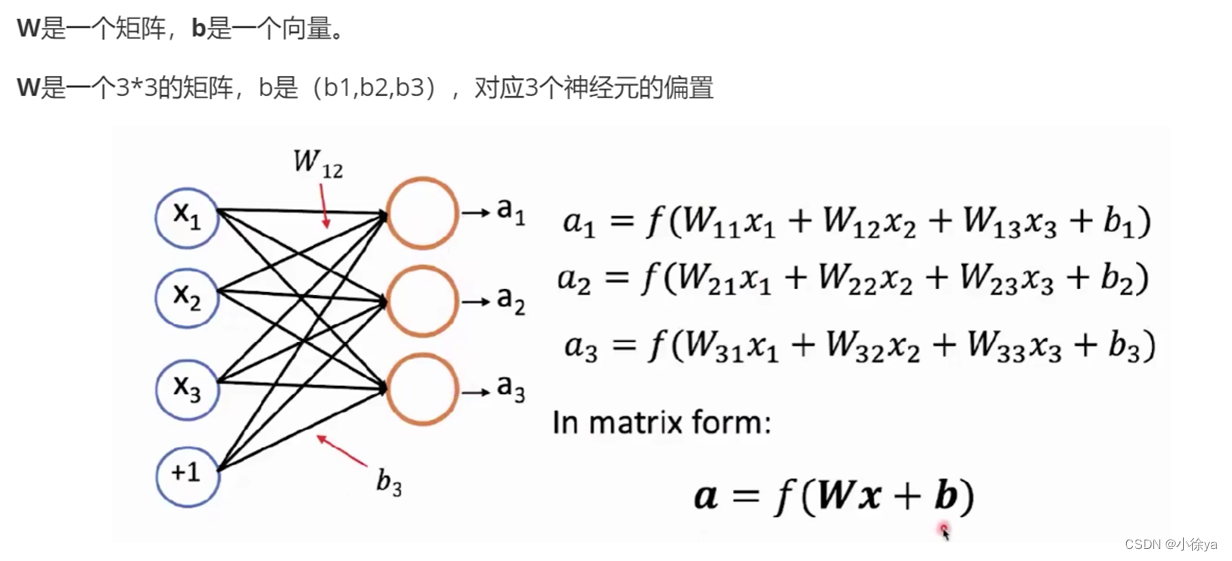
隐藏层 激活函数
 如果没有激活函数,那么多层神经网络的表达能力和单层神经网络的表达能力相同,因此引入非线性激活函数,防止多层神经网络塌缩成单一的神经网络。
如果没有激活函数,那么多层神经网络的表达能力和单层神经网络的表达能力相同,因此引入非线性激活函数,防止多层神经网络塌缩成单一的神经网络。
 常见激活函数
常见激活函数

输出层
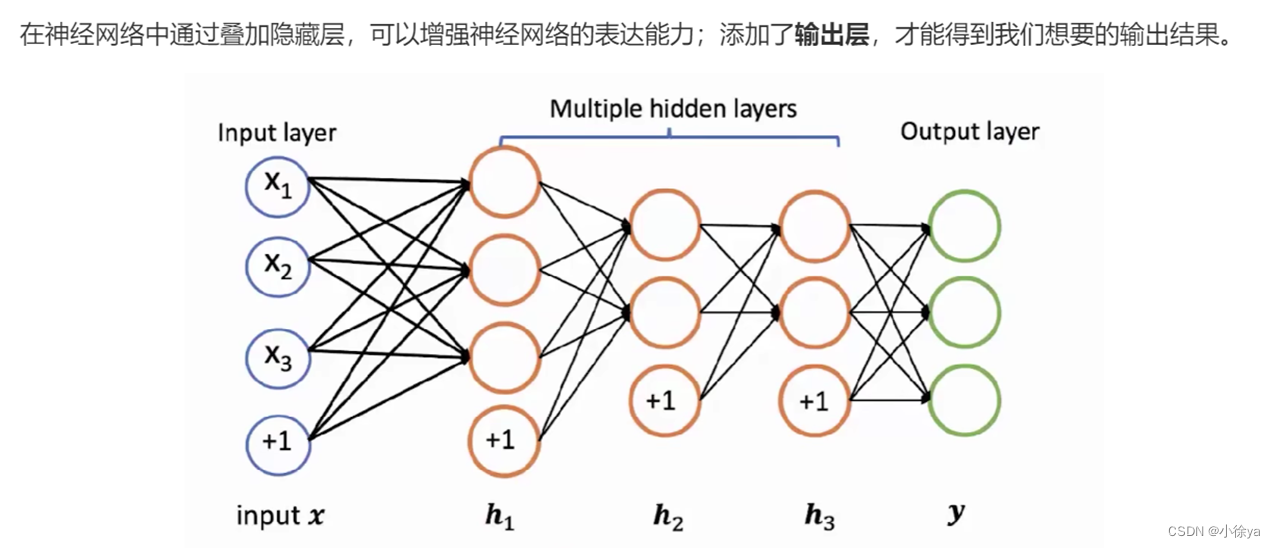
输出层函数


loss函数

梯度下降

反向传播

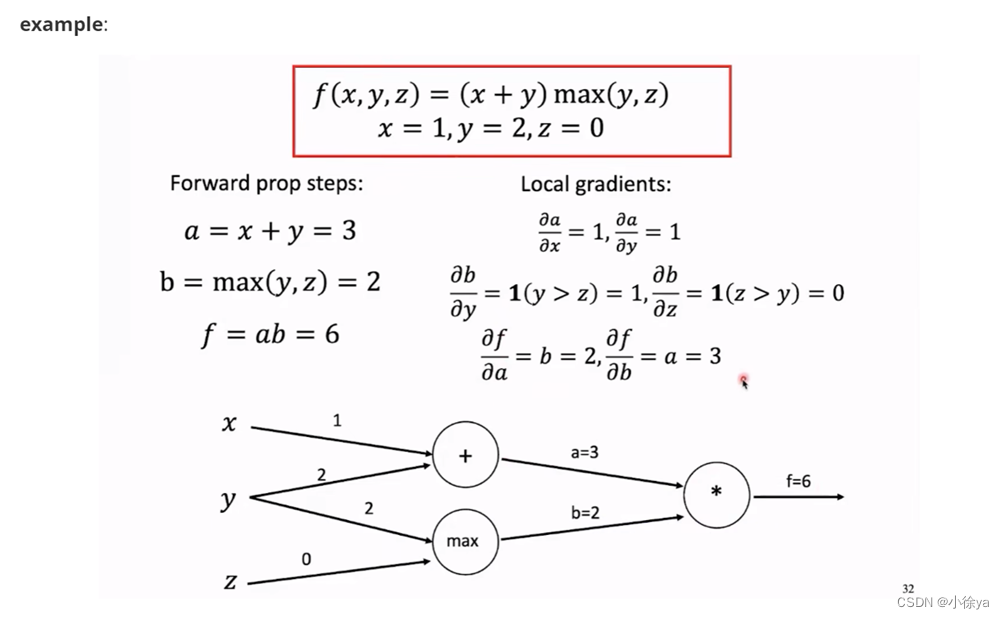
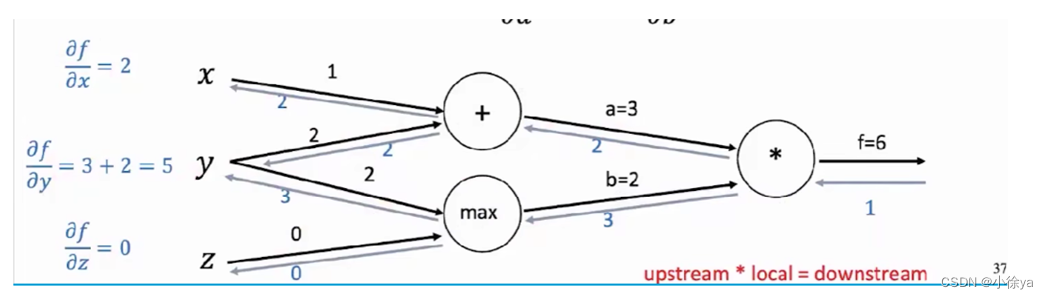
Part 2 Transformer结构
整体结构
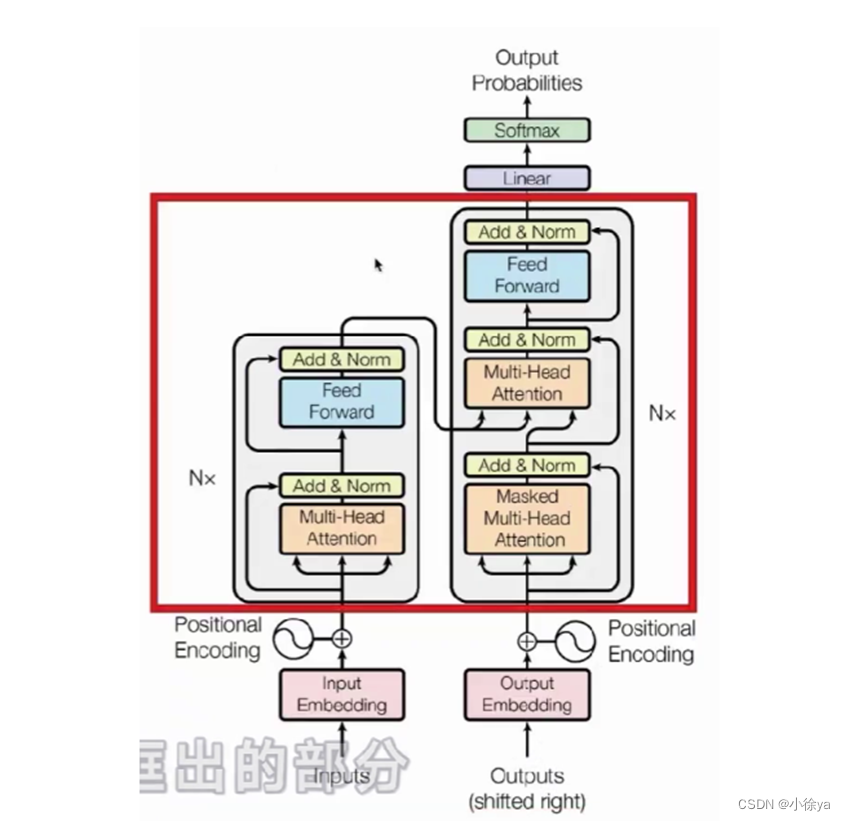
左边是Encoder,右边是Decoder。
下面:输入层,输入层需要将文本序列切分成一个个小单元token,通过embedding转化为向量表示,
中间:模型部分,由多个Transformer block堆叠而成,结构一样但参数有略微差异。通过block的堆叠,可以让模型得到更好的效果。
最上面:输出层,一个线性变换和一个softmax,来输出词表上的概率分布。
Encoder端
输入层的文本切分方式BPE

 输入层中的Positional Encoding(位置编码)
输入层中的Positional Encoding(位置编码)

Encoder端的block

核心:Multi-Head Attention

补充:解释注意力机制


(1)计算注意力分数,s1分别和hi进行点积,得到7个标量(深度学习中的标量就是常数),得到向量$e^1$,
向量$e^1$就是Encoder端隐向量的注意力分数,这个分数就表明了s1与每个Encoder端隐向量的相似程度,
(2)然后用一个softmax函数,转换为概率分布;
前两个位置的值比较大,在这一步的生成中,会更关注前两个位置的隐向量,
(3)对隐向量进行加权求和,得到向量$o_{1}$,向量$o_{1}$包含了Decoder需要的Encoder提供的所有信息;

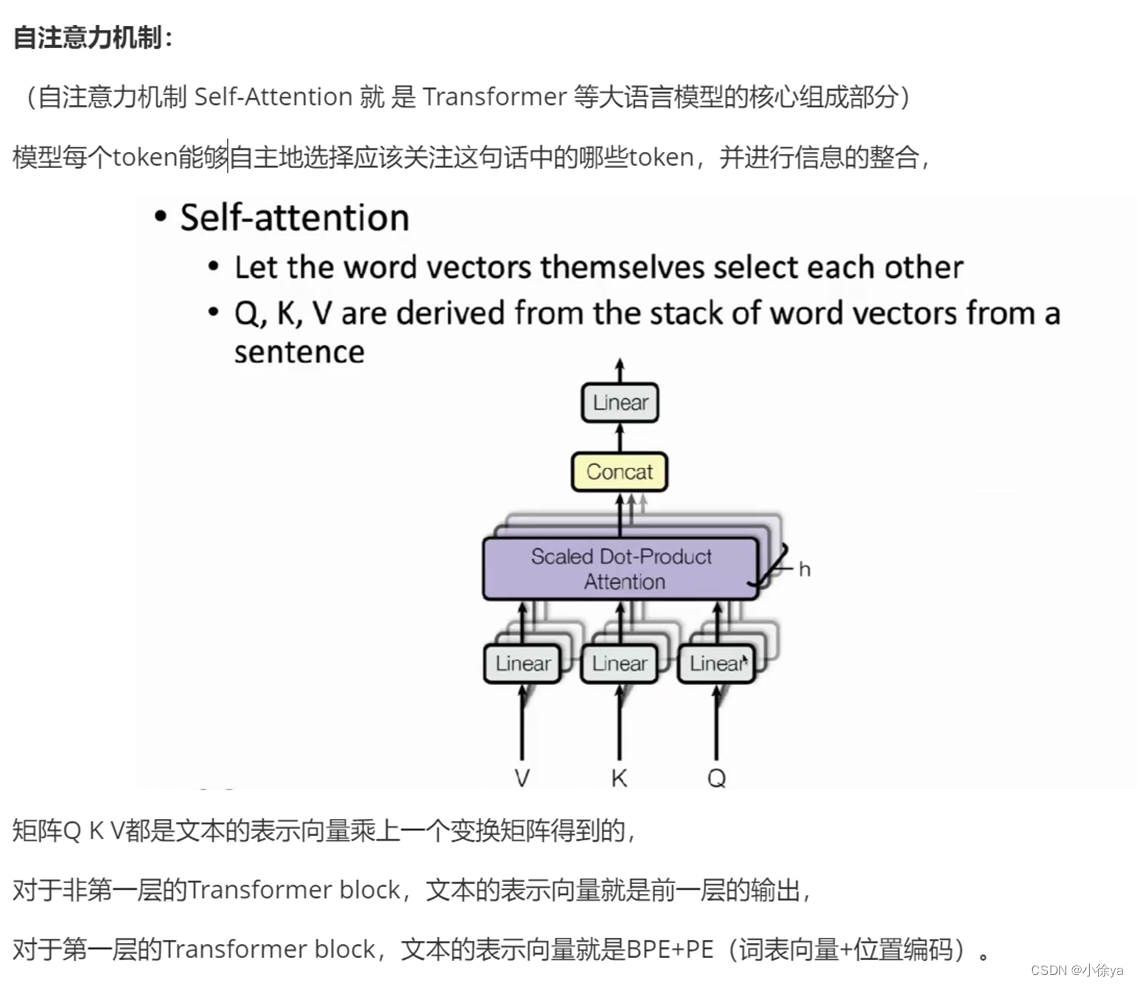
Multi-Head Attention

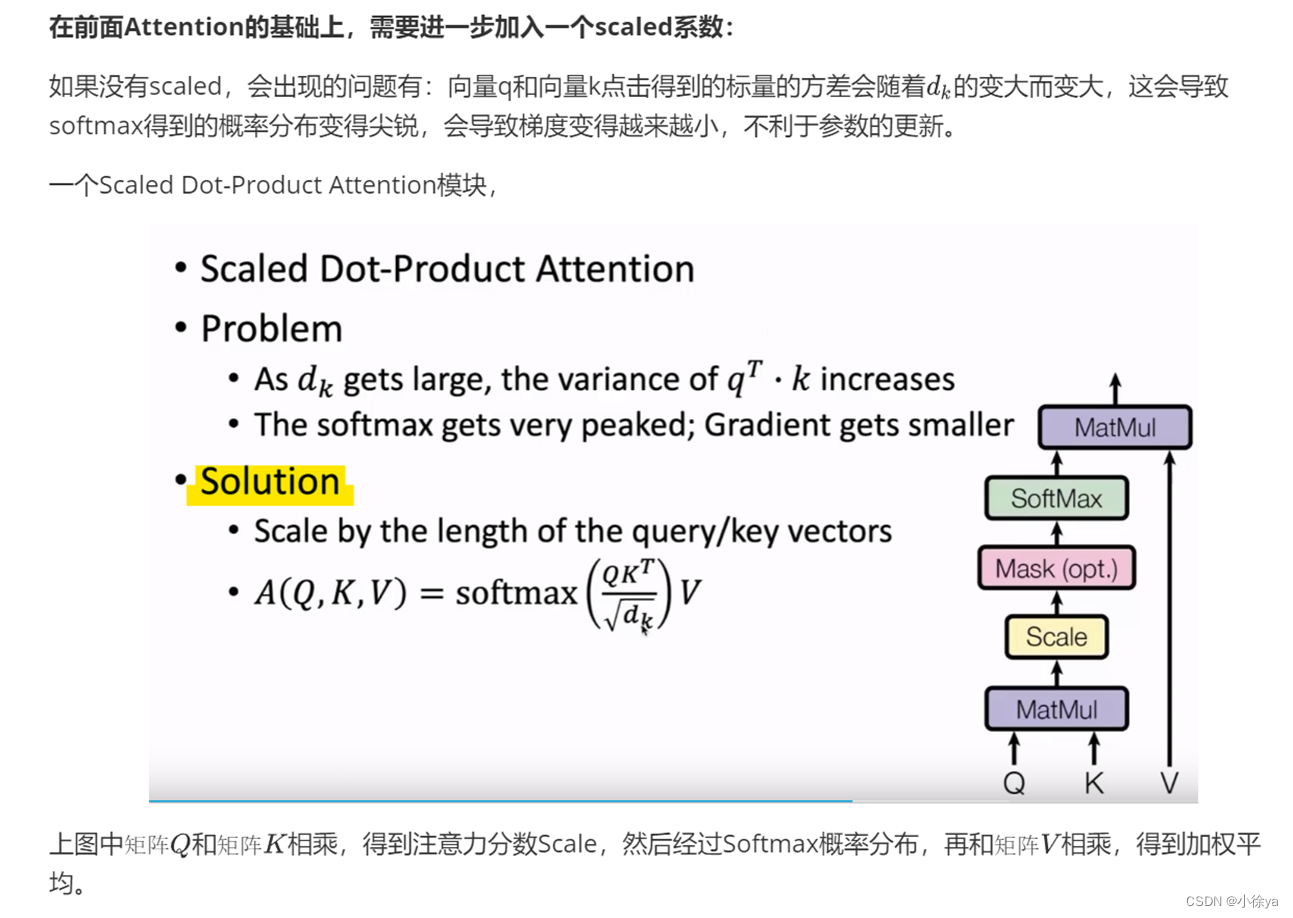
和原来的注意力机制不同的是,
在Transformer中,给定的是一个query向量、一个key向量和value向量对的集合,query向量和key向量的维度都是$d_{k}$,通过向量q和向量k计算注意力分数,通过softmax转换成注意力分布。


Decoder端


和Encoder端block不同的地方:
Masked Multi-Head Attention:通过限制向量Q和向量K相乘得到注意力分数矩阵,把上三角部分变成负无穷,经过softmax之后,上三角部分的概率分布都是0,使得模型无法在当前输出的时候”看到“后面的单词。不会出现生成第i个词参考了第i+1个词,符合从左到右的书写逻辑。
中间多加了一个Multi-Head Attention:它的query向量Q来自Decoder,K 、V向量来自Encoder最后一层的输出,帮助Decoder端的每一步生成都可以关注和整合Encoder端的信息。














 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









